R語言數(shù)據(jù)分析實戰(zhàn):數(shù)據(jù)結(jié)構(gòu)(2)
4、數(shù)據(jù)框
由于不同的列可以包含不同模式(數(shù)值型�����、字符型等)的數(shù)據(jù)���,數(shù)據(jù)框的概念較矩陣來說更為一般��。它與你通常在SAS�、SPSS和Stata中看到的數(shù)據(jù)集類似��。數(shù)據(jù)框?qū)⑹悄阍?/span>R語言中最常處理的數(shù)據(jù)結(jié)構(gòu)�。
表2-1所示的病例數(shù)據(jù)集包含了數(shù)值型和字符型數(shù)據(jù)�����。由于數(shù)據(jù)有多種模式,無法將此數(shù)據(jù)集放入一個矩陣����。在這種情況下,使用數(shù)據(jù)框是最佳選擇�����。
數(shù)據(jù)框可通過函數(shù)data.frame()創(chuàng)建:
-
mydata <- data.frame(col1, col2, col3,…)
其中的列向量col1, col2, col3,… 可為任何類型(如字符型����、數(shù)值型或邏輯型)。每一列的名稱可由函數(shù)names指定����。代碼清單2-4清晰地展示了相應(yīng)用法。

每一列數(shù)據(jù)的模式必須唯一����,不過你卻可以將多個模式的不同列放到一起組成數(shù)據(jù)框。由于數(shù)據(jù)框與數(shù)據(jù)分析人員通常設(shè)想的數(shù)據(jù)集的形態(tài)較為接近�,我們在討論數(shù)據(jù)框時將交替使用術(shù)語列和變量。
選取數(shù)據(jù)框中元素的方式有若干種�����。你可以使用前述(如矩陣中的)下標(biāo)記號,亦可直接指定列名���。代碼清單2-5使用之前創(chuàng)建的patientdata數(shù)據(jù)框演示了這些方式��。
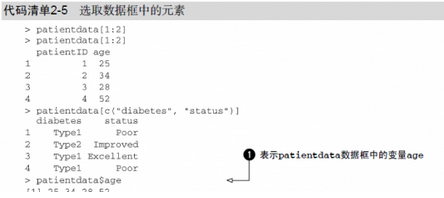
第三個例子中的記號$是新出現(xiàn)的①�����。它被用來選取一個給定數(shù)據(jù)框中的某個特定變量�。例如�����,如果你想生成糖尿病類型變量diabetes和病情變量status的列聯(lián)表���,使用以下代碼即可:
-
table(patientdata$diabetes, patientdata$status)
-
Excellent Improved Poor
-
Type1 1 0 2
-
Type2 0 1 0
在每個變量名前都鍵入一次patientdata$可能會讓人生厭����,所以不妨走一些捷徑���?����?梢月?lián)合使用函數(shù)attach()和detach()或單獨(dú)使用函數(shù)with()來簡化代碼���。
(1)attach()、detach()和with()
函數(shù)attach()可將數(shù)據(jù)框添加到R的搜索路徑中�。R在遇到一個變量名以后,將檢查搜索路徑中的數(shù)據(jù)框��,以定位到這個變量��。以第1章中的mtcars數(shù)據(jù)框為例����,可以使用以下代碼獲取每加侖行駛英里數(shù)(mpg)變量的描述性統(tǒng)計量,并分別繪制此變量與發(fā)動機(jī)排量(disp)和車身重量(wt)的散點圖:
-
summary(mtcars$mpg)
-
plot(mtcars$mpg, mtcars$disp)
-
plot(mtcars$mpg, mtcars$wt)
以上代碼也可寫成:
-
attach(mtcars)
-
summary(mpg)
-
plot(mpg, disp)
-
plot(mpg, wt)
-
detach(mtcars)
函數(shù)detach()將數(shù)據(jù)框從搜索路徑中移除�����。值得注意的是��,detach()并不會對數(shù)據(jù)框本身做任何處理�。這句是可以省略的,但其實它應(yīng)當(dāng)被例行地放入代碼中,因為這是一個好的編程習(xí)慣����。(接下來的幾章中,為了保持代碼片段的簡約和簡短����,我可能會不時地忽略這條良訓(xùn)。)當(dāng)名稱相同的對象不止一個時�,這種方法的局限性就很明顯了??紤]以下代碼:
-
> mpg <- c(25, 36, 47)
-
> attach(mtcars)
-
The following object(s) are masked _by_ ‘.GlobalEnv’: mpg
-
-
> plot(mpg, wt)
-
Error in xy.coords(x, y, xlabel, ylabel, log) :
-
‘x’ and ‘y’ lengths differ
-
-
> mpg
-
[1] 25 36 47
這里,在數(shù)據(jù)框mtcars被綁定(attach)之前����,我們的環(huán)境中已經(jīng)有了一個名為mpg的對象。在這種情況下����,原始對象將取得優(yōu)先權(quán),這與你想要的結(jié)果有所出入�����。由于mpg中有3個元素而disp中有32個元素����,故plot語句出錯��。函數(shù)attach()和detach()最好在你分析一個單獨(dú)的數(shù)據(jù)框�����,并且不太可能有多個同名對象時使用。任何情況下���,都要當(dāng)心那些告知某個對象已被屏蔽(masked)的警告����。除此之外���,另一種方式是使用函數(shù)with()��。你可以這樣重寫上例:
-
with(mtcars, {
-
summary(mpg, disp, wt)
-
plot(mpg, disp)
-
plot(mpg, wt)
-
})
在這種情況下����,大括號{}之間的語句都針對數(shù)據(jù)框mtcars執(zhí)行��,這樣就無須擔(dān)心名稱沖突了����。如果僅有一條語句(例如summary(mpg))����,那么大括號{}可以省略�����。
函數(shù)with()的局限性在于����,賦值僅在此函數(shù)的括號內(nèi)生效?��?紤]以下代碼:
-
with(mtcars, {
-
stats <- summary(mpg)
-
stats
-
})
-
Min. 1st Qu. Median Mean 3rd Qu. Max.
-
10.40 15.43 19.20 20.09 22.80 33.90
-
> stats
-
Error: object ‘stats’ not found
如果你需要創(chuàng)建在with()結(jié)構(gòu)以外存在的對象�,使用特殊賦值符<<-替代標(biāo)準(zhǔn)賦值符(<-)即可�,它可將對象保存到with()之外的全局環(huán)境中。這一點可通過以下代碼闡明:
-
with(mtcars, {
-
nokeepstats <- summary(mpg)
-
keepstats <<- summary(mpg)
-
})
-
> nokeepstats
-
Error: object ‘nokeepstats’ not found
-
> keepstats
-
Min. 1st Qu. Median Mean 3rd Qu. Max.
-
10.40 15.43 19.20 20.09 22.80 33.90
相對于attach()����,多數(shù)的R書籍更推薦使用with()。個人認(rèn)為從根本上說�����,選擇哪一個是自己的偏好問題,并且應(yīng)當(dāng)根據(jù)你的目的和對于這兩個函數(shù)含義的理解而定�。
(2) 實例標(biāo)識符
在病例數(shù)據(jù)中,病人編號(patientID)用于區(qū)分?jǐn)?shù)據(jù)集中不同的個體�。在R語言中,實例標(biāo)識符(case identifier)可通過數(shù)據(jù)框操作函數(shù)中的rowname選項指定���。例如�,語句:
-
patientdata <- data.frame(patientID, age, diabetes, status,row.names=patientID)
將patientID指定為R語言中標(biāo)記各類打印輸出和圖形中實例名稱所用的變量���。
5�、因子
變量可歸結(jié)為名義型����、有序型或連續(xù)型變量����。名義型變量是沒有順序之分的類別變量。糖尿病類型Diabetes(Type1�����、Type2)是名義型變量的一例���。即使在數(shù)據(jù)中Type1編碼為1而Type2編碼為2��,這也并不意味著二者是有序的���。有序型變量表示一種順序關(guān)系��,而非數(shù)量關(guān)系�����。病情Status(poor,
improved, excellent)是順序型變量的一個上佳示例
我們明白�����,病情為poor(較差)病人的狀態(tài)不如improved(病情好轉(zhuǎn))的病人����,但并不知道相差多少�。連續(xù)型變量可以呈現(xiàn)為某個范圍內(nèi)的任意值,并同時表示了順序和數(shù)量��。年齡Age就是一個連續(xù)型變量�����,它能夠表示像14.5或22.8這樣的值以及其間的其他任意值。很清楚����,15歲的人比14歲的人年長一歲。
類別(名義型)變量和有序類別(有序型)變量在R語言中稱為因子(factor)��。因子在R語言中非常重要�����,因為它決定了數(shù)據(jù)的分析方式以及如何進(jìn)行視覺呈現(xiàn)����。你將在本書中通篇看到這樣的例子。
函數(shù)factor()以一個整數(shù)向量的形式存儲類別值��,整數(shù)的取值范圍是[1... k ](其中k 是名義型變量中唯一值的個數(shù))��,同時一個由字符串(原始值)組成的內(nèi)部向量將映射到這些整數(shù)上�����。
舉例來說���,假設(shè)有向量:
-
diabetes <- c("Type1", "Type2", "Type1", "Type1")
語句diabetes <- factor(diabetes)將此向量存儲為(1, 2, 1,
1)�����,并在內(nèi)部將其關(guān)聯(lián)為1=Type1和2=Type2(具體賦值根據(jù)字母順序而定)��。針對向量diabetes進(jìn)行的任何分析都會將其作為名義型變量對待���,并自動選擇適合這一測量尺度的統(tǒng)計方法。
要表示有序型變量�����,需要為函數(shù)factor()指定參數(shù)ordered=TRUE����。給定向量:
-
status <- c("Poor", "Improved", "Excellent", "Poor")
語句status <- factor(status, ordered=TRUE)會將向量編碼為(3, 2, 1,
3),并在內(nèi)部將這些值關(guān)聯(lián)為1=Excellent�、2=Improved以及3=Poor。另外���,針對此向量進(jìn)行的任何分析都會將其作為有序型變量對待��,并自動選擇合適的統(tǒng)計方法�����。
對于字符型向量���,因子的水平默認(rèn)依字母順序創(chuàng)建����。這對于因子status是有意義的��,因為“Excellent”���、“Improved”�����、“Poor”的排序方式恰好與邏輯順序相一致����。如果“Poor”被編碼為“Ailing”��,會有問題�,因為順序?qū)椤癆iling”����、“Excellent”���、“Improved”。如果理想中的順序是“Poor”����、“Improved”、“Excellent”���,則會出現(xiàn)類似的問題���。按默認(rèn)的字母順序排序的因子很少能夠讓人滿意。
你可以通過指定levels選項來覆蓋默認(rèn)排序����。例如:
-
status <- factor(status, order=TRUE,
-
levels=c("Poor", "Improved", "Excellent"))
各水平的賦值將為1=Poor、2=Improved�����、3=Excellent����。請保證指定的水平與數(shù)據(jù)中的真實值相匹配,因為任何在數(shù)據(jù)中出現(xiàn)而未在參數(shù)中列舉的數(shù)據(jù)都將被設(shè)為缺失值。
代碼清單2-6演示了普通因子和有序因子的不同是如何影響數(shù)據(jù)分析的���。
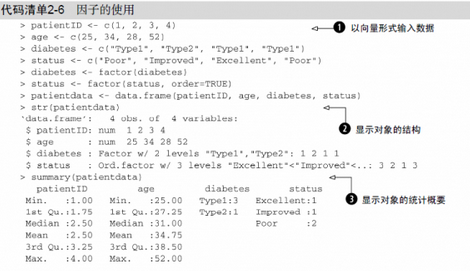
首先��,以向量的形式輸入了數(shù)據(jù)①��。然后�����,將diabetes和status分別指定為一個普通因子和一個有序型因子�。最后��,將數(shù)據(jù)合并為一個數(shù)據(jù)框�����。函數(shù)str(object)可提供R語言中某個對象(本例中為數(shù)據(jù)框)的信息②�。它清楚地顯示diabetes是一個因子,而status是一個有序型因子����,以及此數(shù)據(jù)框在內(nèi)部是如何進(jìn)行編碼的。注意���,函數(shù)summary()會區(qū)別對待各個變量③���。它顯示了連續(xù)型變量age的最小值、最大值��、均值和各四分位數(shù)�����,并顯示了類別型變量diabetes和status(各水平)的頻數(shù)值����。
6、列表
列表(list)是R的數(shù)據(jù)類型中最為復(fù)雜的一種�����。一般來說���,列表就是一些對象(或成分�,component)的有序集合�。列表允許你整合若干(可能無關(guān)的)對象到單個對象名下。例如�����,某個列表中可能是若干向量、矩陣��、數(shù)據(jù)框�,甚至其他列表的組合?���?梢允褂煤瘮?shù)list()創(chuàng)建列表:
-
mylist <- list(object1, object2, …)
其中的對象可以是目前為止講到的任何結(jié)構(gòu)。你還可以為列表中的對象命名:
-
mylist <- list(name1=object1, name2=object2, …)
代碼清單2-7展示了一個例子�。
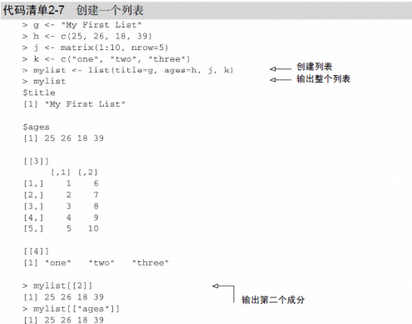
本例創(chuàng)建了一個列表,其中有四個成分:一個字符串����、一個數(shù)值型向量、一個矩陣以及一個字符型向量�。可以組合任意多的對象��,并將它們保存為一個列表����。
你也可以通過在雙重方括號中指明代表某個成分的數(shù)字或名稱來訪問列表中的元素。此例中���,mylist[[2]]和mylist[["ages"]]均指那個含有四個元素的向量���。由于兩個原因���,列表成為了R語言中的重要數(shù)據(jù)結(jié)構(gòu)���。首先����,列表允許以一種簡單的方式組織和重新調(diào)用不相干的信息����。其次,許多R函數(shù)的運(yùn)行結(jié)果都是以列表的形式返回的�。需要取出其中哪些成分由分析人員決定。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330