建模那點事兒—實戰(zhàn)篇
有過建模經驗的人自然懂����,沒有經驗的各位也不要著急,這次我以一個真實模型為例�,給大家詳細講述建模的各個步驟����。
照例,先上流程圖:
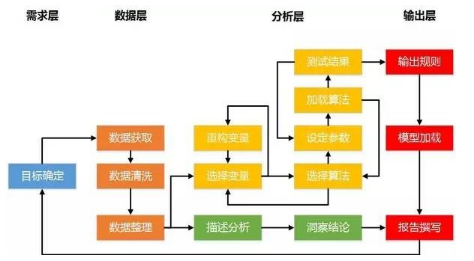
大家可以看到,這個圖是由我之前文章中的兩張圖拼合而來,而我今天講的這個真實模型,將把圖中所有的流程都走一遍�,保證一個步驟都不漏���。
Step 0:項目背景
話說這個項目跟我加入百度有直接關系……
2013年的最后一天����,我結束了在三亞的假期,準備坐飛機回家,這時候接到一個知乎私信,問我對百度的一個數(shù)據科學家(其實就是數(shù)據分析師啦)職位是否感興趣,我立刻回信,定了元旦假期以后去面試�。兩輪面試過后����,面試官——也是我加入百度后的直屬Leader——打電話給我,說他們對我的經歷很滿意�,但是需要我給他們一份能體現(xiàn)建模能力的報告。
按說這也不是一件難事�����,但我翻了翻電腦后發(fā)現(xiàn)一個問題:我從上家公司離職時����,為了裝13,一份跟建模相關的報告文件都沒帶……最后雙方商定��,我有一個星期時間來做一份報告����,這份報告決定了我是否能加入百度。
那么,是時候展示我的技術了!我的回合����,抽卡!
Step 1:目標確定
看看報告的要求:
數(shù)據最好是通過抓取得來,需要用到至少一種(除描述統(tǒng)計以外)的建模技術��,最好有數(shù)據可視化的展示
看來是道開放題�,那么自然要選擇一個我比較熟悉的領域�,因此我選擇了……《二手主機游戲交易論壇用戶行為分析》
為啥選這個呢?你們看了我那么多的Mario圖����,自然知道我會選主機游戲領域�����,但為什么是二手?這要說到我待在國企的最后半年��,那時候我一個月忙三天��,剩下基本沒事干����,因此泡在論壇上倒賣了一段時間的二手游戲……
咳咳……總之�����,目標就確定了:分析某二手主機游戲交易論壇上的帖子��,從中得出其用戶行為的描述��,為用戶進行分類����,輸出洞察報告��。
Step 2:數(shù)據獲取
簡單來說�����,就是用python寫了個定向爬蟲,抓了某個著名游戲論壇的二手區(qū)所有的發(fā)帖信息�����,包括帖子內容�、發(fā)帖人信息等,基本上就是長這個樣子:
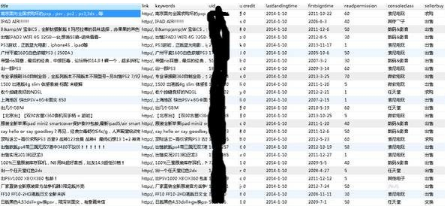
(打碼方式比較簡單粗暴����,請湊合看吧……)
這個模型中的數(shù)據清洗,主要是洗掉帖子中的無效信息���,包括以下兩類:
1�、論壇由于其特殊性���,很多人成交后會把帖子改成《已出》等標題��,這一類數(shù)據需要刪除:
2�����、有一部分人用直接貼圖的方式放求購信息���,這部分體現(xiàn)為只抓到圖片鏈接����,需要刪除��。
數(shù)據清洗結束了么?其實并沒有��,后邊會再進行一輪清洗……不過到時再說���。
Step 4:數(shù)據整理
用上面的那些帖子數(shù)據其實是跑不出啥結果的�,我們需要把數(shù)據整理成可以進一步分析的格式�����。
首先�����,我們給每條帖子打標簽��,標簽分為三類:行為類型(買 OR 賣 OR 換),目標廠商(微軟 OR 索尼 OR 任天堂)��,目標對象(主機 OR 游戲軟件)��。打標簽模式是”符合關鍵詞—打相應標簽“的方法�����,關鍵詞表樣例如下:
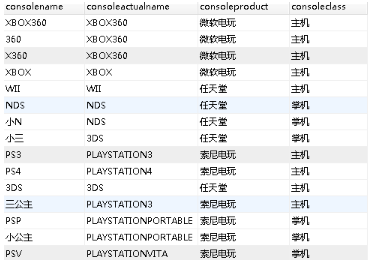
(主機掌機那個標簽后來我在實際操作時沒有使用)
打完標簽之后�,會發(fā)現(xiàn)有很多帖子沒有打上標簽��,原因有兩種:一是關鍵詞沒有涵蓋所有的產品表述(比如三公主這種昵稱)���,二是有一部分人發(fā)的帖子跟買賣游戲無關……
這讓人怎么玩……第二次數(shù)據清洗開始����,把這部分帖子也洗掉吧����。
其次,我們用發(fā)帖用戶作為視角���,輸出一份用戶的統(tǒng)計表格�,里邊包含每個用戶的發(fā)帖數(shù)、求購次數(shù)�����、出售次數(shù)�����、交換次數(shù)����、每一類主機/游戲的行為次數(shù)等等,作為后續(xù)搭建用戶分析模型之用���。表格大概長這個樣子:
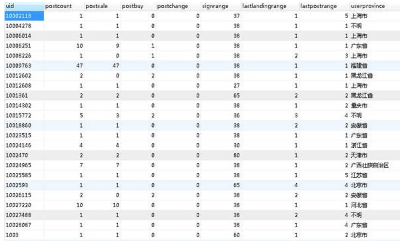
之后這個表的列數(shù)會越來越多���,因為數(shù)據重構的工作都在此表中進行。
整理之后����,我們準備進行描述統(tǒng)計。
Step 5 & 6:描述統(tǒng)計 & 洞察結論
描述統(tǒng)計在這個項目中的意義在于����,描述這一社區(qū)的二手游戲及主機市場的基本情況����,為后續(xù)用戶模型的建立提供基礎信息��。
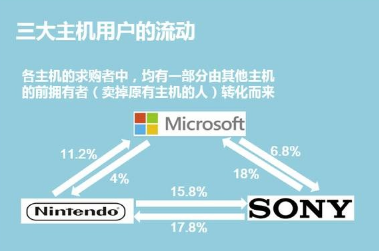
具體如何進行統(tǒng)計就不說了����,直接放成品圖,分別是從各主機市場份額��、用戶相互轉化情況�、地域分布情況進行的洞察�����。

Step 7 & 8:選擇變量 & 選擇算法
因為我要研究的是這些用戶與二手交易相關的行為��,因此初步選擇變量為發(fā)帖數(shù)量�����、微軟主機擁有臺數(shù)����、索尼主機擁有臺數(shù)���、任天堂主機擁有臺數(shù)。
算法上面�,我們的目標是將用戶分群,因此選擇聚類�����,方法選擇最簡單的K-means算法����。
Step 9 & 10:設定參數(shù) & 加載算法
K-means算法除了輸入變量以外,還需要設定聚類數(shù)����,我們先拍腦袋聚個五類吧!
(別笑,實際操作中很多初始參數(shù)都是靠拍腦袋得來的�,要通過結果來逐步優(yōu)化)
看看結果:

第一類別的用戶數(shù)跟總體已經很接近了,完全沒有區(qū)分度啊!
Step 7‘ & 8’ & 9‘ & 10’ & 11:選擇變量 & 選擇算法 &設定參數(shù) & 加載算法 &重構變量
這一節(jié)你看標題都這么長……
既然我們用原始值來聚類的結果不太好���,那么我把原始值重構成若干檔次��,比如發(fā)帖1-10的轉換為1,10-50的轉換為2��,依次類推�,再聚一次看看結果。
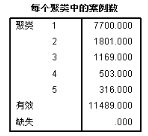
哦哦!看上去有那么點意思了!不過有一類的數(shù)量還是有一點少�,我們聚成四類試試:
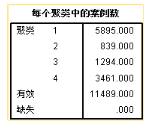
哦哦,完美! 我們運氣不錯���,一次變量重構就輸出了一個看上去還可以的模型結果���,接下來去測試一下吧。
Step 12:結果測試
測試過程中�����,很重要的一步是要看模型的可解釋性����,如果可解釋性較差�����,那么打回重做……
接下來�����,我們看看每一類的統(tǒng)計數(shù)據:
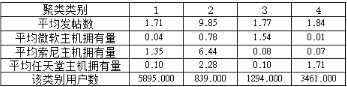
這個表出來以后,基本上可以對我們聚類結果中的每一類人群進行解讀了���。結果測試通過!
Step 13 & 14 & 15:輸出規(guī)則 & 模型加載 & 報告撰寫
這個模型不用回朔到系統(tǒng)中�����,因為僅僅是一個我們用來研究的模型而已����。因此��,輸出規(guī)則和模型加載兩步可以跳過�,直接進入報告撰寫。
聚類模型的結果可歸結為下圖:

眼熟不?在我的第二篇專欄文章第一份數(shù)據報告的誕生 – 一個數(shù)據分析師的自我修養(yǎng) – 知乎專欄 中��,我用這張圖來說明了洞察結論的重要性�,現(xiàn)在你們應該知道這張圖是如何得來的了。
撰寫報告的另外一部分��,在描述統(tǒng)計-洞察結論的過程中已經提到了����,把兩部分放在一次,加上背景����、研究方法等內容�,就是完整的報告啦!
最后附送幾張各類用戶發(fā)帖內容中的關鍵詞詞云圖:

那么�,這篇文章就到此結束了,最后的最后���,公布一下我做這份報告用到的工具:
大家可以看到�,要當一個數(shù)據分析師���,要用到很多類別的工具�,多學一點總是沒有壞處的���,在此與大家共勉�����。
CDA數(shù)據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330