多元線(xiàn)性回歸實(shí)戰(zhàn)筆記
R語(yǔ)言中的線(xiàn)性回歸函數(shù)比較簡(jiǎn)單����,就是lm(),比較復(fù)雜的是對(duì)線(xiàn)性模型的診斷和調(diào)整。這里結(jié)合Statistical Learning和杜克大學(xué)的Data Analysis and Statistical Inference的章節(jié)以及《R語(yǔ)言實(shí)戰(zhàn)》的OLS(Ordinary Least Square)回歸模型章節(jié)來(lái)總結(jié)一下����,診斷多元線(xiàn)性回歸模型的操作分析步驟���。
1����、選擇預(yù)測(cè)變量
因變量比較容易確定,多元回歸模型中難在自變量的選擇���。自變量選擇主要可分為向前選擇(逐次加使RSS最小的自變量)��,向后選擇(逐次扔掉p值最大的變量)�。個(gè)人傾向于向后選擇法�����,一來(lái)p值比較直觀���,模型返回結(jié)果直接給出了各變量的p值�,卻沒(méi)有直接給出RSS��;二來(lái)當(dāng)自變量比較多時(shí)�����,一個(gè)個(gè)加比較麻煩�����。
-
Call:
-
lm(formula=Sales~.+Income:Advertising+Age:Price,data=Carseats)
-
-
Residuals:
-
Min1QMedian3QMax
-
-2.9208-0.75030.01770.67543.3413
-
-
Coefficients:
-
EstimateStd.Errort valuePr(>|t|)
-
(Intercept)6.57556541.00874706.5192.22e-10***
-
CompPrice0.09293710.004118322.567<2e-16***
-
Income0.01089400.00260444.1833.57e-05***
-
Advertising0.07024620.02260913.1070.002030**
-
Population0.00015920.00036790.4330.665330
-
Price-0.10080640.0074399-13.549<2e-16***
-
ShelveLocGood4.84867620.152837831.724<2e-16***
-
ShelveLocMedium1.95326200.125768215.531<2e-16***
-
Age-0.05794660.0159506-3.6330.000318***
-
Education-0.02085250.0196131-1.0630.288361
-
UrbanYes0.14015970.11240191.2470.213171
-
USYes-0.15755710.1489234-1.0580.290729
-
Income:Advertising0.00075100.00027842.6980.007290**
-
Price:Age0.00010680.00013330.8010.423812
-
---
-
Signif.codes:0‘***’0.001‘**’0.01‘*’0.05‘.’0.1‘’1
-
-
Residualstandard error:1.011on386degrees of freedom
-
MultipleR-squared:0.8761,AdjustedR-squared:0.8719
-
F-statistic:210on13and386DF,p-value:<2.2e-16
構(gòu)建一個(gè)回歸模型后��,先看F統(tǒng)計(jì)量的p值,這是對(duì)整個(gè)模型的假設(shè)檢驗(yàn)��,原假設(shè)是各系數(shù)都為0����,如果連這個(gè)p值都不顯著,無(wú)法證明至少有一個(gè)自變量對(duì)因變量有顯著性影響����,這個(gè)模型便不成立����。然后看Adjusted R2,每調(diào)整一次模型�,應(yīng)該力使它變大;Adjusted R2越大說(shuō)明模型中相關(guān)的自變量對(duì)因變量可解釋的變異比例越大�,模型的預(yù)測(cè)性就越好。
構(gòu)建了線(xiàn)性模型后�,如果是一元線(xiàn)性回歸,可以畫(huà)模型圖初步判斷一下線(xiàn)性關(guān)系(多元回歸模型不好可視化):
-
par(mfrow=c(1,1))
-
plot(medv~lstat,Boston)
-
fit1=lm(medv~lstat,data=Boston)
-
abline(fit1,col="red")
性回歸</a>擬合直線(xiàn)圖")
2�、模型診斷
確定了回歸模型的自變量并初步得到一個(gè)線(xiàn)性回歸模型,并不是直接可以拿來(lái)用的����,還要進(jìn)行驗(yàn)證和診斷�。診斷之前�����,先回顧多元線(xiàn)性回歸模型的假設(shè)前提(by Data Analysis and Statistical Inference):
-
(數(shù)值型)自變量要與因變量有線(xiàn)性關(guān)系��;
-
殘差基本呈正態(tài)分布�����;
-
殘差方差基本不變(同方差性)�����;
-
殘差(樣本)間相關(guān)獨(dú)立����。
一個(gè)好的多元線(xiàn)性回歸模型應(yīng)當(dāng)盡量滿(mǎn)足這4點(diǎn)假設(shè)前提。
用lm()構(gòu)造一個(gè)線(xiàn)性模型fit后��,plot(fit)即可返回4張圖(可以par(mfrow=c(2,2))一次展現(xiàn))���,這4張圖可作初步檢驗(yàn):

左上圖用來(lái)檢驗(yàn)假設(shè)1����,如果散點(diǎn)看不出什么規(guī)律,則表示線(xiàn)性關(guān)系良好��,若有明顯關(guān)系�,則說(shuō)明非線(xiàn)性關(guān)系明顯。右上圖用來(lái)檢驗(yàn)假設(shè)2���,若散點(diǎn)大致都集中在QQ圖中的直線(xiàn)上���,則說(shuō)明殘差正態(tài)性良好。左下圖用來(lái)檢驗(yàn)假設(shè)3����,若點(diǎn)在曲線(xiàn)周?chē)S機(jī)分布���,則可認(rèn)為假設(shè)3成立�;若散點(diǎn)呈明顯規(guī)律���,比如方差隨均值而增大�����,則越往右的散點(diǎn)上下間距會(huì)越大�,方差差異就越明顯。假設(shè)4的獨(dú)立性無(wú)法通過(guò)這幾張圖來(lái)檢驗(yàn)���,只能通過(guò)數(shù)據(jù)本身的來(lái)源的意義去判斷�。
右下圖是用來(lái)檢驗(yàn)異常值���。異常值與三個(gè)概念有關(guān):
離群點(diǎn):y遠(yuǎn)離散點(diǎn)主體區(qū)域的點(diǎn)
杠桿點(diǎn):x遠(yuǎn)離散點(diǎn)主體區(qū)域的點(diǎn)��,一般不影響回歸直線(xiàn)的斜率
強(qiáng)影響點(diǎn):影響回歸直線(xiàn)的斜率����,一般是高杠桿點(diǎn)���。
對(duì)于多元線(xiàn)性回歸���,高杠桿點(diǎn)不一定就是極端點(diǎn),有可能是各個(gè)變量的取值都正常�����,但仍然偏離散點(diǎn)主體��。
對(duì)于異常值���,可以謹(jǐn)慎地刪除�,看新的模型是否效果更好。
《R語(yǔ)言實(shí)戰(zhàn)》里推薦了更好的診斷方法���,總結(jié)如下����。
gvlma包的gvlma()函數(shù)可對(duì)擬合模型的假設(shè)作綜合驗(yàn)證���,并對(duì)峰度�����、偏度進(jìn)行驗(yàn)證��。
-
states<-as.data.frame(state.x77[,c("Murder","Population",
-
"Illiteracy","Income","Frost")])
-
fit<-lm(Murder~Population+Illiteracy+Income+
-
Frost,data=states)
-
library(gvlma)
-
gvmodel<-gvlma(fit)
-
summary(gvmodel)
-
-
Call:
-
lm(formula=Murder~Population+Illiteracy+Income+Frost,data=states)
-
-
Residuals:
-
Min1QMedian3QMax
-
-4.7960-1.6495-0.08111.48157.6210
-
-
Coefficients:
-
EstimateStd.Errort valuePr(>|t|)
-
(Intercept)1.235e+003.866e+000.3190.7510
-
Population2.237e-049.052e-052.4710.0173*
-
Illiteracy4.143e+008.744e-014.7382.19e-05***
-
Income6.442e-056.837e-040.0940.9253
-
Frost5.813e-041.005e-020.0580.9541
-
---
-
Signif.codes:0‘***’0.001‘**’0.01‘*’0.05‘.’0.1‘’1
-
-
Residualstandard error:2.535on45degrees of freedom
-
MultipleR-squared:0.567,AdjustedR-squared:0.5285
-
F-statistic:14.73on4and45DF,p-value:9.133e-08
-
-
-
ASSESSMENT OF THE LINEAR MODEL ASSUMPTIONS
-
USING THE GLOBAL TEST ON4DEGREES-OF-FREEDOM:
-
LevelofSignificance=0.05
-
-
Call:
-
gvlma(x=fit)
-
-
Valuep-valueDecision
-
GlobalStat2.77280.5965Assumptionsacceptable.
-
Skewness1.53740.2150Assumptionsacceptable.
-
Kurtosis0.63760.4246Assumptionsacceptable.
-
LinkFunction0.11540.7341Assumptionsacceptable.
-
Heteroscedasticity0.48240.4873Assumptionsacceptable.
最后的Global Stat是對(duì)4個(gè)假設(shè)條件進(jìn)行綜合驗(yàn)證��,通過(guò)了即表示4個(gè)假設(shè)驗(yàn)證都通過(guò)了。最后的Heterosceasticity是進(jìn)行異方差檢測(cè)�����。注意這里假設(shè)檢驗(yàn)的原假設(shè)都是假設(shè)成立���,所以當(dāng)p>0.05時(shí)�����,假設(shè)才能能過(guò)驗(yàn)證����。
如果綜合驗(yàn)證不通過(guò),也有其他方法對(duì)4個(gè)假設(shè)條件分別驗(yàn)證:
線(xiàn)性假設(shè)
library(car)
crPlots(fit)
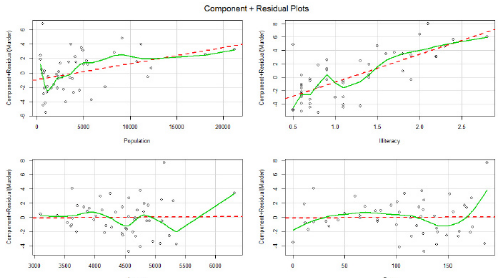
返回的圖是各個(gè)自變量與殘差(因變量)的線(xiàn)性關(guān)系圖���,若存著明顯的非線(xiàn)性關(guān)系��,則需要對(duì)自變量作非線(xiàn)性轉(zhuǎn)化��。書(shū)中說(shuō)這張圖表明線(xiàn)性關(guān)系良好�����。
正態(tài)性
-
library(car)
-
qqPlot(fit,labels=row.names(states),id.method="identify",simulate=TRUE,main="Q-Q Plot")
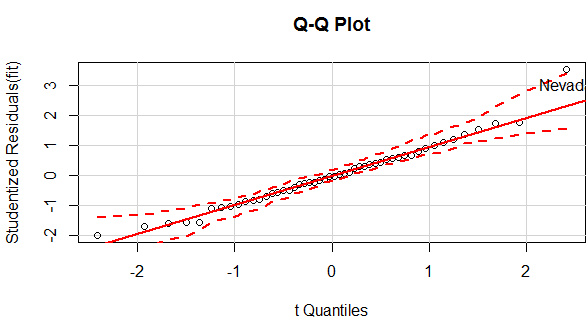
qqPlot()可以生成交互式的qq圖��,選中異常點(diǎn)�,就返回該點(diǎn)的名稱(chēng)����。該圖中除了Nevad點(diǎn)��,其他點(diǎn)都在直線(xiàn)附近�,可見(jiàn)正態(tài)性良好���。
同方差性
-
library(car)
-
ncvTest(fit)
-
-
Non-constantVarianceScoreTest
-
Varianceformula:~fitted.values
-
Chisquare=1.746514Df=1p=0.1863156
p值大于0.05��,可認(rèn)為滿(mǎn)足方差相同的假設(shè)��。
獨(dú)立性
-
library(car)
-
durbinWatsonTest(fit)
-
-
lagAutocorrelationD-WStatisticp-value
-
1-0.20069292.3176910.258
-
Alternativehypothesis:rho!=0
p值大于0.05�����,可認(rèn)為誤差之間相互獨(dú)立���。
除了以上4點(diǎn)基本假設(shè),還有其他方面需要進(jìn)行診斷�����。
(2)多重共線(xiàn)性
理想中的線(xiàn)性模型各個(gè)自變量應(yīng)該是線(xiàn)性無(wú)關(guān)的����,若自變量間存在共線(xiàn)性��,則會(huì)降低回歸系數(shù)的準(zhǔn)確性。一般用方差膨脹因子VIF(Variance Inflation Factor)來(lái)衡量共線(xiàn)性�,《統(tǒng)計(jì)學(xué)習(xí)》中認(rèn)為VIF超過(guò)5或10就存在共線(xiàn)性,《R語(yǔ)言實(shí)戰(zhàn)》中認(rèn)為VIF大于4則存在共線(xiàn)性���。理想中的線(xiàn)性模型VIF=1���,表完全不存在共線(xiàn)性。
-
library(car)
-
vif(fit)
-
-
PopulationIlliteracyIncomeFrost
-
1.2452822.1658481.3458222.082547
可見(jiàn)這4個(gè)自變量VIF都比較小�����,可認(rèn)為不存在多重共線(xiàn)性的問(wèn)題��。
(3)異常值檢驗(yàn)
離群點(diǎn)
離群點(diǎn)有三種判斷方法:一是用qqPlot()畫(huà)QQ圖���,落在置信區(qū)間(上圖中兩條虛線(xiàn))外的即可認(rèn)為是離群點(diǎn)��,如上圖中的Nevad點(diǎn)���;一種是判斷學(xué)生標(biāo)準(zhǔn)化殘差值,絕對(duì)值大于2(《R語(yǔ)言實(shí)戰(zhàn)》中認(rèn)為2�����,《統(tǒng)計(jì)學(xué)習(xí)》中認(rèn)為3)的可認(rèn)為是離群點(diǎn)。
plot(x=fitted(fit),y=rstudent(fit))
abline(h=3,col="red",lty=2)
abline(h=-3,col="red",lty=2)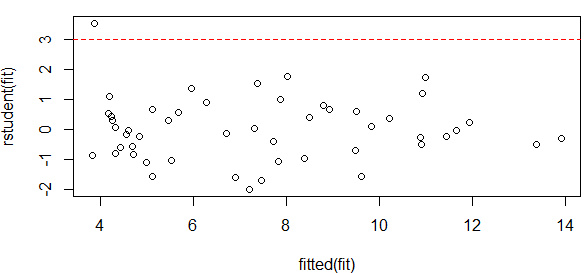
-
which(abs(rstudent(fit))>3)
-
Nevada
-
28
還有一種方法是利用car包里的outlierTest()函數(shù)進(jìn)行假設(shè)檢驗(yàn):
-
library(car)
-
outlierTest(fit)
-
-
rstudent unadjusted p-valueBonferonnip
-
Nevada3.5429290.000950880.047544
這個(gè)函數(shù)用來(lái)檢驗(yàn)最大的標(biāo)準(zhǔn)化殘差值�,如果p>0.05,可以認(rèn)為沒(méi)有離群點(diǎn)�;若p<0.05,則該點(diǎn)是離群點(diǎn)��,但不能說(shuō)明只有一個(gè)離群點(diǎn)�����,可以把這個(gè)點(diǎn)刪除之后再作檢驗(yàn)�。第三種方法可以與第二種方法結(jié)合起來(lái)使用。
高杠桿點(diǎn)
高杠桿值觀測(cè)點(diǎn)���,即是與其他預(yù)測(cè)變量有關(guān)的離群點(diǎn)��。換句話(huà)說(shuō)�,它們是由許多異常的預(yù)測(cè)變量值組合起來(lái)的�����,與響應(yīng)變量值沒(méi)有關(guān)系�����?�!督y(tǒng)計(jì)學(xué)習(xí)》中給出了一個(gè)杠桿統(tǒng)計(jì)量��,《R語(yǔ)言實(shí)戰(zhàn)》中給出了一種具體的操作方法���。(兩本書(shū)也稍有出入�,《統(tǒng)計(jì)學(xué)習(xí)》中平均杠桿值為(p+1)/n�����,而在《R語(yǔ)言實(shí)戰(zhàn)》中平均杠桿值為p/n�;事實(shí)上在樣本量n比較大時(shí),幾乎沒(méi)有差別�。)
-
hat.plot<-function(fit){
-
p<-length(coefficients(fit))
-
n<-length(fitted(fit))
-
plot(hatvalues(fit),main="Index Plot of Hat Values")
-
abline(h=c(2,3)*p/n,col="red",lty=2)
-
identify(1:n,hatvalues(fit),names(hatvalues(fit)))
-
#這句產(chǎn)生交互效果,選中某個(gè)點(diǎn)后����,關(guān)閉后返回點(diǎn)的名稱(chēng)
-
}
-
hat.plot(fit)
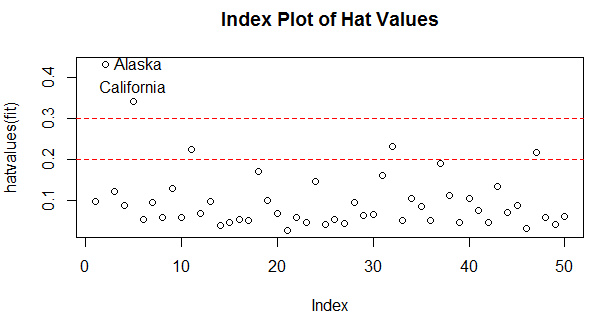
超過(guò)2倍或3倍的平均杠桿值即可認(rèn)為是高杠桿點(diǎn),這里把Alaska和California作為高杠桿點(diǎn)���。
強(qiáng)影響點(diǎn)
強(qiáng)影響點(diǎn)是那種若刪除則模型的系數(shù)會(huì)產(chǎn)生明顯的變化的點(diǎn)���。一種方法是計(jì)算Cook距離���,一般來(lái)說(shuō), Cook’s D值大于4/(n-k -1)�,則表明它是強(qiáng)影響點(diǎn),其中n 為樣本量大小�, k 是預(yù)測(cè)變量數(shù)目。
-
cutoff<-4/(nrow(states-length(fit$coefficients)-2))
-
#coefficients加上了截距項(xiàng)�,因此要多減1
-
plot(fit,which=4,cook.levels=cutoff)
-
abline(h=cutoff,lty=2,col="red")
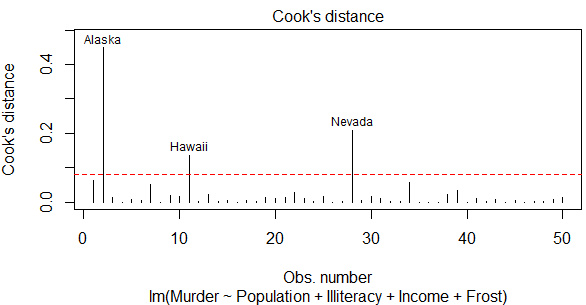
實(shí)際上這就是前面診斷的4張圖之一,語(yǔ)句還是plot(fit)�,which=4表示指定第4張圖,cook.levels可設(shè)定標(biāo)準(zhǔn)值��。紅色虛線(xiàn)以上就返回了強(qiáng)影響點(diǎn)����。
car包里的influencePlot()函數(shù)能一次性同時(shí)檢查離群點(diǎn)、高杠桿點(diǎn)�、強(qiáng)影響點(diǎn)。
-
library(car)
-
influencePlot(fit,id.method="identity",main="Influence Plot",sub="Circle size is proportional to Cook's distance")
-
-
StudResHatCookD
-
Alaska1.7536920.432473190.4480510
-
Nevada3.5429290.095089770.2099157

縱坐標(biāo)超過(guò)+2或小于-2的點(diǎn)可被認(rèn)為是離群點(diǎn)����,水平軸超過(guò)0.2或0.3的州有高杠桿值(通常為預(yù)測(cè)值的組合)。圓圈大小與影響成比例����,圓圈很大的點(diǎn)可能是對(duì)模型參數(shù)的估計(jì)造成的不成比例影響的強(qiáng)影響點(diǎn)�����。
3����、模型調(diào)整
到目前為止��,《統(tǒng)計(jì)學(xué)習(xí)》中提到的多元線(xiàn)性回歸模型潛在的問(wèn)題���,包括4個(gè)假設(shè)不成立、異常值��、共線(xiàn)性的診斷方法在上面已經(jīng)全部得到解決����。這里總結(jié)、延伸《R語(yǔ)言實(shí)戰(zhàn)》里提到的調(diào)整方法——
刪除觀測(cè)點(diǎn)
對(duì)于異常值一個(gè)最簡(jiǎn)單粗暴又高效的方法就是直接刪除�����,不過(guò)有兩點(diǎn)要注意�。一是當(dāng)數(shù)據(jù)量大的時(shí)候可以這么做�,若數(shù)據(jù)量較小則應(yīng)慎重��;二是根據(jù)數(shù)據(jù)的意義判斷���,若明顯就是錯(cuò)誤就可以直接刪除�,否則需判斷是否會(huì)隱藏著深層的現(xiàn)象��。
另外刪除觀測(cè)點(diǎn)后要與刪除之前的模型作比較����,看模型是否變得更好。
變量變換

在進(jìn)行非線(xiàn)性變換之前��,先看看4個(gè)假設(shè)是否成立��,如果成立可以不用變換����;沒(méi)必要追求更好的擬合效果而把模型搞得太復(fù)雜,這有可能出現(xiàn)過(guò)擬合現(xiàn)象����。如果連假設(shè)檢驗(yàn)都不通過(guò),可以通過(guò)變量變換來(lái)調(diào)整模型�。這里只討論線(xiàn)性關(guān)系不佳的情況��,其他情況遇到了再說(shuō)��。
(1)多項(xiàng)式回歸
如果殘差圖中呈現(xiàn)明顯的非線(xiàn)性關(guān)系����,可以考慮對(duì)自變量進(jìn)行多項(xiàng)式回歸�����。舉一個(gè)例子:
-
library(MASS)
-
library(ISLR)
-
fit1=lm(medv~lstat,data=Boston)
-
plot(fit1,which=1)
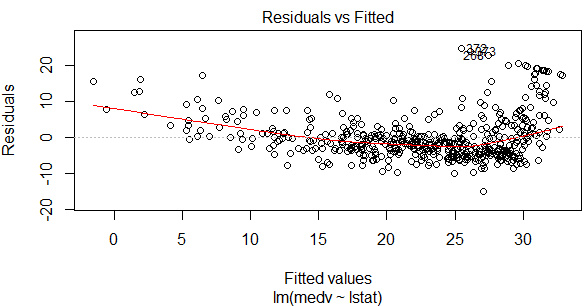
可以看到這個(gè)一元線(xiàn)性回歸模型的殘差圖中�,散點(diǎn)的規(guī)律還是比較明顯�����,說(shuō)明線(xiàn)性關(guān)系較弱��。
-
fit1_1<-lm(medv~poly(lstat,2),data=Boston)
-
plot(fit1_1,which=1)

將自變量進(jìn)行2次多項(xiàng)式回歸后�,發(fā)現(xiàn)現(xiàn)在的殘差圖好多了,散點(diǎn)基本無(wú)規(guī)律�,線(xiàn)性關(guān)系較明顯。
再看看兩個(gè)模型的整體效果——
-
summary(fit1)

-
summary(fit1_1)

可見(jiàn)多項(xiàng)式回歸的模型Adjusted R2也增大了���,模型的解釋性也變強(qiáng)了����。
多項(xiàng)式回歸在《統(tǒng)計(jì)學(xué)習(xí)》后面的非線(xiàn)性模型中還會(huì)提到,到時(shí)候再討論�����。
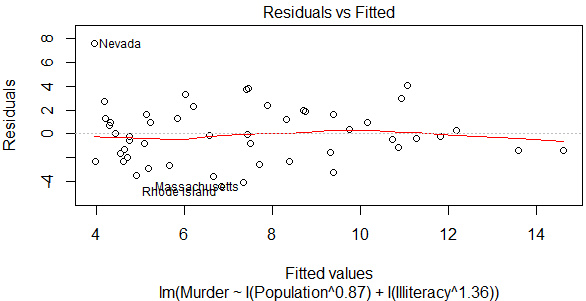
(2)Box-Tidwell變換
car包中的boxTidwell() 函數(shù)通過(guò)獲得預(yù)測(cè)變量?jī)鐢?shù)的最大似然估計(jì)來(lái)改善線(xiàn)性關(guān)系��。
-
library(car)
-
boxTidwell(Murder~Population+Illiteracy,data=states)
-
-
ScoreStatisticp-value MLE oflambda
-
Population-0.32280030.74684650.8693882
-
Illiteracy0.61938140.53566511.3581188
-
-
iterations=19
-
#這里看lambda�����,表示各個(gè)變量的冪次數(shù)
-
lmfit<-lm(Murder~Population+Illiteracy,data=states)
-
lmfit2<-lm(Murder~I(Population^0.87)+I(Illiteracy^1.36),data=states)
-
plot(lmfit,which=1)
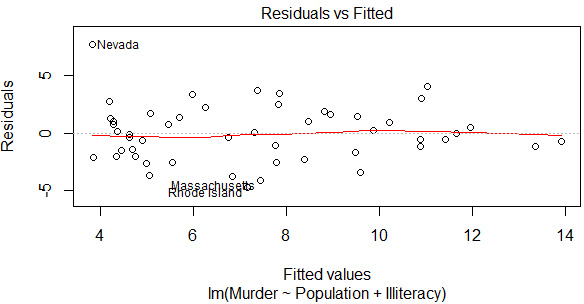
-
plot(lmfit2,which=1)
-
summary(lmfit)

-
summary(lmfit2)

可以發(fā)現(xiàn)殘差圖和Adjusted R2的提升都甚微��,因此沒(méi)有必要作非線(xiàn)性轉(zhuǎn)換��。
4����、模型分析
(1)模型比較
前面只是簡(jiǎn)單得用Adjusted R2來(lái)比較模型,《R語(yǔ)言實(shí)戰(zhàn)》里介紹了可以用方差分析來(lái)比較嵌套模型(即它的一些項(xiàng)完全包含在另一個(gè)模型中)有沒(méi)有顯著性差異����。方差分析的思想是:如果線(xiàn)性模型y~x1+x2+x3與y~x1+x2沒(méi)有顯著性差異,若同時(shí)x3變量對(duì)模型也不顯著,那就沒(méi)必要加上變量x3��。下面進(jìn)行試驗(yàn):
-
aovfit1<-lm(Murder~Population+Illiteracy+Income+Frost,data=states)
-
aovfit2<-lm(Murder~Population+Illiteracy,data=states)
-
anova(aovfit1,aovfit2)
-
-
AnalysisofVarianceTable
-
-
Model1:Murder~Population+Illiteracy+Income+Frost
-
Model2:Murder~Population+Illiteracy
-
Res.DfRSSDfSumofSqFPr(>F)
-
145289.17
-
247289.25-2-0.0785050.00610.9939
-
-
summary(aovfit1)
-
-
Coefficients:
-
EstimateStd.Errort valuePr(>|t|)
-
(Intercept)1.235e+003.866e+000.3190.7510
-
Population2.237e-049.052e-052.4710.0173*
-
Illiteracy4.143e+008.744e-014.7382.19e-05***
-
Income6.442e-056.837e-040.0940.9253
-
Frost5.813e-041.005e-020.0580.9541
-
-
Residualstandard error:2.535on45degrees of freedom
-
MultipleR-squared:0.567,AdjustedR-squared:0.5285
-
F-statistic:14.73on4and45DF,p-value:9.133e-08
-
-
summary(aovfit2)
-
-
Coefficients:
-
EstimateStd.Errort valuePr(>|t|)
-
(Intercept)1.652e+008.101e-012.0390.04713*
-
Population2.242e-047.984e-052.8080.00724**
-
Illiteracy4.081e+005.848e-016.9788.83e-09***
-
-
Residualstandard error:2.481on47degrees of freedom
-
MultipleR-squared:0.5668,AdjustedR-squared:0.5484
-
F-statistic:30.75on2and47DF,p-value:2.893e-09
Income和Frost兩個(gè)變量不顯著��,兩個(gè)模型之間沒(méi)有顯著性差異�,就可以不加這兩個(gè)變量。刪去這兩個(gè)不顯著的變量后��,R2略微減少��,Adjusted R2增大�����,這也符合二者的定義����。
《R語(yǔ)言實(shí)戰(zhàn)》里還介紹到了用AIC(Akaike Information Criterion��,赤池信息準(zhǔn)則)值來(lái)比較模型���,AIC值越小的模型優(yōu)先選擇�����,原理不明���。
-
aovfit1<-lm(Murder~Population+Illiteracy+Income+Frost,data=states)
-
aovfit2<-lm(Murder~Population+Illiteracy,data=states)
-
AIC(aovfit1,aovfit2)
-
-
df AIC
-
aovfit16241.6429
-
aovfit24237.6565
第二個(gè)模型AIC值更小�����,因此選第二個(gè)模型(真是簡(jiǎn)單粗暴)��。注:ANOVA需限定嵌套模型�,AIC則不需要��??梢?jiàn)AIC是更簡(jiǎn)單也更實(shí)用的模型比較方法。
(2)變量選擇
這里的變量選擇與最開(kāi)始的變量選擇同也不同�����,雖然是一回事���,但一開(kāi)始是一個(gè)粗略的變量的選擇���,主要是為了構(gòu)建模型;這里則要進(jìn)行細(xì)致的變量選擇來(lái)調(diào)整模型�。
逐步回歸
前面提到的向前或向后選擇或者是同時(shí)向前向后選擇變量都是逐步回歸法。MASS包中的stepAIC() 函數(shù)可以實(shí)現(xiàn)逐步回歸模型(向前、向后和向前向后)�,依據(jù)的是精確AIC準(zhǔn)則。以下實(shí)例是向后回歸法:
-
library(MASS)
-
aovfit1<-lm(Murder~Population+Illiteracy+Income+Frost,data=states)
-
stepAIC(aovfit1,direction="backward")
-
# “forward”為向前選擇�����,"backward"為向后選擇�,"both"為混合選擇
-
-
Start:AIC=97.75
-
Murder~Population+Illiteracy+Income+Frost
-
-
DfSumofSqRSS AIC
-
-Frost10.021289.1995.753
-
-Income10.057289.2295.759
-
289.1797.749
-
-Population139.238328.41102.111
-
-Illiteracy1144.264433.43115.986
-
-
Step:AIC=95.75
-
Murder~Population+Illiteracy+Income
-
-
DfSumofSqRSS AIC
-
-Income10.057289.2593.763
-
289.1995.753
-
-Population143.658332.85100.783
-
-Illiteracy1236.196525.38123.605
-
-
Step:AIC=93.76
-
Murder~Population+Illiteracy
-
-
DfSumofSqRSS AIC
-
289.2593.763
-
-Population148.517337.7699.516
-
-Illiteracy1299.646588.89127.311
-
-
Call:
-
lm(formula=Murder~Population+Illiteracy,data=states)
-
-
Coefficients:
-
(Intercept)PopulationIlliteracy
-
1.65154970.00022424.0807366
可見(jiàn)原本的4元回歸模型向后退了兩次,最終穩(wěn)定成了2元回歸模型����,與前面模型比較的結(jié)果一致。
全子集回歸
《R語(yǔ)言實(shí)戰(zhàn)》里提到了逐步回歸法的局限:不是每個(gè)模型都評(píng)價(jià)了�����,不能保證選擇的是“最佳”模型�����。比如上例中���,從Murder ~ Population + Illiteracy + Income + Frost到Murder ~ Population + Illiteracy + Income再到Murder~Population+Illiteracy雖然AIC值確實(shí)在減少,但Murder ~ Population + Illiteracy + Frost沒(méi)評(píng)價(jià)����,如果遇到變量很多的情況下���,逐步回歸只沿一個(gè)方向回歸,就有可能錯(cuò)過(guò)最優(yōu)的回歸方向�。
-
library(leaps)
-
leaps<-regsubsets(Murder~Population+Illiteracy+Income+Frost,data=states,nbest=4)
-
plot(leaps,scale="adjr2")
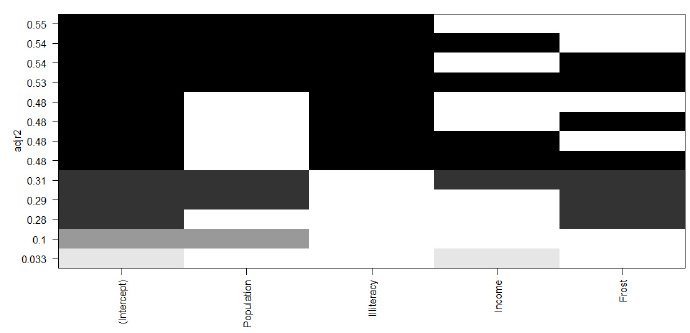
橫坐標(biāo)是變量,縱坐標(biāo)是Adjusted R2���,可見(jiàn)除截距項(xiàng)以外�����,只選定Population和Illiteracy這兩個(gè)變量��,可以使線(xiàn)性模型有最大的Adjusted R2���。
全子集回歸比逐步回歸范圍更廣,模型優(yōu)化效果更好����,但是一旦變量數(shù)多了之后,全子集回歸迭代的次數(shù)就很多����,就會(huì)很慢�����。
事實(shí)上�,變量的選擇不是機(jī)械式地只看那幾個(gè)統(tǒng)計(jì)指標(biāo)���,更主要的是根據(jù)數(shù)據(jù)的實(shí)際意義���,從業(yè)務(wù)角度上來(lái)選擇合適的變量。
線(xiàn)性模型變量的選擇在《統(tǒng)計(jì)學(xué)習(xí)》后面的第6章還會(huì)繼續(xù)講到�,到時(shí)繼續(xù)綜合討論。
(3)交互項(xiàng)
交互項(xiàng)《統(tǒng)計(jì)學(xué)習(xí)》中花了一定篇幅來(lái)描寫(xiě)���,但在《R語(yǔ)言實(shí)戰(zhàn)》是在方差分析章節(jié)中討論�����。添加變量間的交互項(xiàng)有時(shí)可以改善線(xiàn)性關(guān)系�����,提高Adjusted R2���。針對(duì)數(shù)據(jù)的實(shí)際意義,如果兩個(gè)基本上是獨(dú)立的����,也很難產(chǎn)生交互、產(chǎn)生協(xié)同效應(yīng)的變量���,那就不必考慮交互項(xiàng)����;只有從業(yè)務(wù)角度分析��,有可能產(chǎn)生協(xié)同效應(yīng)的變量間才考慮交互項(xiàng)����。
涉及到交互項(xiàng)有一個(gè)原則:如果交互項(xiàng)是顯著的,那么即使變量不顯著����,也要放在回歸模型中;若變量和交互項(xiàng)都不顯著�,則可以都不放。
(4)交叉驗(yàn)證
Andrew Ng的Machine Learning中就提到了����,模型對(duì)舊數(shù)據(jù)擬合得好不一定就對(duì)新數(shù)據(jù)預(yù)測(cè)得好����。因此一個(gè)數(shù)據(jù)集應(yīng)當(dāng)被分兩訓(xùn)練集和測(cè)試集兩部分(或者訓(xùn)練集�����、交叉驗(yàn)證集�����、測(cè)試集三部分)����,訓(xùn)練好的模型還要在新數(shù)據(jù)中測(cè)試性能。
所謂交叉驗(yàn)證�����,即將一定比例的數(shù)據(jù)挑選出來(lái)作為訓(xùn)練樣本�,另外的樣本作保留樣本,先在訓(xùn)練樣本上獲取回歸方程��,然后在保留樣本上做預(yù)測(cè)��。由于保留樣本不涉及模型參數(shù)的選擇,該樣本可獲得比新數(shù)據(jù)更為精確的估計(jì)��。
在k 重交叉驗(yàn)證中����,樣本被分為k個(gè)子樣本��,輪流將k-1個(gè)子樣本組合作為訓(xùn)練集�����,另外1個(gè)子樣本作為保留集�����。這樣會(huì)獲得k 個(gè)預(yù)測(cè)方程�,記錄k 個(gè)保留樣本的預(yù)測(cè)表現(xiàn)結(jié)果,然后求其平均值�。
bootstrap包中的crossval()函數(shù)可以實(shí)現(xiàn)k重交叉驗(yàn)證。
-
shrinkage<-function(fit,k=10){
-
require(bootstrap)
-
# define functions
-
theta.fit<-function(x,y){
-
lsfit(x,y)
-
}
-
theta.predict<-function(fit,x){
-
cbind(1,x)%*%fit$coef
-
}
-
-
# matrix of predictors
-
x<-fit$model[,2:ncol(fit$model)]
-
# vector of predicted values
-
y<-fit$model[,1]
-
-
results<-crossval(x,y,theta.fit,theta.predict,ngroup=k)
-
r2<-cor(y,fit$fitted.values)^2
-
r2cv<-cor(y,results$cv.fit)^2
-
cat("Original R-square =",r2,"\n")
-
cat(k,"Fold Cross-Validated R-square =",r2cv,"\n")
-
cat("Change =",r2-r2cv,"\n")
-
}
這個(gè)自定義的shrinkage()函數(shù)用來(lái)做k重交叉驗(yàn)證�,比計(jì)算訓(xùn)練集和交叉驗(yàn)證集的R方差異。這個(gè)函數(shù)里涉及到一個(gè)概念:復(fù)相關(guān)系數(shù)����。復(fù)相關(guān)系數(shù)實(shí)際上就是y和fitted(y)的簡(jiǎn)單相關(guān)系數(shù)。對(duì)于一元線(xiàn)性回歸�����,R2就是簡(jiǎn)單相關(guān)系數(shù)的平方;對(duì)于多元線(xiàn)性回歸�����,R2是復(fù)相關(guān)系數(shù)的平方�����。這個(gè)我沒(méi)有成功地從公式上推導(dǎo)證明成立�����,就記下吧�。這個(gè)方法用到了自助法的思想,這個(gè)在統(tǒng)計(jì)學(xué)習(xí)后面會(huì)細(xì)致講到���。
-
fit<-lm(Murder~Population+Income+Illiteracy+
-
Frost,data=states)
-
shrinkage(fit)
-
-
OriginalR-square=0.5669502
-
10FoldCross-ValidatedR-square=0.441954
-
Change=0.1249963
可見(jiàn)這個(gè)4元回歸模型在交叉驗(yàn)證集中的R2下降了0.12之多��。若換成前面分析的2元回歸模型——
-
fit2<-lm(Murder~Population+Illiteracy,data=states)
-
shrinkage(fit2)
-
-
OriginalR-square=0.5668327
-
10FoldCross-ValidatedR-square=0.517304
-
Change=0.04952868
這次R2下降只有約0.05����。R2減少得越少,則預(yù)測(cè)得越準(zhǔn)確�。
5、模型應(yīng)用
(1)預(yù)測(cè)
最重要的應(yīng)用毫無(wú)疑問(wèn)就是用建立的模型進(jìn)行預(yù)測(cè)了���。構(gòu)建好模型后��,可用predict()函數(shù)進(jìn)行預(yù)測(cè)——
-
fit2<-lm(Murder~Population+Illiteracy,data=states)
-
predict(fit2,
-
newdata=data.frame(Population=c(2000,3000),Illiteracy=c(1.7,2.2)),
-
interval="confidence")
-
-
fit lwr upr
-
19.0371748.00491110.06944
-
211.3017299.86685112.73661
這里newdata提供了兩個(gè)全新的點(diǎn)供模型來(lái)預(yù)測(cè)�。還可以用interval指定返回置信區(qū)間(confidence)或者預(yù)測(cè)區(qū)間(prediction)��,這也反映了統(tǒng)計(jì)與機(jī)器學(xué)習(xí)的一個(gè)差異——可解釋性�。注意置信區(qū)間考慮的是平均值�,而預(yù)測(cè)區(qū)間考慮的是單個(gè)觀測(cè)值,所以預(yù)測(cè)區(qū)間永遠(yuǎn)比置信區(qū)間廣����,因此預(yù)測(cè)區(qū)間考慮了單個(gè)觀測(cè)值的不可約誤差;而平均值同時(shí)也把不可約誤差給抵消掉了����。
(2)相對(duì)重要性
有的時(shí)候需要解釋模型中各個(gè)自變量對(duì)因變量的重要程度,簡(jiǎn)單處理可以直接看系數(shù)即可���,《R語(yǔ)言實(shí)戰(zhàn)》里自定義了一個(gè)relweights()函數(shù)可以計(jì)算各個(gè)變量的權(quán)重:
-
relweights<-function(fit,...){
-
R<-cor(fit$model)
-
nvar<-ncol(R)
-
rxx<-R[2:nvar,2:nvar]
-
rxy<-R[2:nvar,1]
-
svd<-eigen(rxx)
-
evec<-svd$vectors
-
ev<-svd$values
-
delta<-diag(sqrt(ev))
-
-
# correlations between original predictors and new orthogonal variables
-
lambda<-evec%*%delta%*%t(evec)
-
lambdasq<-lambda^2
-
-
# regression coefficients of Y on orthogonal variables
-
beta<-solve(lambda)%*%rxy
-
rsquare<-colSums(beta^2)
-
rawwgt<-lambdasq%*%beta^2
-
import<-(rawwgt/rsquare)*100
-
lbls<-names(fit$model[2:nvar])
-
rownames(import)<-lbls
-
colnames(import)<-"Weights"
-
-
# plot results
-
barplot(t(import),names.arg=lbls,ylab="% of R-Square",
-
xlab="Predictor Variables",main="Relative Importance of Predictor Variables",
-
sub=paste("R-Square = ",round(rsquare,digits=3)),
-
...)
-
return(import)
-
}
不要在意算法原理和代碼邏輯這種細(xì)節(jié)��,直接看結(jié)果:
-
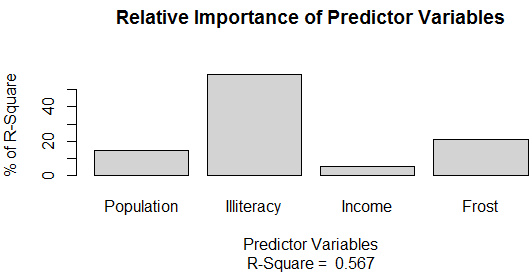
fit<-lm(Murder~Population+Illiteracy+Income+
-
Frost,data=states)
-
relweights(fit,col="lightgrey")
-
-
Weights
-
Population14.723401
-
Illiteracy59.000195
-
Income5.488962
-
Frost20.787442
-
fit$coefficients
-
-
(Intercept)PopulationIlliteracyIncomeFrost
-
1.23456341120.00022367544.14283659030.00006442470.0005813055
-
-
barplot(fit$coefficients[2:5])
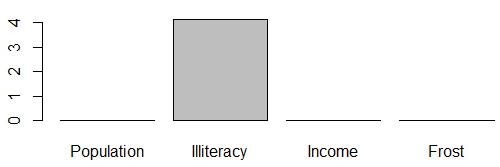
在本例中�,相對(duì)權(quán)重與系數(shù)的排序結(jié)果一致。推薦用相對(duì)權(quán)重�。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情���;
? 想學(xué)習(xí)CDA考試教材���,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫(kù)�,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情;
? 想了解CDA考試含金量��,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330