使用R進(jìn)行統(tǒng)計分析—假設(shè)檢驗(yàn)
假設(shè)檢驗(yàn)是統(tǒng)計學(xué)中的一種推斷方法��,用來判斷兩個樣本或總體間的差異是由于抽樣誤差引起的還是本質(zhì)差別造成的。R語言中提供了很多假設(shè)檢驗(yàn)函數(shù)��,如F檢驗(yàn)����,t檢驗(yàn)和卡方檢驗(yàn)等等。本篇文章介紹如何使用R語言中的這些函數(shù)進(jìn)行假設(shè)檢驗(yàn)���。
二項(xiàng)分布檢驗(yàn)
假設(shè)一個廣告的點(diǎn)擊率為0.02���,更換新的廣告創(chuàng)意后1000次曝光獲得了23次點(diǎn)擊,新廣告在點(diǎn)擊率上是否明顯優(yōu)于老廣告�����?
H0:新廣告與老廣告效果無差異
H1:新廣告效果優(yōu)于老廣告
#老廣告點(diǎn)擊率0.02�����,新廣告1000次廣告曝光獲得23次點(diǎn)擊是否明顯優(yōu)于老廣告binom.test(x =23,n = 1000,p = 0.02,alternative ="greater",conf.level = 0.95 )
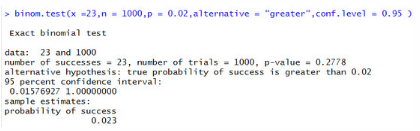
p-value = 0.2778>0.05��,在0.95的置信區(qū)間下接受原假設(shè)H0���。新廣告與老廣告在點(diǎn)擊率上沒有顯著差異���。
#1000次訪問0.02點(diǎn)擊率下差異顯著的臨界值qbinom(p = 0.95,size = 1000,prob = 0.02)
[1] 28
新廣告在1000次廣告曝光中點(diǎn)擊量需要提升到28次以上才能明顯優(yōu)于老廣告的效果。
泊松分布檢驗(yàn)
假設(shè)一次市場推廣活動中前一個小時有50人注冊���,后一個小時有60人注冊���,后一小時的注冊人數(shù)是否明顯高于前一小時?
H0:前一小時與后一小時注冊人數(shù)無差異
H1:后一小時注冊用戶數(shù)量高于前一小時
#上一小時50人注冊����,下一小時60人注冊,后一小時是否顯著高于前一小時poisson.test(x = 60,T = 50,alternative ="greater",conf.level = 0.95)
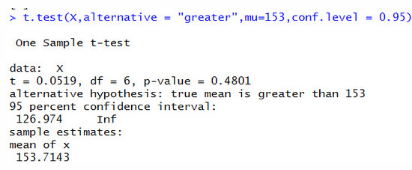
p-value = 0.09227>0.05�,在0.95的置信區(qū)間下接受原假設(shè)H0,后一小時注冊人數(shù)與前一小時無差異����。
#與上一小時50人注冊差異顯著的臨界值
qpois(0.95,lambda=50)
[1] 62
后一小時的注冊用戶數(shù)需要提升到62以上才能明顯高于前一小時的注冊用戶數(shù)。
單樣本t檢驗(yàn)
假設(shè)某流量渠道的目標(biāo)是每日帶來150個咨詢�,在過去的一周帶來的咨詢用戶數(shù)量分別為229,164,121,137,145,127,123,我們是否能認(rèn)為該渠道已經(jīng)達(dá)到目標(biāo)��,即每日的平均咨詢量大于150�����?
這里使用單樣本t檢驗(yàn),首先建立假設(shè)�����。
H0:每日平均咨詢量不大于153����,未達(dá)到目標(biāo)。
H1:每日平均咨詢量大于153���,達(dá)到目標(biāo)��。
#將過去一周咨詢用戶數(shù)量賦給XX=c(229,164,121,137,155,127,143)#計算過去一周咨詢量的均值mean(X)
[1] 153.7143
#過去一周咨詢用戶數(shù)量是否達(dá)到目標(biāo)
t.test(X,alternative ="greater",mu=153,conf.level = 0.95)
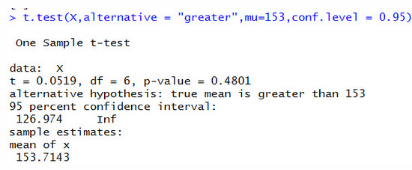
p-value = 0.4801>0.05��,在0.95的置信區(qū)間下接受原假設(shè)H0���,流量渠道的咨詢量沒有達(dá)到目標(biāo)。
雙樣本t檢驗(yàn)
假設(shè)兩個流量渠道在過去的一周分布為網(wǎng)站帶來咨詢用戶����,這兩個流量渠道帶來的咨詢用戶數(shù)量是否有顯著差異?
這里使用雙樣本t檢驗(yàn)����,首先建立假設(shè)���。
H0:兩個流量渠道帶來的咨詢用戶數(shù)量沒有顯著差異。
H1:兩個流量渠道帶來的咨詢用戶數(shù)量存在有顯著差異�����。
#流量渠道1帶來的咨詢用戶數(shù)量賦值給
XX=c(229,164,121,137,155,127,143)
#流量渠道2帶來的咨詢用戶數(shù)量賦值給
YY=c(175,120,187,144,117,184,135)
進(jìn)行雙樣本t檢驗(yàn)之前先進(jìn)行方差檢驗(yàn)��,確定兩組樣本方差是否相同����。 H0:兩個總體方差相同 H1:兩個總體方差不同
#方差檢驗(yàn)����,確定兩個流量渠道的咨詢量是否相同
var.test(x = X,y = Y,conf.level =0.95)

p-value = 0.6469>0.05,在0.95的置信區(qū)間下接受原假設(shè)H0��,兩個總體方差相同����。進(jìn)行等方差t檢驗(yàn)。
#等方差t檢驗(yàn)�����,兩個流量渠道帶來的咨詢用戶數(shù)量是否有差異
t.test(X,Y,var.equal=TRUE,alternative ="two.sided")
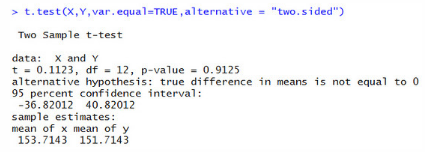
p-value = 0.9125>0.05,接受原假設(shè)H0�,在0.95的置信區(qū)間下兩個流量渠道的咨詢用戶量沒有顯著差異。
成對樣本t檢驗(yàn)
假設(shè)網(wǎng)站對咨詢流程進(jìn)行了優(yōu)化并進(jìn)行了測試���,那么改版后的效果是否明顯優(yōu)于改版前����?
這里使用成對t檢驗(yàn)����,首先建立假設(shè)。
H0:改版后的效果與改版前無差異
H1:改版后的效果明顯優(yōu)于改版前
#改版前注冊用戶量賦給before
before=c(229,164,121,137,155,127,143)
#改版后注冊用戶量賦給after
after=c(217,284,155,190,158,170,180)
#改版前的咨詢量是否小于改版后的咨詢量
t.test(before-after,alternative ="less",conf.level = 0.95)

p-value = 0.02362<0.05����,拒絕原假設(shè)H0,接受備擇假設(shè)H1�����。在0.95的置信區(qū)間下改版后的效果明顯優(yōu)于改版前��。
卡方檢驗(yàn)
假設(shè)廣告創(chuàng)意A1315次訪問����,65次轉(zhuǎn)化�,轉(zhuǎn)化率4.94%�,廣告創(chuàng)意B939次訪問,54次轉(zhuǎn)化����,轉(zhuǎn)化率5.75%。廣告創(chuàng)意B的效果是否優(yōu)于廣告創(chuàng)意A��?
這里使用卡方檢驗(yàn)�����,首先建立假設(shè)�����。
H0:兩個廣告創(chuàng)意的效果無差異
H1:廣告創(chuàng)意B的效果優(yōu)于廣告創(chuàng)意A
對源數(shù)據(jù)近整理�����,廣告創(chuàng)意A1250次未購買��,65次購買�,廣告創(chuàng)意B885次未購買,54次購買���。以此建立列聯(lián)表���。
#創(chuàng)建列聯(lián)表X=c(1250,885,65,54)
dim(X)=c(2,2)
X

#使用卡方檢驗(yàn)chisq.test(X,correct =FALSE)
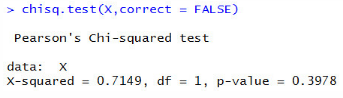
p-value = 0.3978>0.05,在0.95的置信區(qū)間下接受原假設(shè)H0�����,兩個廣告創(chuàng)意效果沒有顯著差異�。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學(xué)習(xí)CDA考試教材���,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫�����,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量����,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330