機(jī)器學(xué)習(xí)算法復(fù)習(xí)--隨機(jī)森林
決策樹這種算法有著很多良好的特性�����,比如說訓(xùn)練時間復(fù)雜度較低����,預(yù)測的過程比較快速,模型容易展示(容易將得到的決策樹做成圖片展示出來)等����。但是同時, 單決策樹又有一些不好的地方�,比如說容易o(hù)ver-fitting,雖然有一些方法����,如剪枝可以減少這種情況����,但是還是不夠的��。
模型組合(比如說有Boosting���,Bagging等)與決策樹相關(guān)的算法比較多�����,這些算法最終的結(jié)果是生成N(可能會有幾百棵以上)棵樹��,這樣可以大 大的減少單決策樹帶來的毛病���,有點(diǎn)類似于三個臭皮匠等于一個諸葛亮的做法,雖然這幾百棵決策樹中的每一棵都很簡單(相對于C4.5這種單決策樹來說)�,但 是他們組合起來確是很強(qiáng)大�。
在最近幾年的paper上,如iccv這種重量級的會議���,iccv 09年 的里面有不少的文章都是與Boosting與隨機(jī)森林相關(guān)的����。模型組合+決策樹相關(guān)的算法有兩種比較基本的形式 - 隨機(jī)森林與GBDT((Gradient Boost Decision Tree)��,其他的比較新的模型組合+決策樹的算法都是來自這兩種算法的延伸�����。本文主要側(cè)重于GBDT�����,對于隨機(jī)森林只是大概提提��,因?yàn)樗鄬Ρ容^簡單�����。
在看本文之前���,建議先看看機(jī)器學(xué)習(xí)與數(shù)學(xué)(3)與其中引用的論文��,本文中的GBDT主要基于此�,而隨機(jī)森林相對比較獨(dú)立����。
基礎(chǔ)內(nèi)容:
這里只是準(zhǔn)備簡單談?wù)劵A(chǔ)的內(nèi)容�,主要參考一下別人的文章�,對于隨機(jī)森林與GBDT,有兩個地方比較重要��,首先是information gain��,其次是決策樹����。這里特別推薦Andrew Moore大牛的Decision Trees Tutorial,與Information Gain Tutorial���。Moore的Data Mining Tutorial系列非常贊����,看懂了上面說的兩個內(nèi)容之后的文章才能繼續(xù)讀下去���。
決策樹實(shí)際上是將空間用超平面進(jìn)行劃分的一種方法��,每次分割的時候�,都將當(dāng)前的空間一分為二��,比如說下面的決策樹:
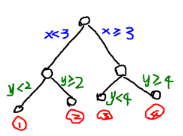
就是將空間劃分成下面的樣子:
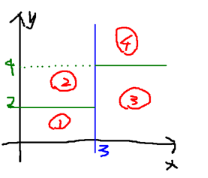
這樣使得每一個葉子節(jié)點(diǎn)都是在空間中的一個不相交的區(qū)域,在進(jìn)行決策的時候�����,會根據(jù)輸入樣本每一維feature的值�����,一步一步往下��,最后使得樣本落入N個區(qū)域中的一個(假設(shè)有N個葉子節(jié)點(diǎn))
隨機(jī)森林(Random Forest):
隨機(jī)森林是一個最近比較火的算法����,它有很多的優(yōu)點(diǎn):
在數(shù)據(jù)集上表現(xiàn)良好
在當(dāng)前的很多數(shù)據(jù)集上��,相對其他算法有著很大的優(yōu)勢
它能夠處理很高維度(feature很多)的數(shù)據(jù)���,并且不用做特征選擇
在訓(xùn)練完后�,它能夠給出哪些feature比較重要
在創(chuàng)建隨機(jī)森林的時候�����,對generlization error使用的是無偏估計
訓(xùn)練速度快
在訓(xùn)練過程中�����,能夠檢測到feature間的互相影響
容易做成并行化方法
實(shí)現(xiàn)比較簡單
隨機(jī)森林顧名思義,是用隨機(jī)的方式建立一個森林����,森林里面有很多的決策樹組成,隨機(jī)森林的每一棵決策樹之間是沒有關(guān)聯(lián)的�����。在得到森林之后�,當(dāng)有一個新的輸 入樣本進(jìn)入的時候,就讓森林中的每一棵決策樹分別進(jìn)行一下判斷�,看看這個樣本應(yīng)該屬于哪一類(對于分類算法),然后看看哪一類被選擇最多��,就預(yù)測這個樣本 為那一類����。
在建立每一棵決策樹的過程中,有兩點(diǎn)需要注意 - 采樣與完全分裂�。首先是兩個隨機(jī)采樣的過程,random forest對輸入的數(shù)據(jù)要進(jìn)行行���、列的采樣�。對于行采樣,采用有放回的方式��,也就是在采樣得到的樣本集合中,可能有重復(fù)的樣本。假設(shè)輸入樣本為N個����,那 么采樣的樣本也為N個����。這樣使得在訓(xùn)練的時候��,每一棵樹的輸入樣本都不是全部的樣本�����,使得相對不容易出現(xiàn)over-fitting�����。然后進(jìn)行列采樣�,從M 個feature中���,選擇m個(m << M)�����。之后就是對采樣之后的數(shù)據(jù)使用完全分裂的方式建立出決策樹���,這樣決策樹的某一個葉子節(jié)點(diǎn)要么是無法繼續(xù)分裂的�,要么里面的所有樣本的都是指向的同一 個分類�����。一般很多的決策樹算法都一個重要的步驟 - 剪枝����,但是這里不這樣干,由于之前的兩個隨機(jī)采樣的過程保證了隨機(jī)性�,所以就算不剪枝,也不會出現(xiàn)over-fitting���。
按這種算法得到的隨機(jī)森林中的每一棵都是很弱的���,但是大家組合起來就很厲害了。我覺得可以這樣比喻隨機(jī)森林算法:每一棵決策樹就是一個精通于某一個窄領(lǐng)域 的專家(因?yàn)槲覀儚腗個feature中選擇m讓每一棵決策樹進(jìn)行學(xué)習(xí))�����,這樣在隨機(jī)森林中就有了很多個精通不同領(lǐng)域的專家,對一個新的問題(新的輸入數(shù) 據(jù))�����,可以用不同的角度去看待它�����,最終由各個專家����,投票得到結(jié)果。
這個頁面上寫的比較清楚了�,其中可能不明白的就是Information Gain�,可以看看之前推薦過的Moore的頁面。
Gradient Boost Decision Tree:
GBDT是一個應(yīng)用很廣泛的算法����,可以用來做分類、回歸�。在很多的數(shù)據(jù)上都有不錯的效果。GBDT這個算法還有一些其他的名字�,比如說MART(Multiple Additive Regression Tree),GBRT(Gradient Boost Regression Tree),Tree Net等���,其實(shí)它們都是一個東西(參考自wikipedia – Gradient Boosting)�����,發(fā)明者是Friedman
Gradient Boost其實(shí)是一個框架�����,里面可以套入很多不同的算法�����,可以參考一下機(jī)器學(xué)習(xí)與數(shù)學(xué)(3)中的講解�����。Boost是"提升"的意思���,一般Boosting算法都是一個迭代的過程,每一次新的訓(xùn)練都是為了改進(jìn)上一次的結(jié)果����。
原始的Boost算法是在算法開始的時候,為每一個樣本賦上一個權(quán)重值,初始的時候���,大家都是一樣重要的����。在每一步訓(xùn)練中得到的模型�,會使得數(shù)據(jù)點(diǎn)的估計 有對有錯,我們就在每一步結(jié)束后���,增加分錯的點(diǎn)的權(quán)重�����,減少分對的點(diǎn)的權(quán)重�,這樣使得某些點(diǎn)如果老是被分錯�����,那么就會被“嚴(yán)重關(guān)注”�,也就被賦上一個很高 的權(quán)重�。然后等進(jìn)行了N次迭代(由用戶指定),將會得到N個簡單的分類器(basic learner)���,然后我們將它們組合起來(比如說可以對它們進(jìn)行加權(quán)����、或者讓它們進(jìn)行投票等),得到一個最終的模型����。
而Gradient Boost與傳統(tǒng)的Boost的區(qū)別是,每一次的計算是為了減少上一次的殘差(residual)���,而為了消除殘差��,我們可以在殘差減少的梯度(Gradient)方向上建立一個新的模型���。所以說,在Gradient Boost中�����,每個新的模型的簡歷是為了使得之前模型的殘差往梯度方向減少�����,與傳統(tǒng)Boost對正確�����、錯誤的樣本進(jìn)行加權(quán)有著很大的區(qū)別。
在分類問題中��,有一個很重要的內(nèi)容叫做Multi-Class Logistic���,也就是多分類的Logistic問題�,它適用于那些類別數(shù)>2的問題��,并且在分類結(jié)果中�����,樣本x不是一定只屬于某一個類可以得到 樣本x分別屬于多個類的概率(也可以說樣本x的估計y符合某一個幾何分布)����,這實(shí)際上是屬于Generalized Linear Model中討論的內(nèi)容,這里就先不談了���,以后有機(jī)會再用一個專門的章節(jié)去做吧��。這里就用一個結(jié)論:如果一個分類問題符合幾何分布���,那么就可以用Logistic變換來進(jìn)行之后的運(yùn)算。
假設(shè)對于一個樣本x�,它可能屬于K個分類,其估計值分別為F1(x)…FK(x)�,Logistic變換如下,logistic變換是一個平滑且將數(shù)據(jù)規(guī)范化(使得向量的長度為1)的過程��,結(jié)果為屬于類別k的概率pk(x)�����,
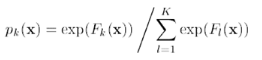
對于Logistic變換后的結(jié)果�,損失函數(shù)為:
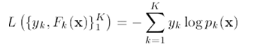
其中,yk為輸入的樣本數(shù)據(jù)的估計值���,當(dāng)一個樣本x屬于類別k時�����,yk = 1�,否則yk = 0����。
將Logistic變換的式子帶入損失函數(shù),并且對其求導(dǎo)�����,可以得到損失函數(shù)的梯度:
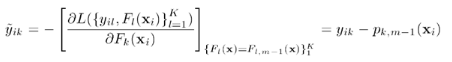
上面說的比較抽象,下面舉個例子:
假設(shè)輸入數(shù)據(jù)x可能屬于5個分類(分別為1,2,3,4,5)�,訓(xùn)練數(shù)據(jù)中,x屬于類別3�,則y = (0, 0, 1, 0, 0),假設(shè)模型估計得到的F(x) = (0, 0.3, 0.6, 0, 0)�,則經(jīng)過Logistic變換后的數(shù)據(jù)p(x) = (0.16,0.21,0.29,0.16,0.16),y - p得到梯度g:(-0.16, -0.21, 0.71, -0.16, -0.16)���。觀察這里可以得到一個比較有意思的結(jié)論:
假設(shè)gk為樣本當(dāng)某一維(某一個分類)上的梯度:
gk>0時����,越大表示其在這一維上的概率p(x)越應(yīng)該提高�����,比如說上面的第三維的概率為0.29�����,就應(yīng)該提高���,屬于應(yīng)該往“正確的方向”前進(jìn)
越小表示這個估計越“準(zhǔn)確”
gk<0時����,越小�����,負(fù)得越多表示在這一維上的概率應(yīng)該降低����,比如說第二維0.21就應(yīng)該得到降低。屬于應(yīng)該朝著“錯誤的反方向”前進(jìn)
越大���,負(fù)得越少表示這個估計越“不錯誤 ”
總的來說��,對于一個樣本��,最理想的梯度是越接近0的梯度��。所以��,我們要能夠讓函數(shù)的估計值能夠使得梯度往反方向移動(>0的維度上����,往負(fù)方向移動�,<0的維度上�,往正方向移動)最終使得梯度盡量=0)�,并且該算法在會嚴(yán)重關(guān)注那些梯度比較大的樣本,跟Boost的意思類似�����。
得到梯度之后�����,就是如何讓梯度減少了��。這里是用的一個迭代+決策樹的方法�����,當(dāng)初始化的時候���,隨便給出一個估計函數(shù)F(x)(可以讓F(x)是一個隨機(jī)的值����,也可以讓F(x)=0)��,然后之后每迭代一步就根據(jù)當(dāng)前每一個樣本的梯度的情況,建立一棵決策樹���。就讓函數(shù)往梯度的反方向前進(jìn)��,最終使得迭代N步后�,梯度越小���。
這里建立的決策樹和普通的決策樹不太一樣,首先��,這個決策樹是一個葉子節(jié)點(diǎn)數(shù)J固定的�,當(dāng)生成了J個節(jié)點(diǎn)后,就不再生成新的節(jié)點(diǎn)了��。
算法的流程如下:(參考自treeBoost論文)

0. 表示給定一個初始值
1. 表示建立M棵決策樹(迭代M次)
2. 表示對函數(shù)估計值F(x)進(jìn)行Logistic變換
3. 表示對于K個分類進(jìn)行下面的操作(其實(shí)這個for循環(huán)也可以理解為向量的操作���,每一個樣本點(diǎn)xi都對應(yīng)了K種可能的分類yi���,所以yi, F(xi), p(xi)都是一個K維的向量,這樣或許容易理解一點(diǎn))
4. 表示求得殘差減少的梯度方向
5. 表示根據(jù)每一個樣本點(diǎn)x��,與其殘差減少的梯度方向�����,得到一棵由J個葉子節(jié)點(diǎn)組成的決策樹
6. 為當(dāng)決策樹建立完成后,通過這個公式�����,可以得到每一個葉子節(jié)點(diǎn)的增益(這個增益在預(yù)測的時候用的)
每個增益的組成其實(shí)也是一個K維的向量����,表示如果在決策樹預(yù)測的過程中,如果某一個樣本點(diǎn)掉入了這個葉子節(jié)點(diǎn)�,則其對應(yīng)的K個分類的值是多少。比如 說����,GBDT得到了三棵決策樹,一個樣本點(diǎn)在預(yù)測的時候��,也會掉入3個葉子節(jié)點(diǎn)上����,其增益分別為(假設(shè)為3分類的問題):
(0.5, 0.8, 0.1), (0.2, 0.6, 0.3), (0.4, 0.3, 0.3),那么這樣最終得到的分類為第二個��,因?yàn)檫x擇分類2的決策樹是最多的���。
7. 的意思為����,將當(dāng)前得到的決策樹與之前的那些決策樹合并起來,作為新的一個模型(跟6中所舉的例子差不多)
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試���,點(diǎn)擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材�,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330