用R語言對混合型數(shù)據(jù)進行聚類分析
利用聚類分析�����,我們可以很容易地看清數(shù)據(jù)集中樣本的分布情況�。以往介紹聚類分析的文章中通常只介紹如何處理連續(xù)型變量����,這些文字并沒有過多地介紹如何處理混合型數(shù)據(jù)(如同時包含連續(xù)型變量����、名義型變量和順序型變量的數(shù)據(jù))。本文將利用 Gower 距離�、PAM(partitioning around medoids)算法和輪廓系數(shù)來介紹如何對混合型數(shù)據(jù)做聚類分析。
本文主要分為三個部分:
距離計算
聚類算法的選擇
聚類個數(shù)的選擇
為了介紹方便�,本文直接使用 ISLR 包中的 College 數(shù)據(jù)集。該數(shù)據(jù)集包含了自 1995 年以來美國大學的 777 條數(shù)據(jù)��,其中主要有以下幾個變量:
連續(xù)型變量
錄取率
學費
新生數(shù)量
分類型變量
公立或私立院校
是否為高水平院校��,即所有新生中畢業(yè)于排名前 10% 高中的新生數(shù)量占比是否大于 50%
本文中涉及到的R包有:
In [3]:
set.seed(1680) # 設(shè)置隨機種子����,使得本文結(jié)果具有可重現(xiàn)性
library(dplyr)
library(ISLR)
library(cluster)
library(Rtsne)
library(ggplot2)
Attaching package: ‘dplyr’
The following objects are masked from ‘package:stats’:
filter, lag
The following objects are masked from ‘package:base’:
intersect, setdiff, setequal, union
構(gòu)建聚類模型之前,我們需要做一些數(shù)據(jù)清洗工作:
錄取率等于錄取人數(shù)除以總申請人數(shù)
判斷某個學校是否為高水平院校�,需要根據(jù)該學校的所有新生中畢業(yè)于排名前 10% 高中的新生數(shù)量占比是否大于 50% 來決定
In [5]:
college_clean <- College %>%
mutate(name = row.names(.),
accept_rate = Accept/Apps,
isElite = cut(Top10perc,
breaks = c(0, 50, 100),
labels = c("Not Elite", "Elite"),
include.lowest = TRUE)) %>%
mutate(isElite = factor(isElite)) %>%
select(name, accept_rate, Outstate, Enroll,
Grad.Rate, Private, isElite)
glimpse(college_clean)
Observations: 777
Variables: 7
$ name (chr) "Abilene Christian University", "Adelphi University", "...
$ accept_rate (dbl) 0.7421687, 0.8801464, 0.7682073, 0.8369305, 0.7564767, ...
$ Outstate (dbl) 7440, 12280, 11250, 12960, 7560, 13500, 13290, 13868, 1...
$ Enroll (dbl) 721, 512, 336, 137, 55, 158, 103, 489, 227, 172, 472, 4...
$ Grad.Rate (dbl) 60, 56, 54, 59, 15, 55, 63, 73, 80, 52, 73, 76, 74, 68,...
$ Private (fctr) Yes, Yes, Yes, Yes, Yes, Yes, Yes, Yes, Yes, Yes, Yes,...
$ isElite (fctr) Not Elite, Not Elite, Not Elite, Elite, Not Elite, Not...
距離計算
聚類分析的第一步是定義樣本之間距離的度量方法,最常用的距離度量方法是歐式距離�。然而歐氏距離只適用于連續(xù)型變量����,所以本文將采用另外一種距離度量方法—— Gower 距離���。
Gower 距離
Gower 距離的定義非常簡單�。首先每個類型的變量都有特殊的距離度量方法����,而且該方法會將變量標準化到[0,1]之間。接下來���,利用加權(quán)線性組合的方法來計算最終的距離矩陣���。不同類型變量的計算方法如下所示:
連續(xù)型變量:利用歸一化的曼哈頓距離
順序型變量:首先將變量按順序排列,然后利用經(jīng)過特殊調(diào)整的曼哈頓距離
名義型變量:首先將包含 k 個類別的變量轉(zhuǎn)換成 k 個 0-1 變量���,然后利用 Dice 系數(shù)做進一步的計算
優(yōu)點:通俗易懂且計算方便
缺點:非常容易受無標準化的連續(xù)型變量異常值影響��,所以數(shù)據(jù)轉(zhuǎn)換過程必不可少�����;該方法需要耗費較大的內(nèi)存
利用 daisy 函數(shù)���,我們只需要一行代碼就可以計算出 Gower 距離��。需要注意的是��,由于新生入學人數(shù)是右偏變量���,我們需要對其做對數(shù)轉(zhuǎn)換��。daisy 函數(shù)內(nèi)置了對數(shù)轉(zhuǎn)換的功能���,你可以調(diào)用幫助文檔來獲取更多的參數(shù)說明����。
In [6]:
# Remove college name before clustering
gower_dist <- daisy(college_clean[, -1],
metric = "gower",
type = list(logratio = 3))
# Check attributes to ensure the correct methods are being used
# (I = interval, N = nominal)
# Note that despite logratio being called,
# the type remains coded as "I"
summary(gower_dist)
Out[6]:
301476 dissimilarities, summarized :
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.0018601 0.1034400 0.2358700 0.2314500 0.3271400 0.7773500
Metric : mixed ; Types = I, I, I, I, N, N
Number of objects : 777
此外��,我們可以通過觀察最相似和最不相似的樣本來判斷該度量方法的合理性���。本案例中��,圣托馬斯大學和約翰卡羅爾大學最相似��,而俄克拉荷馬科技和藝術(shù)大學和哈佛大學差異最大���。
In [7]:
gower_mat <- as.matrix(gower_dist)
# Output most similar pair
college_clean[
which(gower_mat == min(gower_mat[gower_mat != min(gower_mat)]),
arr.ind = TRUE)[1, ], ]
Out[7]:

In [8]:
# Output most dissimilar pair
college_clean[
which(gower_mat == max(gower_mat[gower_mat != max(gower_mat)]),
arr.ind = TRUE)[1, ], ]
Out[8]:

聚類算法的選擇
現(xiàn)在我們已經(jīng)計算好樣本間的距離矩陣�����,接下來需要選擇一個合適的聚類算法�,本文采用 PAM(partioniong around medoids)算法來構(gòu)建模型:
PAM 算法的主要步驟:
隨機選擇 k 個數(shù)據(jù)點�����,并將其設(shè)為簇中心點
遍歷所有樣本點�,并將樣本點歸入最近的簇中
對每個簇而言,找出與簇內(nèi)其他點距離之和最小的點�����,并將其設(shè)為新的簇中心點
重復(fù)第2步���,直到收斂
該算法和 K-means 算法非常相似��。事實上���,除了中心點的計算方法不同外,其他步驟都完全一致 。
優(yōu)點:簡單易懂且不易受異常值所影響
缺點:算法時間復(fù)雜度為 O(n2)O(n2)
聚類個數(shù)的選擇
我們將利用輪廓系數(shù)來確定最佳的聚類個數(shù)����,輪廓系數(shù)是一個用于衡量聚類離散度的內(nèi)部指標,該指標的取值范圍是[-1,1]�����,其數(shù)值越大越好�����。通過比較不同聚類個數(shù)下輪廓系數(shù)的大小�����,我們可以看出當聚類個數(shù)為 3 時���,聚類效果最好。
In [9]:
# Calculate silhouette width for many k using PAM
sil_width <- c(NA)
for(i in 2:10){
pam_fit <- pam(gower_dist,
diss = TRUE,
k = i)
sil_width[i] <- pam_fit$silinfo$avg.width
}
# Plot sihouette width (higher is better)
plot(1:10, sil_width,
xlab = "Number of clusters",
ylab = "Silhouette Width")
lines(1:10, sil_width)
聚類結(jié)果解釋
描述統(tǒng)計量
聚類完畢后���,我們可以調(diào)用 summary 函數(shù)來查看每個簇的匯總信息����。從這些匯總信息中我們可以看出:簇1主要是中等學費且學生規(guī)模較小的私立非頂尖院校,簇2主要是高收費�、低錄取率且高畢業(yè)率的私立頂尖院校,而簇3則是低學費����、低畢業(yè)率且學生規(guī)模較大的公立非頂尖院校。
In [18]:
pam_fit <- pam(gower_dist, diss = TRUE, k = 3)
pam_results <- college_clean %>%
dplyr::select(-name) %>%
mutate(cluster = pam_fit$clustering) %>%
group_by(cluster) %>%
do(the_summary = summary(.))
print(pam_results$the_summary)
[[1]]
accept_rate Outstate Enroll Grad.Rate Private
Min. :0.3283 Min. : 2340 Min. : 35.0 Min. : 15.00 No : 0
1st Qu.:0.7225 1st Qu.: 8842 1st Qu.: 194.8 1st Qu.: 56.00 Yes:500
Median :0.8004 Median :10905 Median : 308.0 Median : 67.50
Mean :0.7820 Mean :11200 Mean : 418.6 Mean : 66.97
3rd Qu.:0.8581 3rd Qu.:13240 3rd Qu.: 484.8 3rd Qu.: 78.25
Max. :1.0000 Max. :21700 Max. :4615.0 Max. :118.00
isElite cluster
Not Elite:500 Min. :1
Elite : 0 1st Qu.:1
Median :1
Mean :1
3rd Qu.:1
Max. :1
[[2]]
accept_rate Outstate Enroll Grad.Rate Private
Min. :0.1545 Min. : 5224 Min. : 137.0 Min. : 54.00 No : 4
1st Qu.:0.4135 1st Qu.:13850 1st Qu.: 391.0 1st Qu.: 77.00 Yes:65
Median :0.5329 Median :17238 Median : 601.0 Median : 89.00
Mean :0.5392 Mean :16225 Mean : 882.5 Mean : 84.78
3rd Qu.:0.6988 3rd Qu.:18590 3rd Qu.:1191.0 3rd Qu.: 94.00
Max. :0.9605 Max. :20100 Max. :4893.0 Max. :100.00
isElite cluster
Not Elite: 0 Min. :2
Elite :69 1st Qu.:2
Median :2
Mean :2
3rd Qu.:2
Max. :2
[[3]]
accept_rate Outstate Enroll Grad.Rate Private
Min. :0.3746 Min. : 2580 Min. : 153 Min. : 10.00 No :208
1st Qu.:0.6423 1st Qu.: 5295 1st Qu.: 694 1st Qu.: 46.00 Yes: 0
Median :0.7458 Median : 6598 Median :1302 Median : 54.50
Mean :0.7315 Mean : 6698 Mean :1615 Mean : 55.42
3rd Qu.:0.8368 3rd Qu.: 7748 3rd Qu.:2184 3rd Qu.: 65.00
Max. :1.0000 Max. :15516 Max. :6392 Max. :100.00
isElite cluster
Not Elite:199 Min. :3
Elite : 9 1st Qu.:3
Median :3
Mean :3
3rd Qu.:3
Max. :3
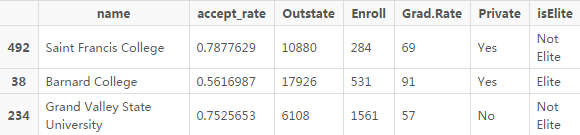
PAM 算法的另一個優(yōu)點是各個簇的中心點是實際的樣本點���。從聚類結(jié)果中我們可以看出�����,圣弗朗西斯大學是簇1 的中心點�,巴朗德學院是簇2 的中心點��,而密歇根州州立大學河谷大學是簇3 的中心點���。
In [19]:
college_clean[pam_fit$medoids, ]
Out[19]:
可視化方法
t-SNE 是一種降維方法�,它可以在保留聚類結(jié)構(gòu)的前提下����,將多維信息壓縮到二維或三維空間中。借助t-SNE我們可以將 PAM 算法的聚類結(jié)果繪制出來�����,有趣的是私立頂尖院校和公立非頂尖院校這兩個簇中間存在一個小聚類簇。
In [22]:
tsne_obj <- Rtsne(gower_dist, is_distance = TRUE)
tsne_data <- tsne_obj$Y %>%
data.frame() %>%
setNames(c("X", "Y")) %>%
mutate(cluster = factor(pam_fit$clustering),
name = college_clean$name)
ggplot(aes(x = X, y = Y), data = tsne_data) +
geom_point(aes(color = cluster))
進一步探究可以發(fā)現(xiàn)��,這一小簇主要包含一些競爭力較強的公立院校�����,比如弗吉尼亞大學和加州大學伯克利分校��。雖然無法通過輪廓系數(shù)指標來證明多分一類是合理的����,但是這 13 所院校的確顯著不同于其他三個簇的院校。
In [25]:
tsne_data %>%
filter(X > 15 & X < 25,
Y > -15 & Y < -10) %>%
left_join(college_clean, by = "name") %>%
collect %>%
.[["name"]]
Out[25]:
-
‘Kansas State University’
-
-
‘North Carolina State University at Raleigh’
-
‘Pennsylvania State Univ. Main Campus’
-
-
‘SUNY at Buffalo’
-
‘Texas A&M Univ. at College Station’
-
-
‘University of Georgia’
-
-
‘University of Kansas’
-
‘University of Maryland at College Park’
-
-
‘University of Minnesota Twin Cities’
-
‘University of Missouri at Columbia’
-
-
‘University of Tennessee at Knoxville’
-
‘University of Texas at Austin’
[R]混合型數(shù)據(jù)聚
利用聚類分析�,我們可以很容易地看清數(shù)據(jù)集中樣本的分布情況。以往介紹聚類分析的文章中通常只介紹如何處理連續(xù)型變量��,這些文字并沒有過多地介紹如何處理混合型數(shù)據(jù)(如同時包含連續(xù)型變量�����、名義型變量和順序型變量的數(shù)據(jù))���。本文將利用 Gower 距離、PAM(partitioning around medoids)算法和輪廓系數(shù)來介紹如何對混合型數(shù)據(jù)做聚類分析。
本文主要分為三個部分:
距離計算
聚類算法的選擇
聚類個數(shù)的選擇
為了介紹方便����,本文直接使用 ISLR 包中的 College 數(shù)據(jù)集。該數(shù)據(jù)集包含了自 1995 年以來美國大學的 777 條數(shù)據(jù)�����,其中主要有以下幾個變量:
連續(xù)型變量
錄取率
學費
新生數(shù)量
分類型變量
公立或私立院校
是否為高水平院校���,即所有新生中畢業(yè)于排名前 10% 高中的新生數(shù)量占比是否大于 50%
本文中涉及到的R包有:
In [3]:
set.seed(1680) # 設(shè)置隨機種子���,使得本文結(jié)果具有可重現(xiàn)性
library(dplyr)
library(ISLR)
library(cluster)
library(Rtsne)
library(ggplot2))
Attaching package: ‘dplyr’
The following objects are masked from ‘package:stats’:
filter, lag
The following objects are masked from ‘package:base’:
intersect, setdiff, setequal, union
構(gòu)建聚類模型之前,我們需要做一些數(shù)據(jù)清洗工作:
錄取率等于錄取人數(shù)除以總申請人數(shù)
判斷某個學校是否為高水平院校�,需要根據(jù)該學校的所有新生中畢業(yè)于排名前 10% 高中的新生數(shù)量占比是否大于 50% 來決定
In [5]:
college_clean <- College %>%
mutate(name = row.names(.),
accept_rate = Accept/Apps,
isElite = cut(Top10perc,
breaks = c(0, 50, 100),
labels = c("Not Elite", "Elite"),
include.lowest = TRUE)) %>%
mutate(isElite = factor(isElite)) %>%
select(name, accept_rate, Outstate, Enroll,
Grad.Rate, Private, isElite)
glimpse(college_clean)
Observations: 777
Variables: 7
$ name (chr) "Abilene Christian University", "Adelphi University", "...
$ accept_rate (dbl) 0.7421687, 0.8801464, 0.7682073, 0.8369305, 0.7564767, ...
$ Outstate (dbl) 7440, 12280, 11250, 12960, 7560, 13500, 13290, 13868, 1...
$ Enroll (dbl) 721, 512, 336, 137, 55, 158, 103, 489, 227, 172, 472, 4...
$ Grad.Rate (dbl) 60, 56, 54, 59, 15, 55, 63, 73, 80, 52, 73, 76, 74, 68,...
$ Private (fctr) Yes, Yes, Yes, Yes, Yes, Yes, Yes, Yes, Yes, Yes, Yes,...
$ isElite (fctr) Not Elite, Not Elite, Not Elite, Elite, Not Elite, Not...
距離計算
聚類分析的第一步是定義樣本之間距離的度量方法,最常用的距離度量方法是歐式距離��。然而歐氏距離只適用于連續(xù)型變量�����,所以本文將采用另外一種距離度量方法—— Gower 距離���。
Gower 距離
Gower 距離的定義非常簡單��。首先每個類型的變量都有特殊的距離度量方法����,而且該方法會將變量標準化到[0,1]之間。接下來��,利用加權(quán)線性組合的方法來計算最終的距離矩陣���。不同類型變量的計算方法如下所示:
連續(xù)型變量:利用歸一化的曼哈頓距離
順序型變量:首先將變量按順序排列�����,然后利用經(jīng)過特殊調(diào)整的曼哈頓距離
名義型變量:首先將包含 k 個類別的變量轉(zhuǎn)換成 k 個 0-1 變量���,然后利用 Dice 系數(shù)做進一步的計算
優(yōu)點:通俗易懂且計算方便
缺點:非常容易受無標準化的連續(xù)型變量異常值影響,所以數(shù)據(jù)轉(zhuǎn)換過程必不可少����;該方法需要耗費較大的內(nèi)存
利用 daisy 函數(shù),我們只需要一行代碼就可以計算出 Gower 距離�。需要注意的是��,由于新生入學人數(shù)是右偏變量�,我們需要對其做對數(shù)轉(zhuǎn)換����。daisy 函數(shù)內(nèi)置了對數(shù)轉(zhuǎn)換的功能��,你可以調(diào)用幫助文檔來獲取更多的參數(shù)說明��。
In [6]:
# Remove college name before clustering
gower_dist <- daisy(college_clean[, -1],
metric = "gower",
type = list(logratio = 3))
# Check attributes to ensure the correct methods are being used
# (I = interval, N = nominal)
# Note that despite logratio being called,
# the type remains coded as "I"
summary(gower_dist)
Out[6]:
301476 dissimilarities, summarized :
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.0018601 0.1034400 0.2358700 0.2314500 0.3271400 0.7773500
Metric : mixed ; Types = I, I, I, I, N, N
Number of objects : 777
此外���,我們可以通過觀察最相似和最不相似的樣本來判斷該度量方法的合理性�����。本案例中���,圣托馬斯大學和約翰卡羅爾大學最相似,而俄克拉荷馬科技和藝術(shù)大學和哈佛大學差異最大�。
In [7]:
gower_mat <- as.matrix(gower_dist)
# Output most similar pair
college_clean[
which(gower_mat == min(gower_mat[gower_mat != min(gower_mat)]),
arr.ind = TRUE)[1, ], ]
Out[7]:

In [8]:
# Output most dissimilar pair
college_clean[
which(gower_mat == max(gower_mat[gower_mat != max(gower_mat)]),
arr.ind = TRUE)[1, ], ]
Out[8]:

聚類算法的選擇
現(xiàn)在我們已經(jīng)計算好樣本間的距離矩陣,接下來需要選擇一個合適的聚類算法����,本文采用 PAM(partioniong around medoids)算法來構(gòu)建模型:
PAM 算法的主要步驟:
-
隨機選擇 k 個數(shù)據(jù)點,并將其設(shè)為簇中心點
-
遍歷所有樣本點���,并將樣本點歸入最近的簇中
-
對每個簇而言�,找出與簇內(nèi)其他點距離之和最小的點,并將其設(shè)為新的簇中心點
-
重復(fù)第2步�����,直到收斂
該算法和 K-means 算法非常相似����。事實上,除了中心點的計算方法不同外���,其他步驟都完全一致 �。
優(yōu)點:簡單易懂且不易受異常值所影響
缺點:算法時間復(fù)雜度為 O(n2)O(n2
聚類個數(shù)的選擇
我們將利用輪廓系數(shù)來確定最佳的聚類個數(shù)���,輪廓系數(shù)是一個用于衡量聚類離散度的內(nèi)部指標�����,該指標的取值范圍是[-1,1]���,其數(shù)值越大越好。通過比較不同聚類個數(shù)下輪廓系數(shù)的大小����,我們可以看出當聚類個數(shù)為 3 時,聚類效果最好�����。
In [9]:
# Calculate silhouette width for many k using PAM
sil_width <- c(NA)
for(i in 2:10){
pam_fit <- pam(gower_dist,
diss = TRUE,
k = i)
sil_width[i] <- pam_fit$silinfo$avg.width
}
# Plot sihouette width (higher is better)
plot(1:10, sil_width,
xlab = "Number of clusters",
ylab = "Silhouette Width")
lines(1:10, sil_width)
聚類結(jié)果解釋
描述統(tǒng)計量
聚類完畢后��,我們可以調(diào)用 summary 函數(shù)來查看每個簇的匯總信息�����。從這些匯總信息中我們可以看出:簇1主要是中等學費且學生規(guī)模較小的私立非頂尖院校����,簇2主要是高收費、低錄取率且高畢業(yè)率的私立頂尖院校����,而簇3則是低學費、低畢業(yè)率且學生規(guī)模較大的公立非頂尖院校�。
In [18]:
pam_fit <- pam(gower_dist, diss = TRUE, k = 3)
pam_results <- college_clean %>%
dplyr::select(-name) %>%
mutate(cluster = pam_fit$clustering) %>%
group_by(cluster) %>%
do(the_summary = summary(.))
print(pam_results$the_summary)
[[1]]
accept_rate Outstate Enroll Grad.Rate Private
Min. :0.3283 Min. : 2340 Min. : 35.0 Min. : 15.00 No : 0
1st Qu.:0.7225 1st Qu.: 8842 1st Qu.: 194.8 1st Qu.: 56.00 Yes:500
Median :0.8004 Median :10905 Median : 308.0 Median : 67.50
Mean :0.7820 Mean :11200 Mean : 418.6 Mean : 66.97
3rd Qu.:0.8581 3rd Qu.:13240 3rd Qu.: 484.8 3rd Qu.: 78.25
Max. :1.0000 Max. :21700 Max. :4615.0 Max. :118.00
isElite cluster
Not Elite:500 Min. :1
Elite : 0 1st Qu.:1
Median :1
Mean :1
3rd Qu.:1
Max. :1
[[2]]
accept_rate Outstate Enroll Grad.Rate Private
Min. :0.1545 Min. : 5224 Min. : 137.0 Min. : 54.00 No : 4
1st Qu.:0.4135 1st Qu.:13850 1st Qu.: 391.0 1st Qu.: 77.00 Yes:65
Median :0.5329 Median :17238 Median : 601.0 Median : 89.00
Mean :0.5392 Mean :16225 Mean : 882.5 Mean : 84.78
3rd Qu.:0.6988 3rd Qu.:18590 3rd Qu.:1191.0 3rd Qu.: 94.00
Max. :0.9605 Max. :20100 Max. :4893.0 Max. :100.00
isElite cluster
Not Elite: 0 Min. :2
Elite :69 1st Qu.:2
Median :2
Mean :2
3rd Qu.:2
Max. :2
[[3]]
accept_rate Outstate Enroll Grad.Rate Private
Min. :0.3746 Min. : 2580 Min. : 153 Min. : 10.00 No :208
1st Qu.:0.6423 1st Qu.: 5295 1st Qu.: 694 1st Qu.: 46.00 Yes: 0
Median :0.7458 Median : 6598 Median :1302 Median : 54.50
Mean :0.7315 Mean : 6698 Mean :1615 Mean : 55.42
3rd Qu.:0.8368 3rd Qu.: 7748 3rd Qu.:2184 3rd Qu.: 65.00
Max. :1.0000 Max. :15516 Max. :6392 Max. :100.00
isElite cluster
Not Elite:199 Min. :3
Elite : 9 1st Qu.:3
Median :3
Mean :3
3rd Qu.:3
Max. :3
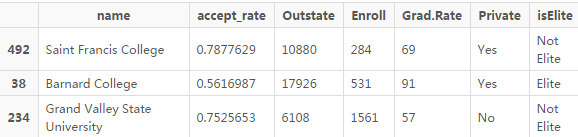
PAM 算法的另一個優(yōu)點是各個簇的中心點是實際的樣本點。從聚類結(jié)果中我們可以看出����,圣弗朗西斯大學是簇1 的中心點,巴朗德學院是簇2 的中心點�����,而密歇根州州立大學河谷大學是簇3 的中心點。
In [19]:
college_clean[pam_fit$medoids, ]
Out[19]:
可視化方法
t-SNE 是一種降維方法�,它可以在保留聚類結(jié)構(gòu)的前提下,將多維信息壓縮到二維或三維空間中�。借助t-SNE我們可以將 PAM 算法的聚類結(jié)果繪制出來,有趣的是私立頂尖院校和公立非頂尖院校這兩個簇中間存在一個小聚類簇��。
In [22]:
tsne_obj <- Rtsne(gower_dist, is_distance = TRUE)
tsne_data <- tsne_obj$Y %>%
data.frame() %>%
setNames(c("X", "Y")) %>%
mutate(cluster = factor(pam_fit$clustering),
name = college_clean$name)
ggplot(aes(x = X, y = Y), data = tsne_data) +
geom_point(aes(color = cluster))
進一步探究可以發(fā)現(xiàn)����,這一小簇主要包含一些競爭力較強的公立院校,比如弗吉尼亞大學和加州大學伯克利分校����。雖然無法通過輪廓系數(shù)指標來證明多分一類是合理的,但是這 13 所院校的確顯著不同于其他三個簇的院校���。
In [25]:
tsne_data %>%
filter(X > 15 & X < 25,
Y > -15 & Y < -10) %>%
left_join(college_clean, by = "name") %>%
collect %>%
.[["name"]]
Out[25]:
-
‘Kansas State University’
-
-
‘North Carolina State University at Raleigh’
-
‘Pennsylvania State Univ. Main Campus’
-
-
‘SUNY at Buffalo’
-
‘Texas A&M Univ. at College Station’
-
-
‘University of Georgia’
-
-
‘University of Kansas’
-
‘University of Maryland at College Park’
-
-
‘University of Minnesota Twin Cities’
-
‘University of Missouri at Columbia’
-
-
‘University of Tennessee at Knoxville’
-
‘University of Texas at Austin’
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材,點擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330