用R語言實(shí)現(xiàn)對(duì)不平衡數(shù)據(jù)的四種處理方法
在對(duì)不平衡的分類數(shù)據(jù)集進(jìn)行建模時(shí),機(jī)器學(xué)習(xí)算法可能并不穩(wěn)定���,其預(yù)測結(jié)果甚至可能是有偏的��,而預(yù)測精度此時(shí)也變得帶有誤導(dǎo)性����。那么,這種結(jié)果是為何發(fā)生的呢?到底是什么因素影響了這些算法的表現(xiàn)?
在不平衡的數(shù)據(jù)中����,任一算法都沒法從樣本量少的類中獲取足夠的信息來進(jìn)行精確預(yù)測。因此����,機(jī)器學(xué)習(xí)算法常常被要求應(yīng)用在平衡數(shù)據(jù)集上。那我們?cè)撊绾翁幚聿黄胶鈹?shù)據(jù)集?本文會(huì)介紹一些相關(guān)方法,它們并不復(fù)雜只是技巧性比較強(qiáng)。
本文會(huì)介紹處理非平衡分類數(shù)據(jù)集的一些要點(diǎn)��,并主要集中于非平衡二分類問題的處理。一如既往�����,我會(huì)盡量精簡地?cái)⑹?���,在文末我?huì)演示如何用R中的ROSE包來解決實(shí)際問題。
什么是不平衡分類
不平衡分類是一種有監(jiān)督學(xué)習(xí)���,但它處理的對(duì)象中有一個(gè)類所占的比例遠(yuǎn)遠(yuǎn)大于其余類����。比起多分類��,這一問題在二分類中更為常見���。(注:下文中占比較大的類稱為大類��,占比較小的類稱為小類)
不平衡一詞指代數(shù)據(jù)中響應(yīng)變量(被解釋變量)的分布不均衡�,如果一個(gè)數(shù)據(jù)集的響應(yīng)變量在不同類上的分布差別較大我們就認(rèn)為它不平衡����。
舉個(gè)例子,假設(shè)我們有一個(gè)觀測數(shù)為100000的數(shù)據(jù)集��,它包含了哈佛大學(xué)申請(qǐng)人的信息���。眾所周知�����,哈佛大學(xué)以極低的錄取比例而聞名�����,那么這個(gè)數(shù)據(jù)集的響應(yīng)變量(即:該申請(qǐng)人是否被錄取���,是為1��,否為0)就很不平衡��,大致98%的觀測響應(yīng)變量為0��,只有2%的幸運(yùn)兒被錄取����。
在現(xiàn)實(shí)生活中���,這類例子更是不勝枚舉,我在下面列舉了一些實(shí)例�,請(qǐng)注意他們的不平衡度是不一樣的。
一個(gè)自動(dòng)產(chǎn)品質(zhì)量檢測機(jī)每天會(huì)檢測工廠生產(chǎn)的產(chǎn)品���,你會(huì)發(fā)現(xiàn)次品率是遠(yuǎn)遠(yuǎn)低于合格率的��。
某地區(qū)進(jìn)行了居民癌癥普查��,結(jié)果患有癌癥的居民人數(shù)也是遠(yuǎn)遠(yuǎn)少于健康人群�����。
在信用卡欺詐數(shù)據(jù)中�����,違規(guī)交易數(shù)比合規(guī)交易少不少����。
一個(gè)遵循6δ原則的生產(chǎn)車間每生產(chǎn)100萬個(gè)產(chǎn)品才會(huì)產(chǎn)出10個(gè)次品�。
生活中的例子還有太多�����,現(xiàn)在你可以發(fā)現(xiàn)獲取這些非平衡數(shù)據(jù)的可能性有多大,所以掌握這些數(shù)據(jù)集的處理方法也是每個(gè)數(shù)據(jù)分析師的必修課�����。
為什么大部分機(jī)器學(xué)習(xí)算法在不平衡數(shù)據(jù)集上表現(xiàn)不佳?
我覺得這是一個(gè)很有意思的問題��,你不妨自己先動(dòng)手試試�,然后你就會(huì)了解把不平衡數(shù)據(jù)再結(jié)構(gòu)化的重要性����,至于如何再結(jié)構(gòu)化�����,我會(huì)在操作部分中講解���。
下面是機(jī)器學(xué)習(xí)算法在不平衡數(shù)據(jù)上精度下降的原因:
響應(yīng)變量的分布不均勻使得算法精度下降����,對(duì)于小類的預(yù)測精度會(huì)很低�����。
算法本身是精度驅(qū)動(dòng)的����,即該模型的目標(biāo)是最小化總體誤差,而小類對(duì)于總體誤差的貢獻(xiàn)很低����。
算法本身假設(shè)數(shù)據(jù)集的類分布均衡,同時(shí)它們也可能假定不同類別的誤差帶來相同的損失(下文會(huì)詳細(xì)敘述)�。
針對(duì)不平衡數(shù)據(jù)的處理方法
這類處理方法其實(shí)就是大名鼎鼎的“采樣法”,總的說來�,應(yīng)用這些方法都是為了把不平衡數(shù)據(jù)修正為平衡數(shù)據(jù)���。修正方法就是調(diào)整原始數(shù)據(jù)集的樣本量���,使得不同類的數(shù)據(jù)比例一致。
而在諸多學(xué)者研究得出基于平衡數(shù)據(jù)的模型整體更優(yōu)的結(jié)論后��,這一類方法越來越受到分析師們的青睞�。
下列是一些具體的處理方法名稱:
欠采樣法(Undersampling)
過采樣法(Oversampling)
人工數(shù)據(jù)合成法(Synthetic Data Generation)
代價(jià)敏感學(xué)習(xí)法(Cose Sensitive Learning)
讓我們逐一了解它們。
1.欠采樣法
該方法主要是對(duì)大類進(jìn)行處理�。它會(huì)減少大類的觀測數(shù)來使得數(shù)據(jù)集平衡。這一辦法在數(shù)據(jù)集整體很大時(shí)較為適宜�,它還可以通過降低訓(xùn)練樣本量來減少計(jì)算時(shí)間和存儲(chǔ)開銷。
欠采樣法共有兩類:隨機(jī)(Random)的和有信息的(Informative)����。
隨機(jī)欠采樣法會(huì)隨機(jī)刪除大類的觀測直至數(shù)據(jù)集平衡����。有信息的欠采樣法則會(huì)依照一個(gè)事先制定的準(zhǔn)則來刪去觀測��。
有信息的欠采樣中�,利用簡易集成算法(EasyEnsemble)和平衡級(jí)聯(lián)算法(BalanceCascade)往往能得到比較好的結(jié)果。這兩種算法也都很直白易懂�����。
簡易集成法:首先��,它將從大類中有放回地抽取一些獨(dú)立樣本生成多個(gè)子集��。然后�����,將這些子集和小類的觀測合并�,再基于合并后的數(shù)據(jù)集訓(xùn)練多個(gè)分類器,以其中多數(shù)分類器的分類結(jié)果為預(yù)測結(jié)果��。如你所見���,整個(gè)流程和無監(jiān)督學(xué)習(xí)非常相似��。
平衡級(jí)聯(lián)法:它是一種有監(jiān)督的學(xué)習(xí)法��,首先將生成多個(gè)分類器��,再基于一定規(guī)則系統(tǒng)地篩選哪些大類樣本應(yīng)當(dāng)被保留����。
但欠采樣法有一個(gè)顯而易見的缺陷,由于要?jiǎng)h去不少觀測����,使用該方法會(huì)使得大類損失不少重要信息����。
2.過采樣法
這一方法針對(duì)小類進(jìn)行處理。它會(huì)以重復(fù)小類的觀測的方式來平衡數(shù)據(jù)��。該方法也被稱作升采樣(Upsampling)���。和欠采樣類似��,它也能分為隨機(jī)過采樣和有信息的過采樣兩類���。
隨機(jī)過采樣會(huì)將小類觀測隨機(jī)重復(fù)���。有信息過采樣也是遵循一定的準(zhǔn)則來人工合成小類觀測。
使用該方法的一大優(yōu)勢是沒有任何信息損失�����。缺點(diǎn)則是由于增加了小類的重復(fù)樣本����,很有可能導(dǎo)致過擬合(譯者注:計(jì)算時(shí)間和存儲(chǔ)開銷也增大不少)。我們通過該方法可以在訓(xùn)練集上得到非常高的擬合精度����,但在測試集上預(yù)測的表現(xiàn)則可能變得愈發(fā)糟糕。
3.人工數(shù)據(jù)合成法
簡單說來�,人工數(shù)據(jù)合成法是利用生成人工數(shù)據(jù)而不是重復(fù)原始觀測來解決不平衡性。它也是一種過采樣技術(shù)���。
在這一領(lǐng)域��,SMOTE法(Synthetic Minority Oversampling Technique)是有效而常用的方法�����。該算法基于特征空間(而不是數(shù)據(jù)空間)生成與小類觀測相似的新數(shù)據(jù)(譯者注:總體是基于歐氏距離來度量相似性�,在特征空間生成一些人工樣本,更通俗地說是在樣本點(diǎn)和它近鄰點(diǎn)的連線上隨機(jī)投點(diǎn)作為生成的人工樣本�����,下文敘述了這一過程但有些晦澀)�。我們也可以說,它生成了小類觀測的隨機(jī)集合來降低分類器的誤差�。
為了生成人工數(shù)據(jù),我們需要利用自助法(Bootstrapping)和K近鄰法(K-neraest neighbors)�。詳細(xì)步驟如下:
計(jì)算樣本點(diǎn)間的距離并確定其近鄰。
生成一個(gè)0到1上的均勻隨機(jī)數(shù)����,并將其乘以距離。
把第二步生成的值加到樣本點(diǎn)的特征向量上�。
這一過程等價(jià)于在在兩個(gè)樣本的連線上隨機(jī)選擇了一個(gè)點(diǎn)���。
R中有一個(gè)包專門用來實(shí)現(xiàn)SMOTE過程��,我們將在實(shí)踐部分做演示���。
4.代價(jià)敏感學(xué)習(xí)(CSL)
這是另一種常用且有意思的方法����。簡而言之����,該方法會(huì)衡量誤分類觀測的代價(jià)來解決不平衡問題。
這方法不會(huì)生成平衡的數(shù)據(jù)集�,而是通過生成代價(jià)矩陣來解決不平衡問題。代價(jià)矩陣是描述特定場景下誤分類觀測帶來的損失的工具����。近來已有研究表明,代價(jià)敏感學(xué)習(xí)法很多時(shí)候比采樣法更優(yōu)�����,因此這種方法也值得一學(xué)���。
讓我們通過一個(gè)例子來了解該方法:給定一個(gè)有關(guān)行人的數(shù)據(jù)集�����,我們想要了解行人是否會(huì)攜帶炸彈���。數(shù)據(jù)集包含了所有的必要信息��,且攜帶炸彈的人會(huì)被標(biāo)記為正類�����,不帶炸彈的就是負(fù)類?,F(xiàn)在問題來了���,我們需要把行人都分好類�。讓我們先來設(shè)定下這一問題的代價(jià)矩陣��。
如果我們將行人正確分類了�,我們不會(huì)蒙受任何損失。但如果我們把一個(gè)恐怖分子歸為負(fù)類(False Negative)����,我們要付出的代價(jià)會(huì)比把和平分子歸為正類(False Positive)的代價(jià)大的多。
代價(jià)矩陣和混淆矩陣類似���,如下所示,我們更關(guān)心的是偽正類(FP)和偽負(fù)類(FN)����。只要觀測被正確分類����,我們不會(huì)有任何代價(jià)損失�����。
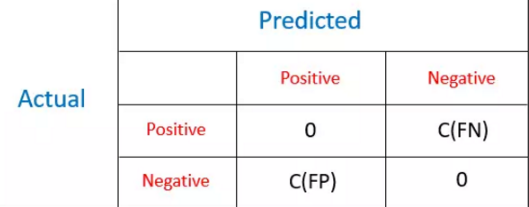
該方法的目標(biāo)就是找到一個(gè)使得總代價(jià)最小的分類器:
Total Cost = C(FN)xFN + C(FP)xFP
其中,
FN是被誤分類的正類樣本數(shù)
FP是被誤分類的負(fù)類樣本數(shù)
C(FN)和C(FP)分別代表FN和FP帶來的損失��。本例中C(FN) > C(FP)
除此之外����,我們還有其他的比較前沿的方法來處理不平衡樣本。比如基于聚類的采樣法(Cluster based sampling)����,自適應(yīng)人工采樣法(adaptive synthetic sampling),邊界線SMOTE(border line SMOTE)��,SMOTEboost��,DataBoost-IM�,核方法等。這些方法的基本思想和前文介紹的四類方法大同小異�。還有一些更直觀的方法可以幫助你提升預(yù)測效果:如利用聚類技術(shù)�����,把大類分為K個(gè)次類��,每個(gè)此類的樣本不重疊����。再基于每個(gè)次類和小類的合并樣本來訓(xùn)練分類器�����。最后把各個(gè)分類結(jié)果平均作為預(yù)測值��。除此之外�,也可以聚焦于獲取更多數(shù)據(jù)來提高小類的占比。
應(yīng)當(dāng)使用哪類評(píng)價(jià)測度來評(píng)判精度?
選擇合適的評(píng)價(jià)測度是不平衡數(shù)據(jù)分析的關(guān)鍵步驟�����。大部分分類算法僅僅通過正確分類率來衡量精度�。但在不平衡數(shù)據(jù)中,使用這種方法有很大的欺騙性��,因?yàn)樾☆悓?duì)于整體精度的影響太小����。
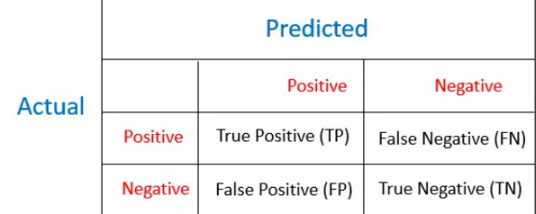
混淆矩陣和代價(jià)矩陣的差異就在于代價(jià)矩陣提供了跟多的誤分類損失信息,其對(duì)角元素皆為0��。而混淆舉證只提供了TP�����,TN��,F(xiàn)P�����,F(xiàn)N四類樣本的比例���,它常用的統(tǒng)計(jì)量則為正確率和錯(cuò)誤率:
Accuracy: (TP + TN)/(TP+TN+FP+FN)
Error Rate = 1 – Accuracy = (FP+FN)/(TP+TN+FP+FN)
如前文所提���,混淆矩陣可能會(huì)提供誤導(dǎo)性結(jié)果,并且它對(duì)數(shù)據(jù)變動(dòng)非常敏感�����。更進(jìn)一步��,我們可以從混淆矩陣衍生出很多統(tǒng)計(jì)量,其中如下測度就提供了關(guān)于不平衡數(shù)據(jù)精度的更好度量:
準(zhǔn)確率(Preciosion):正類樣本分類準(zhǔn)確性的度量��,即被標(biāo)記為正類的觀測中被正確分類的比例�����。
Precision = TP / (TP + FP)
召回率(Recall):所有實(shí)際正類樣本被正確分類的比率�����。也被稱作敏感度(Sensitivity)
Recall = TP / (TP + FN)
F測度(F measure):結(jié)合準(zhǔn)確率和召回率作為分類有效性的測度��。具體公式如下(?常取1):
F measure = ((1 + β)2 × Recall × Precision) / ( β2 × Recall + Precision )
盡管這些測度比正確率和錯(cuò)誤率更好��,但總的說來對(duì)于衡量分類器而言還不夠有效��。比如���,準(zhǔn)確率無法刻畫負(fù)類樣本的正確率�。召回率只針對(duì)實(shí)際正類樣本的分類結(jié)果��。這也就是說�,我們需要尋找更好的測度來評(píng)價(jià)分類器。
謝天謝地!我們可以通過ROC(Receiver Operationg Characterstics)曲線來衡量分類預(yù)測精度�����。這也是目前廣泛使用的評(píng)估方法。ROC曲線是通過繪制TP率(Sensitivity)和FP率(Specificity)的關(guān)系得到的��。
Specificity = TN / (TN + FP)
ROC圖上的任意一點(diǎn)都代表了單個(gè)分類器在一個(gè)給定分布上的表現(xiàn)�。ROC曲線之所以有用是因?yàn)樗峁┝朔诸悢?shù)據(jù)收益(TP)和損失(FP)的可視化信息�。ROC曲線下方區(qū)域的面積(AUC)越大,整體分類精度就越高�����。
但有時(shí)ROC曲線也會(huì)失效�,它的不足包括:
對(duì)于偏態(tài)分布的數(shù)據(jù),可能會(huì)高估精度
沒有提供分類表現(xiàn)的置信區(qū)間
無法提供不同分類器表現(xiàn)差異的顯著性水平
作為一種替代方法�,我們也可以選擇別的可視化方式比如PR曲線和代價(jià)曲線。特別地����,代價(jià)曲線被認(rèn)為有以圖形方式描述分類器誤分類代價(jià)的能力。但在90%的場合中����,ROC曲線已經(jīng)足夠好。
在R中進(jìn)行不平衡數(shù)據(jù)分類
我們已經(jīng)學(xué)習(xí)了不平衡分類的一些重要理論技術(shù)��。是時(shí)候來應(yīng)用它們了!在R中,諸如ROSE包和EMwR包都可以幫助我們快速實(shí)現(xiàn)采樣過程���。我們將以一個(gè)二分類案例做演示����。
ROSE(Random Over Sampling Examples)包可以幫助我們基于采樣和平滑自助法(smoothed bootstrap)來生成人工樣本����。這個(gè)包也提供了一些定義良好的函數(shù)來快速完成分類任務(wù)。
讓我們開始吧
ROSE包中內(nèi)置了一個(gè)叫做hacide的不平衡數(shù)據(jù)集�����,它包括hacide.train和hacide.test兩個(gè)部分����,讓我們把它讀入R環(huán)境:
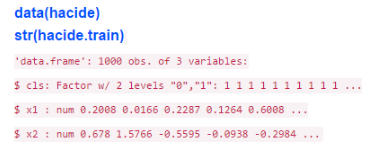
如你所見,數(shù)據(jù)集有3個(gè)變量的1000個(gè)觀測���。cls是響應(yīng)變量���,x1和x2是解釋變量。讓我們檢查下cls的不平衡程度:

可以看到,數(shù)據(jù)集中只有2%的正樣本�,其余98%都屬于負(fù)類。數(shù)據(jù)的不平衡性極其嚴(yán)重��。那么���,這對(duì)我們的分類精度會(huì)帶來多大影響?我們先建立一個(gè)簡單的決策樹模型:
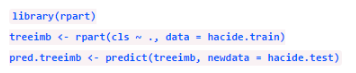
然我們看看這個(gè)模型的預(yù)測精度��,ROSE包提供了名為accuracy.meas()的函數(shù)�����,它能用來計(jì)算準(zhǔn)確率,召回率和F測度等統(tǒng)計(jì)量��。
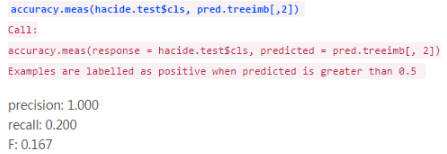
這些測度值看上去很有意思���。如果我們?cè)O(shè)定閾值為0.5��,準(zhǔn)確率等于1說明沒有被誤分為正類的樣本��。召回率等于0.2意味著有很多樣本被誤分為負(fù)類��。0.167的F值也說明模型整體精度很低���。
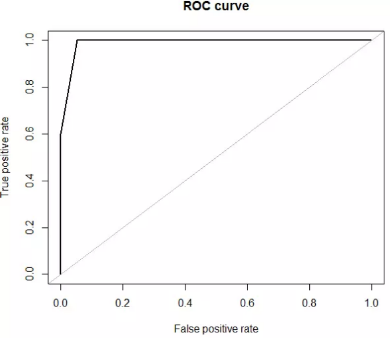
我們?cè)賮砜纯茨P偷腞OC曲線����,它會(huì)給我們提供這個(gè)模型分類能力的直觀評(píng)價(jià)�。使用roc.curve()函數(shù)可以繪制該曲線:

AUC值等于0.6是個(gè)很槽糕的結(jié)果。因此我們很有必要在建模前將數(shù)據(jù)集修正平衡�。在本案例中,決策樹算法對(duì)于小類樣本無能為力�。
我們將使用采樣技術(shù)來提升預(yù)測精度。這個(gè)包提供了ovun.sample()的函數(shù)來實(shí)現(xiàn)過采樣和欠采樣����。
我們先試試過采樣
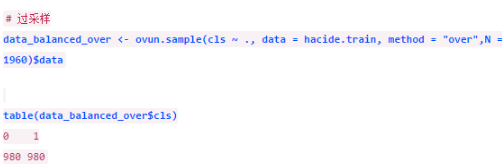
上述代碼實(shí)現(xiàn)了過采樣方法。N代表最終平衡數(shù)據(jù)集包含的樣本點(diǎn)���,本例中我們有980個(gè)原始負(fù)類樣本���,所以我們要通過過采樣法把正類樣本也補(bǔ)充到980個(gè),數(shù)據(jù)集共有1960個(gè)觀測���。
與之類似���,我們也能用欠采樣方法���,請(qǐng)牢記欠采樣是無放回的。
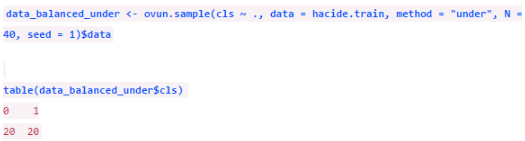
欠采樣后數(shù)據(jù)是平衡了��,但由于只剩下了40個(gè)樣本��,我們損失了太多信息��。我們還可以同時(shí)采取這兩類方法�����,只需要把參數(shù)改為method = “both”�����。這時(shí)�����,對(duì)小類樣本會(huì)進(jìn)行有放回的過采樣而對(duì)大類樣本則進(jìn)行無放回的欠采樣����。
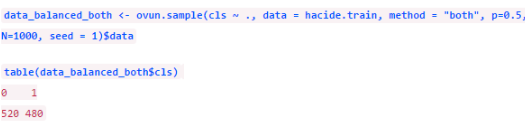
函數(shù)的參數(shù)p代表新生成數(shù)據(jù)集中正類的比例���。
但前文已經(jīng)提過兩類采樣法都有自身的缺陷�����,欠采樣會(huì)損失信息�,過采樣容易導(dǎo)致過擬合,因而ROSE包也提供了ROSE()函數(shù)來合成人工數(shù)據(jù)�,它能提供關(guān)于原始數(shù)據(jù)的更好估計(jì)。
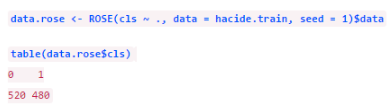
這里生成的數(shù)據(jù)量和原始數(shù)據(jù)集相等(1000個(gè)觀測)?,F(xiàn)在,我們已經(jīng)用4種方法平衡了數(shù)據(jù)���,我們分別建模評(píng)評(píng)估精度����。

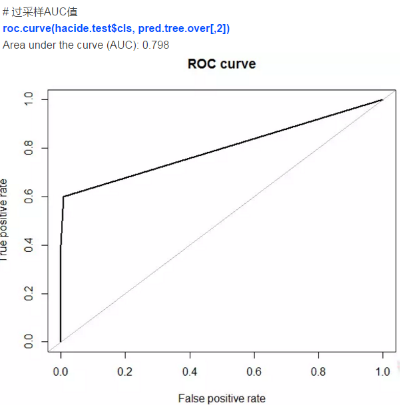
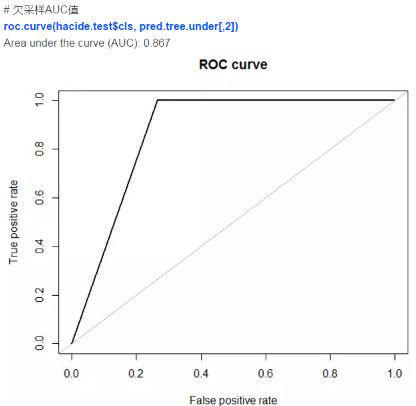
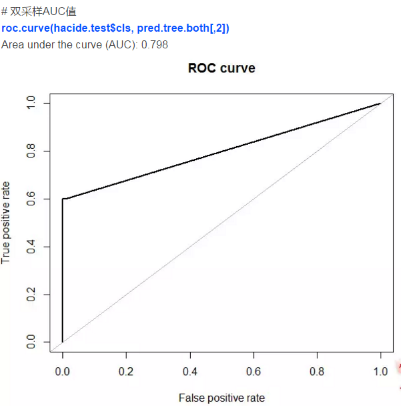
因此���,我們發(fā)現(xiàn)利用人工數(shù)據(jù)合成法可以帶來最高的預(yù)測精度���,它的表現(xiàn)比采樣法要好。這一技術(shù)和更穩(wěn)健的模型結(jié)合(隨機(jī)森林��,提升法)可以得到更高的精度����。
這個(gè)包為我們提供了一些基于holdout和bagging的模型評(píng)估方法��,這有助于我們判斷預(yù)測結(jié)果是否有太大的方差����。

可以發(fā)現(xiàn)預(yù)測精度維持在0.98附近��,這意味著預(yù)測結(jié)果波動(dòng)不大���。類似的���,你可以用自助法來評(píng)估,只要把method.asses改為”BOOT”��。extr.pred參數(shù)是一個(gè)輸出預(yù)測結(jié)果為正類的列的函數(shù)��。
結(jié)語
當(dāng)我們面對(duì)不平衡數(shù)據(jù)集時(shí)�,我們常常發(fā)現(xiàn)利用采樣法修正的效果不錯(cuò)���。但在本例中����,人工數(shù)據(jù)合成比傳統(tǒng)的采樣法更好。為了得到更好的結(jié)果�,你可以使用一些更前沿的方法,諸如基于boosting 的人工數(shù)據(jù)合成���。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試���,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材��,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量����,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330