騙子也玩大數(shù)據(jù)��?來自數(shù)據(jù)分析師的揭秘
近年在很多揭露詐騙的報(bào)道中��,常常出現(xiàn)老太太接到電話說孫子出事了�、老板接到電話說稅務(wù)局要查稅等案例,為什么現(xiàn)在騙子“對號入座”的本事這么強(qiáng)?
其實(shí)��,這與騙子們從“撒網(wǎng)式詐騙”向“精準(zhǔn)詐騙”升級有著密切關(guān)系�。這年頭競爭這么激烈,有一批騙子已經(jīng)進(jìn)化為具有大數(shù)據(jù)工匠精神的大騙子�。據(jù)了解,很多騙子在非法獲取個(gè)人信息之后�����,會利用大數(shù)據(jù)方法進(jìn)行分析,并根據(jù)用戶信息的特點(diǎn)設(shè)計(jì)詐騙環(huán)節(jié)和故事�����,從而進(jìn)行“精準(zhǔn)式詐騙”���。而“航班取消”�����、“二胎生育退費(fèi)”�、“推薦必漲股票”���、“交通違章提醒”�����、“信用卡提額”等等���,都成為騙子慣用的手法。
其實(shí)�,這些伎倆在專業(yè)的數(shù)據(jù)分析員眼里,其實(shí)并非什么神奇的事情���。
想要騙到你���,騙子最需要以下三類數(shù)據(jù)
想要成為一個(gè)成功率高的大騙子����,首先必須獲得客戶數(shù)據(jù)���,無論這數(shù)據(jù)是通過廣撒 “木馬”搜集來的,還是在地下數(shù)據(jù)交易市場弄來的��,在這各種類別的數(shù)據(jù)中����,有三類是騙子們比較關(guān)注的:
一是身份類信息,最常見的是姓名與身份證號的表格�����,這種信息出貨多���,泄露渠道多樣���,市場上供大于求。還有些擴(kuò)充了性別、年齡����、工作單位、職級�����、年收入等��,通常來源于收入調(diào)查與黑客拖庫數(shù)據(jù)��。
二是金融類信息��,姓名�、銀行卡號、信用卡卡號�����、開卡行����、手機(jī)、地址�、信用額度等數(shù)據(jù)�����,此數(shù)據(jù)大部分來源于制卡郵寄等環(huán)節(jié)的信息泄露�,制卡工廠�、快遞公司、郵局��、物流點(diǎn)都有可能成為泄露點(diǎn)�����,另一小部分是內(nèi)鬼數(shù)據(jù)�����,市場供不應(yīng)求�����、價(jià)值極高�����。
三是金融賬號密碼�,主要是各大銀行登錄類的,通常是黑客數(shù)據(jù)�,來源于釣魚、撞庫等黑客行為�,通過此類數(shù)據(jù)往往能獲得更詳細(xì)的金融數(shù)據(jù),如詳細(xì)交易流水�。

利用特征選擇進(jìn)行“精準(zhǔn)欺詐”
一旦騙子拿到了上述這些數(shù)據(jù),接下來他就要篩選出易騙人群進(jìn)行“對號入座”��。只要運(yùn)用大數(shù)據(jù)的思維方式�����, “選擇易騙人群”這個(gè)需求就變成了一個(gè)有監(jiān)督的模型學(xué)習(xí)問題�����。而一般針對監(jiān)督模型的特征選擇有如下五種方法:
利用相關(guān)性對變量進(jìn)行排序
自變量x1,x2,..xn�,目標(biāo)變量y,變量xi和y的相關(guān)性越高��,則xi所包含的用于預(yù)測y的信息量越大��,從而其排序越高����?��?梢杂肞earson相關(guān)系數(shù)來衡量兩個(gè)變量的線性相關(guān)性:
利用Pearson相關(guān)系數(shù)來做變量排序有以下問題:
(1)只考慮單一變量的重要性,很多變量單獨(dú)存在時(shí)沒有用���,但和其他變量結(jié)合在一起后則會起到顯著作用;
(2)依賴于自變量和目標(biāo)變量之間的線性假設(shè)��。
(3)適用于回歸問題��,即���,目標(biāo)變量y是連續(xù)的,對于分類問題應(yīng)用起來需要謹(jǐn)慎��。
單變量分類器
如1里面提到的���,對于分類問題,利用相關(guān)性對變量進(jìn)行排序可能會出現(xiàn)問題��。一個(gè)簡單的將上述思路拓展到分類問題的方法是�,構(gòu)造一個(gè)單變量分類器,然后依據(jù)單個(gè)變量對y的預(yù)測能力進(jìn)行排序�。單變量的預(yù)測能力可以通過IV或者AUC等各種指標(biāo)進(jìn)行評估。除此之外��,對于分類變量卡方檢驗(yàn)也是常見的篩選特征的方法,基本思想是假設(shè)兩個(gè)變量獨(dú)立���,利用列聯(lián)表的數(shù)據(jù)計(jì)算實(shí)際頻數(shù)與理論頻數(shù)的差異�����,如有顯著差異則拒絕原假設(shè)認(rèn)為變量間是有相關(guān)關(guān)系�,反之接受原假設(shè)���。

信息增益
信息增益是一種有效的特征選擇方法��,它的公式:
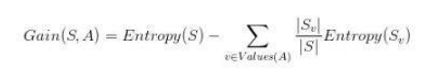
對于公式的解釋為:原本分類的信息熵減去加入特征后分類的條件熵��,兩者的差值就是這個(gè)特征給分類帶來的“凈化”程度��,如果信息增益越大�����,該特征對于分類來說就越有價(jià)值��。其中熵表示不確定程度���,分布越均勻����,越不確定���,熵越大����。
逐步回歸法
上述的三種方法都是對單變量進(jìn)行排序����,不能考慮這個(gè)變量在和其他變量結(jié)合在一起時(shí)的作用。為了解決這個(gè)問題��,可以用forward selection�����、backward selection和stepwise selection的方法����。
forward selection是從截距項(xiàng)開始依次按顯著性水平將自變量一個(gè)一個(gè)地加入模型�����,直到?jīng)]有滿足顯著性水平的變量可以加入為止�����。
backward selection一開始所有變量都在模型中�,將不符合顯著性水平的變量依次剔除���,值得一提的是存在于某些情況多個(gè)變量各自對目標(biāo)變量不顯著��,但組合起來能顯著的提高模型的表現(xiàn)��,這種情況在采用forward selection的情況下變量是進(jìn)入不了模型的���,而采用backward selection可以解決這個(gè)問題。
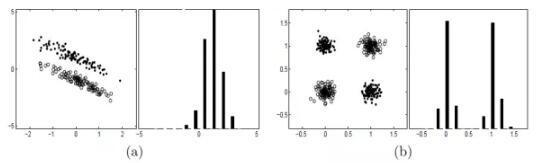
如圖1(a)所示X2變量(縱軸)能區(qū)分分類1����、0,X1變量(橫軸)完全是不顯著的�����,如圖1(b)將X2變量替換成X3變量����,兩個(gè)變量組合的區(qū)分能力要好于之前一個(gè)變量���,完全不顯著的變量可能與其他變量組合顯著提高區(qū)分能力。
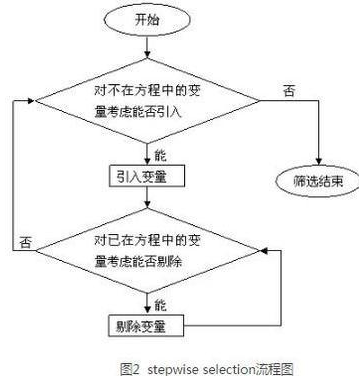
stepwise selection����,依次按顯著性水平將變量一個(gè)一個(gè)加入,同時(shí)對已加入的變量做顯著性檢驗(yàn)����,如果原來變量因?yàn)樾碌淖兞考尤攵兊貌辉亠@著,那就將它剔除模型��。stepwise的優(yōu)勢在于能保證方程中的變量全部顯著�����,而方程外無顯著性的變量��。
Lasso回歸
為進(jìn)一步消除變量間共線性的問題����,可以通過Lasso回歸�����,其本質(zhì)是通過在損失函數(shù)中加入懲罰函數(shù)項(xiàng),在增加細(xì)微偏差的同時(shí)換取更小的預(yù)測方差��,并使得模型變量更為精煉����、解釋性更強(qiáng)。
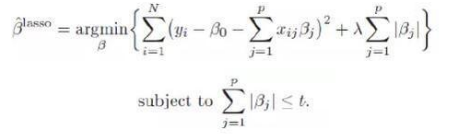
其中����,使用懲罰約束來篩選擬合模型中的系數(shù),當(dāng)t值小到一定程度��,估計(jì)參數(shù)的估值是0��,這樣就起到了變量篩選的作用�。當(dāng)t不斷增大,選入模型的變量會增多��,當(dāng)t增大到某個(gè)值時(shí)所有變量都會進(jìn)入��,這是就相當(dāng)于傳統(tǒng)方法的參數(shù)估計(jì)�。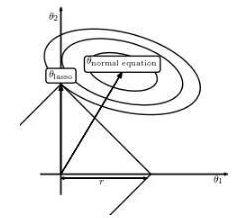
如圖3,L1正規(guī)化的約束條件是圖中坐標(biāo)中心方形區(qū)域����,而傳統(tǒng)方法偏差最小的估計(jì)是以第一象限橢圓區(qū)域?yàn)橹行南蛲鈹U(kuò)散�,故最優(yōu)解是在兩者的臨界點(diǎn)���,即對應(yīng)方形與橢圓形的切點(diǎn)�����,此時(shí)對應(yīng)的q1 為0���,起到了變量篩選的作用。
大數(shù)據(jù)如何篩選出信用卡詐騙易騙人群
我們再以信用卡提額詐騙舉例�����。就目前披露的數(shù)據(jù)顯示����,某一銀行在短短的3個(gè)月時(shí)間內(nèi)接到被騙客戶投訴數(shù)突增6000多起,占到欺詐案件總數(shù)的48%以上��。為何看似老套的欺詐手段�����,為什么還有這么多人上當(dāng)受騙呢?
前面我們提到,特征選擇剔除不顯著的變量�,能有效的提高模型的預(yù)測能力����,降低模型的復(fù)雜度從而減少更多的預(yù)測方差,增強(qiáng)模型的可解釋性��。我們以信用卡申請人的一組信息為樣本�,模擬一下騙子的篩選過程。
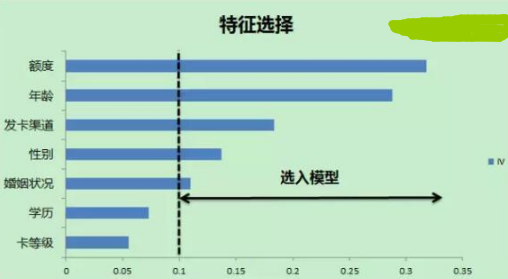
圖4
見圖4�����,經(jīng)過對客戶信息進(jìn)行“特征選擇”�,可以看出“額度”、“年齡”���、“發(fā)卡渠道”����、“性別”����、“婚姻狀況”是最具有信息價(jià)值的變量���,可以從這五個(gè)維度對名單進(jìn)行篩選,從而進(jìn)行“精準(zhǔn)詐騙”����。
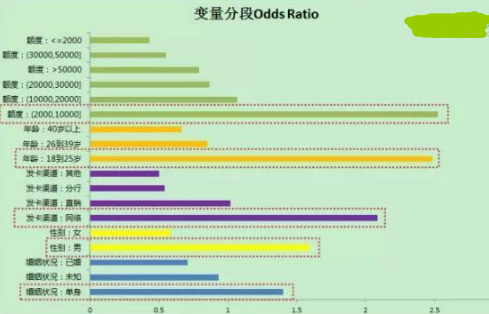
圖5
那么,從選出的五個(gè)維度的特征來看���,什么樣的人最容易上當(dāng)呢?通過網(wǎng)絡(luò)申請數(shù)據(jù)��,我們得到圖5的結(jié)果����,其中橫坐標(biāo)表示被欺騙的容易程度��,取值越大���,越容易被欺騙���。從圖可以看出:
1、信用卡額度較低但對資金需求量大的年輕人(18-25歲)����,提額對其誘惑較大��,因此容易成為目標(biāo)人群;
2�、通過網(wǎng)絡(luò)發(fā)卡的渠道可能更容易遇到信息泄漏;
3�、單身的男性一般有易輕信、嫌麻煩��、求助資源少的情況��,容易被騙子利用�����。
老話說����,“知己知彼�����,才能百戰(zhàn)不殆”��。只有深入的了解騙子們所使用的方法�,才能更好的做好反欺詐工作,有針對性地去做一些數(shù)據(jù)上的深挖�。另一方面�,電話欺詐的根源仍然是數(shù)據(jù)泄露的問題�����,相關(guān)企業(yè)要加強(qiáng)信息安全方面的投入建設(shè)�,咱們每個(gè)個(gè)人更要樹立起對隱私數(shù)據(jù)保護(hù)的安全意識,為共同維護(hù)安全的信息生態(tài)圈而努力�。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情���;
? 想學(xué)習(xí)CDA考試教材����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫�����,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量���,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330