為什么機(jī)器學(xué)習(xí)真的可以學(xué)到東西
開始跟《機(jī)器學(xué)習(xí)基石》這門課����,相對(duì)于Stanford那門課����,這門明顯難度大很多,我跟到第10個(gè)Lecture�����,才剛剛講到Logistic Regression����。前面費(fèi)了很大力氣在講機(jī)器什么時(shí)候可以學(xué)習(xí),以及證明為什么能學(xué)習(xí)���。
此文主要是基于《機(jī)器學(xué)習(xí)基石》的學(xué)習(xí)筆記�。Topic是為什么機(jī)器可以學(xué)習(xí)?
下面是一個(gè)粗略的機(jī)器學(xué)習(xí)流程圖
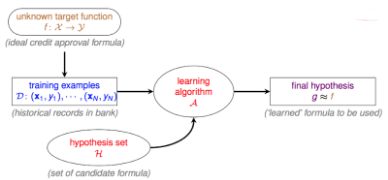
機(jī)器學(xué)習(xí)最開始也是最終的目的是獲得一個(gè)target function����,喂進(jìn)去數(shù)據(jù)能直接得到正確結(jié)論的函數(shù)。為了得到這個(gè)函數(shù)�����,我們需要一大堆的訓(xùn)練數(shù)據(jù)���。然后通過一個(gè)好的機(jī)器學(xué)習(xí)算法����,從一大堆可能的function(也就是H)中挑選一個(gè)比較好的function(也就是g)�,這個(gè)g和target function長得越像越好�。
Hoeffding’s inequality
大家有沒有想過,為什么這樣就能學(xué)到東西���。我們的算法只是在訓(xùn)練數(shù)據(jù)上跑���,從訓(xùn)練數(shù)據(jù)跑出來的g,我們?cè)趺茨艽_定它也能在測試數(shù)據(jù)上跑的很好呢�?這個(gè)就是問題的關(guān)鍵。其實(shí)接下來內(nèi)容主要就是論證這個(gè)問題。
先來考慮一個(gè)簡單的問題����。比如說我們現(xiàn)在有一個(gè)黑罐子,里面有很多彈珠�����,只有兩種顏色���,黃的和綠的����。好現(xiàn)在問你�����,你怎么能知道黃色彈珠大概有多少顆���?
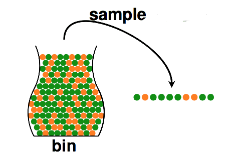
大家肯定都會(huì)說抽樣���。沒錯(cuò),我們抽出10個(gè)彈珠�,很容易能知道黃色彈珠在sample中的比例。但是這個(gè)比例真的能代表罐子中的比例嗎?也許能�,也許不能。而且能的記錄會(huì)隨著我們sample數(shù)目的增大而增大���。但是也有可能你抓出一把全綠��。但這種情況發(fā)生的記錄很小�。這里我們有一個(gè)定理保證這種偏差發(fā)生的記錄很小��。
Hoeffding's inequality可以保證偏差很大發(fā)生的幾率很小���,并且隨著N的增大很減小���。公式如下,v代表sample中黃色彈珠的比例��,μ表示罐子中黃色彈珠的比例���。?也就是偏差。

壞事的發(fā)生
現(xiàn)在我們稱v為Ein,μ為Eout���,現(xiàn)在我們已經(jīng)證明了Ein和Eout不會(huì)差的太遠(yuǎn)�,更重要的事情是保重Ein越小越好,這就需要一個(gè)好的算法����。
還記得上面的學(xué)習(xí)流程嗎,我們的算法是從很多個(gè)h中去挑選一個(gè)Ein最小的h讓它成為g�����。但是這里會(huì)有壞事情發(fā)生���。
所謂的壞事情就是bad sample���,就是說我們抽出了十個(gè)全是綠的彈珠。現(xiàn)在有一個(gè)好的h稱之為h1��,和壞的h叫h2���,h1對(duì)于這個(gè)bad sample的表現(xiàn)當(dāng)然是糟糕的��,而恰好h2表現(xiàn)很好���,那h2就被選成g了。
當(dāng)出現(xiàn)壞事的時(shí)候���,我們學(xué)習(xí)就會(huì)困難��,可以直接說不能學(xué)習(xí)�����。所以這個(gè)壞事出現(xiàn)的概率是多少呢�?把所有h中發(fā)生壞事的幾率加起來。

從上圖的式子中可以看到�,壞事發(fā)生的幾率和M有關(guān)。M也就是h的個(gè)數(shù)�����。
從現(xiàn)在的條件來看�,如果M很大甚至無線的話那么Learning是不可行的���。
無效的Hypothesis
真實(shí)的情況是M一般不會(huì)很大��,請(qǐng)?jiān)僮屑?xì)看看上一張圖的推導(dǎo)����,M是通過把所有的h壞事發(fā)生的概率加起來的����,但是其實(shí)這些h不是互相獨(dú)立的。所以這些h是有重復(fù)的��,如下圖�。
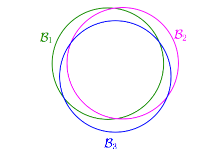
比如說,我們想學(xué)習(xí)的target function是一條把x1分類成正負(fù)的線?����,F(xiàn)在h就有無數(shù)個(gè)����,因?yàn)槿我庖粭l線都能分類,但是實(shí)際有意義的只有兩種��,分成正的和負(fù)的。
如果是兩個(gè)點(diǎn)的話,實(shí)際有效的h就有4種,但是3個(gè)點(diǎn)就有可能不到8種了,因?yàn)闀?huì)出現(xiàn)三點(diǎn)共線的情況��。4個(gè)點(diǎn)的話按理說有16種,但是同樣有一種情況不會(huì)發(fā)生��,請(qǐng)看下圖�。
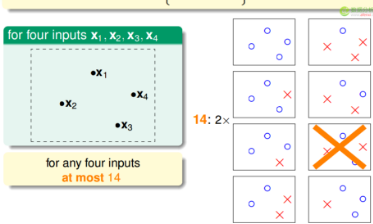
所以現(xiàn)在我們的公式就變成了這樣�,大大減小M的個(gè)數(shù)

成長函數(shù)的上限
現(xiàn)在我們給上面effective(N)一個(gè)稱呼,叫做成長函數(shù)����。也就是說��,對(duì)于某一個(gè)輸入D,H最多能夠產(chǎn)生的多少種方程。注意是種類的數(shù)量����。
這個(gè)所謂的種類我們也給一個(gè)定義叫做dichotomy,用來表示H對(duì)與D的二元分類情況。
好,現(xiàn)在問題的關(guān)鍵,就是H到底能把D分成多少個(gè)dichotomy�����。也就是它的成長函數(shù)到底是多少���?
但是我們很難確定它的成長函數(shù)�����。但是好在我們擁有一個(gè)叫做break point的東西���,這就是成長函數(shù)的上限���。我們?cè)倏椿厣厦娣诸惖睦印?
-
一個(gè)點(diǎn)能分成兩種
-
兩個(gè)點(diǎn)分成四種
-
三個(gè)點(diǎn)分成六種或者八種
-
四個(gè)點(diǎn)只有14種(break point)
這里的輸入為三個(gè)點(diǎn)就是一個(gè)break point。也就是說當(dāng)輸入N個(gè)點(diǎn)�����,H不能夠把這個(gè)N個(gè)點(diǎn)的排列組合全部表示出來時(shí)(2^N),N就是一個(gè)break point��。
當(dāng)H能把N的全部組合表示出來時(shí),說明這N個(gè)點(diǎn)被H給shatter掉了
我們用B(N,k)來表示當(dāng)輸入N個(gè)點(diǎn)時(shí)����,H可以最多產(chǎn)生多少個(gè)dichotomy��。
通過數(shù)學(xué)歸納法我們可以證明到

VC BOUND
現(xiàn)在到了最后一步�,除了把上邊那個(gè)成長函數(shù)的上限代入進(jìn)去之外,還需要進(jìn)行一系列的變形����,這些變形需要很強(qiáng)的數(shù)學(xué)能力和概率上面的知識(shí),我自己都不太懂�����,況且我覺得大部分人都不需要了解。這里我就略過��,有興趣的強(qiáng)人自己google咯�����。
最終的式子如下
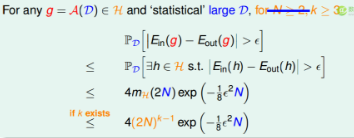
好了�,現(xiàn)在我們終于能說機(jī)器學(xué)習(xí)確實(shí)可以學(xué)到東西了。但是需要滿足三個(gè)條件�。
-
有一個(gè)好的H(擁有break point)
-
足夠多的數(shù)據(jù)
-
好的算法,能夠使Ein足夠小
這三者的關(guān)系如下圖�����。

dvc = k - 1��,大致上可以把它看出theta的維度加1
上圖很清晰的說明����,并不是說你的模型搞得很復(fù)雜���,算法弄得很好��,就能學(xué)好��,反而是取到一個(gè)折中的點(diǎn)���,這樣的學(xué)習(xí)才最有效�。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試��,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�����;
? 想學(xué)習(xí)CDA考試教材����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫�����,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330