丨前言
本文將系統(tǒng)的講解數(shù)據(jù)挖掘領(lǐng)域的經(jīng)典聚類算法,并給予代碼實現(xiàn)示例��。雖然當(dāng)下已有很多平臺都集成了數(shù)據(jù)挖掘領(lǐng)域的經(jīng)典算法模塊�����,但筆者認為要深入理解算法的核心���,剖析算法的執(zhí)行過程���,那么通過代碼的實現(xiàn)及運行結(jié)果來進行算法的驗證,這樣的過程是很有必要的��。因此本文���,將有助于讀者對經(jīng)典聚類算法的深入學(xué)習(xí)與理解�����。
丨聚類和分類的區(qū)別
一開始筆者就想談?wù)勥@個話題����,畢竟在數(shù)據(jù)挖掘算法領(lǐng)域����,這兩者有著很大的差別,對于初學(xué)者很容易混淆��。拋開晦澀的定義陳述����,在此我們先通過兩個生活比喻看看什么是監(jiān)督學(xué)習(xí),什么是非監(jiān)督學(xué)習(xí)���。
回首我們?nèi)松蠲篮玫亩罐⒛耆A��,那時的我們���,少年初長成����,結(jié)束了小學(xué)生涯���,步入初中��,這個年齡是我們?nèi)松械谝粋€分水嶺����。初中一年級剛?cè)雽W(xué)時�,同學(xué)們之間彼此不認識,老師對同學(xué)們也都不熟悉��。但隨著時間的推移����,同學(xué)們基本上都分成了三五群,回想一下那時的我們���,是不是整天玩在一起的同學(xué)總是那幾個�����?我們發(fā)現(xiàn)��,這個過程老師是不參與的����,老師不會讓同學(xué)們分成幾組�,讓哪幾個同學(xué)經(jīng)常在一起學(xué)習(xí)和玩耍。想想這個過程���,其實是我們自己辨別和哪些同學(xué)合得來一個過程�,這期間我們可能會判斷同學(xué)的性格����,學(xué)習(xí)成績,共同愛好與話題�,是否和同學(xué)家離的很近還能一起上學(xué)和回家等等很多的維度因素。時間久了�����,班級里就會出現(xiàn)不同的幾個圈子,這個圈子的數(shù)量及細節(jié)一開始并沒有人知曉�,并且這個過程無老師進行監(jiān)督,因此我們視之為無監(jiān)督學(xué)習(xí)�。在此我們指出,聚類算法是無監(jiān)督學(xué)習(xí)的算法���。
初中三年級�����,因為我們背負著中考的重擔(dān)�����,大家都為了自己的理想高中做最后的沖刺努力��。設(shè)想這樣一種情況:為了更好的幫助大家不斷提高學(xué)習(xí)成績�����,班主任老師將班級分成了五個互幫互助小組(語文�、數(shù)學(xué)�����、物理、生物���、英語)���,每個小組十位同學(xué),分別是班級里這幾個科目考試成績最好的前十名同學(xué)����,為了達到更好的互幫互助效果����,每位達到條件要求的同學(xué)只能加入一門科目小組,也就是說�����,如果某位同學(xué)有兩門或兩門以上的科目都排在班級前十名��,則班主任老師隨機指定其加入某一小組���。這樣所有同學(xué)都可以在互幫互助小組的幫助下更大程度的提升自己的薄弱科目����,實現(xiàn)共贏。在此我們可以看到小組的種類���,數(shù)量�����,都是定義好的�����,只需要老師指定好各個小組的成員����。因此��,這樣的學(xué)習(xí)過程是一種監(jiān)督學(xué)習(xí)過程�����,老師給出小組的種類和數(shù)量用排名的方式來監(jiān)督并激勵學(xué)生學(xué)習(xí)����。在此我們指出��,分類算法是監(jiān)督學(xué)習(xí)的算法���。
總結(jié)一下,數(shù)據(jù)分類是分析已有的數(shù)據(jù)�,尋找其共同的屬性,并根據(jù)分類模型將這些數(shù)據(jù)劃分成不同的類別��,這些數(shù)據(jù)賦予類標號�。這些類別是事先定義好的,并且類別數(shù)是已知的�。相反,數(shù)據(jù)聚類則是將本沒有類別參考的數(shù)據(jù)進行分析并劃分為不同的組�,即從這些數(shù)據(jù)導(dǎo)出類標號。聚類分析本身則是根據(jù)數(shù)據(jù)來發(fā)掘數(shù)據(jù)對象及其關(guān)系信息�����,并將這些數(shù)據(jù)分組�。每個組內(nèi)的對象之間是相似的��,而各個組間的對象是不相關(guān)的���。不難理解���,組內(nèi)相似性越高���,組間相異性越高,則聚類越好��。
丨K 均值算法詳解及實現(xiàn)
算法流程
K 均值算法����,應(yīng)該是聚類算法中最為基礎(chǔ)但也最為重要的算法。其算法流程如下:
隨機的取 k 個點作為 k 個初始質(zhì)心�����;
計算其他點到這個 k 個質(zhì)心的距離���;
如果某個點 p 離第 n 個質(zhì)心的距離更近����,則該點屬于 cluster n���,并對其打標簽����,標注 point p.label=n,其中 n<=k����;
計算同一 cluster 中,也就是相同 label 的點向量的平均值��,作為新的質(zhì)心�����;
迭代至所有質(zhì)心都不變化為止���,即算法結(jié)束�����。
當(dāng)然算法實現(xiàn)的方法有很多����,比如在選擇初始質(zhì)心時�����,可以隨機選擇 k 個�,也可以隨機選擇 k 個離得最遠的點等等,方法不盡相同�。
K 值估計
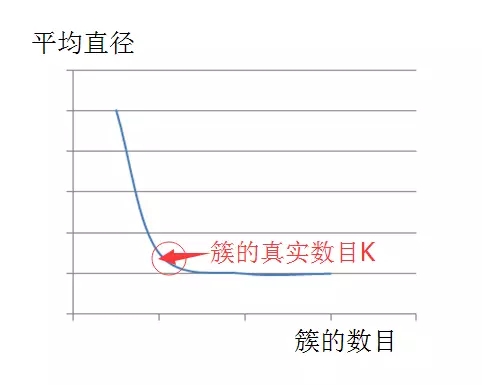
對于 k 值,必須提前知道���,這也是 kmeans 算法的一個缺點���。當(dāng)然對于 k 值,我們可以有很多種方法進行估計�。本文中,我們采用平均直徑法來進行 k 的估計��。
也就是說���,首先視所有的點為一個大的整體 cluster�����,計算所有點之間距離的平均值作為該 cluster 的平均直徑�����。選擇初始質(zhì)心的時候����,先選擇最遠的兩個點,接下來從這最兩個點開始���,與這最兩個點距離都很遠的點(遠的程度為����,該點到之前選擇的最遠的兩個點的距離都大于整體 cluster 的平均直徑)可視為新發(fā)現(xiàn)的質(zhì)心����,否則不視之為質(zhì)心。設(shè)想一下�����,如果利用平均半徑或平均直徑這一個指標�����,若我們猜想的 K 值大于或等于真實的 K 值����,也就是簇的真實數(shù)目,那么該指標的上升趨勢會很緩慢�,但是如果我們給出的 K 值小于真實的簇的數(shù)目時,這個指標一定會急劇上升�����。
根據(jù)這樣的估算思想����,我們就能估計出正確的 k 值,并且得到 k 個初始質(zhì)心�����,接著�,我們便根據(jù)上述算法流程繼續(xù)進行迭代,直到所有質(zhì)心都不變化��,從而成功實現(xiàn)算法��。如下圖所示:
圖 1. K 值估計
 我們知道 k 均值總是收斂的�����,也就是說����,k 均值算法一定會達到一種穩(wěn)定狀態(tài),在此狀態(tài)下����,所有的點都不會從一個簇轉(zhuǎn)移到另一個簇�,因此質(zhì)心不在發(fā)生改變�����。在此����,我們引出一個剪枝優(yōu)化,即:k 均值最明顯的收斂過程會發(fā)生在算法運行的前期階段����,故在某些情況下為了增加算法的執(zhí)行效率,我們可以替換上述算法的第五步��,采用“迭代至僅有 1%~3%的點在影響質(zhì)心”或“迭代至僅有 1%~3%的點在改變簇”�����。
k 均值適用于絕大多數(shù)的數(shù)據(jù)類型�,并且簡單有效。但其缺點就是需要知道準確的 k 值����,并且不能處理異形簇��,比如球形簇�,不同尺寸及密度的簇����,環(huán)形簇等等���。
本文主要為算法講解及實現(xiàn)����,因此代碼實現(xiàn)暫不考慮面向?qū)ο笏枷?����,采用面向過程的實現(xiàn)方式��,如果數(shù)據(jù)多維�����,可能會需要做數(shù)據(jù)預(yù)處理��,比如歸一化,并且修改代碼相關(guān)方法即可�����。
算法實現(xiàn)
清單 1. Kmeans 算法代碼實現(xiàn)
我們知道 k 均值總是收斂的�����,也就是說����,k 均值算法一定會達到一種穩(wěn)定狀態(tài),在此狀態(tài)下����,所有的點都不會從一個簇轉(zhuǎn)移到另一個簇�,因此質(zhì)心不在發(fā)生改變�����。在此����,我們引出一個剪枝優(yōu)化,即:k 均值最明顯的收斂過程會發(fā)生在算法運行的前期階段����,故在某些情況下為了增加算法的執(zhí)行效率,我們可以替換上述算法的第五步��,采用“迭代至僅有 1%~3%的點在影響質(zhì)心”或“迭代至僅有 1%~3%的點在改變簇”�����。
k 均值適用于絕大多數(shù)的數(shù)據(jù)類型�,并且簡單有效。但其缺點就是需要知道準確的 k 值����,并且不能處理異形簇��,比如球形簇�,不同尺寸及密度的簇����,環(huán)形簇等等���。
本文主要為算法講解及實現(xiàn)����,因此代碼實現(xiàn)暫不考慮面向?qū)ο笏枷?����,采用面向過程的實現(xiàn)方式��,如果數(shù)據(jù)多維�����,可能會需要做數(shù)據(jù)預(yù)處理��,比如歸一化,并且修改代碼相關(guān)方法即可�����。
算法實現(xiàn)
清單 1. Kmeans 算法代碼實現(xiàn)






測試數(shù)據(jù)
給出一組簡單的二維測試數(shù)據(jù):
清單 2. Kmeans 算法測試數(shù)據(jù)
 運行結(jié)果
清單 3. Kmeans 算法運行結(jié)果
運行結(jié)果
清單 3. Kmeans 算法運行結(jié)果
 丨層次聚類算法詳解及實現(xiàn)
層次聚類簡介
層次聚類分為凝聚式層次聚類和分裂式層次聚類���。
凝聚式層次聚類����,就是在初始階段將每一個點都視為一個簇�����,之后每一次合并兩個最接近的簇�����,當(dāng)然對于接近程度的定義則需要指定簇的鄰近準則�。
分裂式層次聚類,就是在初始階段將所有的點視為一個簇����,之后每次分裂出一個簇,直到最后剩下單個點的簇為止�。
本文中我們將詳細介紹凝聚式層次聚類算法�。
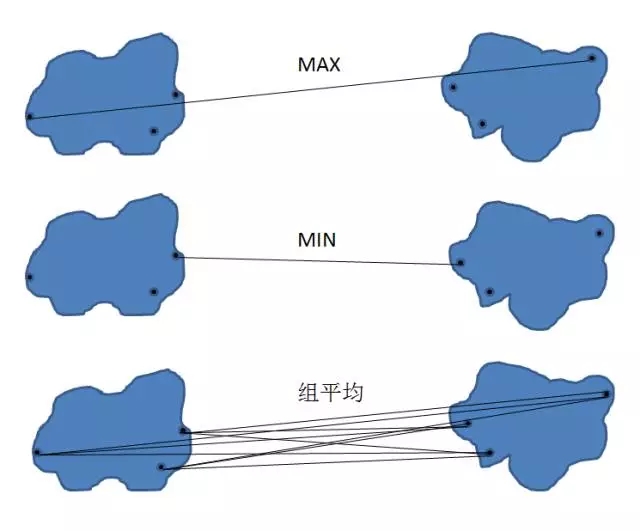
對于凝聚式層次聚類��,指定簇的鄰近準則是非常重要的一個環(huán)節(jié)����,在此我們介紹三種最常用的準則,分別是 MAX�, MIN�����, 組平均�。如下圖所示:
圖 2. 層次聚類計算準則
丨層次聚類算法詳解及實現(xiàn)
層次聚類簡介
層次聚類分為凝聚式層次聚類和分裂式層次聚類���。
凝聚式層次聚類����,就是在初始階段將每一個點都視為一個簇�����,之后每一次合并兩個最接近的簇�����,當(dāng)然對于接近程度的定義則需要指定簇的鄰近準則�。
分裂式層次聚類,就是在初始階段將所有的點視為一個簇����,之后每次分裂出一個簇,直到最后剩下單個點的簇為止�。
本文中我們將詳細介紹凝聚式層次聚類算法�。
對于凝聚式層次聚類��,指定簇的鄰近準則是非常重要的一個環(huán)節(jié)����,在此我們介紹三種最常用的準則,分別是 MAX�, MIN�����, 組平均�。如下圖所示:
圖 2. 層次聚類計算準則
 算法流程
凝聚式層次聚類算法也是一個迭代的過程,算法流程如下:
每次選最近的兩個簇合并�����,我們將這兩個合并后的簇稱之為合并簇����。
若采用 MAX 準則,選擇其他簇與合并簇中離得最遠的兩個點之間的距離作為簇之間的鄰近度�。若采用 MIN 準則,取其他簇與合并簇中離得最近的兩個點之間的距離作為簇之間的鄰近度���。若組平均準則�����,取其他簇與合并簇所有點之間距離的平均值作為簇之間的鄰近度����。
重復(fù)步驟 1 和步驟 2,合并至只剩下一個簇�����。
算法過程舉例
下面我們看一個例子:
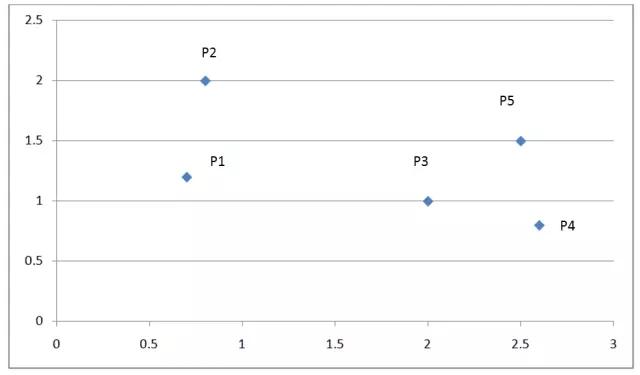
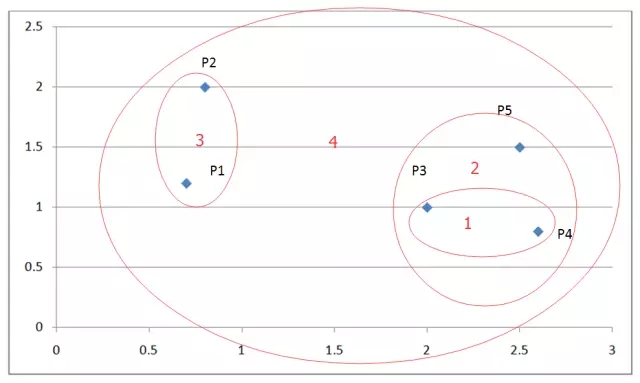
下圖是一個有五個點的而為坐標系:
圖 3. 層次聚類舉例
算法流程
凝聚式層次聚類算法也是一個迭代的過程,算法流程如下:
每次選最近的兩個簇合并�����,我們將這兩個合并后的簇稱之為合并簇����。
若采用 MAX 準則,選擇其他簇與合并簇中離得最遠的兩個點之間的距離作為簇之間的鄰近度�。若采用 MIN 準則,取其他簇與合并簇中離得最近的兩個點之間的距離作為簇之間的鄰近度���。若組平均準則�����,取其他簇與合并簇所有點之間距離的平均值作為簇之間的鄰近度����。
重復(fù)步驟 1 和步驟 2,合并至只剩下一個簇�����。
算法過程舉例
下面我們看一個例子:
下圖是一個有五個點的而為坐標系:
圖 3. 層次聚類舉例
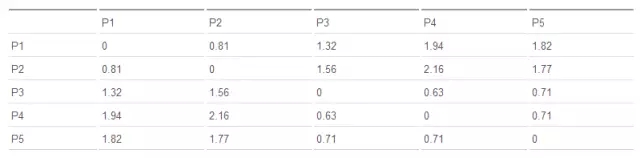
 下表為這五個點的歐式距離矩陣:
表 1. 歐式距離原始矩陣
下表為這五個點的歐式距離矩陣:
表 1. 歐式距離原始矩陣
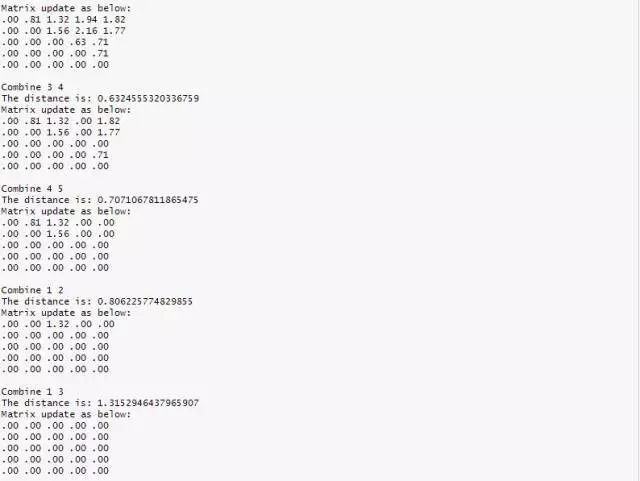
 根據(jù)算法流程����,我們先找出距離最近的兩個簇,P3����, P4。
合并 P3�����, P4 為 {P3��, P4},根據(jù) MIN 原則更新矩陣如下:
MIN.distance({P3����, P4}, P1) = 1.32����;
MIN.distance({P3, P4}��, P2) = 1.56���;
MIN.distance({P3, P4}����, P5) = 0.70;
表 2. 歐式距離更新矩陣 1
根據(jù)算法流程����,我們先找出距離最近的兩個簇,P3����, P4。
合并 P3�����, P4 為 {P3��, P4},根據(jù) MIN 原則更新矩陣如下:
MIN.distance({P3����, P4}, P1) = 1.32����;
MIN.distance({P3, P4}��, P2) = 1.56���;
MIN.distance({P3, P4}����, P5) = 0.70;
表 2. 歐式距離更新矩陣 1
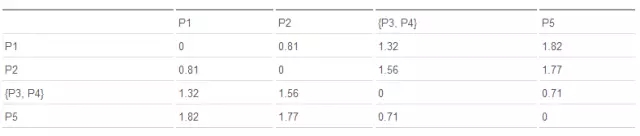 接著繼續(xù)找出距離最近的兩個簇��,{P3�����, P4}���, P5����。
合并 {P3, P4}����, P5 為 {P3, P4�����, P5}�,根據(jù) MIN 原則繼續(xù)更新矩陣:
MIN.distance(P1, {P3�, P4, P5}) = 1.32�;
MIN.distance(P2, {P3��, P4���, P5}) = 1.56��;
表 3. 歐式距離更新矩陣 2
接著繼續(xù)找出距離最近的兩個簇��,{P3�����, P4}���, P5����。
合并 {P3, P4}����, P5 為 {P3, P4�����, P5}�,根據(jù) MIN 原則繼續(xù)更新矩陣:
MIN.distance(P1, {P3�, P4, P5}) = 1.32�;
MIN.distance(P2, {P3��, P4���, P5}) = 1.56��;
表 3. 歐式距離更新矩陣 2
 接著繼續(xù)找出距離最近的兩個簇���,P1����, P2����。
合并 P1, P2 為 {P1�����, P2}��,根據(jù) MIN 原則繼續(xù)更新矩陣:
MIN.distance({P1���,P2}, {P3���, P4��, P5}) = 1.32
表 4. 歐式距離更新矩陣 3
接著繼續(xù)找出距離最近的兩個簇���,P1����, P2����。
合并 P1, P2 為 {P1�����, P2}��,根據(jù) MIN 原則繼續(xù)更新矩陣:
MIN.distance({P1���,P2}, {P3���, P4��, P5}) = 1.32
表 4. 歐式距離更新矩陣 3
 最終合并剩下的這兩個簇即可獲得最終結(jié)果��,如下圖:
圖 4. 層次聚類舉例結(jié)果
最終合并剩下的這兩個簇即可獲得最終結(jié)果��,如下圖:
圖 4. 層次聚類舉例結(jié)果
 MAX�,組平均算法流程同理,只是在更新矩陣時將上述計算簇間距離變?yōu)榇亻g兩點最大歐式距離����,和簇間所有點平均歐式距離即可。
算法實現(xiàn)
清單 4. 層次聚類算法代碼實現(xiàn)
MAX�,組平均算法流程同理,只是在更新矩陣時將上述計算簇間距離變?yōu)榇亻g兩點最大歐式距離����,和簇間所有點平均歐式距離即可。
算法實現(xiàn)
清單 4. 層次聚類算法代碼實現(xiàn)




測試數(shù)據(jù)
給出一組簡單的二維測試數(shù)據(jù)
清單 5. 層次聚類算法測試數(shù)據(jù)
 運行結(jié)果
清單 6. 層次聚類算法運行結(jié)果
運行結(jié)果
清單 6. 層次聚類算法運行結(jié)果
 丨DBSCAN 算法詳解及實現(xiàn)
考慮一種情況��,點的分布不均勻����,形狀不規(guī)則時,Kmeans 算法及層次聚類算法將面臨失效的風(fēng)險�����。
如下坐標系:
圖 5. DBSCAN 算法舉例
丨DBSCAN 算法詳解及實現(xiàn)
考慮一種情況��,點的分布不均勻����,形狀不規(guī)則時,Kmeans 算法及層次聚類算法將面臨失效的風(fēng)險�����。
如下坐標系:
圖 5. DBSCAN 算法舉例
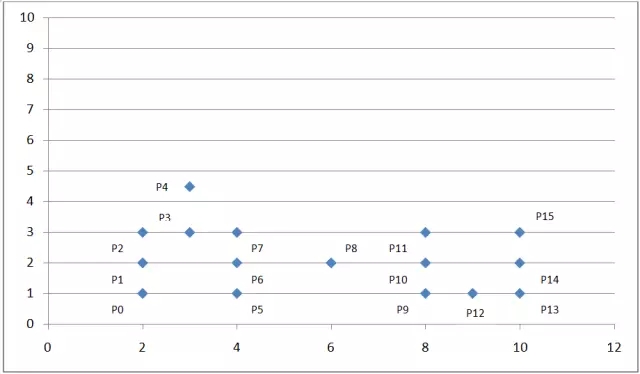 我們可以看到上面的點密度不均勻���,這時我們考慮采用基于密度的聚類算法:DBSCAN���。
算法流程
設(shè)定掃描半徑 Eps, 并規(guī)定掃描半徑內(nèi)的密度值��。若當(dāng)前點的半徑范圍內(nèi)密度大于等于設(shè)定密度值��,則設(shè)置當(dāng)前點為核心點�����;若某點剛好在某核心點的半徑邊緣上�,則設(shè)定此點為邊界點����;若某點既不是核心點又不是邊界點��,則此點為噪聲點。
刪除噪聲點。
將距離在掃描半徑內(nèi)的所有核心點賦予邊進行連通�����。
每組連通的核心點標記為一個簇。
將所有邊界點指定到與之對應(yīng)的核心點的簇總�����。
算法過程舉例
如上圖坐標系所示�����,我們設(shè)定掃描半徑 Eps 為 1.5,密度閾值 threshold 為 3���,則通過上述算法過程���,我們可以得到下圖:
圖 6. DBSCAN 算法舉例結(jié)果示例
我們可以看到上面的點密度不均勻���,這時我們考慮采用基于密度的聚類算法:DBSCAN���。
算法流程
設(shè)定掃描半徑 Eps, 并規(guī)定掃描半徑內(nèi)的密度值��。若當(dāng)前點的半徑范圍內(nèi)密度大于等于設(shè)定密度值��,則設(shè)置當(dāng)前點為核心點�����;若某點剛好在某核心點的半徑邊緣上�,則設(shè)定此點為邊界點����;若某點既不是核心點又不是邊界點��,則此點為噪聲點。
刪除噪聲點。
將距離在掃描半徑內(nèi)的所有核心點賦予邊進行連通�����。
每組連通的核心點標記為一個簇。
將所有邊界點指定到與之對應(yīng)的核心點的簇總�����。
算法過程舉例
如上圖坐標系所示�����,我們設(shè)定掃描半徑 Eps 為 1.5,密度閾值 threshold 為 3���,則通過上述算法過程���,我們可以得到下圖:
圖 6. DBSCAN 算法舉例結(jié)果示例
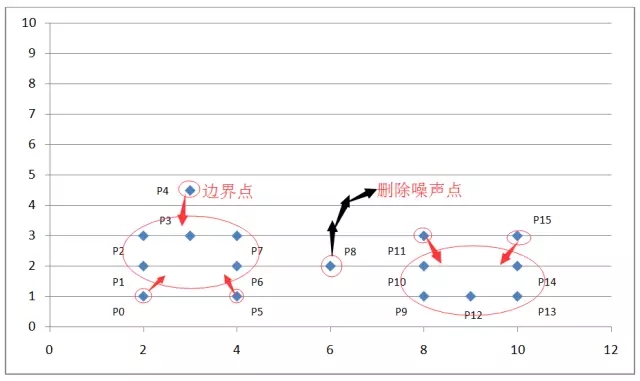 通過計算各個點之間的歐式距離及其所在掃描半徑內(nèi)的密度值來判斷這些點屬于核心點�,邊界點或是噪聲點����。因為我們設(shè)定了掃描半徑為 1.5�����,密度閾值為 3��,所以:
P0 點為邊界點����,因為在以其為中心的掃描半徑內(nèi)只有兩個點 P0 和 P1�;
P1 點為核心點���,因為在以其為中心的掃描半徑內(nèi)有四個點 P0,P1����,P2,P4 ���;
P8 為噪聲點��,因為其既非核心點��,也非邊界點����;
其他點依次類推�。
算法實現(xiàn)
清單 7. DBSCAN 算法代碼實現(xiàn)
通過計算各個點之間的歐式距離及其所在掃描半徑內(nèi)的密度值來判斷這些點屬于核心點�,邊界點或是噪聲點����。因為我們設(shè)定了掃描半徑為 1.5�����,密度閾值為 3��,所以:
P0 點為邊界點����,因為在以其為中心的掃描半徑內(nèi)只有兩個點 P0 和 P1�;
P1 點為核心點���,因為在以其為中心的掃描半徑內(nèi)有四個點 P0,P1����,P2,P4 ���;
P8 為噪聲點��,因為其既非核心點��,也非邊界點����;
其他點依次類推�。
算法實現(xiàn)
清單 7. DBSCAN 算法代碼實現(xiàn)
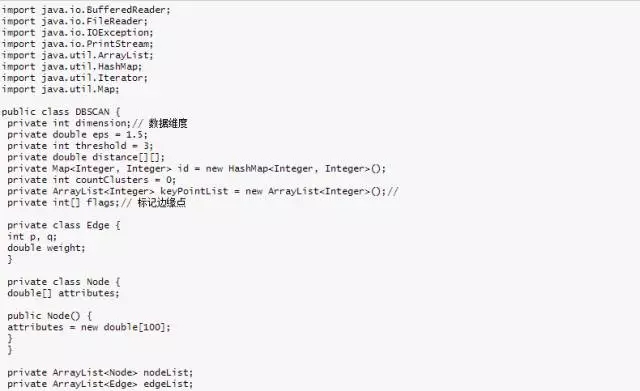





測試數(shù)據(jù)
清單 8. DBSCAN 算法測試數(shù)據(jù)

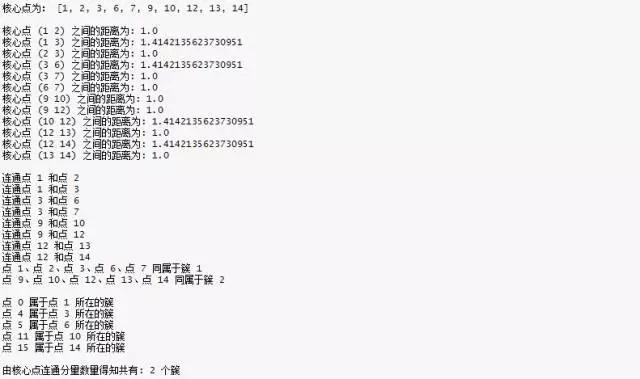
運行結(jié)果
清單 9. DBSCAN 算法運行結(jié)果
 丨其他聚類算法簡介
BIRCH 算法
Birch 是一種能夠高效處理大數(shù)據(jù)聚類的基于樹的層次聚類算法���。設(shè)想這樣一種情況,一個擁有大規(guī)模數(shù)據(jù)的數(shù)據(jù)庫�����,當(dāng)這些數(shù)據(jù)被放入主存進行聚類處理時����,一般的聚類算法則沒有對應(yīng)的高效處理能力,這時 Birch 算法是最佳的選擇。
Birth 不僅能夠高效地處理大數(shù)據(jù)聚類,并且能最小化 IO 花銷�����。它不需要掃描全局數(shù)據(jù)已經(jīng)現(xiàn)有的簇。
算法流程
聚類特征 CF=(N,LS��,SS)��,其中 N 代表簇中點的個數(shù)����,LS 代表簇中代表簇中各點線性和�,SS 代表簇中各點的平方和距離�����。聚類特征被應(yīng)用于 CF 樹中���,CF 樹是一種高度平衡樹�����,它具有兩個參數(shù):平衡因子 B 和簇半徑閾值 T��。其中平衡因子 B 代表每一個非葉子節(jié)點最多能夠引入 B 個實體條目�����。
葉子節(jié)點最多只能包含 L 個實體條目�,并且它們具有前向后向指針���,這樣可以彼此鏈接起來。
樹的大小取決于簇半徑閾值 T 的大小��。
從根節(jié)點開始����,遞歸查找與要插入的數(shù)據(jù)點距離最近的葉子節(jié)點中的實體條目��,遞歸過程選擇最短路徑��。
比較上述計算出的數(shù)據(jù)點與葉子節(jié)點中實體條目間的最近距離是否小葉簇半徑閾值 T�,小于則吸收該數(shù)據(jù)點�。否則執(zhí)行下一步。
判斷當(dāng)前條目所在的葉節(jié)點個數(shù)是否小于 L��,若小于則直接將該數(shù)據(jù)點插入當(dāng)前點����。否則分裂葉子節(jié)點,分裂過程是將葉子節(jié)點中距離最遠的兩個實體條目變?yōu)樾碌膬蓚€葉子節(jié)點��,其他條目則根據(jù)距離最近原則重新分配到這兩個新的葉子節(jié)點中����。刪除原來的葉子節(jié)點并更新 CF 樹。
若不能將所有數(shù)據(jù)點加入 CF 樹中��,則考慮增加簇半徑閾值 T�����,并重新更新 CF 樹直至所有的數(shù)據(jù)點被加入 CF 樹為止。
CURE 算法
算法流程
在數(shù)據(jù)集中選擇樣本數(shù)據(jù)�。
將上述樣本數(shù)據(jù)劃分為 P 個同樣大小的劃分。
將每個劃分中的點聚成 m/pq 個簇�,共得到 m/q 個簇。過程中需刪除噪聲點��。
對上述 m/q 個簇進行聚類直至剩下 k 個簇����。
繼續(xù)刪除離群點。
將剩下的點指派到最近的簇完成聚類過程����。
結(jié)束語
聚類算法是數(shù)據(jù)挖掘算法中最為重要的部分之一,算法種類繁多�����,應(yīng)用場景也各有不同�����,本文章提到的聚類算法為常見常用的一些較為基本的算法����,對于其他的聚類算法,如最小生成樹聚類��,CLIQUE��,DENCLUE���,SOM 等等如有興趣�,讀者可以自行查找相關(guān)資料進行學(xué)習(xí)�����。本文旨在提高讀者對算法本身的理解���,代碼實現(xiàn)過程及結(jié)果打印能夠更好的幫助讀者剖析算法����,使讀者能夠更快的入門并掌握基本的聚類算法�����。
參考資料
《數(shù)據(jù)挖掘導(dǎo)論》
丨其他聚類算法簡介
BIRCH 算法
Birch 是一種能夠高效處理大數(shù)據(jù)聚類的基于樹的層次聚類算法���。設(shè)想這樣一種情況,一個擁有大規(guī)模數(shù)據(jù)的數(shù)據(jù)庫�����,當(dāng)這些數(shù)據(jù)被放入主存進行聚類處理時����,一般的聚類算法則沒有對應(yīng)的高效處理能力,這時 Birch 算法是最佳的選擇。
Birth 不僅能夠高效地處理大數(shù)據(jù)聚類,并且能最小化 IO 花銷�����。它不需要掃描全局數(shù)據(jù)已經(jīng)現(xiàn)有的簇。
算法流程
聚類特征 CF=(N,LS��,SS)��,其中 N 代表簇中點的個數(shù)����,LS 代表簇中代表簇中各點線性和�,SS 代表簇中各點的平方和距離�����。聚類特征被應(yīng)用于 CF 樹中���,CF 樹是一種高度平衡樹�����,它具有兩個參數(shù):平衡因子 B 和簇半徑閾值 T��。其中平衡因子 B 代表每一個非葉子節(jié)點最多能夠引入 B 個實體條目�����。
葉子節(jié)點最多只能包含 L 個實體條目�,并且它們具有前向后向指針���,這樣可以彼此鏈接起來。
樹的大小取決于簇半徑閾值 T 的大小��。
從根節(jié)點開始����,遞歸查找與要插入的數(shù)據(jù)點距離最近的葉子節(jié)點中的實體條目��,遞歸過程選擇最短路徑��。
比較上述計算出的數(shù)據(jù)點與葉子節(jié)點中實體條目間的最近距離是否小葉簇半徑閾值 T�,小于則吸收該數(shù)據(jù)點�。否則執(zhí)行下一步。
判斷當(dāng)前條目所在的葉節(jié)點個數(shù)是否小于 L��,若小于則直接將該數(shù)據(jù)點插入當(dāng)前點����。否則分裂葉子節(jié)點,分裂過程是將葉子節(jié)點中距離最遠的兩個實體條目變?yōu)樾碌膬蓚€葉子節(jié)點��,其他條目則根據(jù)距離最近原則重新分配到這兩個新的葉子節(jié)點中����。刪除原來的葉子節(jié)點并更新 CF 樹。
若不能將所有數(shù)據(jù)點加入 CF 樹中��,則考慮增加簇半徑閾值 T�����,并重新更新 CF 樹直至所有的數(shù)據(jù)點被加入 CF 樹為止。
CURE 算法
算法流程
在數(shù)據(jù)集中選擇樣本數(shù)據(jù)�。
將上述樣本數(shù)據(jù)劃分為 P 個同樣大小的劃分。
將每個劃分中的點聚成 m/pq 個簇�,共得到 m/q 個簇。過程中需刪除噪聲點��。
對上述 m/q 個簇進行聚類直至剩下 k 個簇����。
繼續(xù)刪除離群點。
將剩下的點指派到最近的簇完成聚類過程����。
結(jié)束語
聚類算法是數(shù)據(jù)挖掘算法中最為重要的部分之一,算法種類繁多�����,應(yīng)用場景也各有不同�����,本文章提到的聚類算法為常見常用的一些較為基本的算法����,對于其他的聚類算法,如最小生成樹聚類��,CLIQUE��,DENCLUE���,SOM 等等如有興趣�,讀者可以自行查找相關(guān)資料進行學(xué)習(xí)�����。本文旨在提高讀者對算法本身的理解���,代碼實現(xiàn)過程及結(jié)果打印能夠更好的幫助讀者剖析算法����,使讀者能夠更快的入門并掌握基本的聚類算法�����。
參考資料
《數(shù)據(jù)挖掘導(dǎo)論》
《大數(shù)據(jù)-互聯(lián)網(wǎng)大規(guī)模數(shù)據(jù)挖掘與分布式處理》
文 | 楊翔宇 段偉瑋
來源 | IBM Developerworks
CDA LV2開設(shè)數(shù)據(jù)挖掘課程���,歡迎微信掃碼����,直達課程參加:


(CDA微店二維碼) (CDA數(shù)據(jù)分析師服務(wù)號)
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認證考試,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330