如何高效地學(xué)好R語言?
學(xué)R語言主要在于5點(diǎn)三階段:
第一階段有一點(diǎn):基礎(chǔ)的文件操作(read.*, write.*)、數(shù)據(jù)結(jié)構(gòu)知識(shí)���,認(rèn)識(shí)什么是數(shù)據(jù)框(data.frame)�、列表(list)���、矩陣(matrix)����、向量(vector),如何提取(包括which, [ ]等)��、置換(t, matrix等)����、刪除(-, which等)、運(yùn)算(+, -, *, / , %%, %/%等)�����、轉(zhuǎn)換(as.*)��、修改(edit, fix等)數(shù)據(jù)(包括單個(gè)數(shù)�、行、列����、表、變量)���,安裝包�����、調(diào)用包以及session的保存�����。完成這一階段����,你就大致能像excel里處理數(shù)據(jù)一樣了����。
第二階段有三點(diǎn):
1、學(xué)習(xí)統(tǒng)計(jì)����。
這是貫穿整個(gè)R學(xué)習(xí)的最重要的一部,很多時(shí)候你并不是不知道在哪里找�����,怎么使用某個(gè)函數(shù)的參數(shù)�,更多的時(shí)候你是不知道某個(gè)統(tǒng)計(jì)方法的原理,所代表的意義甚至不知道該用什么方法����。所以學(xué)習(xí)統(tǒng)計(jì)學(xué)知識(shí)往往才是學(xué)習(xí)R的關(guān)鍵,之后找函數(shù)、怎么用其實(shí)都是傻瓜式的��,并不需要你從頭編寫算法��。這部分內(nèi)容頁要結(jié)合每個(gè)人要做的事做��。
2��、批量處理��。
由于R和matlab一樣���,注重的是批量處理��,而且R之中的循環(huán)往往效率極低�����,所以在R之中如果你發(fā)現(xiàn)你要使用雙層循環(huán)的時(shí)候�����,就要想想了���,有沒有批量處理的方法。
a、首先����,幾乎所有的R里的運(yùn)算符和自帶的函數(shù)都是可以批量處理的。比如向量a+向量b是指每個(gè)元素按照index相加�����,所以就沒必要for一下了���;
b、其次�,R自帶有的apply族函數(shù)(因?yàn)槭且幌盗幸詀pply結(jié)尾的函數(shù),所以稱為apply族)�,split,以及aggregate函數(shù)���。這三類就是R自帶的批量處理的利器�,學(xué)好這三類函數(shù)��,基本就可以完成絕大部分的數(shù)據(jù)批量處理了��。
c���、然后就是reshape2包以及plyr包了����,這是批量處理的兩個(gè)利器,reshape主要是整形���,plyr包基本提供了一套整理數(shù)據(jù)的理念�����,學(xué)好這兩個(gè)包����,批量處理將事半功倍�。
d、在實(shí)際過程中����,一些for還是無法避免的。這時(shí)候就要考慮用別的語言來處理這部分事情了��。比較常用的方法就是用別的語言批量生成R的代碼�����,還有就是直接用R調(diào)用別的語言處理的結(jié)果或者用別的語言調(diào)用R的處理結(jié)果。
3�、繪圖系統(tǒng)。
總結(jié)而言�,我們可以把R的繪圖系統(tǒng)分成四個(gè):Graphics,lattice�,ggplot2以及grid。最好學(xué)習(xí)順序也是按照這個(gè)來���。
a��、自帶的繪圖系統(tǒng)
這套系統(tǒng)可以完成最基本的事情,其操作也類似于matlab����,可以看做是分步驟命令參數(shù)式繪圖,基本就是將一系列作圖看做一步步的命令��,每一句都干一件事��,然后通過參數(shù)調(diào)整其中的某個(gè)元素的大小��、位置�����、顏色。
b�、lattice
繪圖邏輯也同上。只是加了分組繪圖�����、facet的功能��,這些都很實(shí)用����,其目的就是講自帶函數(shù)中需要大量預(yù)處理以及多步繪圖的命令用一行命令代替。上手也非常簡(jiǎn)單�。
c、ggplot2
這是經(jīng)典的R繪圖包�,繪圖哲學(xué)是圖層式的,理解成一個(gè)一個(gè)圖層的覆蓋�����。這個(gè)繪圖系統(tǒng)能做很多事����,而且其自帶主題也相當(dāng)漂亮。有一定的學(xué)習(xí)難度�。
以下就是我用ggplot畫的圖
grid繪圖系統(tǒng)算是最基元的繪圖命令�����,很多指令都是從畫圓����、直線��、矩形開始的����,這算是R里最好理解但也是最復(fù)雜的繪圖系統(tǒng)。適合想入深坑的人士學(xué)習(xí)����,如果要自由創(chuàng)造一些新的圖形����,或者編寫繪圖包,這是必學(xué)的繪圖系統(tǒng)��。另一個(gè)值得說的就是grid中也有專門用來整理拼圖的指令����,這個(gè)對(duì)于有一些論文拼圖需求的人來說還是學(xué)學(xué)比較好�����。
如果你完成了以上兩個(gè)階段��,你已經(jīng)可以在工作學(xué)習(xí)中完成絕大部分的工作���。但如果你是知識(shí)的創(chuàng)造者,或者是個(gè)程序員�,或者是要實(shí)踐自己的算法、理論���、統(tǒng)計(jì)方法�、繪圖方法��,或者亦或是你只是腦抽了�,那就要進(jìn)入第三階段的學(xué)習(xí)。這部分包括�����,C語言掌握與精通�、R語言調(diào)試、改進(jìn)�����、編寫包、寫一個(gè)地道的幫助文檔���、推銷自己的想法��。這一階段完成了�����,你也就是一個(gè)R語言的大牛了��。少年到處是你可以施展拳腳的地方��。
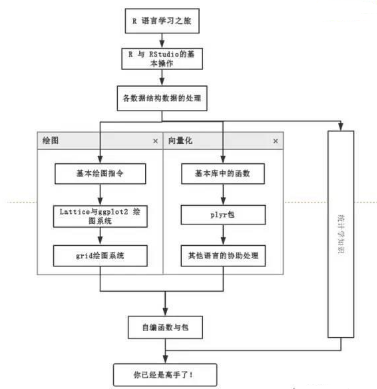
由以上內(nèi)容��,可以基本上把學(xué)習(xí)路徑總結(jié)為下圖:
此外��,其實(shí)R語言是一門輕編程重統(tǒng)計(jì)的語言,所以題主完全不需要擔(dān)心自己的編程基礎(chǔ)����。直接做幾個(gè)小項(xiàng)目,你會(huì)很快上手���,千萬不要從教材第一頁讀到最后一頁����,那種效率極低,且容易半途而廢��。
關(guān)于批處理的問題有幾位同僚在回復(fù)里面詢問批處理的問題����,這里做個(gè)簡(jiǎn)單的解釋。
批處理類似于向量運(yùn)算���,但也有很大差距�����,簡(jiǎn)單的說��,是一個(gè)函數(shù)可以快速的套用到多維變量的每一維值中��。
1. 自帶函數(shù)的批處理
譬如:
s <- 1:5
s * 2
這就是一個(gè)最簡(jiǎn)單的批處理的例子�,結(jié)果是
2 4 6 8 10
這是一個(gè)簡(jiǎn)單的向量標(biāo)量積結(jié)果��,而所謂的批處理也就是類似于這種處理方式。而在R之中��,數(shù)據(jù)的最小單元其實(shí)就是向量����,因此,幾乎所有R的函數(shù)��,都是批處理的�����。(注意�����,與matlab不同��,matlab最小單元是矩陣�,因此,其基本的運(yùn)算都是基于舉證運(yùn)算的)�。
我們可以用以下方式定義批處理函數(shù):如果一個(gè)函數(shù)F,滿足���,
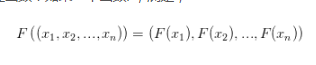
且函數(shù)F的實(shí)現(xiàn)不基于任何顯式循環(huán)(諸如for�����,while����, until)��,則函數(shù)F可以稱之為批處理函數(shù)�。
譬如:plot(將兩個(gè)向量的對(duì)應(yīng)的數(shù)逐個(gè)地畫到圖中),paste(將字符串向量的每個(gè)字符串都做連接)等等���。��。�。
這里比較一下會(huì)更加清楚�,譬如如果在python里實(shí)現(xiàn)以上功能(不實(shí)用pandas和numpy包),就得采用顯式的循環(huán)(for�����,while等):
a = list(range(1, 6))a = [i * 2 for i in a]
因此���,我們可以看出采用批處理最大的優(yōu)點(diǎn)在于減少的代碼量��,并且更加簡(jiǎn)潔明了�,易于維護(hù)。
2. 批處理是否更加高效
其實(shí)批處理的另一個(gè)好處就是使得運(yùn)行更加高效����,因?yàn)榕幚砗瘮?shù)往往經(jīng)過處理(使用更好的算法或者更底層的實(shí)現(xiàn)方式)得到某種程度的提速。我們?cè)谶@里測(cè)試實(shí)現(xiàn)將向量每個(gè)元素都自乘2這一功能���,分別采用按鍵替換�����,按數(shù)字索引替換以及直接批量處理的方式�����,來測(cè)試不同方式速度是如何的����。
a <- 1:10
f1 <- function(x) {
for (i in x) {
x[which(x == i)] = i * 2
}
}
f2 <-function(x) {
for (i in 1:10) {
x[i] = x[i] * 2
}
}
f3 <- function(x) {
x = x * 2
}
system.time(replicate(100000, f1(a)))
system.time(replicate(100000, f2(a)))
system.time(replicate(100000, f3(a)))
結(jié)果如下:> system.time(replicate(100000, f1(a)))
用戶 系統(tǒng) 流逝
4.47 0.01 4.72
> system.time(replicate(100000, f2(a)))
用戶 系統(tǒng) 流逝
2.53 0.00 2.63
> system.time(replicate(100000, f3(a)))
用戶 系統(tǒng) 流逝
0.63 0.03 0.72
明顯看出�����,批處理并且避免顯式循環(huán)的方式的確有助于提高速度�����,代碼量也少的多。因此���,何樂而不為呢?
但是經(jīng)過測(cè)試���,并不是每個(gè)批處理函數(shù)的效果并不是都是那么明顯���,譬如:strsplit。甚至研究碼源之后�,你也會(huì)發(fā)現(xiàn),很多批處理常用的函數(shù)的實(shí)現(xiàn)其實(shí)都是for�����,因此�,有一派觀點(diǎn)認(rèn)為避免顯式循環(huán)(特別是指采用apply函數(shù)、plyr包的方法避免顯式循環(huán))���,其實(shí)具有一定的誤導(dǎo)性����,其是否能提高效率也是要視情況而定。
3. apply族函數(shù)和aggregate函數(shù)
這是R基礎(chǔ)包自帶的兩類用于批量處理的函數(shù)包���,在此,只做簡(jiǎn)單地介紹:
apply函數(shù)族共有五個(gè)��,分別是:apply��,lapply��,sapply��,tapply��,vapply��。其總用其實(shí)就是將某個(gè)函數(shù)逐個(gè)套用到向量(矩陣)中每個(gè)元素之中���,其實(shí)具體的作用����,讀幫助文檔就可以了���。
aggregate這個(gè)函數(shù)比較有意思,常用的帶入方式是:
aggregate(aDataFrame, by = list(vector1,vector2), FUN = aFunction)
作用就是基于by指定的變量做分組��,計(jì)算FUN分別統(tǒng)計(jì)每個(gè)組的結(jié)果
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材���,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫��,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量�,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330