數(shù)據(jù)挖掘- 分類(lèi)算法比較
隨著計(jì)算能力�、存儲(chǔ)���、網(wǎng)絡(luò)的高速發(fā)展,人類(lèi)積累的數(shù)據(jù)量正以指數(shù)速度增長(zhǎng)�。對(duì)于這些數(shù)據(jù),人們迫切希望從中提取出隱藏其中的有用信息��,更需要發(fā)現(xiàn)更深層次的規(guī)律�,對(duì)決策,商務(wù)應(yīng)用提供更有效的支持�����。為了滿(mǎn)足這種需求�,數(shù)據(jù)挖掘技術(shù)的得到了長(zhǎng)足的發(fā)展,而分類(lèi)在數(shù)據(jù)挖掘中是一項(xiàng)非常重要的任務(wù)����,目前在商業(yè)上應(yīng)用最多。本文主要側(cè)重數(shù)據(jù)挖掘中分類(lèi)算法的效果的對(duì)比�����,通過(guò)簡(jiǎn)單的實(shí)驗(yàn)(采用開(kāi)源的數(shù)據(jù)挖掘工具 -Weka)來(lái)驗(yàn)證不同的分類(lèi)算法的效果�����,幫助數(shù)據(jù)挖掘新手認(rèn)識(shí)不同的分類(lèi)算法的特點(diǎn)�����,并且掌握開(kāi)源數(shù)據(jù)挖掘工具的使用��。
分類(lèi)算法是解決分類(lèi)問(wèn)題的方法��,是數(shù)據(jù)挖掘��、機(jī)器學(xué)習(xí)和模式識(shí)別中一個(gè)重要的研究領(lǐng)域���。分類(lèi)算法通過(guò)對(duì)已知類(lèi)別訓(xùn)練集的分析�����,從中發(fā)現(xiàn)分類(lèi)規(guī)則����,以此預(yù)測(cè)新數(shù)據(jù)的類(lèi)別。分類(lèi)算法的應(yīng)用非常廣泛�����,銀行中風(fēng)險(xiǎn)評(píng)估�、客戶(hù)類(lèi)別分類(lèi)、文本檢索和搜索引擎分類(lèi)����、安全領(lǐng)域中的入侵檢測(cè)以及軟件項(xiàng)目中的應(yīng)用等等。
分類(lèi)算法介紹
以下介紹典型的分類(lèi)算法�。
Bayes
貝葉斯分類(lèi)器的分類(lèi)原理是通過(guò)某對(duì)象的先驗(yàn)概率,利用貝葉斯公式計(jì)算出其后驗(yàn)概率�����,即該對(duì)象屬于某一類(lèi)的概率�,選擇具有最大后驗(yàn)概率的類(lèi)作為該對(duì)象所屬的類(lèi)。目前研究較多的貝葉斯分類(lèi)器主要有四種�����,分別是:Naive Bayes�����、 TAN�、BAN 和 GBN。
貝葉斯網(wǎng)絡(luò)(BayesNet)
貝葉斯網(wǎng)絡(luò)是一個(gè)帶有概率注釋的有向無(wú)環(huán)圖����,圖中的每一個(gè)結(jié)點(diǎn)均表示一個(gè)隨機(jī)變量 , 圖中兩結(jié)點(diǎn)間若存在著一條弧,則表示這兩結(jié)點(diǎn)相對(duì)應(yīng)的隨機(jī)變量是概率相依的����,反之則說(shuō)明這兩個(gè)隨機(jī)變量是條件獨(dú)立的。網(wǎng)絡(luò)中任意一個(gè)結(jié)點(diǎn) X 均有一個(gè)相應(yīng)的條件概率表 Conditional Probability Table���,CPT) ����,用以表示結(jié)點(diǎn) X 在其父結(jié)點(diǎn)取各可能值時(shí)的條件概率����。若結(jié)點(diǎn) X 無(wú)父結(jié)點(diǎn) , 則 X 的 CPT 為其先驗(yàn)概率分布。貝葉斯網(wǎng)絡(luò)的結(jié)構(gòu)及各結(jié)點(diǎn)的 CPT 定義了網(wǎng)絡(luò)中各變量的概率分布�。應(yīng)用貝葉斯網(wǎng)絡(luò)分類(lèi)器進(jìn)行分類(lèi)主要分成兩階段。第一階段是貝葉斯網(wǎng)絡(luò)分類(lèi)器的學(xué)習(xí)��,即從樣本數(shù)據(jù)中構(gòu)造分類(lèi)器,包括結(jié)構(gòu)學(xué)習(xí)和 CPT 學(xué)習(xí)�;第二階段是貝葉斯網(wǎng)絡(luò)分類(lèi)器的推理,即計(jì)算類(lèi)結(jié)點(diǎn)的條件概率��,對(duì)分類(lèi)數(shù)據(jù)進(jìn)行分類(lèi)�。這兩個(gè)階段的時(shí)間復(fù)雜性均取決于特征值間的依賴(lài)程度,甚至可以是 NP 完全問(wèn)題�����,因而在實(shí)際應(yīng)用中�,往往需要對(duì)貝葉斯網(wǎng)絡(luò)分類(lèi)器進(jìn)行簡(jiǎn)化。根據(jù)對(duì)特征值間不同關(guān)聯(lián)程度的假設(shè)�����,可以得出各種貝葉斯分類(lèi)器�。
樸素貝葉斯(NaiveBayes)
樸素貝葉斯模型(NBC)發(fā)源于古典數(shù)學(xué)理論,有著堅(jiān)實(shí)的數(shù)學(xué)基礎(chǔ)�,以及穩(wěn)定的分類(lèi)效率。同時(shí)�,NBC 模型所需估計(jì)的參數(shù)很少,對(duì)缺失數(shù)據(jù)不太敏感����,算法也比較簡(jiǎn)單����。NBC 模型假設(shè)屬性之間相互獨(dú)立�,這個(gè)假設(shè)在實(shí)際應(yīng)用中往往是不成立的,這給 NBC 模型的正確分類(lèi)帶來(lái)了一定影響����。在屬性個(gè)數(shù)比較多或者屬性之間相關(guān)性較大時(shí)�,NBC 模型的分類(lèi)效率比不上決策樹(shù)模型。而在屬性相關(guān)性較小時(shí)�����,NBC 模型的性能最為良好��。
Lazy Learning
相對(duì)其它的 Inductive Learning 的算法來(lái)說(shuō)����,Lazy Learning 的方法在訓(xùn)練是僅僅是保存樣本集的信息,直到測(cè)試樣本到達(dá)時(shí)才進(jìn)行分類(lèi)決策��。也就是說(shuō)這個(gè)決策模型是在測(cè)試樣本到來(lái)以后才生成的�����。相對(duì)與其它的分類(lèi)算法來(lái)說(shuō),這類(lèi)的分類(lèi)算法可以根據(jù)每個(gè)測(cè)試樣本的樣本信息來(lái)學(xué)習(xí)模型�,這樣的學(xué)習(xí)模型可能更好的擬 合局部的樣本特性。kNN 算法的思路非常簡(jiǎn)單直觀(guān):如果一個(gè)樣本在特征空間中的 k 個(gè)最相似 ( 即特征空間中最鄰近 ) 的樣本中的大多數(shù)屬于某一個(gè)類(lèi)別��,則該樣本也屬于這個(gè)類(lèi)別���。其基本原理是在測(cè)試樣本到達(dá)的時(shí)候?qū)ふ业綔y(cè)試樣本的 k 臨近的樣本�,然后選擇這些鄰居樣本的類(lèi)別最集中的一種作為測(cè)試樣本的類(lèi)別����。在 weka 中關(guān)于 kNN 的算法有兩個(gè),分別是 IB1����,IBk。
IB1 即 1 近鄰
IB1 是通過(guò)它的一個(gè)鄰居來(lái)判斷測(cè)試樣本的類(lèi)別
IBk 即 K 近鄰
IBk 是通過(guò)它周?chē)?k 個(gè)鄰居來(lái)判斷測(cè)試樣本的類(lèi)別
在樣本中有比較多的噪音點(diǎn)是(noisy points)時(shí)�����,通過(guò)一個(gè)鄰居的效果很顯然會(huì)差一些�����,因?yàn)槌霈F(xiàn)誤差的情況會(huì)比較多。這種情況下�,IBk 就成了一個(gè)較優(yōu)的選項(xiàng)了。這個(gè)時(shí)候有出現(xiàn)了一個(gè)問(wèn)題�����,k 這個(gè)值如何確定�����,一般來(lái)說(shuō)這個(gè) k 是通過(guò)經(jīng)驗(yàn)來(lái)判斷的���。
Trees
即決策樹(shù)算法,決策樹(shù)是對(duì)數(shù)據(jù)進(jìn)行分類(lèi)���,以此達(dá)到預(yù)測(cè)的目的���。該決策樹(shù)方法先根據(jù)訓(xùn)練集數(shù)據(jù)形成決策樹(shù),如果該樹(shù)不能對(duì)所有對(duì)象給出正確的分類(lèi)����,那么選擇一些例外加入到訓(xùn)練集數(shù)據(jù)中,重復(fù)該過(guò)程一直到形成正確的決策集�����。決策樹(shù)代表著決策集的樹(shù)形結(jié)構(gòu)。決策樹(shù)由決策結(jié)點(diǎn)���、分支和葉子組成�����。決策樹(shù)中最上面 的結(jié)點(diǎn)為根結(jié)點(diǎn)���,每個(gè)分支是一個(gè)新的決策結(jié)點(diǎn),或者是樹(shù)的葉子����。每個(gè)決策結(jié)點(diǎn)代表一個(gè)問(wèn)題或決策,通常 對(duì)應(yīng)于待分類(lèi)對(duì)象的屬性�。每一個(gè)葉子結(jié)點(diǎn)代表一種可能的分類(lèi)結(jié)果。沿決策樹(shù)從上到下遍歷的過(guò)程中���,在每個(gè)結(jié)點(diǎn)都會(huì)遇到一個(gè)測(cè)試���,對(duì)每個(gè)結(jié)點(diǎn)上問(wèn)題的不同的 測(cè)試輸出導(dǎo)致不同的分支,最后會(huì)到達(dá)一個(gè)葉子結(jié)點(diǎn)����,這個(gè)過(guò)程就是利用決策樹(shù)進(jìn)行分類(lèi)的過(guò)程���,利用若干個(gè)變量來(lái)判斷所屬的類(lèi)別。
-
Id3 即決策樹(shù) ID3 算法
ID3 算法是由 Quinlan 首先提出的���。該算法是以信息論為基礎(chǔ)����,以信息熵和信息增益度為衡量標(biāo)準(zhǔn)�����,從而實(shí)現(xiàn)對(duì)數(shù)據(jù)的歸納分類(lèi)�����。
以下是一些信息論的基本概念:
定義 1:若存在 n 個(gè)相同概率的消息���,則每個(gè)消息的概率 p 是 1/n,一個(gè)消息傳遞的信息量為 Log2(n)
定義 2:若有 n 個(gè)消息�,其給定概率分布為 P=(p1,p2 … pn),則由該分布傳遞的信息量稱(chēng)為 P 的熵�����,記為
I (p) =-(i=1 to n 求和 ) piLog2(pi) 。
定義 3:若一個(gè)記錄集合 T 根據(jù)類(lèi)別屬性的值被分成互相獨(dú)立的類(lèi) C1C2..Ck����,則識(shí)別 T 的一個(gè)元素所屬哪個(gè)類(lèi)所需要的信息量為 Info (T) =I (p) ,其中 P 為 C1C2 … Ck 的概率分布��,即 P= (|C1|/|T| … |Ck|/|T|)
定義 4:若我們先根據(jù)非類(lèi)別屬性 X 的值將 T 分成集合 T1,T2 … Tn��,則確定 T 中一個(gè)元素類(lèi)的信息量可通過(guò)確定 Ti 的加權(quán)平均值來(lái)得到�����,即 Info(Ti) 的加權(quán)平均值為:
Info(X, T) = (i=1 to n 求和 ) ((|Ti|/|T |) Info (Ti))
定義 5:信息增益度是兩個(gè)信息量之間的差值���,其中一個(gè)信息量是需確定 T 的一個(gè)元素的信息量����,另一個(gè)信息量是在已得到的屬性 X 的值后需確定的 T 一個(gè)元素的信息量�����,信息增益度公式為:
Gain(X, T) =Info (T)-Info(X, T)
-
J48 即決策樹(shù) C4.5 算法
-
C4.5 算法一種分類(lèi)決策樹(shù)算法 , 其核心算法是 ID3 算法���。C4.5 算法繼承了 ID3 算法的優(yōu)點(diǎn)��,并在以下幾方面對(duì) ID3 算法進(jìn)行了改進(jìn):用信息增益率來(lái)選擇屬性����,克服了用信息增益選擇屬性時(shí)偏向選擇取值多的屬性的不足;
在樹(shù)構(gòu)造過(guò)程中進(jìn)行剪枝�����;
能夠完成對(duì)連續(xù)屬性的離散化處理���;
能夠?qū)Σ煌暾麛?shù)據(jù)進(jìn)行處理�。
C4.5 算法有如下優(yōu)點(diǎn):產(chǎn)生的分類(lèi)規(guī)則易于理解��,準(zhǔn)確率較高����。其缺點(diǎn)是:在構(gòu)造樹(shù)的過(guò)程中,需要對(duì)數(shù)據(jù)集進(jìn)行多次的順序掃描和排序���,因而導(dǎo)致算法的低效。
Rule
-
Decision Table 即決策表
決策表 (Decision Table)��,是一中使用表的結(jié)構(gòu),精確而簡(jiǎn)潔描述復(fù)雜邏輯的方式�����。
-
JRip 即 RIPPER 算法
規(guī)則歸納學(xué)習(xí)從分類(lèi)實(shí)例出發(fā)能夠歸納出一般的概念描述�����。其中重要的算法為 IREP 算法和 RIPPER 算法��。重復(fù)增量修枝(RIPPER)算法生成一條規(guī)則��,隨機(jī)地將沒(méi)有覆蓋的實(shí)例分成生長(zhǎng)集合和修剪集合�,規(guī)定規(guī)則集合中的每個(gè)規(guī)則是有兩個(gè)規(guī)則來(lái)生成:替代規(guī)則和修訂規(guī)則。
Meta
-
AdaBoostM1 即 AdaBoosting 算法
Adaboost 是一種迭代算法�,其核心思想是針對(duì)同一個(gè)訓(xùn)練集訓(xùn)練不同的分類(lèi)器 ( 弱分類(lèi)器 ) ,然后把這些弱分類(lèi)器集合起來(lái)�����,構(gòu)成一個(gè)更強(qiáng)的最終分類(lèi)器 ( 強(qiáng)分類(lèi)器 ) ����。其算法本身是通過(guò)改變數(shù)據(jù)分布來(lái)實(shí)現(xiàn)的,它根據(jù)每次訓(xùn)練集之中每個(gè)樣本的分類(lèi)是否正確��,以及上次的總體分類(lèi)的準(zhǔn)確率,來(lái)確定每個(gè)樣本的權(quán)值����。將修改過(guò)權(quán)值的新數(shù)據(jù)集送給下層分類(lèi)器進(jìn)行訓(xùn)練,最后將每次訓(xùn)練得到的分類(lèi)器最后融合起來(lái)�,作為最后的決策分類(lèi)器。
-
Bagging 即 Bagging 方法
Bootstrps bagging boosting 都屬于集成學(xué)習(xí)方法��,將訓(xùn)練的學(xué)習(xí)器集成在一起���。原理來(lái)源于 PAC 學(xué)習(xí)模型(Probably Approximately CorrectK)���。其中的 Bagging 是 bootstrap aggregating 的縮寫(xiě),是最早的 Ensemble 算法之一�,它也是最直接容易實(shí)現(xiàn),又具有不錯(cuò)的效果的算法之一��。Bagging 中的多樣性是由有放回抽取訓(xùn)練樣本來(lái)實(shí)現(xiàn)的���,用這種方式隨機(jī)產(chǎn)生多個(gè)訓(xùn)練數(shù)據(jù)的子集��,在每一個(gè)訓(xùn)練集的子集上訓(xùn)練一個(gè)同種分類(lèi)器����,最終分類(lèi)結(jié)果是由多個(gè)分類(lèi)器的分類(lèi)結(jié)果多數(shù)投票而產(chǎn)生的���。
Weka 中分類(lèi)算法的參數(shù)解釋
Correlation coefficient (= CC) : 相關(guān)系數(shù)
Root mean squared error (= RMSE) : 均方根誤差
Root relative squared error (= RRSE) : 相對(duì)平方根誤差
Mean absolute error (= MAE) : 平均絕對(duì)誤差
Root absolute error (= RAE) : 平均絕對(duì)誤差平方根
Combined: (1-abs (CC)) + RRSE + RAE: 結(jié)合的
Accuracy (= ACC) : 正確率
注意��,Correction coefficient 只適用于連續(xù)值類(lèi)別����,Accuracy 只適用于離散類(lèi)別
Kappa statistic:這個(gè)指標(biāo)用于評(píng)判分類(lèi)器的分類(lèi)結(jié)果與隨機(jī)分類(lèi)的差異度�。
絕對(duì)差值(Mean absolute error):這個(gè)指標(biāo)用于評(píng)判預(yù)測(cè)值與實(shí)際值之間的差異度。把多次測(cè)得值之間相互接近的程度稱(chēng)為精密度����,精密度用偏差表示,偏差指測(cè)得值與平均值之間的差值����,偏差越小,精密度則越高����。
中誤差(Root mean square error:RMSE):帶權(quán)殘差平方和的平均數(shù)的平方根,作為在一定條件下衡量測(cè)量精度的一種數(shù)值指標(biāo)��。中誤差是衡量觀(guān)測(cè)精度的一種數(shù)字標(biāo)準(zhǔn)���,亦稱(chēng)“標(biāo)準(zhǔn)差”或“均方根差”��。在相同觀(guān)測(cè)條件下的一組真誤差平方中數(shù)的平方根���。因真誤差不易求得 , 所 以通常用最小二乘法求得的觀(guān)測(cè)值改正數(shù)來(lái)代替真誤差����。它是觀(guān)測(cè)值與真值偏差的平方和觀(guān)測(cè)次數(shù) n 比值的平方根�����。中誤差不等于真誤差��,它僅是一組真誤差的代表值�����。中誤差的大小反映了該組觀(guān)測(cè)值精度的高低��,因此�����,通常稱(chēng)中誤差為觀(guān)測(cè)值的中誤差。
分類(lèi)算法的評(píng)價(jià)標(biāo)準(zhǔn)
預(yù)測(cè)的準(zhǔn)確率:這涉及到模型正確地預(yù)測(cè)新的或先前沒(méi)見(jiàn)過(guò)的數(shù)據(jù)的類(lèi) 標(biāo)號(hào)能力�。
速度:涉及到產(chǎn)生和使用模型的計(jì)算花費(fèi)。
強(qiáng)壯性:這涉及給定噪聲數(shù)據(jù)或具有空缺值的數(shù)據(jù)��,模型正確預(yù)測(cè)的能力����。
可伸縮性:這涉及給定大量的數(shù)據(jù)�,有效的構(gòu)造模型的能力。
可解釋性:這涉及學(xué)習(xí)模型提供的理解和洞察的層次�����。
分類(lèi)算法的比較
以下主要采用兩種數(shù)據(jù)集(Monk's Problems 和 Satimage)來(lái)分別運(yùn)行不同的分類(lèi)算法�����,采用的是 Weka 數(shù)據(jù)挖掘工具����。
Monk's Problems 數(shù)據(jù)集特點(diǎn)
1. 屬性全部為 nominal 類(lèi)型
2. 訓(xùn)練樣本較少
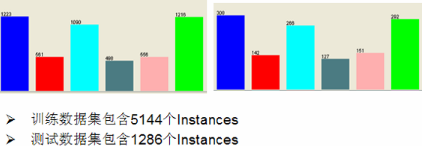
圖 1. 訓(xùn)練數(shù)據(jù)集

3. 訓(xùn)練集數(shù)據(jù)的可視化圖,該圖根據(jù)直方圖上方一欄所選擇的 class 屬性(attr6)來(lái)著色�����。
圖 2. 訓(xùn)練數(shù)據(jù)集可視化圖
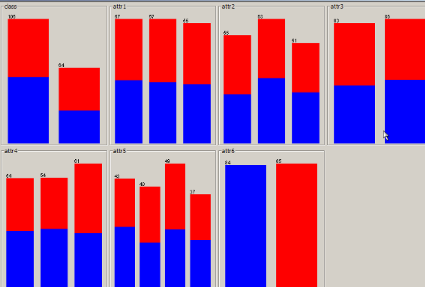
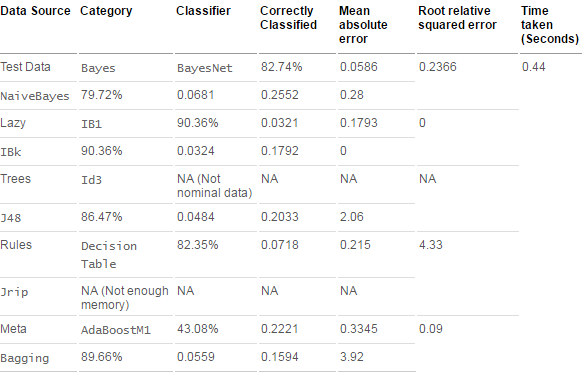
各分類(lèi)器初步分類(lèi)效果分析
各分類(lèi)器不做參數(shù)調(diào)整,使用默認(rèn)參數(shù)進(jìn)行得到的結(jié)果���。
表 1. 分類(lèi)器初步結(jié)果比較
分類(lèi)器比較
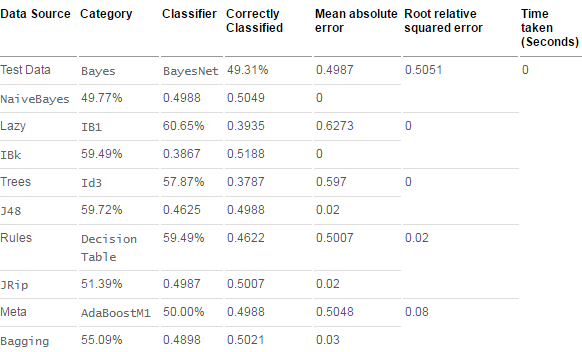
預(yù)測(cè)的準(zhǔn)確率比較
采用基于懶惰學(xué)習(xí)的 IB1�����、IBk 的分類(lèi)器的誤差率較低�����,采用基于概率統(tǒng)計(jì)的 BayesNet 分類(lèi)器的誤差率較高��,其他的基于決策樹(shù)和基于規(guī)則的分類(lèi)器誤差居于前兩者之間��,這是因?yàn)樵跇颖据^少的情況下����,采用 IB1 時(shí)����,生成的決策模型是在測(cè)試樣本到來(lái)以后才生成,這樣的學(xué)習(xí)模型可能更好的擬合局部的樣本特性�。采用統(tǒng)計(jì)學(xué)分類(lèi)方法的 BayesNet 之所以準(zhǔn)確度較低,可能是由于貝葉斯定理的成立本身需要很強(qiáng)的獨(dú)立性假設(shè)前提��,而此假設(shè)在實(shí)際情況中經(jīng)常是不成立的。但是一般地�,統(tǒng)計(jì)分類(lèi)算法趨于計(jì)算量大。
進(jìn)一步比較分類(lèi)結(jié)果的散點(diǎn)圖(其中正確分類(lèi)的結(jié)果用叉表示�����,分錯(cuò)的結(jié)果用方框表示)����,發(fā)現(xiàn) BayesNet 分類(lèi)器針對(duì)屬性 6(attr6)的預(yù)測(cè)結(jié)果分錯(cuò)的結(jié)果明顯比 IB1 的分錯(cuò)結(jié)果要多些����,而這些錯(cuò)誤的散點(diǎn)中,又以屬性 6 的取值為 2 的散點(diǎn)中錯(cuò)誤的數(shù)目較多���。
圖 3. BayesNet 的分類(lèi)結(jié)果散點(diǎn)圖
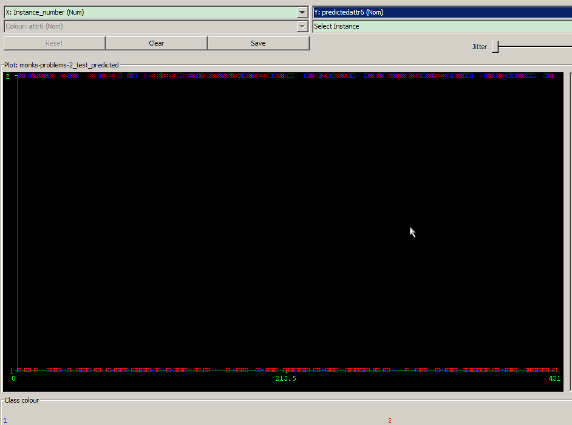
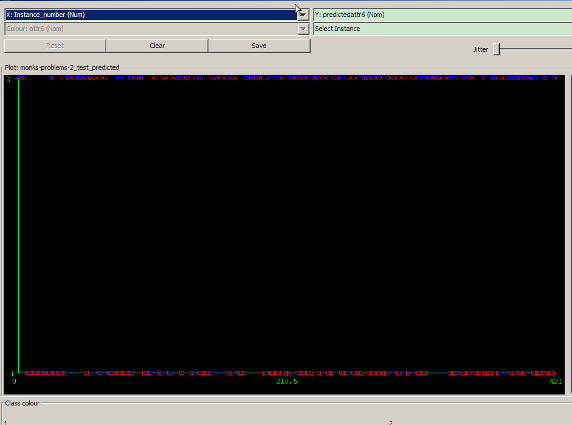
圖 4. IB1 分類(lèi)結(jié)果散點(diǎn)圖
分類(lèi)速度比較
Adaboost 的分類(lèi)花了 0.08 秒���,Bagging 的分類(lèi)花了 0.03 秒,相對(duì)于其他的分類(lèi)器�,這兩個(gè)分類(lèi)器速度較慢。這是因?yàn)檫@兩個(gè)算法采用迭代����,針對(duì)同一個(gè)訓(xùn)練集,訓(xùn)練多種分類(lèi)器,然后把這些分類(lèi)器集合起來(lái)�,所以時(shí)間消耗較長(zhǎng)。
分類(lèi)器參數(shù)調(diào)優(yōu)
IBK 調(diào)優(yōu)
【 KNN 】:6
擴(kuò)大鄰近學(xué)習(xí)的節(jié)點(diǎn)范圍���,降低異常點(diǎn)的干擾(距離較大的異常點(diǎn))
? 【 DistanceWeighting 】:Weight by 1/distance
通過(guò)修改距離權(quán)重����,進(jìn)一步降低異常點(diǎn)的干擾(距離較大的異常點(diǎn))
圖 5. IBk 分類(lèi)調(diào)優(yōu)
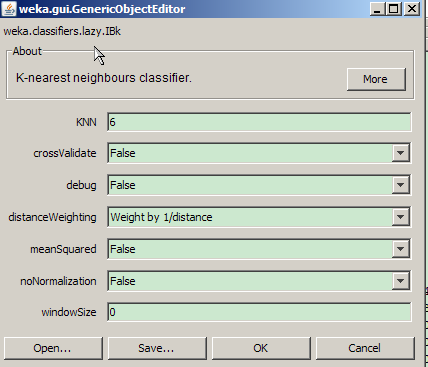
IBk 調(diào)優(yōu)結(jié)果
調(diào)優(yōu)后準(zhǔn)確率從 60.65% 上升到 63.43%����。

表 2. IBk 調(diào)優(yōu)結(jié)果
J48 調(diào)優(yōu)
【 binarySplits 】:True
采用 2 分法,生成決策樹(shù)��。
圖 6. J48 分類(lèi)調(diào)優(yōu)
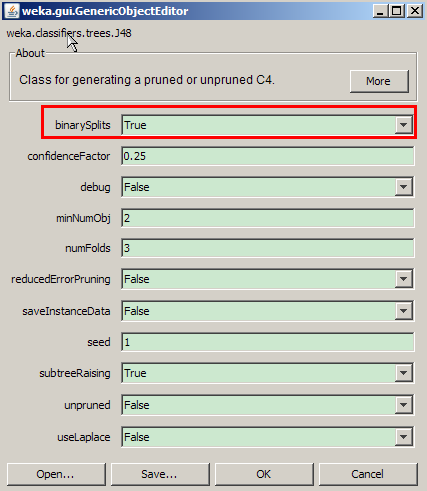
J48 調(diào)優(yōu)結(jié)果
調(diào)優(yōu)后準(zhǔn)確率從 59.72% 上升到 64.35%�,但是分類(lèi)模型建立時(shí)間從 0 延長(zhǎng)到了 0.31 秒
表 3. J48 調(diào)優(yōu)結(jié)果

Salmage 數(shù)據(jù)集特點(diǎn)
1. 屬性為 numeric 類(lèi)型 , 共 37 個(gè)屬性
2. 訓(xùn)練數(shù)據(jù)各類(lèi)不平衡,測(cè)試數(shù)據(jù)各類(lèi)不平衡
圖 7. 訓(xùn)練數(shù)據(jù)集可視化圖
各分類(lèi)器初步分類(lèi)效果分析
各分類(lèi)器不做參數(shù)調(diào)整��,使用默認(rèn)參數(shù)得到的結(jié)果如下:
表 4. 分類(lèi)器初步結(jié)果比較
分類(lèi)器比較
預(yù)測(cè)的準(zhǔn)確率比較
采用基于懶惰學(xué)習(xí)的 IB1�����、IBk 的分類(lèi)器的準(zhǔn)確率都較高���,為 90.36%���,采用 基于決策樁的 AdaBoostM 分類(lèi)器的準(zhǔn)確率較低�,為 43.08%���,貝葉斯分類(lèi)器的準(zhǔn)確 率較之前的數(shù)據(jù)集(Monk ’ s problem)有明顯的提高���,從 49% 到了 80% 左右,這主 要是因?yàn)闃颖究臻g的擴(kuò)大����,其他的分類(lèi)器準(zhǔn)確率也處于 80% 左右。
分類(lèi)速度比較
DecisionTable 的分類(lèi)花了 4.33 秒�,Bagging 的分類(lèi)花了 3.92 秒�,J48 的分類(lèi)模型建立花了 2.06 秒,相對(duì)于其他的分類(lèi)器�,這三個(gè)分類(lèi)器速度較慢。
分類(lèi)器參數(shù)調(diào)優(yōu)
IBK 調(diào)優(yōu)
【 KNN 】:6
擴(kuò)大鄰近學(xué)習(xí)的節(jié)點(diǎn)范圍���,降低異常點(diǎn)的干擾(距離較大的異常點(diǎn))
? 【 DistanceWeighting 】:Weight by 1/distance
通過(guò)修改距離權(quán)重����,進(jìn)一步降低異常點(diǎn)的干擾(距離較大的異常點(diǎn))
IBK 調(diào)優(yōu)結(jié)果
調(diào)優(yōu)后準(zhǔn)確率從 90.36% 上升到 90.98%, 準(zhǔn)確度有略微提升��,說(shuō)明通過(guò)擴(kuò)大鄰近學(xué)習(xí)的節(jié)點(diǎn)范圍不能明顯提高分類(lèi)器的性能。
表 5. IBk 調(diào)優(yōu)結(jié)果

J48 調(diào)優(yōu)
【 binarySplits 】:True
采用 2 分法�����,生成決策樹(shù)�。
J48 調(diào)優(yōu)結(jié)果
分類(lèi)性能沒(méi)有提升。說(shuō)明采用 2 分法對(duì)分類(lèi)沒(méi)有影響�����。相反���,時(shí)間比原來(lái)的算法有略微延長(zhǎng)��。
表 6. J48 調(diào)優(yōu)結(jié)果

改進(jìn)和建議
本文給出的調(diào)優(yōu)方法只是一個(gè)簡(jiǎn)單的示例��,實(shí)際上根據(jù)合理的參數(shù)調(diào)整����,這些分類(lèi)算法的效果還能得到更大的提升���。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材���,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫(kù)����,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情����;
? 想了解CDA考試含金量,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330