數據挖掘:聚類分析經典算法講解及實現
本文將系統(tǒng)的講解數據挖掘領域的經典聚類算法��,并給予代碼實現示例���。雖然當下已有很多平臺都集成了數據挖掘領域的經典算法模塊,但筆者認為要深入理解算法的核心����,剖析算法的執(zhí)行過程,那么通過代碼的實現及運行結果來進行算法的驗證��,這樣的過程是很有必要的���。因此本文�����,將有助于讀者對經典聚類算法的深入學習與理解���。
聚類和分類的區(qū)別一開始筆者就想談談這個話題�����,畢竟在數據挖掘算法領域�����,這兩者有著很大的差別�����,對于初學者很容易混淆�����。拋開晦澀的定義陳述���,在此我們先通過兩個生活比喻看看什么是監(jiān)督學習,什么是非監(jiān)督學習�����。
回首我們人生最美好的豆蔻年華,那時的我們�,少年初長成,結束了小學生涯����,步入初中,這個年齡是我們人生中第一個分水嶺��。初中一年級剛入學時���,同學們之間彼此不認識��,老師對同學們也都不熟悉。但隨著時間的推移��,同學們基本上都分成了三五群�����,回想一下那時的我們����,是不是整天玩在一起的同學總是那幾個�����?我們發(fā)現���,這個過程老師是不參與的,老師不會讓同學們分成幾組���,讓哪幾個同學經常在一起學習和玩耍�。想想這個過程���,其實是我們自己辨別和哪些同學合得來一個過程�����,這期間我們可能會判斷同學的性格�����,學習成績����,共同愛好與話題,是否和同學家離的很近還能一起上學和回家等等很多的維度因素��。時間久了�����,班級里就會出現不同的幾個圈子�����,這個圈子的數量及細節(jié)一開始并沒有人知曉�,并且這個過程無老師進行監(jiān)督,因此我們視之為無監(jiān)督學習��。在此我們指出�����,聚類算法是無監(jiān)督學習的算法��。
初中三年級��,因為我們背負著中考的重擔�,大家都為了自己的理想高中做最后的沖刺努力���。設想這樣一種情況:為了更好的幫助大家不斷提高學習成績�,班主任老師將班級分成了五個互幫互助小組(語文、數學����、物理、生物�����、英語)�,每個小組十位同學,分別是班級里這幾個科目考試成績最好的前十名同學��,為了達到更好的互幫互助效果��,每位達到條件要求的同學只能加入一門科目小組�����,也就是說����,如果某位同學有兩門或兩門以上的科目都排在班級前十名,則班主任老師隨機指定其加入某一小組�。這樣所有同學都可以在互幫互助小組的幫助下更大程度的提升自己的薄弱科目,實現共贏。在此我們可以看到小組的種類����,數量,都是定義好的��,只需要老師指定好各個小組的成員�。因此,這樣的學習過程是一種監(jiān)督學習過程��,老師給出小組的種類和數量用排名的方式來監(jiān)督并激勵學生學習����。在此我們指出,分類算法是監(jiān)督學習的算法����。
總結一下,數據分類是分析已有的數據�,尋找其共同的屬性,并根據分類模型將這些數據劃分成不同的類別����,這些數據賦予類標號。這些類別是事先定義好的��,并且類別數是已知的����。相反,數據聚類則是將本沒有類別參考的數據進行分析并劃分為不同的組��,即從這些數據導出類標號����。聚類分析本身則是根據數據來發(fā)掘數據對象及其關系信息,并將這些數據分組��。每個組內的對象之間是相似的�,而各個組間的對象是不相關的。不難理解���,組內相似性越高�����,組間相異性越高��,則聚類越好��。
K 均值算法詳解及實現
算法流程
K 均值算法�����,應該是聚類算法中最為基礎但也最為重要的算法���。其算法流程如下:
-
隨機的取 k 個點作為 k 個初始質心�����;
-
計算其他點到這個 k 個質心的距離��;
-
如果某個點 p 離第 n 個質心的距離更近���,則該點屬于 cluster n,并對其打標簽��,標注 point p.label=n���,其中 n<=k���;
-
計算同一 cluster 中,也就是相同 label 的點向量的平均值��,作為新的質心��;
-
迭代至所有質心都不變化為止,即算法結束�����。
當然算法實現的方法有很多����,比如在選擇初始質心時��,可以隨機選擇 k 個���,也可以隨機選擇 k 個離得最遠的點等等�����,方法不盡相同����。
K 值估計
對于 k 值�����,必須提前知道����,這也是 kmeans 算法的一個缺點��。當然對于 k 值����,我們可以有很多種方法進行估計�����。本文中�,我們采用平均直徑法來進行 k 的估計。
也就是說�����,首先視所有的點為一個大的整體 cluster�,計算所有點之間距離的平均值作為該 cluster 的平均直徑。選擇初始質心的時候��,先選擇最遠的兩個點�����,接下來從這最兩個點開始�,與這最兩個點距離都很遠的點(遠的程度為����,該點到之前選擇的最遠的兩個點的距離都大于整體 cluster 的平均直徑)可視為新發(fā)現的質心���,否則不視之為質心����。設想一下��,如果利用平均半徑或平均直徑這一個指標��,若我們猜想的 K 值大于或等于真實的 K 值��,也就是簇的真實數目���,那么該指標的上升趨勢會很緩慢,但是如果我們給出的 K 值小于真實的簇的數目時�,這個指標一定會急劇上升。
根據這樣的估算思想����,我們就能估計出正確的 k 值,并且得到 k 個初始質心�����,接著,我們便根據上述算法流程繼續(xù)進行迭代���,直到所有質心都不變化�����,從而成功實現算法���。如下圖所示:
圖 1. K 值估計
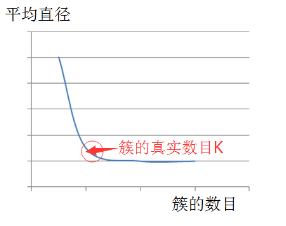
我們知道 k 均值總是收斂的,也就是說��,k 均值算法一定會達到一種穩(wěn)定狀態(tài)�,在此狀態(tài)下,所有的點都不會從一個簇轉移到另一個簇����,因此質心不在發(fā)生改變。在此���,我們引出一個剪枝優(yōu)化��,即:k 均值最明顯的收斂過程會發(fā)生在算法運行的前期階段���,故在某些情況下為了增加算法的執(zhí)行效率�����,我們可以替換上述算法的第五步��,采用“迭代至僅有 1%~3%的點在影響質心”或“迭代至僅有 1%~3%的點在改變簇”���。
k 均值適用于絕大多數的數據類型,并且簡單有效���。但其缺點就是需要知道準確的 k 值,并且不能處理異形簇����,比如球形簇,不同尺寸及密度的簇��,環(huán)形簇等等�。
本文主要為算法講解及實現,因此代碼實現暫不考慮面向對象思想��,采用面向過程的實現方式,如果數據多維����,可能會需要做數據預處理,比如歸一化����,并且修改代碼相關方法即可。
算法實現
清單 1. Kmeans 算法代碼實現
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.io.PrintStream;
import java.text.DecimalFormat;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.PriorityQueue;
import java.util.Queue;
public class Kmeans {
private class Node {
int label;// label 用來記錄點屬于第幾個 cluster
double[] attributes;
public Node() {
attributes = new double[100];
}
}
private class NodeComparator {
Node nodeOne;
Node nodeTwo;
double distance;
public void compute() {
double val = 0;
for (int i = 0; i < dimension; ++i) {
val += (this.nodeOne.attributes[i] - this.nodeTwo.attributes[i]) *
(this.nodeOne.attributes[i] - this.nodeTwo.attributes[i]);
}
this.distance = val;
}
}
private ArrayList<Node> arraylist;
private ArrayList<Node> centroidList;
private double averageDis;
private int dimension;
private Queue<NodeComparator> FsQueue =
new PriorityQueue<NodeComparator>(150, // 用來排序任意兩點之間的距離��,從大到小排
new Comparator<NodeComparator>() {
public int compare(NodeComparator one, NodeComparator two) {
if (one.distance < two.distance)
return 1;
else if (one.distance > two.distance)
return -1;
else
return 0;
}
});
public void setKmeansInput(String path) {
try {
BufferedReader br = new BufferedReader(new FileReader(path));
String str;
String[] strArray;
arraylist = new ArrayList<Node>();
while ((str = br.readLine()) != null) {
strArray = str.split(",");
dimension = strArray.length;
Node node = new Node();
for (int i = 0; i < dimension; ++i) {
node.attributes[i] = Double.parseDouble(strArray[i]);
}
arraylist.add(node);
}
br.close();
} catch (IOException e) {
e.printStackTrace();
}
}
public void computeTheK() {
int cntTuple = 0;
for (int i = 0; i < arraylist.size() - 1; ++i) {
for (int j = i + 1; j < arraylist.size(); ++j) {
NodeComparator nodecomp = new NodeComparator();
nodecomp.nodeOne = new Node();
nodecomp.nodeTwo = new Node();
for (int k = 0; k < dimension; ++k) {
nodecomp.nodeOne.attributes[k] = arraylist.get(i).attributes[k];
nodecomp.nodeTwo.attributes[k] = arraylist.get(j).attributes[k];
}
nodecomp.compute();
averageDis += nodecomp.distance;
FsQueue.add(nodecomp);
cntTuple++;
}
}
averageDis /= cntTuple;// 計算平均距離
chooseCentroid(FsQueue);
}
public double getDistance(Node one, Node two) {// 計算兩點間的歐氏距離
double val = 0;
for (int i = 0; i < dimension; ++i) {
val += (one.attributes[i] - two.attributes[i]) * (one.attributes[i] - two.attributes[i]);
}
return val;
}
public void chooseCentroid(Queue<NodeComparator> queue) {
centroidList = new ArrayList<Node>();
boolean flag = false;
while (!queue.isEmpty()) {
boolean judgeOne = false;
boolean judgeTwo = false;
NodeComparator nc = FsQueue.poll();
if (nc.distance < averageDis)
break;// 如果接下來的元組�,兩節(jié)點間距離小于平均距離,則不繼續(xù)迭代
if (!flag) {
centroidList.add(nc.nodeOne);// 先加入所有點中距離最遠的兩個點
centroidList.add(nc.nodeTwo);
flag = true;
} else {// 之后從之前已加入的最遠的兩個點開始��,找離這兩個點最遠的點�����,
// 如果距離大于所有點的平均距離��,則認為找到了新的質心���,否則不認定為質心
for (int i = 0; i < centroidList.size(); ++i) {
Node testnode = centroidList.get(i);
if (centroidList.contains(nc.nodeOne) || getDistance(testnode, nc.nodeOne) < averageDis) {
judgeOne = true;
}
if (centroidList.contains(nc.nodeTwo) || getDistance(testnode, nc.nodeTwo) < averageDis) {
judgeTwo = true;
}
}
if (!judgeOne) {
centroidList.add(nc.nodeOne);
}
if (!judgeTwo) {
centroidList.add(nc.nodeTwo);
}
}
}
}
public void doIteration(ArrayList<Node> centroid) {
int cnt = 1;
int cntEnd = 0;
int numLabel = centroid.size();
while (true) {// 迭代����,直到所有的質心都不變化為止
boolean flag = false;
for (int i = 0; i < arraylist.size(); ++i) {
double dis = 0x7fffffff;
cnt = 1;
for (int j = 0; j < centroid.size(); ++j) {
Node node = centroid.get(j);
if (getDistance(arraylist.get(i), node) < dis) {
dis = getDistance(arraylist.get(i), node);
arraylist.get(i).label = cnt;
}
cnt++;
}
}
int j = 0;
numLabel -= 1;
while (j < numLabel) {
int c = 0;
Node node = new Node();
for (int i = 0; i < arraylist.size(); ++i) {
if (arraylist.get(i).label == j + 1) {
for (int k = 0; k < dimension; ++k) {
node.attributes[k] += arraylist.get(i).attributes[k];
}
c++;
}
}
DecimalFormat df = new DecimalFormat("#.###");// 保留小數點后三位
double[] attributelist = new double[100];
for (int i = 0; i < dimension; ++i) {
attributelist[i] = Double.parseDouble(df.format(node.attributes[i] / c));
if (attributelist[i] != centroid.get(j).attributes[i]) {
centroid.get(j).attributes[i] = attributelist[i];
flag = true;
}
}
if (!flag) {
cntEnd++;
if (cntEnd == numLabel) {// 若所有的質心都不變,則跳出循環(huán)
break;
}
}
j++;
}
if (cntEnd == numLabel) {// 若所有的質心都不變�����,則 success
System.out.println("run kmeans successfully.");
break;
}
}
}
public void printKmeansResults(String path) {
try {
PrintStream out = new PrintStream(path);
computeTheK();
doIteration(centroidList);
out.println("There are " + centroidList.size() + " clusters!");
for (int i = 0; i < arraylist.size(); ++i) {
out.print("(");
for (int j = 0; j < dimension - 1; ++j) {
out.print(arraylist.get(i).attributes[j] + ", ");
}
out.print(arraylist.get(i).attributes[dimension - 1] + ") ");
out.println("belongs to cluster " + arraylist.get(i).label);
}
out.close();
System.out.println("Please check results in: " + path);
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
Kmeans kmeans = new Kmeans();
kmeans.setKmeansInput("c:/kmeans.txt");
kmeans.printKmeansResults("c:/kmeansResults.txt");
}
}
測試數據
給出一組簡單的二維測試數據:
清單 2. Kmeans 算法測試數據
1,1
2,1
1,2
2,2
6,1
6,2
7,1
7,2
1,5
1,6
2,5
2,6
6,5
6,6
7,5
7,6
運行結果
清單 3. Kmeans 算法運行結果
There are 4 clusters!
(1.0, 1.0) belongs to cluster 1
(2.0, 1.0) belongs to cluster 1
(1.0, 2.0) belongs to cluster 1
(2.0, 2.0) belongs to cluster 1
(6.0, 1.0) belongs to cluster 3
(6.0, 2.0) belongs to cluster 3
(7.0, 1.0) belongs to cluster 3
(7.0, 2.0) belongs to cluster 3
(1.0, 5.0) belongs to cluster 4
(1.0, 6.0) belongs to cluster 4
(2.0, 5.0) belongs to cluster 4
(2.0, 6.0) belongs to cluster 4
(6.0, 5.0) belongs to cluster 2
(6.0, 6.0) belongs to cluster 2
(7.0, 5.0) belongs to cluster 2
(7.0, 6.0) belongs to cluster 2
層次聚類分為凝聚式層次聚類和分裂式層次聚類�。
凝聚式層次聚類,就是在初始階段將每一個點都視為一個簇����,之后每一次合并兩個最接近的簇,當然對于接近程度的定義則需要指定簇的鄰近準則����。
分裂式層次聚類,就是在初始階段將所有的點視為一個簇���,之后每次分裂出一個簇�,直到最后剩下單個點的簇為止�����。
本文中我們將詳細介紹凝聚式層次聚類算法����。
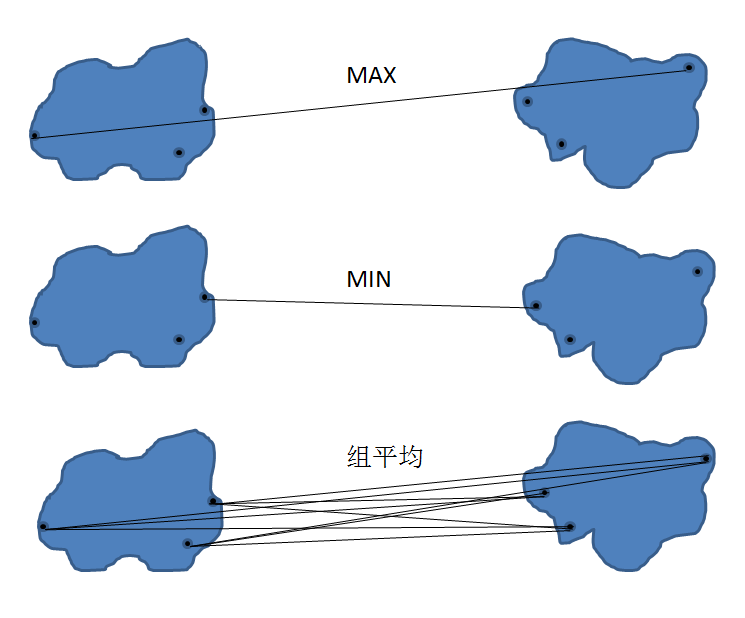
對于凝聚式層次聚類,指定簇的鄰近準則是非常重要的一個環(huán)節(jié)����,在此我們介紹三種最常用的準則,分別是 MAX, MIN, 組平均���。如下圖所示:
圖 2. 層次聚類計算準則
算法流程
凝聚式層次聚類算法也是一個迭代的過程���,算法流程如下:
-
每次選最近的兩個簇合并,我們將這兩個合并后的簇稱之為合并簇�����。
-
若采用 MAX 準則���,選擇其他簇與合并簇中離得最遠的兩個點之間的距離作為簇之間的鄰近度����。若采用 MIN 準則�����,取其他簇與合并簇中離得最近的兩個點之間的距離作為簇之間的鄰近度��。若組平均準則,取其他簇與合并簇所有點之間距離的平均值作為簇之間的鄰近度��。
-
重復步驟 1 和步驟 2����,合并至只剩下一個簇。
算法過程舉例
下面我們看一個例子:
下圖是一個有五個點的而為坐標系:
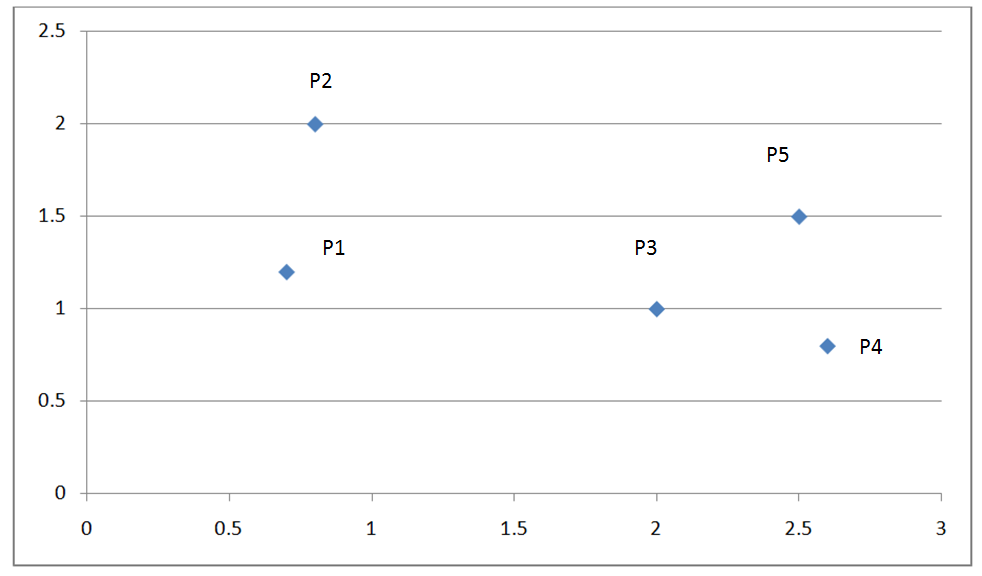
下表為這五個點的歐式距離矩陣:
表 1. 歐式距離原始矩陣
|
|
P1
|
P2
|
P3
|
P4
|
P5
|
|
P1
|
0
|
0.81
|
1.32
|
1.94
|
1.82
|
|
P2
|
0.81
|
0
|
1.56
|
2.16
|
1.77
|
|
P3
|
1.32
|
1.56
|
0
|
0.63
|
0.71
|
|
P4
|
1.94
|
2.16
|
0.63
|
0
|
0.71
|
|
P5
|
1.82
|
1.77
|
0.71
|
0.71
|
0
|
根據算法流程�����,我們先找出距離最近的兩個簇�,P3, P4。
合并 P3, P4 為 {P3, P4}�,根據 MIN 原則更新矩陣如下:
MIN.distance({P3, P4}, P1) = 1.32;
MIN.distance({P3, P4}, P2) = 1.56;
MIN.distance({P3, P4}, P5) = 0.70;
表 2. 歐式距離更新矩陣 1
|
|
P1
|
P2
|
{P3, P4}
|
P5
|
|
P1
|
0
|
0.81
|
1.32
|
1.82
|
|
P2
|
0.81
|
0
|
1.56
|
1.77
|
|
{P3, P4}
|
1.32
|
1.56
|
0
|
0.71
|
|
P5
|
1.82
|
1.77
|
0.71
|
0
|
接著繼續(xù)找出距離最近的兩個簇,{P3, P4}, P5����。
合并 {P3, P4}, P5 為 {P3, P4, P5},根據 MIN 原則繼續(xù)更新矩陣:
MIN.distance(P1, {P3, P4, P5}) = 1.32;
MIN.distance(P2, {P3, P4, P5}) = 1.56;
表 3. 歐式距離更新矩陣 2
|
|
P1
|
P2
|
{P3, P4, P5}
|
|
P1
|
0
|
0.81
|
1.32
|
|
P2
|
0.81
|
0
|
1.56
|
|
{P3, P4, P5}
|
1.32
|
1.56
|
0
|
接著繼續(xù)找出距離最近的兩個簇�,P1, P2。
合并 P1, P2 為 {P1, P2}���,根據 MIN 原則繼續(xù)更新矩陣:
MIN.distance({P1,P2}, {P3, P4, P5}) = 1.32
表 4. 歐式距離更新矩陣 3
|
|
{P1, P2}
|
{P3, P4, P5}
|
|
{P1, P2}
|
0
|
1.32
|
|
{P3, P4, P5}
|
1.32
|
0
|
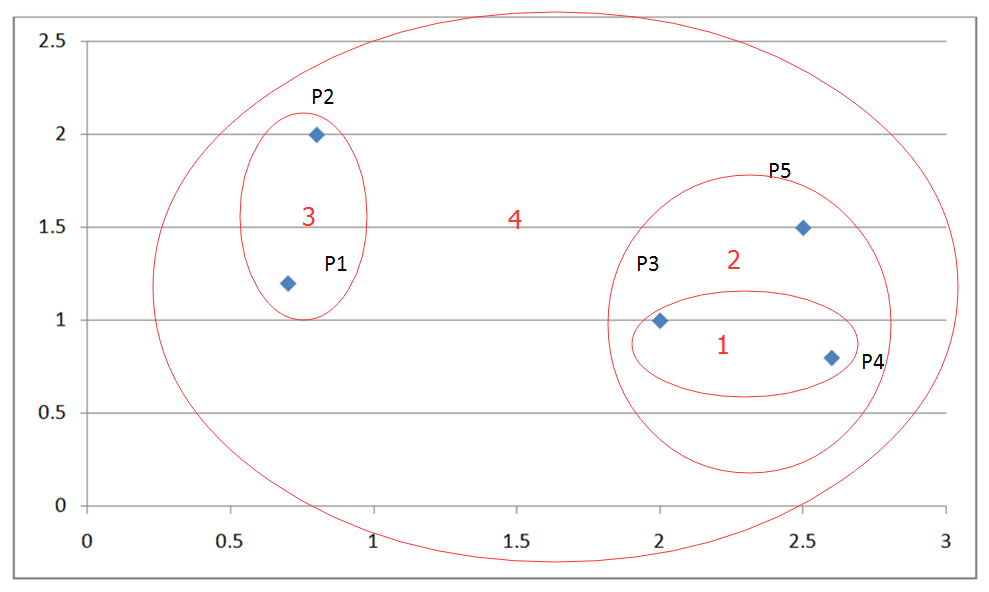
最終合并剩下的這兩個簇即可獲得最終結果,如下圖:
圖 4. 層次聚類舉例結果
MAX���,組平均算法流程同理�,只是在更新矩陣時將上述計算簇間距離變?yōu)榇亻g兩點最大歐式距離,和簇間所有點平均歐式距離即可����。
算法實現
清單 4. 層次聚類算法代碼實現
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.io.PrintStream;
import java.text.DecimalFormat;
import java.util.ArrayList;
public class Hierarchical {
private double[][] matrix;
private int dimension;// 數據維度
private class Node {
double[] attributes;
public Node() {
attributes = new double[100];
}
}
private ArrayList<Node> arraylist;
private class Model {
int x = 0;
int y = 0;
double value = 0;
}
private Model minModel = new Model();
private double getDistance(Node one, Node two) {// 計算兩點間的歐氏距離
double val = 0;
for (int i = 0; i < dimension; ++i) {
val += (one.attributes[i] - two.attributes[i]) * (one.attributes[i] - two.attributes[i]);
}
return Math.sqrt(val);
}
private void loadMatrix() {// 將輸入數據轉化為矩陣
for (int i = 0; i < matrix.length; ++i) {
for (int j = i + 1; j < matrix.length; ++j) {
double distance = getDistance(arraylist.get(i), arraylist.get(j));
matrix[i][j] = distance;
}
}
}
private Model findMinValueOfMatrix(double[][] matrix) {// 找出矩陣中距離最近的兩個簇
Model model = new Model();
double min = 0x7fffffff;
for (int i = 0; i < matrix.length; ++i) {
for (int j = i + 1; j < matrix.length; ++j) {
if (min > matrix[i][j] && matrix[i][j] != 0) {
min = matrix[i][j];
model.x = i;
model.y = j;
model.value = matrix[i][j];
}
}
}
return model;
}
private void processHierarchical(String path) {
try {
PrintStream out = new PrintStream(path);
while (true) {// 凝聚層次聚類迭代
out.println("Matrix update as below: ");
for (int i = 0; i < matrix.length; ++i) {// 輸出每次迭代更新的矩陣
for (int j = 0; j < matrix.length - 1; ++j) {
out.print(new DecimalFormat("#.00").format(matrix[i][j]) + " ");
}
out.println(new DecimalFormat("#.00").format(matrix[i][matrix.length - 1]));
}
out.println();
minModel = findMinValueOfMatrix(matrix);
if (minModel.value == 0) {// 當找不出距離最近的兩個簇時,迭代結束
break;
}
out.println("Combine " + (minModel.x + 1) + " " + (minModel.y + 1));
out.println("The distance is: " + minModel.value);
matrix[minModel.x][minModel.y] = 0;// 更新矩陣
for (int i = 0; i < matrix.length; ++i) {// 如果合并了點 p1 與 p2��,則只保留 p1,p2 其中之一與其他點的距離��,取較小值
if (matrix[i][minModel.x] <= matrix[i][minModel.y]) {
matrix[i][minModel.y] = 0;
} else {
matrix[i][minModel.x] = 0;
}
if (matrix[minModel.x][i] <= matrix[minModel.y][i]) {
matrix[minModel.y][i] = 0;
} else {
matrix[minModel.x][i] = 0;
}
}
}
out.close();
System.out.println("Please check results in: " + path);
} catch (Exception e) {
e.printStackTrace();
}
}
public void setInput(String path) {
try {
BufferedReader br = new BufferedReader(new FileReader(path));
String str;
String[] strArray;
arraylist = new ArrayList<Node>();
while ((str = br.readLine()) != null) {
strArray = str.split(",");
dimension = strArray.length;
Node node = new Node();
for (int i = 0; i < dimension; ++i) {
node.attributes[i] = Double.parseDouble(strArray[i]);
}
arraylist.add(node);
}
matrix = new double[arraylist.size()][arraylist.size()];
loadMatrix();
br.close();
} catch (IOException e) {
e.printStackTrace();
}
}
public void printOutput(String path) {
processHierarchical(path);
}
public static void main(String[] args) {
Hierarchical hi = new Hierarchical();
hi.setInput("c:/hierarchical.txt");
hi.printOutput("c:/hierarchical_results.txt");
}
}
測試數據
給出一組簡單的二維測試數據
清單 5. 層次聚類算法測試數據
0.7,1.2
0.8,2
2,1
2.6,0.8
2.5,1.5
運行結果
清單 6. 層次聚類算法運行結果
Matrix update as below:
.00 .81 1.32 1.94 1.82
.00 .00 1.56 2.16 1.77
.00 .00 .00 .63 .71
.00 .00 .00 .00 .71
.00 .00 .00 .00 .00
Combine 3 4
The distance is: 0.6324555320336759
Matrix update as below:
.00 .81 1.32 .00 1.82
.00 .00 1.56 .00 1.77
.00 .00 .00 .00 .00
.00 .00 .00 .00 .71
.00 .00 .00 .00 .00
Combine 4 5
The distance is: 0.7071067811865475
Matrix update as below:
.00 .81 1.32 .00 .00
.00 .00 1.56 .00 .00
.00 .00 .00 .00 .00
.00 .00 .00 .00 .00
.00 .00 .00 .00 .00
Combine 1 2
The distance is: 0.806225774829855
Matrix update as below:
.00 .00 1.32 .00 .00
.00 .00 .00 .00 .00
.00 .00 .00 .00 .00
.00 .00 .00 .00 .00
.00 .00 .00 .00 .00
Combine 1 3
The distance is: 1.3152946437965907
Matrix update as below:
.00 .00 .00 .00 .00
.00 .00 .00 .00 .00
.00 .00 .00 .00 .00
.00 .00 .00 .00 .00
.00 .00 .00 .00 .00
DBSCAN 算法詳解及實現
考慮一種情況�,點的分布不均勻,形狀不規(guī)則時��,Kmeans 算法及層次聚類算法將面臨失效的風險�����。
如下坐標系:
圖 5. DBSCAN 算法舉例
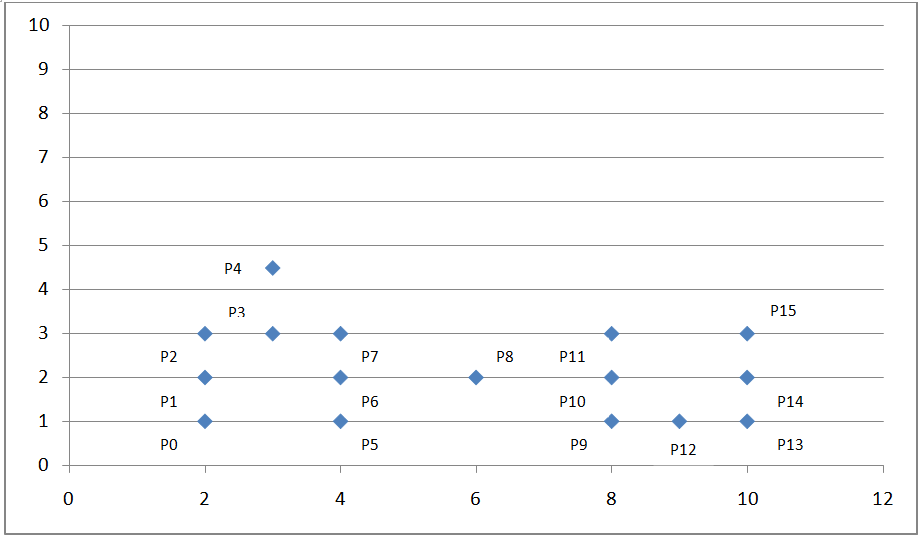
我們可以看到上面的點密度不均勻���,這時我們考慮采用基于密度的聚類算法:DBSCAN��。
算法流程
-
設定掃描半徑 Eps, 并規(guī)定掃描半徑內的密度值���。若當前點的半徑范圍內密度大于等于設定密度值����,則設置當前點為核心點�����;若某點剛好在某核心點的半徑邊緣上�����,則設定此點為邊界點��;若某點既不是核心點又不是邊界點�����,則此點為噪聲點�����。
-
刪除噪聲點��。
-
將距離在掃描半徑內的所有核心點賦予邊進行連通����。
-
每組連通的核心點標記為一個簇����。
-
將所有邊界點指定到與之對應的核心點的簇總����。
算法過程舉例
如上圖坐標系所示���,我們設定掃描半徑 Eps 為 1.5����,密度閾值 threshold 為 3����,則通過上述算法過程,我們可以得到下圖:
圖 6. DBSCAN 算法舉例結果示例
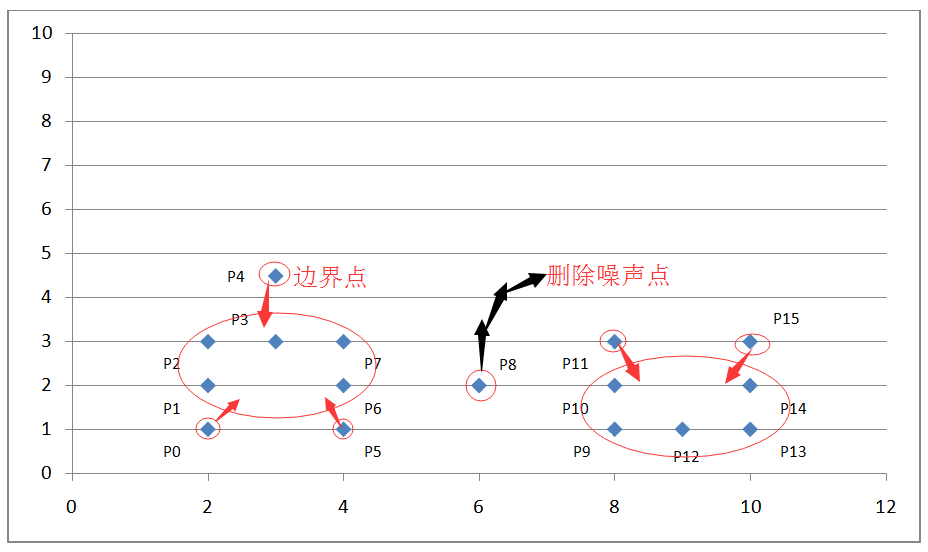
通過計算各個點之間的歐式距離及其所在掃描半徑內的密度值來判斷這些點屬于核心點�,邊界點或是噪聲點。因為我們設定了掃描半徑為 1.5�,密度閾值為 3,所以:
-
P0 點為邊界點����,因為在以其為中心的掃描半徑內只有兩個點 P0 和 P1;
-
P1 點為核心點���,因為在以其為中心的掃描半徑內有四個點 P0,P1,P2,P4 ���;
-
P8 為噪聲點�����,因為其既非核心點��,也非邊界點����;
-
其他點依次類推����。
算法實現
清單 7. DBSCAN 算法代碼實現
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.io.PrintStream;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
public class DBSCAN {
private int dimension;// 數據維度
private double eps = 1.5;
private int threshold = 3;
private double distance[][];
private Map<Integer, Integer> id = new HashMap<Integer, Integer>();
private int countClusters = 0;
private ArrayList<Integer> keyPointList = new ArrayList<Integer>();//
private int[] flags;// 標記邊緣點
private class Edge {
int p, q;
double weight;
}
private class Node {
double[] attributes;
public Node() {
attributes = new double[100];
}
}
private ArrayList<Node> nodeList;
private ArrayList<Edge> edgeList;
private double getDistance(Node one, Node two) {// 計算兩點間的歐氏距離
double val = 0;
for (int i = 0; i < dimension; ++i) {
val += (one.attributes[i] - two.attributes[i]) * (one.attributes[i] - two.attributes[i]);
}
return Math.sqrt(val);
}
public void loadEdges() {// 給所有在掃描半徑內的核心點之間加邊,標記邊界點并且自動忽略噪聲點
edgeList = new ArrayList<Edge>();
flags = new int[nodeList.size()];
int[] countPoint = new int[nodeList.size()];
for (int i = 0; i < countPoint.length; ++i) {
countPoint[i] = 1;// 每一個點一開始都是核心點
}
for (int i = 0; i < nodeList.size(); ++i) {
for (int j = i + 1; j < nodeList.size(); ++j) {
distance[i][j] = getDistance(nodeList.get(i), nodeList.get(j));
if (distance[i][j] <= eps) {// 兩點間距離小于掃描半徑
countPoint[i]++;
if (countPoint[i] > 0 && countPoint[i] < threshold) {
flags[i] = j;// 記錄邊界點
}
if (countPoint[i] >= threshold) {// 如果記錄當前點的掃描半徑內密度值大于或等于給定閾值
flags[i] = 0;
if (!keyPointList.contains(i)) {
keyPointList.add(i);
}
}
countPoint[j]++;
if (countPoint[j] > 0 && countPoint[j] < threshold) {
flags[j] = i;// 記錄邊界點
}
if (countPoint[j] >= threshold) {// 如果記錄當前點的掃描半徑內密度值大于或等于給定
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330