5種常用的相關分析方法
相關分析(Analysis of Correlation)是網(wǎng)站分析中經(jīng)常使用的分析方法之一。通過對不同特征或數(shù)據(jù)間的關系進行分析����,發(fā)現(xiàn)業(yè)務運營中的關鍵影響及驅(qū)動因素。并對業(yè)務的發(fā)展進行預測���。本篇文章將介紹5種常用的分析方法��。在開始介紹相關分析之前�,需要特別說明的是相關關系不等于因果關系�����。
相關分析的方法很多,初級的方法可以快速發(fā)現(xiàn)數(shù)據(jù)之間的關系����,如正相關,負相關或不相關����。中級的方法可以對數(shù)據(jù)間關系的強弱進行度量,如完全相關�����,不完全相關等���。高級的方法可以將數(shù)據(jù)間的關系轉(zhuǎn)化為模型�����,并通過模型對未來的業(yè)務發(fā)展進行預測�����。下面我們以一組廣告的成本數(shù)據(jù)和曝光量數(shù)據(jù)對每一種相關分析方法進行介紹���。
以下是每日廣告曝光量和費用成本的數(shù)據(jù)��,每一行代表一天中的花費和獲得的廣告曝光數(shù)量�����。憑經(jīng)驗判斷�����,這兩組數(shù)據(jù)間應該存在聯(lián)系���,但僅通過這兩組數(shù)據(jù)我們無法證明這種關系真實存在���,也無法對這種關系的強度進行度量���。因此我們希望通過相關分析來找出這兩組數(shù)據(jù)之間的關系,并對這種關系進度度量�����。
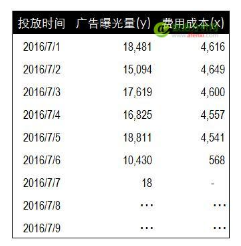
1��,圖表相關分析(折線圖及散點圖)
第一種相關分析方法是將數(shù)據(jù)進行可視化處理�����,簡單的說就是繪制圖表。單純從數(shù)據(jù)的角度很難發(fā)現(xiàn)其中的趨勢和聯(lián)系�,而將數(shù)據(jù)點繪制成圖表后趨勢和聯(lián)系就會變的清晰起來。對于有明顯時間維度的數(shù)據(jù)�����,我們選擇使用折線圖���。
為了更清晰的對比這兩組數(shù)據(jù)的變化和趨勢�,我們使用雙坐標軸折線圖�����,其中主坐標軸用來繪制廣告曝光量數(shù)據(jù)���,次坐標軸用來繪制費用成本的數(shù)據(jù)���。通過折線圖可以發(fā)現(xiàn),費用成本和廣告曝光量兩組數(shù)據(jù)的變化和趨勢大致相同���,從整體的大趨勢來看�,費用成本和廣告曝光量兩組數(shù)據(jù)都呈現(xiàn)增長趨勢。從規(guī)律性來看費用成本和廣告曝光量數(shù)據(jù)每次的最低點都出現(xiàn)在同一天���。從細節(jié)來看�,兩組數(shù)據(jù)的短期趨勢的變化也基本一致��。
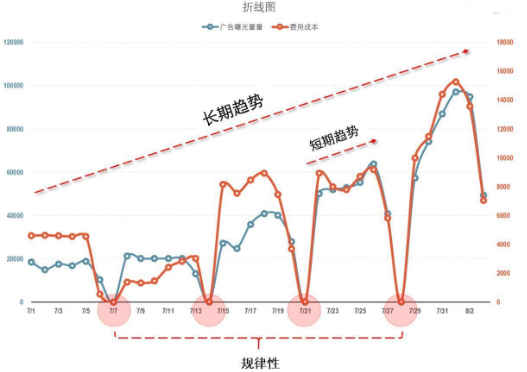
經(jīng)過以上這些對比����,我們可以說廣告曝光量和費用成本之間有一些相關關系,但這種方法在整個分析過程和解釋上過于復雜��,如果換成復雜一點的數(shù)據(jù)或者相關度較低的數(shù)據(jù)就會出現(xiàn)很多問題���。
比折線圖更直觀的是散點圖����。散點圖去除了時間維度的影響��,只關注廣告曝光量和費用成本這里兩組數(shù)據(jù)間的關系�����。在繪制散點圖之前���,我們將費用成本標識為X�����,也就是自變量�����,將廣告曝光量標識為y����,也就是因變量���。下面是一張根據(jù)每一天中廣告曝光量和費用成本數(shù)據(jù)繪制的散點圖���,X軸是自變量費用成本數(shù)據(jù),Y軸是因變量廣告曝光量數(shù)據(jù)�����。從數(shù)據(jù)點的分布情況可以發(fā)現(xiàn),自變量x和因變量y有著相同的變化趨勢����,當費用成本的增加后��,廣告曝光量也隨之增加��。
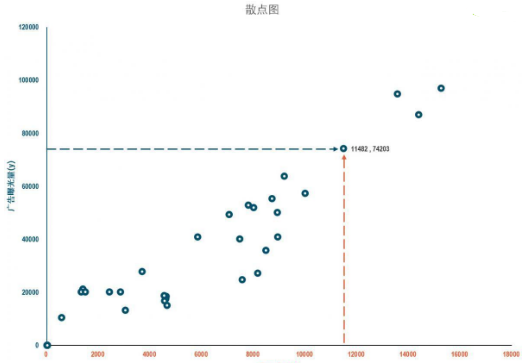
折線圖和散點圖都清晰的表示了廣告曝光量和費用成本兩組數(shù)據(jù)間的相關關系���,優(yōu)點是對相關關系的展現(xiàn)清晰�����,缺點是無法對相關關系進行準確的度量��,缺乏說服力��。并且當數(shù)據(jù)超過兩組時也無法完成各組數(shù)據(jù)間的相關分析����。若要通過具體數(shù)字來度量兩組或兩組以上數(shù)據(jù)間的相關關系��,需要使用第二種方法:協(xié)方差���。
2�����,協(xié)方差及協(xié)方差矩陣
第二種相關分析方法是計算協(xié)方差�。協(xié)方差用來衡量兩個變量的總體誤差�����,如果兩個變量的變化趨勢一致���,協(xié)方差就是正值�,說明兩個變量正相關�����。如果兩個變量的變化趨勢相反��,協(xié)方差就是負值�,說明兩個變量負相關。如果兩個變量相互獨立����,那么協(xié)方差就是0��,說明兩個變量不相關��。以下是協(xié)方差的計算公式:
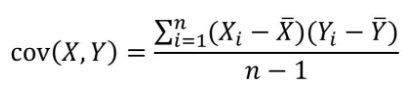
下面是廣告曝光量和費用成本間協(xié)方差的計算過程和結(jié)果���,經(jīng)過計算,我們得到了一個很大的正值��,因此可以說明兩組數(shù)據(jù)間是正相關的����。廣告曝光量隨著費用成本的增長而增長。在實際工作中不需要按下面的方法來計算����,可以通過Excel中COVAR()函數(shù)直接獲得兩組數(shù)據(jù)的協(xié)方差值。
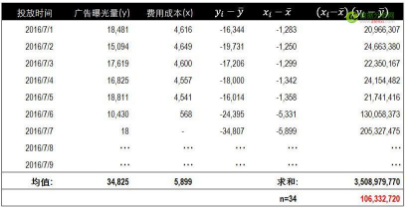
協(xié)方差只能對兩組數(shù)據(jù)進行相關性分析����,當有兩組以上數(shù)據(jù)時就需要使用協(xié)方差矩陣。下面是三組數(shù)據(jù)x�����,y����,z,的協(xié)方差矩陣計算公式��。
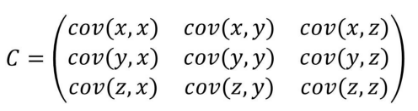
協(xié)方差通過數(shù)字衡量變量間的相關性��,正值表示正相關�����,負值表示負相關����。但無法對相關的密切程度進行度量。當我們面對多個變量時�����,無法通過協(xié)方差來說明那兩組數(shù)據(jù)的相關性最高�。要衡量和對比相關性的密切程度,就需要使用下一個方法:相關系數(shù)���。,
3��,相關系數(shù)
第三個相關分析方法是相關系數(shù)��。相關系數(shù)(Correlation coefficient)是反應變量之間關系密切程度的統(tǒng)計指標�����,相關系數(shù)的取值區(qū)間在1到-1之間���。1表示兩個變量完全線性相關���,-1表示兩個變量完全負相關,0表示兩個變量不相關���。數(shù)據(jù)越趨近于0表示相關關系越弱�。以下是相關系數(shù)的計算公式�。
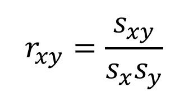
其中rxy表示樣本相關系數(shù),Sxy表示樣本協(xié)方差����,Sx表示X的樣本標準差,Sy表示y的樣本標準差�����。下面分別是Sxy協(xié)方差和Sx和Sy標準差的計算公式。由于是樣本協(xié)方差和樣本標準差���,因此分母使用的是n-1���。
Sxy樣本協(xié)方差計算公式:
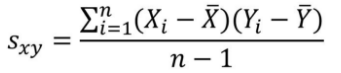
Sx樣本標準差計算公式:
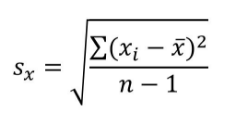
Sy樣本標準差計算公式:
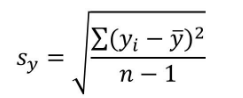
下面是計算相關系數(shù)的過程����,在表中我們分別計算了x,y變量的協(xié)方差以及各自的標準差�,并求得相關系數(shù)值為0.93。0.93大于0說明兩個變量間正相關����,同時0.93非常接近于1,說明兩個變量間高度相關��。
在實際工作中��,不需要上面這么復雜的計算過程����,在Excel的數(shù)據(jù)分析模塊中選擇相關系數(shù)功能,設置好x�,y變量后可以自動求得相關系數(shù)的值。在下面的結(jié)果中可以看到�����,廣告曝光量和費用成本的相關系數(shù)與我們手動求的結(jié)果一致。

相關系數(shù)的優(yōu)點是可以通過數(shù)字對變量的關系進行度量��,并且?guī)в蟹较蛐裕?表示正相關����,-1表示負相關,可以對變量關系的強弱進行度量�,越靠近0相關性越弱。缺點是無法利用這種關系對數(shù)據(jù)進行預測���,簡單的說就是沒有對變量間的關系進行提煉和固化�����,形成模型�����。要利用變量間的關系進行預測��,需要使用到下一種相關分析方法�,回歸分析。,
4�����,一元回歸及多元回歸
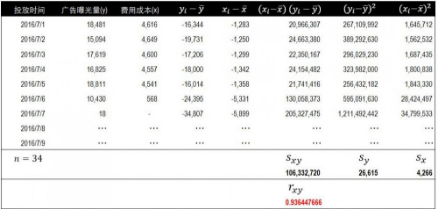
第四種相關分析方法是回歸分析�����?;貧w分析(regression analysis)是確定兩組或兩組以上變量間關系的統(tǒng)計方法?��;貧w分析按照變量的數(shù)量分為一元回歸和多元回歸。兩個變量使用一元回歸��,兩個以上變量使用多元回歸�。進行回歸分析之前有兩個準備工作,第一確定變量的數(shù)量�。第二確定自變量和因變量。我們的數(shù)據(jù)中只包含廣告曝光量和費用成本兩個變量�����,因此使用一元回歸���。根據(jù)經(jīng)驗廣告曝光量是隨著費用成本的變化而改變的�����,因此將費用成本設置為自變量x�,廣告曝光量設置為因變量y。
以下是一元回歸方程��,其中y表示廣告曝光量��,x表示費用成本����。b0為方程的截距,b1為斜率��,同時也表示了兩個變量間的關系���。我們的目標就是b0和b1的值�,知道了這兩個值也就知道了變量間的關系�。并且可以通過這個關系在已知成本費用的情況下預測廣告曝光量。
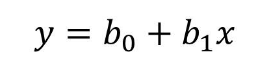
這是b1的計算公式�,我們通過已知的費用成本x和廣告曝光量y來計算b1的值。
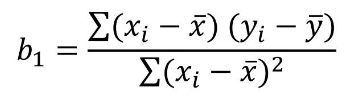
以下是通過最小二乘法計算b1值的具體計算過程和結(jié)果�,經(jīng)計算���,b1的值為5.84。同時我們也獲得了自變量和因變量的均值���。通過這三個值可以計算出b0的值�。
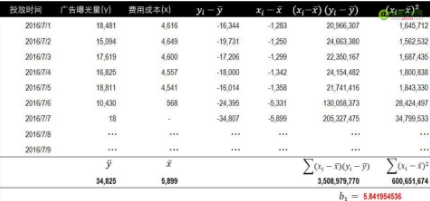
以下是b0的計算公式���,在已知b1和自變量與因變量均值的情況下����,b0的值很容易計算�����。
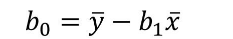
將自變量和因變量的均值以及斜率b1代入到公式中���,求出一元回歸方程截距b0的值為374。這里b1我們保留兩位小數(shù)��,取值5.84���。
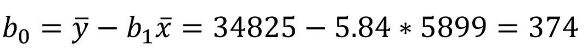
在實際的工作中不需要進行如此繁瑣的計算���,Excel可以幫我們自動完成并給出結(jié)果��。在Excel中使用數(shù)據(jù)分析中的回歸功能�,輸入自變量和因變量的范圍后可以自動獲得b0(Intercept)的值362.15和b1的值5.84��。這里的b0和之前手動計算獲得的值有一些差異�����,因為前面用于計算的b1值只保留了兩位小數(shù)����。
這里還要單獨說明下R Square的值0.87。這個值叫做判定系數(shù)���,用來度量回歸方程的擬合優(yōu)度�����。這個值越大�����,說明回歸方程越有意義�,自變量對因變量的解釋度越高。

將截距b0和斜率b1代入到一元回歸方程中就獲得了自變量與因變量的關系�。費用成本每增加1元,廣告曝光量會增加379.84次����。通過這個關系我們可以根據(jù)成本預測廣告曝光量數(shù)據(jù)。也可以根據(jù)轉(zhuǎn)化所需的廣告曝光量來反推投入的費用成本���。獲得這個方程還有一個更簡單的方法�����,就是在Excel中對自變量和因變量生成散點圖�����,然后選擇添加趨勢線�,在添加趨勢線的菜單中選中顯示公式和顯示R平方值即可�����。
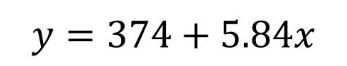
以上介紹的是兩個變量的一元回歸方法��,如果有兩個以上的變量使用Excel中的回歸分析��,選中相應的自變量和因變量范圍即可����。下面是多元回歸方程。
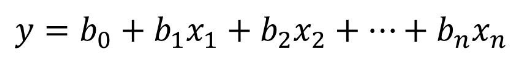
5��,信息熵及互信息
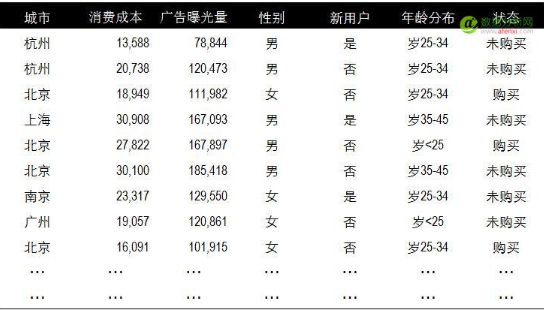
最后一種相關分析方法是信息熵與互信息����。前面我們一直在圍繞消費成本和廣告曝光量兩組數(shù)據(jù)展開分析。實際工作中影響最終效果的因素可能有很多�,并且不一定都是數(shù)值形式。比如我們站在更高的維度來看之前的數(shù)據(jù)��。廣告曝光量只是一個過程指標���,最終要分析和關注的是用戶是否購買的狀態(tài)���。而影響這個結(jié)果的因素也不僅僅是消費成本或其他數(shù)值化指標??赡苁且恍?a href='/map/tezheng/' style='color:#000;font-size:inherit;'>特征值。例如用戶所在的城市����,用戶的性別�,年齡區(qū)間分布����,以及是否第一次到訪網(wǎng)站等等。這些都不能通過數(shù)字進行度量�����。
度量這些文本特征值之間相關關系的方法就是互信息�����。通過這種方法我們可以發(fā)現(xiàn)哪一類特征與最終的結(jié)果關系密切��。下面是我們模擬的一些用戶特征和數(shù)據(jù)�����。在這些數(shù)據(jù)中我們忽略之前的消費成本和廣告曝光量數(shù)據(jù)�,只關注特征與狀態(tài)的關系。
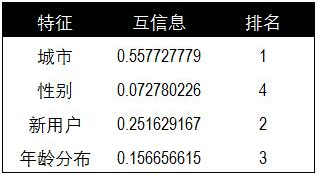
對于信息熵和互信息具體的計算過程請參考文章《決策樹分類和預測算法的原理及實現(xiàn)》���,這里直接給出每個特征的互信息值以及排名結(jié)果。經(jīng)過計算城市與購買狀態(tài)的相關性最高�����,所在城市為北京的用戶購買率較高。
到此為止5種相關分析方法都已介紹完��,每種方法各有特點��。其中圖表方法最為直觀���,相關系數(shù)方法可以看到變量間兩兩的相關性�����,回歸方程可以對相關關系進行提煉���,并生成模型用于預測,互信息可以對文本類特征間的相關關系進行度量���。
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330