本文描述了一個(gè)基于 Spark 構(gòu)建的認(rèn)知系統(tǒng):文本情感分析系統(tǒng)�,分析和理解社交論壇的非結(jié)構(gòu)化文本數(shù)據(jù)。
基于 Spark 的文本情感分析
文本情感分析是指對(duì)具有人為主觀情感色彩文本材料進(jìn)行處理����、分析和推理的過(guò)程。文本情感分析主要的應(yīng)用場(chǎng)景是對(duì)用戶關(guān)于某個(gè)主題的評(píng)論文本進(jìn)行處理和分析����。比如,人們?cè)诖蛩闳タ匆徊侩娪爸?����,通常?huì)去看豆瓣電影板塊上的用戶評(píng)論�����,再?zèng)Q定是否去看這部電影����。另外一方面�,電影制片人會(huì)通過(guò)對(duì)專(zhuān)業(yè)論壇上的用戶評(píng)論進(jìn)行分析�,了解市場(chǎng)對(duì)于電影的總體反饋�。本文中文本分析的對(duì)象為網(wǎng)絡(luò)短評(píng),為非正式場(chǎng)合的短文本語(yǔ)料��,在只考慮正面傾向和負(fù)面傾向的情況下,實(shí)現(xiàn)文本傾向性的分類(lèi)。
文本情感分析主要涉及如下四個(gè)技術(shù)環(huán)節(jié):
收集數(shù)據(jù)集:本文中,以分析電影《瘋狂動(dòng)物城》的用戶評(píng)論為例子��,采集豆瓣上《瘋狂動(dòng)物城》的用戶短評(píng)和短評(píng)評(píng)分作為樣本數(shù)據(jù)����,通過(guò)樣本數(shù)據(jù)訓(xùn)練分類(lèi)模型來(lái)判斷微博上的一段話對(duì)該電影的情感傾向���。
設(shè)計(jì)文本的表示模型:讓機(jī)器“讀懂”文字,是文本情感分析的基礎(chǔ),而這首先要解決的問(wèn)題是文本的表示模型。通常���,文本的表示采用向量空間模型��,也就是說(shuō)采用向量表示文本����。向量的特征項(xiàng)是模型中最小的單元,可以是一個(gè)文檔中的字、詞或短語(yǔ)���,一個(gè)文檔的內(nèi)容可以看成是它的特征項(xiàng)組成的集合�����,而每一個(gè)特征項(xiàng)依據(jù)一定的原則都被賦予上權(quán)重�����。
選擇文本的特征:當(dāng)可以把一個(gè)文檔映射成向量后,那如何選擇特征項(xiàng)和特征值呢����?通常的做法是先進(jìn)行中文分詞(----本文使用 jieba 分詞工具)����,把用戶評(píng)論轉(zhuǎn)化成詞語(yǔ)后,可以使用 TF-IDF(Term Frequency–Inverse Document Frequency�,詞頻-逆文檔頻率)算法來(lái)抽取特征�����,并計(jì)算出特征值����。
選擇分類(lèi)模型:常用的分類(lèi)算法有很多���,如:決策樹(shù)����、貝葉斯����、人工神經(jīng)網(wǎng)絡(luò)、K-近鄰��、支持向量機(jī)等等。在文本分類(lèi)上使用較多的是貝葉斯和支持向量機(jī)。本文中���,也以這兩種方法來(lái)進(jìn)行模型訓(xùn)練�����。
為什么采用 Spark
傳統(tǒng)的單節(jié)點(diǎn)計(jì)算已經(jīng)難以滿足用戶生成的海量數(shù)據(jù)的處理和分析的要求。比如����,豆瓣網(wǎng)站上《瘋狂動(dòng)物城》電影短評(píng)就有 111421 條,如果需要同時(shí)處理來(lái)自多個(gè)大型專(zhuān)業(yè)網(wǎng)站上所有電影的影評(píng)����,單臺(tái)服務(wù)器的計(jì)算能力和存儲(chǔ)能力都很難滿足需求。這個(gè)時(shí)候需要考慮引入分布式計(jì)算的技術(shù)�����,使得計(jì)算能力和存儲(chǔ)能力能夠線性擴(kuò)展�����。
Spark 是一個(gè)快速的�、通用的集群計(jì)算平臺(tái),也是業(yè)內(nèi)非常流行的開(kāi)源分布式技術(shù)���。Spark 圍繞著 RDD(Resilient Distributed Dataset)彈性分布式數(shù)據(jù)集,擴(kuò)展了廣泛使用的 MapReduce[5]計(jì)算模型,相比起 Hadoop[6]的 MapReduce 計(jì)算框架�����,Spark 更為高效和靈活。Spark 主要的特點(diǎn)如下:
內(nèi)存計(jì)算:能夠在內(nèi)存中進(jìn)行計(jì)算��,它會(huì)優(yōu)先考慮使用各計(jì)算節(jié)點(diǎn)的內(nèi)存作為存儲(chǔ),當(dāng)內(nèi)存不足時(shí)才會(huì)考慮使用磁盤(pán)����,這樣極大的減少了磁盤(pán) I/O�,提高了效率。
惰性求值:RDD 豐富的計(jì)算操作可以分為兩類(lèi)���,轉(zhuǎn)化操作和行動(dòng)操作�。而當(dāng)程序調(diào)用 RDD 的轉(zhuǎn)化操作(如數(shù)據(jù)的讀取�����、Map、Filter)的時(shí)候���,Spark 并不會(huì)立刻開(kāi)始計(jì)算,而是記下所需要執(zhí)行的操作��,盡可能的將一些轉(zhuǎn)化操作合并,來(lái)減少計(jì)算數(shù)據(jù)的步驟����,只有在調(diào)用行動(dòng)操作(如獲取數(shù)據(jù)的行數(shù) Count)的時(shí)候才會(huì)開(kāi)始讀入數(shù)據(jù)��,進(jìn)行轉(zhuǎn)化操作��、行動(dòng)操作����,得到結(jié)果���。
接口豐富:Spark 提供 Scala�,Java�,Python,R 四種編程語(yǔ)言接口���,可以滿足不同技術(shù)背景的工程人員的需求��。并且還能和其他大數(shù)據(jù)工具密切配合。例如 Spark 可以運(yùn)行在 Hadoop 之上�����,能夠訪問(wèn)所有支持 Hadoop 的數(shù)據(jù)源(如 HDFS�、Cassandra����、Hbase)�����。
本文以 Spark 的 Python 接口為例,介紹如何構(gòu)建一個(gè)文本情感分析系統(tǒng)����。作者采用 Python 3.5.0���,Spark1.6.1 作為開(kāi)發(fā)環(huán)境�����,使用 Jupyter Notebook[7]編寫(xiě)代碼。Jupyter Notebook 是由 IPython Notebook 演化而來(lái),是一套基于 Web 的交互環(huán)境,允許大家將代碼、代碼執(zhí)行�、數(shù)學(xué)函數(shù)�����、富文檔��、繪圖以及其它元素整合為單一文件���。在運(yùn)行 pyspark 的之前��,需要指定一下 pyspark 的運(yùn)行環(huán)境,如下所示:
清單 1. 指定 pyspark 的 ipython notebook 運(yùn)行環(huán)境

接下里就可以在 Jupyter Notebook 里編寫(xiě)代碼了。
基于 Spark 如何構(gòu)建文本情感分析系統(tǒng)
在本文第 1 章�,介紹了文本情感分析主要涉及的四個(gè)技術(shù)環(huán)節(jié)?��;?Spark 構(gòu)建的文本分類(lèi)系統(tǒng)的技術(shù)流程也是這樣的����。在大規(guī)模的文本數(shù)據(jù)的情況下��,有所不同的是文本的特征維度一般都是非常巨大的�。試想一下所有的中文字���、詞有多少�����,再算上其他的語(yǔ)言和所有能在互聯(lián)網(wǎng)上找到的文本,那么文本數(shù)據(jù)按照詞的維度就能輕松的超過(guò)數(shù)十萬(wàn)����、數(shù)百萬(wàn)維����,所以需要尋找一種可以處理極大維度文本數(shù)據(jù)的方法��。
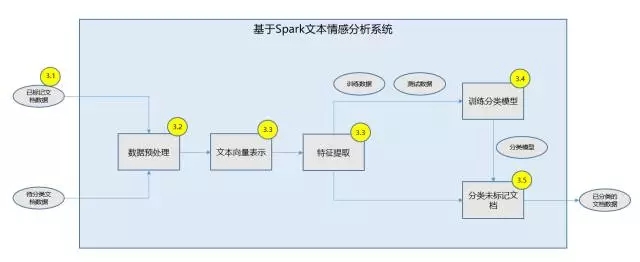
在本文后續(xù)章節(jié)中,將依次按照基于 Spark 做數(shù)據(jù)預(yù)處理�����、文本建模����、特征提取、訓(xùn)練分類(lèi)模型、實(shí)現(xiàn)待輸入文本分類(lèi)展開(kāi)討論����。系統(tǒng)的上下文關(guān)系圖如圖 1 所示,系統(tǒng)的功能架構(gòu)圖如圖 2 所示�����。
圖 1. 基于 Spark 文本情感分析系統(tǒng)上下文

圖 2. 基于 Spark 文本情感分析系統(tǒng)功能架構(gòu)圖
爬取的數(shù)據(jù)說(shuō)明
為了說(shuō)明文本分類(lèi)系統(tǒng)的構(gòu)建過(guò)程����,作者爬取了豆瓣網(wǎng)絡(luò)上《瘋狂動(dòng)物城》的短評(píng)和評(píng)分(https://movie.douban.com/subject/25662329/comments)。示例數(shù)據(jù)如下所示:
表 1. 示例數(shù)據(jù)

表格中每一行為一條評(píng)論數(shù)據(jù)���,按照“評(píng)分�����,評(píng)論文本”排放�,中間以制表符切分�,評(píng)分范圍從 1 分到 5 分���,這樣的數(shù)據(jù)共采集了 116567 條。
數(shù)據(jù)預(yù)處理
這一節(jié)本文是要說(shuō)明用 Spark 是如何做數(shù)據(jù)清洗和抽取的���。在該子系統(tǒng)中輸入為爬蟲(chóng)的數(shù)據(jù)��,輸出為包含相同數(shù)量好評(píng)和壞評(píng)的 Saprk 彈性分布式數(shù)據(jù)集�。
Spark 數(shù)據(jù)處理主要是圍繞 RDD(Resilient Distributed Datasets) 彈性分布式數(shù)據(jù)集對(duì)象展開(kāi),本文首先將爬蟲(chóng)數(shù)據(jù)載入到 Spark 系統(tǒng)���,抽象成為一個(gè) RDD�。可以用 distinct 方法對(duì)數(shù)據(jù)去重�����。數(shù)據(jù)轉(zhuǎn)換主要是用了 map 方法����,它接受傳入的一個(gè)數(shù)據(jù)轉(zhuǎn)換的方法來(lái)按行執(zhí)行方法����,從而達(dá)到轉(zhuǎn)換的操作它只需要用一個(gè)函數(shù)將輸入和輸出映射好��,那么就能完成轉(zhuǎn)換����。數(shù)據(jù)過(guò)濾使用 filter 方法,它能夠保留判斷條件為真的數(shù)據(jù)�?�?梢杂孟旅孢@個(gè)語(yǔ)句�,將每一行文本變成一個(gè) list���,并且只保留長(zhǎng)度為 2 的數(shù)據(jù)�。
清單 2. Spark 做數(shù)據(jù)預(yù)處理

清單 3. 統(tǒng)計(jì)數(shù)據(jù)基本信息
 本文得到�,五分的數(shù)據(jù)有 30447 條���,4 分、3 分、2 分�����、1 分的數(shù)據(jù)分別有 11711 條����,123 條����,70 條。打五分的毫無(wú)疑問(wèn)是好評(píng)��;考慮到不同人對(duì)于評(píng)分的不同偏好�,對(duì)于打四分的數(shù)據(jù),本文無(wú)法得知它是好評(píng)還是壞評(píng)�;對(duì)于打三分及三分以下的是壞評(píng)���。
下面就可以將帶有評(píng)分?jǐn)?shù)據(jù)轉(zhuǎn)化成為好評(píng)數(shù)據(jù)和壞評(píng)數(shù)據(jù),為了提高計(jì)算效率�,本文將其重新分區(qū)。
清單 4. 合并負(fù)樣本數(shù)據(jù)
本文得到�,五分的數(shù)據(jù)有 30447 條���,4 分、3 分、2 分�����、1 分的數(shù)據(jù)分別有 11711 條����,123 條����,70 條。打五分的毫無(wú)疑問(wèn)是好評(píng)��;考慮到不同人對(duì)于評(píng)分的不同偏好�,對(duì)于打四分的數(shù)據(jù),本文無(wú)法得知它是好評(píng)還是壞評(píng)�;對(duì)于打三分及三分以下的是壞評(píng)���。
下面就可以將帶有評(píng)分?jǐn)?shù)據(jù)轉(zhuǎn)化成為好評(píng)數(shù)據(jù)和壞評(píng)數(shù)據(jù),為了提高計(jì)算效率�,本文將其重新分區(qū)。
清單 4. 合并負(fù)樣本數(shù)據(jù)
 通過(guò)計(jì)算得到���,好評(píng)和壞評(píng)分別有 30447 條和 2238 條���,屬于非平衡樣本的機(jī)器模型訓(xùn)練。本文只取部分好評(píng)數(shù)據(jù)���,好評(píng)和壞評(píng)的數(shù)量一樣�,這樣訓(xùn)練的正負(fù)樣本就是均衡的���。最后把正負(fù)樣本放在一起���,并把分類(lèi)標(biāo)簽和文本分開(kāi),形成訓(xùn)練數(shù)據(jù)集
清單 5. 生成訓(xùn)練數(shù)據(jù)集
通過(guò)計(jì)算得到���,好評(píng)和壞評(píng)分別有 30447 條和 2238 條���,屬于非平衡樣本的機(jī)器模型訓(xùn)練。本文只取部分好評(píng)數(shù)據(jù)���,好評(píng)和壞評(píng)的數(shù)量一樣�,這樣訓(xùn)練的正負(fù)樣本就是均衡的���。最后把正負(fù)樣本放在一起���,并把分類(lèi)標(biāo)簽和文本分開(kāi),形成訓(xùn)練數(shù)據(jù)集
清單 5. 生成訓(xùn)練數(shù)據(jù)集
 文本的向量表示和文本特征提取
這一節(jié)中�����,本文主要介紹如何做文本分詞�,如何用 TF-IDF 算法抽取文本特征。將輸入的文本數(shù)據(jù)轉(zhuǎn)化為向量�,讓計(jì)算能夠“讀懂”文本。
解決文本分類(lèi)問(wèn)題�,最重要的就是要讓文本可計(jì)算,用合適的方式來(lái)表示文本���,其中的核心就是找到文本的特征和特征值�����。相比起英文���,中文多了一個(gè)分詞的過(guò)程。本文首先用 jieba 分詞器將文本分詞��,這樣每個(gè)詞都可以作為文本的一個(gè)特征�����。jieba 分詞器有三種模式的分詞:
精確模式����,試圖將句子最精確地切開(kāi),適合文本分析;
全模式���,把句子中所有的可以成詞的詞語(yǔ)都掃描出來(lái)���, 速度非常快�����,但是不能解決歧義�;
搜索引擎模式,在精確模式的基礎(chǔ)上���,對(duì)長(zhǎng)詞再次切分�,提高召回率��,適合用于搜索引擎分詞�����。
這里本文用的是搜索引擎模式將每一句評(píng)論轉(zhuǎn)化為詞�����。
清單 6. 分詞
文本的向量表示和文本特征提取
這一節(jié)中�����,本文主要介紹如何做文本分詞�,如何用 TF-IDF 算法抽取文本特征。將輸入的文本數(shù)據(jù)轉(zhuǎn)化為向量�,讓計(jì)算能夠“讀懂”文本。
解決文本分類(lèi)問(wèn)題�,最重要的就是要讓文本可計(jì)算,用合適的方式來(lái)表示文本���,其中的核心就是找到文本的特征和特征值�����。相比起英文���,中文多了一個(gè)分詞的過(guò)程。本文首先用 jieba 分詞器將文本分詞��,這樣每個(gè)詞都可以作為文本的一個(gè)特征�����。jieba 分詞器有三種模式的分詞:
精確模式����,試圖將句子最精確地切開(kāi),適合文本分析;
全模式���,把句子中所有的可以成詞的詞語(yǔ)都掃描出來(lái)���, 速度非常快�����,但是不能解決歧義�;
搜索引擎模式,在精確模式的基礎(chǔ)上���,對(duì)長(zhǎng)詞再次切分�,提高召回率��,適合用于搜索引擎分詞�����。
這里本文用的是搜索引擎模式將每一句評(píng)論轉(zhuǎn)化為詞�����。
清單 6. 分詞
 出于對(duì)大規(guī)模數(shù)據(jù)計(jì)算需求的考慮,spark 的詞頻計(jì)算是用特征哈希(HashingTF)來(lái)計(jì)算的����。特征哈希是一種處理高維數(shù)據(jù)的技術(shù)���,經(jīng)常應(yīng)用在文本和分類(lèi)數(shù)據(jù)集上���。普通的 k 分之一特征編碼需要在一個(gè)向量中維護(hù)可能的特征值及其到下標(biāo)的映射,而每次構(gòu)建這個(gè)映射的過(guò)程本身就需要對(duì)數(shù)據(jù)集進(jìn)行一次遍歷���。這并不適合上千萬(wàn)甚至更多維度的特征處理�����。
特征哈希是通過(guò)哈希方程對(duì)特征賦予向量下標(biāo)的�����,所以在不同情況下�����,同樣的特征就是能夠得到相同的向量下標(biāo)�,這樣就不需要維護(hù)一個(gè)特征值及其下表的向量。
要使用特征哈希來(lái)處理文本��,需要先實(shí)例化一個(gè) HashingTF 對(duì)象�����,將詞轉(zhuǎn)化為詞頻�����,為了高效計(jì)算���,本文將后面會(huì)重復(fù)使用的詞頻緩存�����。
清單 7. 訓(xùn)練詞頻矩陣
出于對(duì)大規(guī)模數(shù)據(jù)計(jì)算需求的考慮,spark 的詞頻計(jì)算是用特征哈希(HashingTF)來(lái)計(jì)算的����。特征哈希是一種處理高維數(shù)據(jù)的技術(shù)���,經(jīng)常應(yīng)用在文本和分類(lèi)數(shù)據(jù)集上���。普通的 k 分之一特征編碼需要在一個(gè)向量中維護(hù)可能的特征值及其到下標(biāo)的映射,而每次構(gòu)建這個(gè)映射的過(guò)程本身就需要對(duì)數(shù)據(jù)集進(jìn)行一次遍歷���。這并不適合上千萬(wàn)甚至更多維度的特征處理�����。
特征哈希是通過(guò)哈希方程對(duì)特征賦予向量下標(biāo)的�����,所以在不同情況下�����,同樣的特征就是能夠得到相同的向量下標(biāo)�,這樣就不需要維護(hù)一個(gè)特征值及其下表的向量。
要使用特征哈希來(lái)處理文本��,需要先實(shí)例化一個(gè) HashingTF 對(duì)象�����,將詞轉(zhuǎn)化為詞頻�����,為了高效計(jì)算���,本文將后面會(huì)重復(fù)使用的詞頻緩存�����。
清單 7. 訓(xùn)練詞頻矩陣

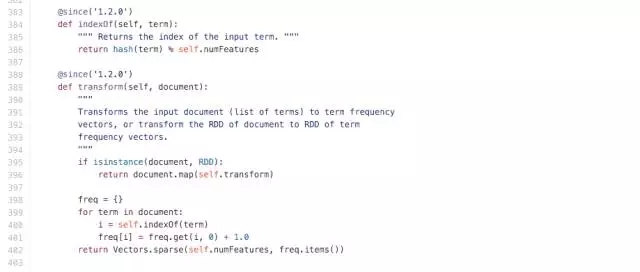
缺省情況下����,實(shí)例化的 HashingTF 特征維數(shù) numFeatures 取了 220次方維�,在 spark 的源碼中可以看到,HashingTF 的過(guò)程就是對(duì)每一個(gè)詞作了一次哈希并對(duì)特征維數(shù)取余得到該詞的位置�����,然后按照該詞出現(xiàn)的次數(shù)計(jì)次。所以就不用像傳統(tǒng)方法一樣每次維護(hù)一張?jiān)~表���,運(yùn)用 HashingTF 就可以方便的得到該詞所對(duì)應(yīng)向量元素的位置��。當(dāng)然這樣做的代價(jià)就是向量維數(shù)會(huì)非常大����,好在 spark 可以支持稀疏向量��,所以計(jì)算開(kāi)銷(xiāo)并不大���。
圖 3. HashingTF 源碼
 詞頻是一種抽取特征的方法,但是它還有很多問(wèn)題�,比如在這句話中“這幾天的天氣真好,項(xiàng)目組的老師打算組織大家一起去春游�����?���!暗摹毕啾扔凇绊?xiàng)目組”更容易出現(xiàn)在人們的語(yǔ)言中,“的”和“項(xiàng)目組”同樣只出現(xiàn)一次����,但是項(xiàng)目組對(duì)于這句話來(lái)說(shuō)更重要�。
本文采用 TF-IDF 作為特征提取的方法����,它的權(quán)重與特征項(xiàng)在文檔中出現(xiàn)的評(píng)率成正相關(guān),與在整個(gè)語(yǔ)料中出現(xiàn)該特征項(xiàng)的文檔成反相關(guān)�����。下面依據(jù) tf 來(lái)計(jì)算逆詞頻 idf����,并計(jì)算出 TF-IDF
清單 8. 計(jì)算 TF-IDF 矩陣
詞頻是一種抽取特征的方法,但是它還有很多問(wèn)題�,比如在這句話中“這幾天的天氣真好,項(xiàng)目組的老師打算組織大家一起去春游�����?���!暗摹毕啾扔凇绊?xiàng)目組”更容易出現(xiàn)在人們的語(yǔ)言中,“的”和“項(xiàng)目組”同樣只出現(xiàn)一次����,但是項(xiàng)目組對(duì)于這句話來(lái)說(shuō)更重要�。
本文采用 TF-IDF 作為特征提取的方法����,它的權(quán)重與特征項(xiàng)在文檔中出現(xiàn)的評(píng)率成正相關(guān),與在整個(gè)語(yǔ)料中出現(xiàn)該特征項(xiàng)的文檔成反相關(guān)�����。下面依據(jù) tf 來(lái)計(jì)算逆詞頻 idf����,并計(jì)算出 TF-IDF
清單 8. 計(jì)算 TF-IDF 矩陣
 至此,本文就抽取出了文本的特征����,并用向量去表示了文本。
訓(xùn)練分類(lèi)模型
在這一小節(jié)中��,本文介紹如何用 Spark 訓(xùn)練樸素貝葉斯分類(lèi)模型�����,這一流程的輸入是文本的特征向量及已經(jīng)標(biāo)記好的分類(lèi)標(biāo)簽����。在這里本文得到的是分類(lèi)模型及文本分類(lèi)的正確率�。
現(xiàn)在�,有了文本的特征項(xiàng)及特征值,也有了分類(lèi)標(biāo)簽����,需要用 RDD 的 zip 算子將這兩部分?jǐn)?shù)據(jù)連接起來(lái),并將其轉(zhuǎn)化為分類(lèi)模型里的 LabeledPoint 類(lèi)型�。并隨機(jī)將數(shù)據(jù)分為訓(xùn)練集和測(cè)試集,60%作為訓(xùn)練集���,40%作為測(cè)試集。
清單 9. 生成訓(xùn)練集和測(cè)試集
至此,本文就抽取出了文本的特征����,并用向量去表示了文本。
訓(xùn)練分類(lèi)模型
在這一小節(jié)中��,本文介紹如何用 Spark 訓(xùn)練樸素貝葉斯分類(lèi)模型�����,這一流程的輸入是文本的特征向量及已經(jīng)標(biāo)記好的分類(lèi)標(biāo)簽����。在這里本文得到的是分類(lèi)模型及文本分類(lèi)的正確率�。
現(xiàn)在�,有了文本的特征項(xiàng)及特征值,也有了分類(lèi)標(biāo)簽����,需要用 RDD 的 zip 算子將這兩部分?jǐn)?shù)據(jù)連接起來(lái),并將其轉(zhuǎn)化為分類(lèi)模型里的 LabeledPoint 類(lèi)型�。并隨機(jī)將數(shù)據(jù)分為訓(xùn)練集和測(cè)試集,60%作為訓(xùn)練集���,40%作為測(cè)試集。
清單 9. 生成訓(xùn)練集和測(cè)試集
 本文用訓(xùn)練數(shù)據(jù)來(lái)訓(xùn)練貝葉斯模型�,得到 NBmodel 模型來(lái)預(yù)測(cè)測(cè)試集的文本特征向量,并且計(jì)算出各個(gè)模型的正確率���,這個(gè)模型的正確率為 74.83%�。
清單 10. 訓(xùn)練貝葉斯分類(lèi)模型
本文用訓(xùn)練數(shù)據(jù)來(lái)訓(xùn)練貝葉斯模型�,得到 NBmodel 模型來(lái)預(yù)測(cè)測(cè)試集的文本特征向量,并且計(jì)算出各個(gè)模型的正確率���,這個(gè)模型的正確率為 74.83%�。
清單 10. 訓(xùn)練貝葉斯分類(lèi)模型
 可以看出貝葉斯模型最后的預(yù)測(cè)模型并不高����,但是基于本文采集的數(shù)據(jù)資源有限,特征提取過(guò)程比較簡(jiǎn)單直接����。所以還有很大的優(yōu)化空間�,在第四章中���,本文將介紹提高正確率的方法����。
分類(lèi)未標(biāo)記文檔
現(xiàn)在可以用本文訓(xùn)練好的模型來(lái)對(duì)未標(biāo)記文本分類(lèi)���,流程是獲取用戶輸入的評(píng)論����,然后將輸入的評(píng)論文本分詞并轉(zhuǎn)化成 tf-idf 特征向量���,然后用 3.4 節(jié)中訓(xùn)練好的分類(lèi)模型來(lái)分類(lèi)����。
清單 11. 分類(lèi)未分類(lèi)文本
可以看出貝葉斯模型最后的預(yù)測(cè)模型并不高����,但是基于本文采集的數(shù)據(jù)資源有限,特征提取過(guò)程比較簡(jiǎn)單直接����。所以還有很大的優(yōu)化空間�,在第四章中���,本文將介紹提高正確率的方法����。
分類(lèi)未標(biāo)記文檔
現(xiàn)在可以用本文訓(xùn)練好的模型來(lái)對(duì)未標(biāo)記文本分類(lèi)���,流程是獲取用戶輸入的評(píng)論����,然后將輸入的評(píng)論文本分詞并轉(zhuǎn)化成 tf-idf 特征向量���,然后用 3.4 節(jié)中訓(xùn)練好的分類(lèi)模型來(lái)分類(lèi)����。
清單 11. 分類(lèi)未分類(lèi)文本
 當(dāng)程序輸入待分類(lèi)的評(píng)論:“這部電影沒(méi)有意思�,劇情老套,真沒(méi)勁�����, 后悔來(lái)看了”
程序輸出為“NaiveBayes Model Predict: 0.0”。
當(dāng)程序輸入待分類(lèi)的評(píng)論:“太精彩了講了一個(gè)關(guān)于夢(mèng)想的故事劇情很反轉(zhuǎn)制作也很精良”
程序輸出為“NaiveBayes Model Predict: 1.0”���。
至此����,最為簡(jiǎn)單的文本情感分類(lèi)系統(tǒng)就構(gòu)建完整了�。
提高正確率的方法
在第三章中,本文介紹了構(gòu)建文本分類(lèi)系統(tǒng)的方法���,但是正確率只有 74.83%�,在這一章中��,本文將講述文本分類(lèi)正確率低的原因及改進(jìn)方法����。
文本分類(lèi)正確率低的原因主要有:
文本預(yù)處理比較粗糙�����,可以進(jìn)一步處理���,比如去掉停用詞�����,去掉低頻詞����;
特征詞抽取信息太少,搜索引擎模式的分詞模式不如全分詞模式提供的特征項(xiàng)多��;
樸素貝葉斯模型比較簡(jiǎn)單����,可以用其他更為先進(jìn)的模型算法,如 SVM��;
數(shù)據(jù)資源太少�����,本文只能利用了好評(píng)���、壞評(píng)論各 2238 條�。數(shù)據(jù)量太少�����,由于爬蟲(chóng)爬取的數(shù)據(jù),沒(méi)有進(jìn)行人工的進(jìn)一步的篩選�,數(shù)據(jù)質(zhì)量也得不到 100%的保證。
下面分別就這四個(gè)方面���,本文進(jìn)一步深入的進(jìn)行處理���,對(duì)模型進(jìn)行優(yōu)化。
數(shù)據(jù)預(yù)處理中去掉停用詞
停用詞是指出現(xiàn)在所有文檔中很多次的常用詞�,比如“的”、“了”���、“是”等�����,可以在提取特征的時(shí)候?qū)⑦@些噪聲去掉���。
首先需要統(tǒng)計(jì)一下詞頻����,看哪些詞是使用最多的,然后定義一個(gè)停用詞表,在構(gòu)建向量前����,將這些詞去掉。本文先進(jìn)行詞頻統(tǒng)計(jì)��,查看最常用的詞是哪些���。
清單 12. 統(tǒng)計(jì)詞頻
當(dāng)程序輸入待分類(lèi)的評(píng)論:“這部電影沒(méi)有意思�,劇情老套,真沒(méi)勁�����, 后悔來(lái)看了”
程序輸出為“NaiveBayes Model Predict: 0.0”。
當(dāng)程序輸入待分類(lèi)的評(píng)論:“太精彩了講了一個(gè)關(guān)于夢(mèng)想的故事劇情很反轉(zhuǎn)制作也很精良”
程序輸出為“NaiveBayes Model Predict: 1.0”���。
至此����,最為簡(jiǎn)單的文本情感分類(lèi)系統(tǒng)就構(gòu)建完整了�。
提高正確率的方法
在第三章中,本文介紹了構(gòu)建文本分類(lèi)系統(tǒng)的方法���,但是正確率只有 74.83%�,在這一章中��,本文將講述文本分類(lèi)正確率低的原因及改進(jìn)方法����。
文本分類(lèi)正確率低的原因主要有:
文本預(yù)處理比較粗糙�����,可以進(jìn)一步處理���,比如去掉停用詞�����,去掉低頻詞����;
特征詞抽取信息太少,搜索引擎模式的分詞模式不如全分詞模式提供的特征項(xiàng)多��;
樸素貝葉斯模型比較簡(jiǎn)單����,可以用其他更為先進(jìn)的模型算法,如 SVM��;
數(shù)據(jù)資源太少�����,本文只能利用了好評(píng)���、壞評(píng)論各 2238 條�。數(shù)據(jù)量太少�����,由于爬蟲(chóng)爬取的數(shù)據(jù),沒(méi)有進(jìn)行人工的進(jìn)一步的篩選�,數(shù)據(jù)質(zhì)量也得不到 100%的保證。
下面分別就這四個(gè)方面���,本文進(jìn)一步深入的進(jìn)行處理���,對(duì)模型進(jìn)行優(yōu)化。
數(shù)據(jù)預(yù)處理中去掉停用詞
停用詞是指出現(xiàn)在所有文檔中很多次的常用詞�,比如“的”、“了”���、“是”等�����,可以在提取特征的時(shí)候?qū)⑦@些噪聲去掉���。
首先需要統(tǒng)計(jì)一下詞頻����,看哪些詞是使用最多的,然后定義一個(gè)停用詞表,在構(gòu)建向量前����,將這些詞去掉。本文先進(jìn)行詞頻統(tǒng)計(jì)��,查看最常用的詞是哪些���。
清單 12. 統(tǒng)計(jì)詞頻
 通過(guò)觀察���,選擇出現(xiàn)次數(shù)比較多,但是對(duì)于文本情感表達(dá)沒(méi)有意義的詞��,作為停用詞���,構(gòu)建停用詞表�����。然后定義一個(gè)過(guò)濾函數(shù)�����,如果該詞在停用詞表中那么需要將這個(gè)詞過(guò)濾掉���。
清單 13. 去掉停用詞
通過(guò)觀察���,選擇出現(xiàn)次數(shù)比較多,但是對(duì)于文本情感表達(dá)沒(méi)有意義的詞��,作為停用詞���,構(gòu)建停用詞表�����。然后定義一個(gè)過(guò)濾函數(shù)�����,如果該詞在停用詞表中那么需要將這個(gè)詞過(guò)濾掉���。
清單 13. 去掉停用詞

嘗試不用的分詞模式
本文在分詞的時(shí)候使用的搜索引擎分詞模式��,在這種模式下只抽取了重要的關(guān)鍵字��,可能忽略了一些可能的特征詞��?����?梢园逊衷~模式切換到全分詞模式�,盡可能的不漏掉特征詞���,同樣的模型訓(xùn)練�����,正確率會(huì)有 1%~2%的提升���。
清單 14. 全分詞模式分詞
 更換訓(xùn)練模型方法
在不進(jìn)行深入優(yōu)化的情況下,SVM 往往有著比其他分類(lèi)模型更好的分類(lèi)效果����。下面在相同的條件下,運(yùn)用 SVM 模型訓(xùn)練����,最后得到的正確率有 78.59%。
清單 15. 用支持向量機(jī)訓(xùn)練分類(lèi)模型
更換訓(xùn)練模型方法
在不進(jìn)行深入優(yōu)化的情況下,SVM 往往有著比其他分類(lèi)模型更好的分類(lèi)效果����。下面在相同的條件下,運(yùn)用 SVM 模型訓(xùn)練����,最后得到的正確率有 78.59%。
清單 15. 用支持向量機(jī)訓(xùn)練分類(lèi)模型
 訓(xùn)練數(shù)據(jù)的問(wèn)題
本文只是為了演示如何構(gòu)建這套系統(tǒng)�,所以爬取的數(shù)據(jù)量并不多,獲取的文本數(shù)據(jù)也沒(méi)有人工的進(jìn)一步核對(duì)其正確性����。如果本文能夠有更豐富且權(quán)威的數(shù)據(jù)源,那么模型的正確率將會(huì)有較大的提高����。
作者對(duì)中國(guó)科學(xué)院大學(xué)的譚松波教授發(fā)布的酒店產(chǎn)品評(píng)論文本做了分類(lèi)系統(tǒng)測(cè)試,該數(shù)據(jù)集是多數(shù)學(xué)者公認(rèn)并且使用的�。用 SVM 訓(xùn)練的模型正確率有 87.59%。
總結(jié)
訓(xùn)練數(shù)據(jù)的問(wèn)題
本文只是為了演示如何構(gòu)建這套系統(tǒng)�,所以爬取的數(shù)據(jù)量并不多,獲取的文本數(shù)據(jù)也沒(méi)有人工的進(jìn)一步核對(duì)其正確性����。如果本文能夠有更豐富且權(quán)威的數(shù)據(jù)源,那么模型的正確率將會(huì)有較大的提高����。
作者對(duì)中國(guó)科學(xué)院大學(xué)的譚松波教授發(fā)布的酒店產(chǎn)品評(píng)論文本做了分類(lèi)系統(tǒng)測(cè)試,該數(shù)據(jù)集是多數(shù)學(xué)者公認(rèn)并且使用的�。用 SVM 訓(xùn)練的模型正確率有 87.59%。
總結(jié)
本文向讀者詳細(xì)的介紹了利用 Spark 構(gòu)建文本情感分類(lèi)系統(tǒng)的過(guò)程��,從數(shù)據(jù)的清洗�、轉(zhuǎn)換,Spark 的 RDD 有 Filter����、Map 方法可以輕松勝任;對(duì)于抽取文本特征��,Spark 針對(duì)大規(guī)模數(shù)據(jù)的處理不僅在計(jì)算模型上有優(yōu)化,還做了算法的優(yōu)化�����,它利用哈希特征算法來(lái)實(shí)現(xiàn) TF-IDF����,從而能夠支持上千萬(wàn)維的模型訓(xùn)練;對(duì)于選擇分類(lèi)模型�����,Spark 也實(shí)現(xiàn)好了常用的分類(lèi)模型�����,調(diào)用起來(lái)非常方便�����。最后希望這篇文章可以對(duì)大家學(xué)習(xí) spark 和文本分類(lèi)有幫助��。
文 | 江 萬(wàn)�, 北京郵電大學(xué)研究生, 北京郵電大學(xué)
英 春����,軟件服務(wù)團(tuán)隊(duì)架構(gòu)師�����,IBM
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情��;
? 想學(xué)習(xí)CDA考試教材���,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫(kù),點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情�����;
? 想了解CDA考試含金量���,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330