如何基于數(shù)據(jù)快速構(gòu)建用戶模型(Persona)
用戶模型(Persona)是Alan Cooper在《About Face:交互設(shè)計(jì)精髓》一書中提到的研究用戶的系統(tǒng)化方法��。它是產(chǎn)品經(jīng)理、交互設(shè)計(jì)師了解用戶目標(biāo)和需求�、與開發(fā)團(tuán)隊(duì)及相關(guān)人交流�����、避免設(shè)計(jì)陷阱的重要工具����。
但在現(xiàn)實(shí)中,一般只有很少的成熟公司����,產(chǎn)品經(jīng)理、交互設(shè)計(jì)師或用戶研究人員才會花時間構(gòu)建用戶模型��,個人認(rèn)為之所以這樣����,至少包含兩方面原因:
一個主要原因在于,按照傳統(tǒng)方法構(gòu)建用戶模型的成本高��、時間長��,不是一般公司和團(tuán)隊(duì)所能承受的;
另一個原因在于,傳統(tǒng)方法對用戶模型構(gòu)建者的要求很高����,尤其是對用戶的訪談和觀察,其中有很多的方法和技巧��,不少產(chǎn)品經(jīng)理不敢嘗試���,有些人嘗試后并沒有得到有用的信息����,后面往往就不再做了���。
我們將嘗試提出一種基于用戶行為數(shù)據(jù)的快速構(gòu)建用戶模型的方法�。
用戶模型構(gòu)建的傳統(tǒng)方法
Alan Cooper提出了兩種構(gòu)建用戶模型的方法:
用戶模型:基于對用戶的訪談和觀察等研究結(jié)果建立����,嚴(yán)謹(jǐn)可靠但費(fèi)時;
臨時用戶模型(ad hoc persona):基于行業(yè)專家或市場調(diào)查數(shù)據(jù)對用戶的理解建立,快速但容易有偏頗�����。
方法1:基于訪談和觀察的構(gòu)建用戶模型(正統(tǒng)方法)
在Alan Cooper的方法中�����,對用戶的訪談和觀察是構(gòu)建用戶模型的重要基礎(chǔ)。完整步驟如下圖:
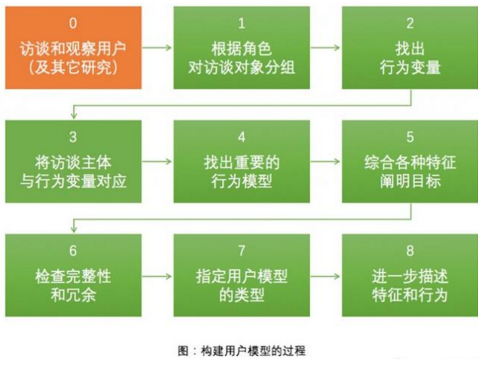
第0步:對用戶的訪談和觀察(及其他研究)���。將用戶當(dāng)成師傅,自己作為徒弟去觀察師傅的行為���,并提出問題��。在整個過程中收集并研究用戶行為�、環(huán)境�����、談話內(nèi)容等信息��,以發(fā)現(xiàn)用戶的行為����、情境和目標(biāo)。(比如����,某兒童社區(qū)的用戶角色大致分為孩子、媽媽、爸爸和祖輩等四類�,需要分別研究)
第1步:根據(jù)角色對訪談對象進(jìn)行分組。根據(jù)研究結(jié)果和理解對用戶進(jìn)行大致的角色劃分�����,并根據(jù)角色對要訪談的用戶進(jìn)行分組�����。
第2步:找出行為變量���。把每種角色的顯著行為列成幾組行為變量�����。一般包括用戶的活動(行為及頻率)�����、(對產(chǎn)品及相關(guān)技術(shù)的)態(tài)度���、能力、動機(jī)�����、技能幾個方面。
第3步:將訪談主體和行為變量對應(yīng)起來����。實(shí)際上就是為每個訪談用戶標(biāo)注各項(xiàng)行為的情況。
第4步:找出重要的行為模型��。發(fā)現(xiàn)訪談用戶中的中的顯著的行為模式組合�����。(比如兒童社區(qū)產(chǎn)品的「某些家長」會「密切關(guān)注」孩子在社區(qū)中的一舉一動����,而「另一些家長」則只是「偶爾了解」一下孩子的情況)
第5步:綜合各種特征�,闡明目標(biāo)。從用戶模型的行為細(xì)節(jié)中綜合/挖掘出用戶的目標(biāo)和其他特性�。
第6步:檢查完整性和冗余。為每種用戶模型彌補(bǔ)行為特征中重要的缺漏����,將行為模式相同而僅僅是人口統(tǒng)計(jì)數(shù)據(jù)有差異的用戶模型合并為一個。
第7步:指定用戶模型的類型���。對用戶模型進(jìn)行優(yōu)先級排序��,確定主要��、次要����、補(bǔ)充和負(fù)面用戶模型。主要用戶模型是界面設(shè)計(jì)的主要對象����,一個產(chǎn)品的一個界面,只能有一個主要用戶模型��。
第8步:進(jìn)一步描述特征和行為����。通過第三人稱敘述的方式描述用戶模型,并為不同用戶模型選擇恰當(dāng)?shù)恼掌?��。至此����,用戶模型?gòu)建完成�����。
方法2:構(gòu)建臨時用戶模型(ad hoc persona)
在缺乏時間、資源不能做對用戶的訪談和觀察時���,可以基于行業(yè)專家對用戶的理解�、或市場研究中獲得的人口統(tǒng)計(jì)數(shù)據(jù)�,建立「臨時用戶模型」。
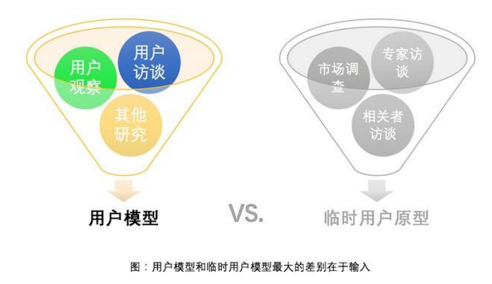
「臨時用戶模型」的構(gòu)建過程與「用戶模型」的構(gòu)建過程很像�,只是其數(shù)據(jù)基礎(chǔ)一個是來自對真實(shí)用戶的訪談和觀察,另一個是來自對用戶的理解���。二者的準(zhǔn)確度和精度都有差別���。
基于用戶行為數(shù)據(jù)快速���、迭代構(gòu)建用戶模型的方法
到現(xiàn)在����,距離Alan Cooper首次提出用戶模型(Persona)概念已經(jīng)過去快20年了3����。在這期間�����,軟件產(chǎn)品開發(fā)的過程方法以及公司的運(yùn)作方式都發(fā)生了很大改變:以快 速迭代為特點(diǎn)的敏捷開發(fā)方法取代了傳統(tǒng)的瀑布模型�,以「開發(fā)→測量→認(rèn)知」反饋循環(huán)為核心的精益創(chuàng)業(yè)方法在逐步影響和改變公司的運(yùn)作方式……
而傳統(tǒng)的用戶模型構(gòu)建方法�,從誕生之日起并未發(fā)生特別大的變化。對于已經(jīng)習(xí)慣了敏捷����、快速的產(chǎn)品經(jīng)理和交互設(shè)計(jì)師來說:一方面,花很長時間去研究用 戶構(gòu)建用戶模型需要下相當(dāng)大的決心��、更需要下很大力氣才能爭取到所需的時間和資源;另一方面���,互聯(lián)網(wǎng)產(chǎn)品冷啟動耗費(fèi)的時間越來越短�,為了降低成本和風(fēng)險�����, 產(chǎn)品團(tuán)隊(duì)在啟動期往往會選擇盡快將產(chǎn)品推向用戶�,盡快獲得反饋以「快速試錯」,現(xiàn)實(shí)和壓力迫使大多數(shù)新產(chǎn)品的PM不敢投入大量時間精力深入的進(jìn)行用戶研 究����。這就很容易理解��,為什么大家都覺得用戶模型很好���,卻鮮有人在工作中真正運(yùn)用它。
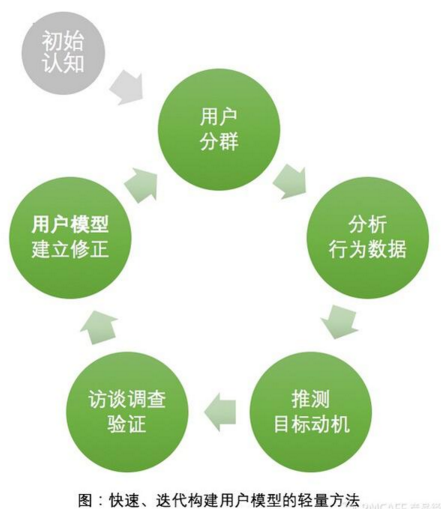
接下來����,我們將提出一種基于用戶行為數(shù)據(jù)的快速、迭代構(gòu)建用戶模型的輕量方法�����。
首先�,在開始時,整理和收集已經(jīng)獲得的任何對用戶的認(rèn)知��、經(jīng)驗(yàn)和數(shù)據(jù)�����。
它們可能是您和所在團(tuán)隊(duì)對用戶的理解�����,也可能是您產(chǎn)品的業(yè)務(wù)數(shù)據(jù)庫中記錄的用戶相關(guān)信息(比如用戶的性別�、年齡、等級等屬性)��,還可能是用戶(在產(chǎn)品內(nèi)外)填寫的任何表單或留下來的信息(比如用戶填寫的調(diào)查問卷��、留下的微信賬號等等)�。
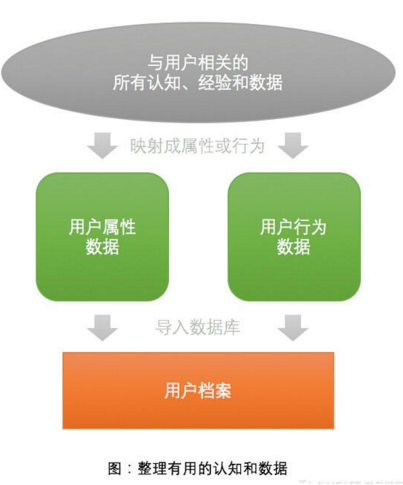
您可以將這些信息映射成為用戶的描述信息(屬性)或用戶的行為信息,并存儲起來形成用戶檔案(最終形成的結(jié)果如下圖示意)�����。
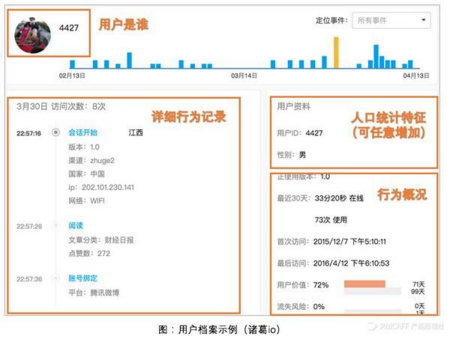
注意:從這一步開始��,你就需要一個存儲了用戶信息和用戶行為信息的數(shù)據(jù)庫系統(tǒng)����,它能夠支持你快速的進(jìn)行接下來的各種分析和探索�����,直至形成用戶模型��。
然后���,根據(jù)已獲得的認(rèn)知和經(jīng)驗(yàn)對用戶分群��,這些用戶群是進(jìn)一步研究的基礎(chǔ)���。比如���,你覺得用戶也許可以分為孩子、媽媽�、爸爸和祖輩等四類,或者你認(rèn)為購物的用戶可以分為男女兩類���,那就根據(jù)數(shù)據(jù)劃分好了�����。
接下來����,您就要對上一步的用戶群逐個進(jìn)行分析���,并嘗試從中發(fā)現(xiàn)顯著的行為模式。
對于每個用戶群��,分析步驟如下:
從用戶群中隨機(jī)選取一些用戶(一般根據(jù)您的時間情況,可以選取幾十到上百個用戶���,建議最少不低于30個);
逐個用戶解讀其屬性特征和行為記錄,努力通過這些數(shù)據(jù)還原出用戶的真實(shí)使用場景和過程��,并嘗試推測其目標(biāo)���。在解讀的同時��,隨時記錄你發(fā)現(xiàn)的有趣的行 為模式�����、以及不解之處��。(注意���,這一步的工作至關(guān)重要�����,對用戶及其行為的感性認(rèn)識是后續(xù)工作的基礎(chǔ)���。要記?��。鹤x用戶如讀書,讀其百遍�、其義自現(xiàn)!)
根據(jù)上面步驟中發(fā)現(xiàn)的典型行為模式和場景、目標(biāo)的推測���,對用戶群進(jìn)行更細(xì)致的劃分。比如�,你發(fā)現(xiàn)一些用戶會定期采購大量的辦公用品(有趣的行為模 式),并推測這些人可能是企業(yè)行政部門的采購人員�,他們要根據(jù)其他員工的需求定期完成采購任務(wù)(場景和目標(biāo)),那么你就可以將這群人劃分出來�����,作為一個單 獨(dú)的用戶群(候選的用戶模型)��,進(jìn)行后續(xù)的研究�����。
對上一步形成的候選用戶模型(用戶群),對其屬性和行為數(shù)據(jù)進(jìn)行統(tǒng)計(jì)分析�����,初步驗(yàn)證您的猜想���。
接下來,對上面形成的每個候選用戶模型���,進(jìn)一步完成其目標(biāo)和動機(jī)的推測���。同樣,在過程中有任何不解之處��,請記錄下來��。
從每個用戶模型中選取少量具有代表性的用戶�,進(jìn)行訪談或調(diào)查,以消除您在前面研究中遇到的不解之處�。在這一步, 如果您有足夠的時間和資源�,那么可以多選一些用戶,并盡可能的做現(xiàn)場的訪談和觀察;如果您時間和資源有限����,那么可以少選一些用戶�����,或者采用電話�、問卷等方 式完成訪談�,對于配合度較高的用戶,可以考慮采用錄屏或QQ遠(yuǎn)程協(xié)助之類的工具觀察用戶的真實(shí)行為��。因?yàn)槟谇懊娴牟襟E中已經(jīng)對用戶的真實(shí)行為有了一定的 了解�,所以在這一步,您可以不必嚴(yán)格的執(zhí)行Alan Cooper的用戶研究方法����,從而節(jié)省大量的時間和資源。但是��,如非特殊情況���,請盡量不要跳過這一步����。記?���。耗呐率桥c用戶進(jìn)行很少量的溝通�,也有助于發(fā)現(xiàn)未知的問題�����,這是非常值得的��。
在完成了上面的工作之后����,接下來���,您就可以對候選用戶模型進(jìn)行逐個的審視和修正�。 合并相似的��,補(bǔ)充不完整的��,采用敘述的方式描述每個用戶模型���,并為其選擇適當(dāng)?shù)恼掌?��,這樣就得到了本次迭代的用戶模型(如下圖示例��,圖片來自網(wǎng)絡(luò))��。您可以用這個模型指導(dǎo)界面設(shè)計(jì)��、與團(tuán)隊(duì)溝通……

最后���,根據(jù)您的認(rèn)知變化和產(chǎn)品需要,可以在合適的時機(jī)對之前得到的模型進(jìn)行新一輪的修正�����。 修正的過程和前面相同�����,可能您會在幾次產(chǎn)品迭代中穿插進(jìn)行一輪用戶模型的迭代��,時間越久�����,用戶模型就越接近真實(shí)的用戶情況����。
小結(jié)
本文提供了一種借助行為數(shù)據(jù)和工具快速���、迭代的構(gòu)建用戶模型(Persona)的方法,這套方法與傳統(tǒng)的用戶模型構(gòu)建方法相比損失了一定的質(zhì)量但效率更高����,更適合今天的互聯(lián)網(wǎng)團(tuán)隊(duì)的工作方式和節(jié)奏。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材���,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫�,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量���,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330