處理多重共線性問題
一���、多重共線性的表現(xiàn)
線性回歸模型中的解釋變量之間由于存在精確相關關系或高度相關關系��?�?此葡嗷オ毩⒌闹笜吮举|上是相同的��,是可以相互代替的�����,但是完全共線性的情況并不多見�,一般出現(xiàn)的是在一定程度上的共線性,即近似共線性�����。
二��、多重共線性的后果
1.理論后果
多重共線性是因為變量之間的相關程度比較高�。
按布蘭查德認為, 在計量經(jīng)濟學中, 多重共線性實質上是一個“微數(shù)缺測性”問題,就是說多重共線性其實是由樣本容量太小所造成�,當樣本容量越小,多重共線性越嚴重��。
多重共線性的理論主要后果:
(1)完全共線性下參數(shù)估計量不存在��;
(2)近似共線性下OLS估計量非有效��;
(3)模型的預測功能失效����;
(4)參數(shù)估計量經(jīng)濟含義不合理
2.現(xiàn)實后果
(1)各個解釋變量對指標最后結論影響很難精確鑒別;
(2)置信區(qū)間比原本寬�����,使得接受假設的概率更大����;
(3)統(tǒng)計量不顯著����;
(4)擬合優(yōu)度的平方會很大�����;
(5)OLS估計量及其標準誤對數(shù)據(jù)微小的變化也會很敏感����。
三�����、多重共線性產(chǎn)生的原因
1.模型參數(shù)的選用不當�����,在我們建立模型時如果變量之間存在著高度的相關性
2. 由于研究的經(jīng)濟變量隨時間往往有共同的變化趨勢,他們之間存在著共性���。例如當經(jīng)濟繁榮時�����,反映經(jīng)濟情況的指標有可能按著某種比例關系增長
3. 滯后變量�����。滯后變量的引入也會產(chǎn)生多重共線行����,例如本期的消費水平除受本期的收入影響之外,還有可能受前期的收入影響�����,建立模型時���,本期的收入水平就有可能和前期的收入水平存在著共線性����。
四�、多重共線性的識別
1.方差擴大因子法( VIF)
一般認為如果最大的VIF超過10,常常表示存在多重共線性����。
2.容差容忍定法
如果容差(tolerance)<=0.1,常常表示存在多重共線性���。
3. 條件索引
條件索引(condition index)>10�,可以說明存在比較嚴重的共線性。
五���、多重共線性的處理方法
處理方法有多重增加樣本容量���、剔除因子法、PLS(偏最小二乘法)����、嶺回歸法��、主成分法���。
今天著重介紹——主成分法�。
當自變量間有較強的線性相關性時�����,利用個p個變量的主成分��,所具有的性質��,如果他們是互不相關的,可由前m個主成z1���、z2��、zm來建立回歸模型�。
由原始變量的觀測數(shù)據(jù)計算前個主成分的得分值�,將其作為主成分的觀測值,建立Y與主成分的回歸模型即得回歸方程�����。這時p元降為m元,這樣既簡化了回歸方程的結構�����,且消除了變量間相關性帶來的影響
六�����、實際的應用
我們以下這個模型分析主營業(yè)務利潤的影響
Opinci,t=a0+a1*Intani,t+a2*Ppei,t+a3*Opinci,t-1+a4*Levi,t+a5*Asseti,t +ξi,t
1��、回歸分析
2�����、結果
對自變量主成分法從多重共線性的識別方法來看,此模型中存在共線性問題��,Ppei,t是影響因子���。
3����、對自變量主成分法
由于spss沒有獨立的主成分分析模塊�,需要在因子分析里完成,因此需要特別注意��。
在數(shù)據(jù)窗口下選擇“分析”—“降維”—“因子分析����。
3.1 結果
從KMO 和 Bartlett 的檢驗得知p<0.001����,KMO檢驗通過,適合做主成分或因子分析�����,從解釋的總方差表里初始特征值兩個主成分(初始因子)貢獻率已達86.89%�����,提取前兩個主成分用于分析。
由成分矩陣和表解釋的總方差可計算前兩個特征向量����,用成分矩陣前兩列分別除以前兩個特征值的平方根得前兩個主成分表達式:
F1=0.4726Opinci,t-1+0.4854 Instani,t +0.5371Ppei,t+ 0.0534Levi,t+ 0.4995Asseti,t(式1)
F2=-0.1219Opinci,t-1-0.0510Instani,t -0.0497 Ppei,t+ 0.9837Levi,t+0.1131 Asseti,t(式2)
其中Opinci,t-1、 Instani,t �����、Ppei,t����、 Levi,t、 Asseti,t表示為標準化變量(這是因為在進行主成分分析時是以標準化變量進行分析的���,是從相關陣出發(fā)分析的)
由于主成分互不相關��,可以用提取的主成分代替自變量進行回歸分析��,因此需要計算主成分得分來代替自變量Opinci,t-1���、 Instani,t 、Ppei,t����、 Levi,t���、 Asseti,t。
主成分的計算:依據(jù)式1和2中兩個主成分的表達式�,對各自變量標準化后帶入就可以計算出每個樣品的主成分得分。
但是在spss中���,由因子分析提取時是用主成分法提取的�����,根據(jù)初始因子與主成分的關系�����,未旋轉的初始因子等于主成分除以特征根的平方根����,因此主成分得分等于因子得分乘以特征根的平方根��,可以由因子得分計算主成分得分����。
前面在因子分析選項中保存了因子得分(因子得分保存變量)���,因此計算兩個主成分得分:點擊“轉換”—“計算變量”�����。
在彈出的窗口分別定義主成分
F1=第一因子得分*第一特征根的平方根
F2=第二因子得分*第二特征根的平方根
(3)主成分回歸過程
要做主成分回歸����,需要用標準化的因變量(因為自變量經(jīng)過標準化處理做主成分分析��,因變量需要對應做標準化)與主成分做回歸�,對因變量Opinci,t做標準化處理。
點擊“分析”-“描述統(tǒng)計”-“描述”�����,在彈出窗口中將Opinci,t調入變量����,并選中“將標準化得分另存為變量”后確定完成Opinci,t的標準化�����。

點擊“分析”-“回歸”-“線性”在彈出窗口中將Z主營業(yè)務利潤(y)調入因變量�����,F(xiàn)1和F2調入自變量����,其他選項如前,然后點擊“確定”運行主成分回歸���。

相關輸出結果:
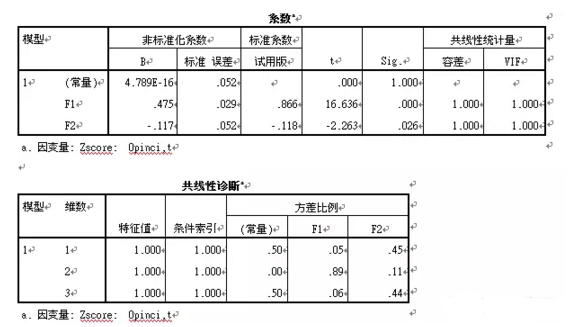
由表可知����,標準化Opinci,t對兩個主成分的線性回歸p<0.001,通過顯著性檢驗�,沒有多重共線性���,回歸系數(shù)合理��。
Zscore:(Opinci,t) =0.475F1-0.117F2�,將前面F1����、F2的表達式(式1和2)帶入可得標準化Opinci,t關于標準化自變量的回歸方程:
Zscore:(Opinci,t)=
0.2388Opinci,t-1+0.2365Instani,t +0.2609Ppei,t-0.0897Levi,t+ 0.2240Asseti,t
求得最終回歸結果�����。
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試,點擊>>>
“CDA報名”
了解CDA考試詳情;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330