R語(yǔ)言數(shù)據(jù)挖掘實(shí)戰(zhàn)案例:電商評(píng)論情感分析
隨著網(wǎng)上購(gòu)物的流行,各大電商競(jìng)爭(zhēng)激烈,為了提高客戶服務(wù)質(zhì)量,除了打價(jià)格戰(zhàn)外,了解客戶的需求點(diǎn),傾聽客戶的心聲也越來(lái)越重要,其中重要的方式 就是對(duì)消費(fèi)者的文本評(píng)論進(jìn)行數(shù)據(jù)挖掘.今天通過(guò)學(xué)習(xí)《R語(yǔ)言數(shù)據(jù)挖掘實(shí)戰(zhàn)》之案例:電商評(píng)論與數(shù)據(jù)分析���,從目標(biāo)到操作內(nèi)容分享給大家。
本文的結(jié)構(gòu)如下

1.要達(dá)到的目標(biāo)
通過(guò)對(duì)客戶的評(píng)論,進(jìn)行一系列的方法進(jìn)行分析,得出客戶對(duì)于某個(gè)商品的各方面的態(tài)度和情感傾向,以及客戶注重商品的哪些屬性,商品的優(yōu)點(diǎn)和缺點(diǎn)分別是什么,商品的賣點(diǎn)是什么,等等..
2.文本挖掘主要的思想.
由于語(yǔ)言數(shù)據(jù)的特殊性,我們主要是將一篇句子中的關(guān)鍵詞提取出來(lái),從而將一個(gè)評(píng)論的關(guān)鍵詞也提取出來(lái),然后根據(jù)關(guān)鍵詞所占的權(quán)重,這里我們用空間向量的模型,將每個(gè)特征關(guān)鍵詞轉(zhuǎn)化為數(shù)字向量,然后計(jì)算其距離,然后聚類,得到情感的三類,分別是正面的,負(fù)面的,中性的.用以代表客戶對(duì)商品的情感傾向.
3.文本挖掘的主要流程:
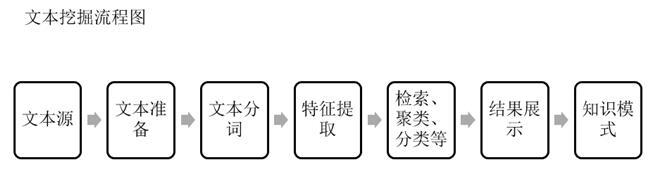
4.案例流程簡(jiǎn)介與原理介紹及軟件操作
4.1數(shù)據(jù)的爬取
首先下載八爪魚軟件,鏈接是http://www.bazhuayu.com/download,下載安裝后,注冊(cè)賬號(hào)登錄, 界面如上:
點(diǎn)擊快速開始—新建任務(wù),輸入任務(wù)名點(diǎn)擊下一步,打開京東美的熱水器頁(yè)面
復(fù)制制頁(yè)面的地址到八爪魚中去如下圖: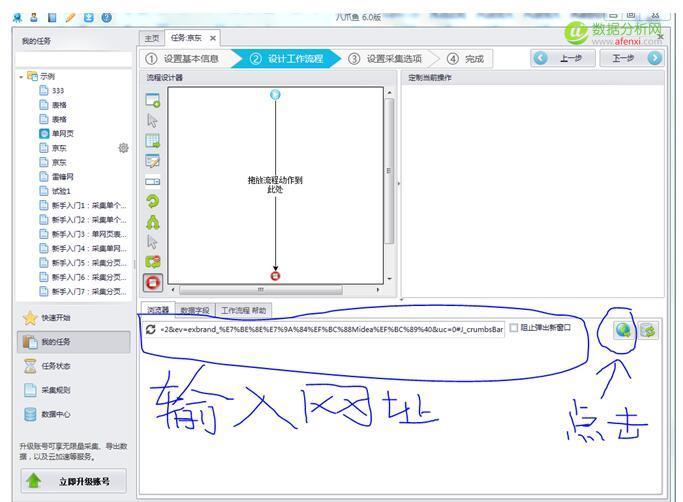
觀察網(wǎng)頁(yè)的類型,由于包含美的熱水器的頁(yè)面不止一頁(yè),下面有翻頁(yè)按鈕,因此我們需要建立一個(gè)循環(huán)點(diǎn)擊下一頁(yè), 然后在八爪魚中的京東頁(yè)面上點(diǎn)擊下一頁(yè),在彈出的對(duì)話列表中點(diǎn)擊循環(huán)點(diǎn)擊下一頁(yè),如圖: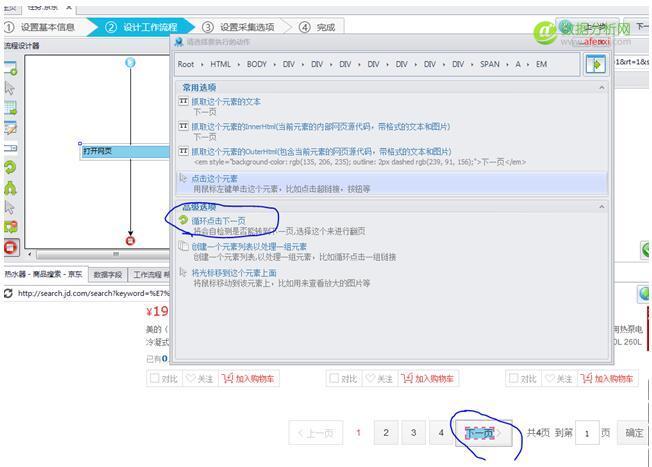
然后點(diǎn)擊一個(gè)商品,在彈出的頁(yè)面中點(diǎn)擊添加一個(gè)元素列表以處理一祖元素–再點(diǎn)擊添加到列表—繼續(xù)編輯列表,接下來(lái)我們點(diǎn)擊另一商品的名字,在彈出的頁(yè)面上點(diǎn)擊添加到列表,這樣軟件便自動(dòng)識(shí)別了頁(yè)面中的其他商品,再點(diǎn)擊創(chuàng)建列表完成,再點(diǎn)擊循環(huán),這樣就創(chuàng)建了一個(gè)循環(huán)抓取頁(yè)面中商品的列表,
然后軟件自動(dòng)跳轉(zhuǎn)到第一個(gè)商品的具體頁(yè)面,我們點(diǎn)擊評(píng)論,在彈出頁(yè)面中點(diǎn)擊 點(diǎn)擊這個(gè)元素,看到評(píng)論也有很多頁(yè),這時(shí)我們又需要?jiǎng)?chuàng)建一個(gè)循環(huán)列表,同上,點(diǎn)擊下一頁(yè)—循環(huán)點(diǎn)擊.然后點(diǎn)擊我們需要抓取的評(píng)論文本,在彈出頁(yè)面中點(diǎn)擊創(chuàng)建一個(gè)元素列表以處理一組元素—-點(diǎn)擊添加到列表—繼續(xù)編輯列表,然后點(diǎn)擊第2個(gè)評(píng)論在彈出頁(yè)面中點(diǎn)擊添加到列表—循環(huán),再點(diǎn)擊評(píng)論的文本選擇抓取這個(gè)元素的文本.好了,此時(shí)軟件會(huì)循環(huán)抓取本頁(yè)面的文本,如圖:

都點(diǎn)擊完成成后,我們?cè)倏丛O(shè)計(jì)器發(fā)現(xiàn)有4個(gè)循環(huán),第一個(gè)是翻頁(yè),第二個(gè)是循環(huán)點(diǎn)擊每一個(gè)商品,第三個(gè)是評(píng)論頁(yè)翻頁(yè),第4個(gè)是循環(huán)抓取評(píng)論文本,這樣我們需要把第4個(gè)循環(huán)內(nèi)嵌在第3個(gè)循環(huán)里面去,然后再整體內(nèi)嵌到第2個(gè)循環(huán)里面去,再整體內(nèi)嵌到第1個(gè)循環(huán)里面去,這樣的意思就是,先點(diǎn)下一頁(yè),再點(diǎn)商品,再點(diǎn)下一特,再抓取評(píng)論,這套動(dòng)作循環(huán).那么我們?cè)谠O(shè)計(jì)器中只需拖動(dòng)第4個(gè)循環(huán)到第3個(gè)循環(huán)再這樣拖動(dòng)下去.即可: 拖動(dòng)結(jié)果如下:,再點(diǎn)下一步—下一步–單擊采集就OK 了.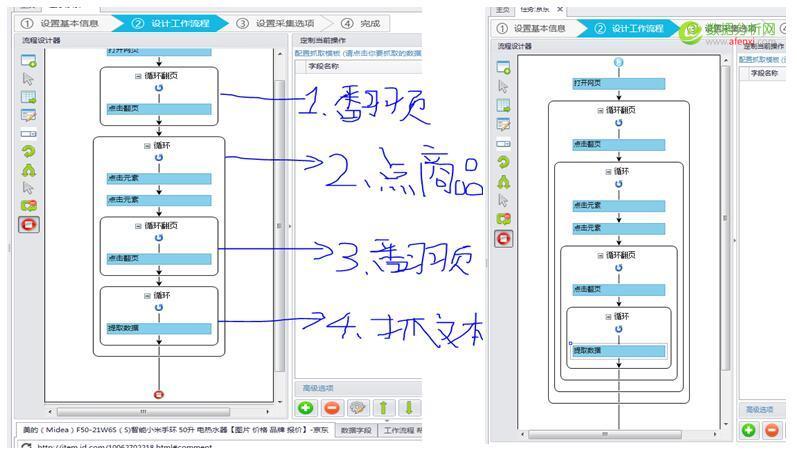 4.2文本去重
4.2文本去重
本例使用了京東平臺(tái)下對(duì)于美的熱水器的客戶評(píng)論作為分析對(duì)象,按照流程,首先我們使用八爪魚在京東網(wǎng)站上爬取了客戶對(duì)于美的熱水器的評(píng)論,部分?jǐn)?shù)據(jù)如下!

進(jìn)行簡(jiǎn)單的觀察,我們可以發(fā)現(xiàn)評(píng)論的一些特點(diǎn),
文本短,基本上大量的評(píng)論就是一句話.
情感傾向明顯:明顯的詞匯 如”好” “可以”
語(yǔ)言不規(guī)范:會(huì)出現(xiàn)一些網(wǎng)絡(luò)用詞,符號(hào),數(shù)字等
重復(fù)性大:一句話出現(xiàn)詞語(yǔ)重復(fù)
數(shù)據(jù)量大.
故我們需要對(duì)這些數(shù)據(jù)進(jìn)行數(shù)據(jù)預(yù)處理,先進(jìn)行數(shù)據(jù)清洗,
編輯距離去重其實(shí)就是一種字符串之間相似度計(jì)算的方法���。給定兩個(gè)字符串��,將字符串A轉(zhuǎn)化為字符串B所需要的刪除�、插入����、替換等操作步驟的數(shù)量就叫做從A到B的編輯路徑。而最短的編輯路徑就叫字符串A��、B的編輯距離����。比如,“還沒(méi)正式使用����,不知道怎樣���,但安裝的材料費(fèi)確實(shí)有點(diǎn)高,380”與“還沒(méi)使用��,不知道質(zhì)量如何�����,但安裝的材料費(fèi)確實(shí)貴���,380”的編輯距離就是9.
首先,針對(duì)重復(fù)的評(píng)論我們要去重,即刪掉重復(fù)的評(píng)論.
另外一句話中出現(xiàn)的重復(fù)詞匯,這會(huì)影響一個(gè)評(píng)論中關(guān)鍵詞在整體中出現(xiàn)的頻率太高而影響分析結(jié)果.我們要將其壓縮.
還有一些無(wú)意義的評(píng)論,像是自動(dòng)好評(píng)的,我們要識(shí)別并刪去.
4.3壓縮語(yǔ)句的規(guī)則:
1.若讀入與上列表相同,下為空,則放下
2.若讀入與上列表相同,下有,判斷重復(fù), 清空下表
3.若讀入與上列表相同,下有,判斷不重,清空上下
4.若讀入與上列表不同,字符>=2,判斷重復(fù),清空上下
5.若讀入與上列表不同,下為空,判斷不重,繼續(xù)放上
6.若讀入與上列表不同,下有,判斷不重,放下
7.讀完后,判斷上下,若重則壓縮.
4.4然后我們?cè)龠M(jìn)行中文的分詞,分詞的大致原理是:
中文分詞是指將一段漢字序列切分成獨(dú)立的詞����。分詞結(jié)果的準(zhǔn)確性對(duì)文本挖掘效果至關(guān)重要���。目前分詞算法主要包括四種:字符串匹配算法��、基于理解的算法����、基于統(tǒng)計(jì)的方法和基于機(jī)器學(xué)習(xí)的算法�。
1.字符串匹配算法是將待分的文本串和詞典中的詞進(jìn)行精確匹配,如果詞典中的字符串出現(xiàn)在當(dāng)前的待分的文本中,說(shuō)明匹配成功��。常用的匹配算法主要有正向最大匹配����、逆向最大匹配��、雙向最大匹配和最小切分�。
2.基于理解的算法是通過(guò)模擬現(xiàn)實(shí)中人對(duì)某個(gè)句子的理解的效果進(jìn)行分詞。這種方法需要進(jìn)行句法結(jié)構(gòu)分析���,同時(shí)需要使用大量的語(yǔ)言知識(shí)和信息�����,比較復(fù)雜�����。
3.基于統(tǒng)計(jì)的方法是利用統(tǒng)計(jì)的思想進(jìn)行分詞�����。單詞由單字構(gòu)成����,在文本中,相鄰字共同出現(xiàn)的次數(shù)越多�,他們構(gòu)成詞的概率就越大;因此可以利用字之間的共現(xiàn)概率來(lái)反映詞的幾率,統(tǒng)計(jì)相鄰字的共現(xiàn)次數(shù)��,計(jì)算它們的共現(xiàn)概率�����。當(dāng)共現(xiàn)概率高于設(shè)定的閾值時(shí)�����,可以認(rèn)為它們可能構(gòu)成了詞
4.最后是基于機(jī)器學(xué)習(xí)的方法:利用機(jī)器學(xué)習(xí)進(jìn)行模型構(gòu)建�����。構(gòu)建大量已分詞的文本作為訓(xùn)練數(shù)據(jù)���,利用機(jī)器學(xué)習(xí)算法進(jìn)行模型訓(xùn)練�,利用模型對(duì)未知文本進(jìn)行分詞�����。
4.5得到分詞結(jié)果后,
我們知道,在句子中經(jīng)常會(huì)有一些”了””啊””但是”這些句子的語(yǔ)氣詞,關(guān)聯(lián)詞,介詞等等,這些詞語(yǔ)對(duì)于句子的特征沒(méi)有貢獻(xiàn),我們可以將其去除,另外還有一些專有名詞,針對(duì)此次分析案例,評(píng)論中經(jīng)常會(huì)出現(xiàn)”熱水器”,”中國(guó)”這是我們已知的,因?yàn)槲覀儽緛?lái)就是對(duì)于熱水器的評(píng)論進(jìn)行分析,故這些屬于無(wú)用信息.我們也可以刪除.那么這里就要去除這些詞.一般是通過(guò)建立的自定義詞庫(kù)來(lái)刪除.
4.6 我們處理完分詞結(jié)果后,
便可以進(jìn)行統(tǒng)計(jì),畫出詞頻云圖,來(lái)大致的了解那些關(guān)鍵詞的情況,借此對(duì)于我們下一步的分析,提供思考的材料.操作如下:

4.7 有了分詞結(jié)果后,
我們便開始著手建模分析了,在模型的選擇面前,有很多方法,但總結(jié)下來(lái)就只有兩類,分別向量空間模型和概率模型,這里分別介紹一個(gè)代表模型
模型一: TF-IDF法:

方法A:將每個(gè)詞出現(xiàn)的頻率加權(quán)后,當(dāng)做其所在維度的坐標(biāo),由此確定一特征的空間位置.
方法B:將出現(xiàn)的所有詞包含的屬性作為維度,再將詞與每個(gè)屬性的關(guān)系作為坐標(biāo),然后來(lái)定位一篇文檔在向量空間里的位置.
但是實(shí)際上�,如果一個(gè)詞條在一個(gè)類的文檔中頻繁出現(xiàn),則說(shuō)明該詞條能夠很好代表這個(gè)類的文本的特征�����,這樣的詞條應(yīng)該給它們賦予較高的權(quán)重��,并選來(lái)作為該類文本的特征詞以區(qū)別與其它類文檔���。這就是IDF的不足之處.
模型二:.LDA模型
傳統(tǒng)判斷兩個(gè)文檔相似性的方法是通過(guò)查看兩個(gè)文檔共同出現(xiàn)的單詞的多少,如TF-IDF等��,這種方法沒(méi)有考慮到文字背后的語(yǔ)義關(guān)聯(lián)���,可能在兩個(gè)文檔共同出現(xiàn)的單詞很少甚至沒(méi)有�����,但兩個(gè)文檔是相似的。
舉個(gè)例子�����,有兩個(gè)句子分別如下:
“喬布斯離我們而去了�?���!?/span>
“蘋果價(jià)格會(huì)不會(huì)降?”
可以看到上面這兩個(gè)句子沒(méi)有共同出現(xiàn)的單詞���,但這兩個(gè)句子是相似的,如果按傳統(tǒng)的方法判斷這兩個(gè)句子肯定不相似����,所以在判斷文檔相關(guān)性的時(shí)候需要考慮到文檔的語(yǔ)義,而語(yǔ)義挖掘的利器是主題模型����,LDA就是其中一種比較有效的模型����。
LDA模型是一個(gè)無(wú)監(jiān)督的生成主題模型,其假設(shè):文檔集中的文檔是按照一定的概率共享隱含主題集合�,隱含主題集合則由相關(guān)詞構(gòu)成。這里一共有三個(gè)集合���,分別是文檔集�、主題集和詞集。文檔集到主題集服從概率分布��,詞集到主題集也服從概率分布?����,F(xiàn)在我們已知文檔集和詞集���,根據(jù)貝葉斯定理我們就有可能求出主題集。具體的算法非常復(fù)雜,這里不做多的解釋,有興趣的同學(xué)可以參看如下資料
http://www.52analysis.com/shujuwajue/2609.html
http://blog.csdn.net/huagong_a … 37616
4.8 項(xiàng)目總結(jié)
1.數(shù)據(jù)的復(fù)雜性更高,文本挖掘面對(duì)的非結(jié)構(gòu)性語(yǔ)言,且文本很復(fù)雜.
2.流程不同,文本挖掘更注重預(yù)處理階段
3.總的流程如下:

5.應(yīng)用領(lǐng)域:
1.輿情分析
2.搜索引擎優(yōu)化
3.其他各行各業(yè)的輔助應(yīng)用
6.分析工具:
ROST CM 6是武漢大學(xué)沈陽(yáng)教授研發(fā)編碼的國(guó)內(nèi)目前唯一的以輔助人文社會(huì)科學(xué)研究的大型免費(fèi)社會(huì)計(jì)算平臺(tái)�����。該軟件可以實(shí)現(xiàn)微博分析����、聊天分析、全網(wǎng)分析��、網(wǎng)站分析�����、瀏覽分析、分詞��、詞頻統(tǒng)計(jì)�����、英文詞頻統(tǒng)計(jì)�、流量分析、聚類分析等一系列文本分析,用戶量超過(guò)7000,遍布海內(nèi)外100多所大學(xué),包括劍橋大學(xué)�����、日本北海道大學(xué)��、北京大學(xué)�、清華大學(xué)、香港城市大學(xué)�����、澳門大學(xué)眾多高校���。下載地址: http://www.121down.com/soft/softview-38078.html
RStudio是一種R語(yǔ)言的集成開發(fā)環(huán)境(IDE)���,其亮點(diǎn)是出色的界面設(shè)計(jì)及編程輔助工具��。它可以在多種平臺(tái)上運(yùn)行����,包括windows��,Mac��,Ubuntu���,以及網(wǎng)頁(yè)版�����。另外這個(gè)軟件是免費(fèi)和開源的,可以在官方網(wǎng)頁(yè):www.rstudio.org
上下載���。
7.1 Rostcm6實(shí)現(xiàn):
打開軟件ROSTCM6
這是處理前的文本內(nèi)容,我們將爬取到的數(shù)據(jù),只去除評(píng)論這一字段,然后保存為TXT格式,打開如下,按照流程我們先去除重復(fù)和字符,英文,數(shù)字等項(xiàng).
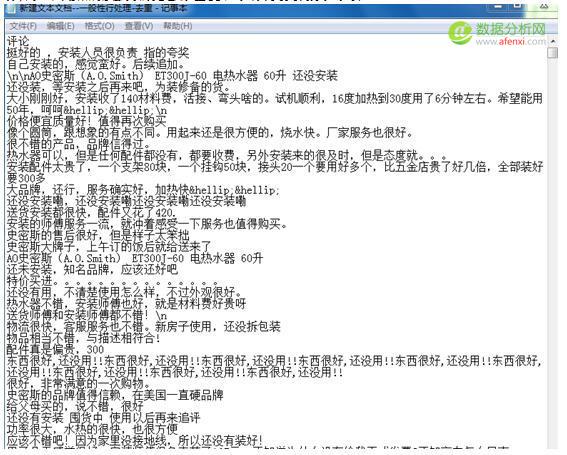
2.點(diǎn) 文本處理–一般性處理—處理?xiàng)l件選 “凡是重復(fù)的行只保留一行”與”把所有行中包含的英文字符全部刪掉” 用來(lái)去掉英文和數(shù)字等字符
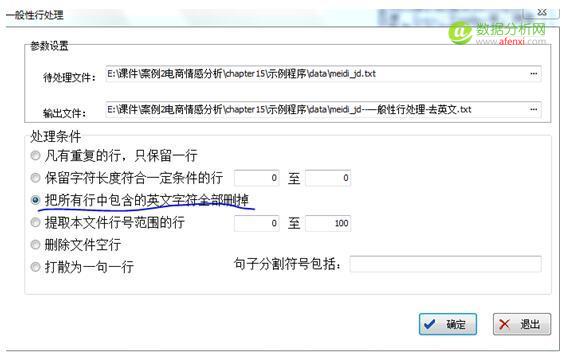
這是處理后的文檔內(nèi)容,可以看到數(shù)字和英文都被刪除了. 3.接下來(lái), 再進(jìn)行分詞處理. 點(diǎn) 功能分析 —-分詞 (這里可以選擇自定義詞庫(kù),比如搜狗詞庫(kù),或者其他)
3.接下來(lái), 再進(jìn)行分詞處理. 點(diǎn) 功能分析 —-分詞 (這里可以選擇自定義詞庫(kù),比如搜狗詞庫(kù),或者其他)
得分詞處理后的結(jié)果.,簡(jiǎn)單觀察一下,分詞后 ,有許多 “在”,”下”,”一”等等無(wú)意義的停用詞
4.接下來(lái),我們進(jìn)行專有名詞,停用詞過(guò)濾. 并統(tǒng)計(jì)詞頻.點(diǎn) 功能分析 —詞頻分析(中文)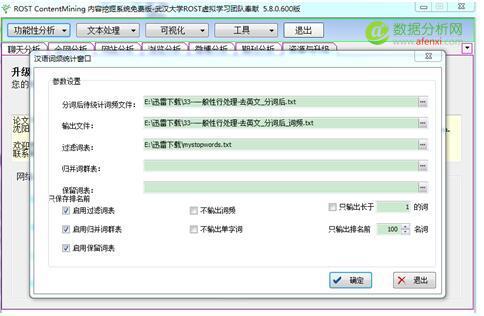
在功能性分析下點(diǎn)情感分析,可以進(jìn)行情感分析,
并可以實(shí)現(xiàn)云圖的可視化.
7.2 R的實(shí)現(xiàn)
這里需要安裝幾個(gè)必須包,因?yàn)橛袔讉€(gè)包安裝比較復(fù)雜,這里給了鏈接http://blog.csdn.net/cl1143015 … 82731
大家可以參看這個(gè)博客安裝包.安裝完成后就可以開始R文本挖掘了
加載工作空間
library(rJava)
library(tmcn)
library(Rwordseg)
library(tm)
setwd(“F:/數(shù)據(jù)及程序/chapter15/上機(jī)實(shí)驗(yàn)”)
data1=readLines(“./data/meidi_jd_pos.txt”,encoding = “UTF-8″)
head(data1)
data<-data1[1:100]
—————————————————————#Rwordseg分詞
data1_cut=segmentCN(data1,nosymbol=T,returnType=”tm”)
刪除\n,英文字母�,數(shù)字
data1_cut=gsub(“\n”,””,data1_cut)
data1_cut=gsub(“[a-z]*”,””,data1_cut)
data1_cut=gsub(“\d+”,””,data1_cut)
write.table(data1_cut,’data1_cut.txt’,row.names = FALSE)
Data1=readLines(‘data1_cut.txt’)
Data1=gsub(‘\”‘,”,data1_cut)
length(Data1)
head(Data1)
———————————————————————– #加載工作空間
library(NLP)
library(tm)
library(slam)
library(topicmodels)
R語(yǔ)言環(huán)境下的文本可視化及主題分析
setwd(“F:/數(shù)據(jù)及程序/chapter15/上機(jī)實(shí)驗(yàn)”)
data1=readLines(“./data/meidi_jd_pos_cut.txt”,encoding = “UTF-8”)
head(data1)
stopwords<- unlist (readLines(“./data/stoplist.txt”,encoding = “UTF-8”))
stopwords = stopwords[611:length(stopwords)]
刪除空格��、字母
Data1=gsub(“\n”,””,Data1)
Data1=gsub(“[a~z]*”,””,Data1)
Data1=gsub(“\d+”,””,Data1)
構(gòu)建語(yǔ)料庫(kù)
corpus1 = Corpus(VectorSource(Data1))
corpus1 = tm_map(corpus1,FUN=removeWords,stopwordsCN(stopwords))
建立文檔-詞條矩陣
sample.dtm1 <- DocumentTermMatrix(corpus1, control = list(wordLengths = c(2, Inf)))
colnames(as.matrix(sample.dtm1))
tm::findFreqTerms(sample.dtm1,2)
unlist(tm::findAssocs(sample.dtm1,’安裝’,0.2))
—————————————————————–
#主題模型分析
Gibbs = LDA(sample.dtm1, k = 3, method = “Gibbs”,control = list(seed = 2015, burnin = 1000,thin = 100, iter = 1000))
最可能的主題文檔
Topic1 <- topics(Gibbs, 1)
table(Topic1)
每個(gè)Topic前10個(gè)Term
Terms1 <- terms(Gibbs, 10)
Terms1
——————————————————————- #用vec方法分詞
library(tmcn)
library(tm)
library(Rwordseg)
library(wordcloud)
setwd(“F:/數(shù)據(jù)及程序/chapter15/上機(jī)實(shí)驗(yàn)”)
data1=readLines(“./data/meidi_jd_pos.txt”,encoding = “UTF-8”)
d.vec1 <- segmentCN(data1,returnType = “vec”)
wc1=getWordFreq(unlist(d.vec1),onlyCN = TRUE)
wordcloud(wc1$Word,wc1$Freq,col=rainbow(length(wc1$Freq)),min.freq = 1000)
#
8.結(jié)果展示與說(shuō)明
這是分析的部分結(jié)果.可以看到大部分客戶的評(píng)論包含積極情緒,說(shuō)明了客戶對(duì)于美的熱水器認(rèn)可度比較高滿意度也可以,當(dāng)然,我們僅憑情感分析的結(jié)果是無(wú)法看出,客戶到底對(duì)于哪些方面滿意,哪些方面不滿意,我們有什么可以保持的地方,又有哪些需要改進(jìn)的地方,這就需要我們的另一項(xiàng)結(jié)果展示.
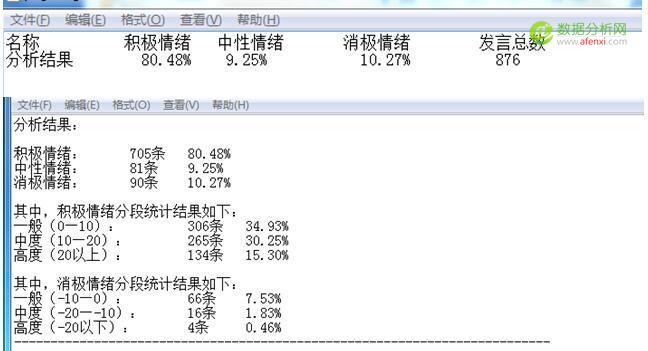

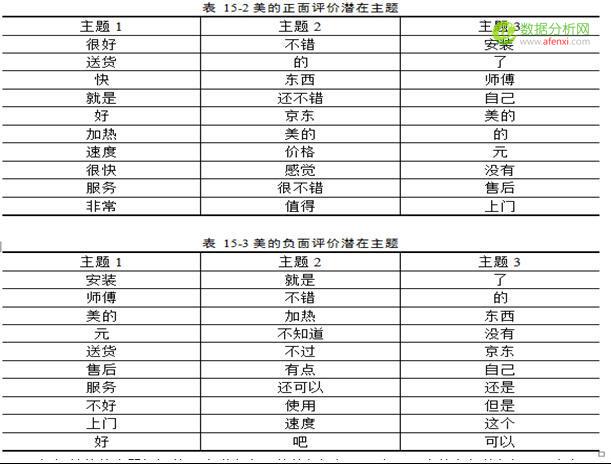
點(diǎn)可視化工具,便可得到詞頻云圖.根據(jù)云圖,我們可以看到客戶最最關(guān)心的幾個(gè)點(diǎn),也就是評(píng)論中,說(shuō)得比較多的幾個(gè)點(diǎn),由圖我們可以看到”安裝”,”師傅””配件””加熱””快””便宜””速度””品牌””京東””送貨”“服務(wù)””價(jià)格””加熱”等等關(guān)鍵詞出現(xiàn)頻率較高,我們大致可以猜測(cè)的是26
安裝方面的問(wèn)題
熱水器價(jià)格方面比較便宜
熱水器功能方面 加熱快,
京東的服務(wù)和送貨比較快.
另外值得我們注意的是,云圖里面,也有些”好”,”大”,”滿意”等等出現(xiàn)比較多的詞,我們尚且不知道這些詞背后的語(yǔ)義,這就需要我們?nèi)フ业较鄳?yīng)的評(píng)論,提取出這些詞相應(yīng)的主題點(diǎn).再加以優(yōu)化分析的結(jié)果
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情��;
? 想學(xué)習(xí)CDA考試教材��,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫(kù),點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情�����;
? 想了解CDA考試含金量���,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330