基于樹的建模-完整教程(R & Python)
基于樹的學習算法被認為是最好的方法之一�����,主要用于監(jiān)測學習方法?����;跇涞姆椒ㄖС志哂懈呔?、高穩(wěn)定性和易用性解釋的預測模型。不同于線性模型��,它們映射非線性關系相當不錯��。他們善于解決手頭的任何問題(分類或回歸)���。
決策樹方法,隨機森林,梯度增加被廣泛用于各種數(shù)據(jù)科學問題����。因此,對于每一個分析師(新鮮),重要的是要學習這些算法和用于建模。
決策樹����、隨機森林、梯度增加等方法被廣泛用于各種數(shù)據(jù)科學問題���。因此,對于每一個分析師(包括新人)����,學習這些算法并用于建模是非常重要的��。
本教程是旨在幫助初學者從頭學習基于樹的建模�。在成功完成本教程之后,有望初學者成為一個精通使用基于樹的算法并能夠建立預測模型的人。
注意:本教程不需要先驗知識的機器學習��。然而,了解R或Python的基礎知識將是有益的�。開始你可以遵循Python 和R的完整教程。
1.決策樹是什么?它是如何工作的呢?
決策樹是一種監(jiān)督學習算法(有一個預定義的目標變量),主要是用于分類問題�。它適用于分類和連續(xù)的輸入和輸出變量。在這種方法中, 基于在輸入變量中最重要的分配器/微分器的區(qū)別�,我們把人口或樣本分成兩個或兩個以上的均勻集(或群體)。
例子:-
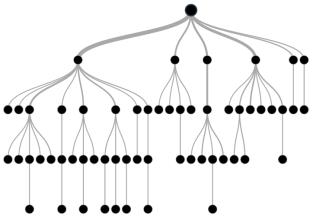
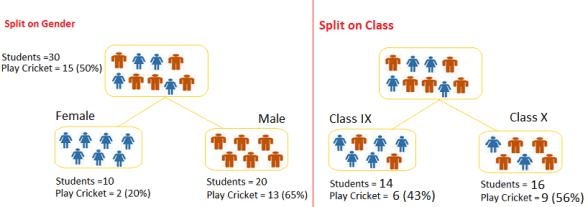
假設我們有30名學生作為樣本��,包含三個變量:性別(男孩/女孩),班級(IX/ X)和身高 (5到6英尺)。這30名學生中超過15人在閑暇時間打板球?��,F(xiàn)在,我想創(chuàng)建一個模型來預測誰會在休閑期間打板球�����。在這個問題上,我們需要根據(jù)非常重要的三個輸入變量來隔離在閑暇時間打板球的學生�����。
這就是決策樹的幫助,它根據(jù)三變量的所有值和確定變量隔離學生,創(chuàng)造最好的同質組學生(這是異構的)。在下面的圖片中,您可以看到相比其他兩個變量性別變量是最好的能夠識別的均勻集�。
正如上面提到的,決策樹識別最重要的變量,它最大的價值就是提供人口的均勻集?���,F(xiàn)在出現(xiàn)的問題是,它是如何識別變量和分裂的?要做到這一點,決策樹使用不同的算法,我們將在下一節(jié)中討論。
決策樹的類型
決策樹的類型是基于目標變量的類型��。它可以有兩種類型:
1.分類變量決策樹: 有分類目標變量的決策樹就稱為分類變量決策樹����。例子:在上述情況下的學生問題,目標變量是“學生會打板球”,即“是”或“否”�����。
2.連續(xù)變量決策樹: 有連續(xù)目標變量的決策樹就稱為連續(xù)變量決策樹。
例子:假設我們有一個問題�����,預測客戶是否會支付他與保險公司續(xù)保保險費(是 / 否)��。在這里我們知道客戶的收入是一個重要的變量,但保險公司沒有所有客戶收入的詳細信息?,F(xiàn)在,我們知道這是一個重要的變量,我們就可以建立一個決策樹來根據(jù)職業(yè)、產(chǎn)品和其他變量預測客戶收入�����。在這種情況下,我們的預計值為連續(xù)變量���。
決策樹相關的重要術語
讓我們看看使用決策樹的基本術語:
1.根節(jié)點:它代表總體或樣本,這進一步被分成兩個或兩個以上的均勻集�����。
2.分裂:它是將一個節(jié)點劃分成兩個或兩個以上的子節(jié)點的過程���。
3.決策節(jié)點:當子節(jié)點進一步分裂成子節(jié)點,那么它被稱為決策節(jié)點。
4.葉/終端節(jié)點:節(jié)點不分裂稱為葉或終端節(jié)點。
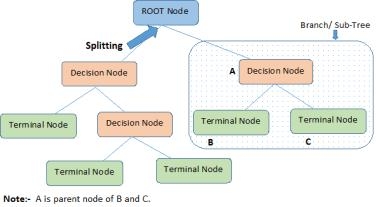
5.修剪:當我們刪除一個決定節(jié)點的子節(jié)點,這個過程稱為修剪�����。也可以說相反分裂的過程����。
6.分支/子樹:整個樹的子部分稱為分行或子樹。
7.父節(jié)點和子節(jié)點:被分為子節(jié)點的節(jié)點稱為父節(jié)點�����,就像子節(jié)點是父節(jié)點的孩子���。
這些是常用的決策樹��。正如我們所知,每個算法都有優(yōu)點和缺點,下面是一個人應該知道的重要因素。
優(yōu)勢
1.容易理解:決策樹輸出是很容易理解的,即便是在那些從屬于以非思辯背景的人�。它不需要任何統(tǒng)計知識來閱讀和解釋它們。它的圖形表示非常直觀���,用戶可以很容易地理解他們的假說����。
2.有用的數(shù)據(jù)探索:決策樹是用一種最快的方式來識別最重要的變量和兩個或兩個以上變量之間的關系���。在決策樹的幫助下,我們可以創(chuàng)建新變量或有更好的能力來預測目標變量的功能���。您可以參考文章(技巧提高的力量回歸模型)這樣一個方法��。它也可以用于數(shù)據(jù)探索階段�����。例如,我們正在研究一個問題,在數(shù)以百計的變量信息中,決策樹將有助于識別最重要的變量�。
3.較少的數(shù)據(jù)清洗要求: 相比其他建模技術它需要較少的數(shù)據(jù)清洗���。它的公平程度不受異常值和缺失值的影響����。
4.數(shù)據(jù)類型不是一個約束:它可以處理數(shù)值和分類變量�。
5.非參數(shù)方法:決策樹被認為是一種非參數(shù)方法。這意味著決策樹沒有假設空間分布和分類器結構��。
缺點
1.過擬合: 過擬合是決策樹模型最現(xiàn)實的困難��。這個問題只能通過設置約束模型參數(shù)和修剪來解決 (在下面詳細討論)�。
2.不適合連續(xù)變量:在處理連續(xù)數(shù)值變量時,決策樹在對不同類別變量進行分類時失去信息。
2.回歸樹vs分類樹
我們都知道,終端節(jié)點(或樹葉)位于決策樹的底部。這意味著我們通常會顛倒繪制決策樹,即葉子在底部根在頂部(如下所示)����。

這些模型的功能幾乎相似,讓我們看看回歸樹和分類樹主要的差異和相似點:
①用于回歸樹的因變量是連續(xù)的,而用于分類樹的因變量是無條件的��。
②在回歸樹中,訓練數(shù)據(jù)中的終端節(jié)點的價值獲取是觀測值落在該區(qū)域的平均響應�����。因此,如果一個看不見的數(shù)據(jù)觀察落在那個區(qū)域,我們將它估算為平均值���。
③在分類樹中, 訓練數(shù)據(jù)中終端節(jié)點獲得的價值是觀測值落在該區(qū)域的模式����。因此,如果一個看不見的數(shù)據(jù)落在該地區(qū),我們會使用眾數(shù)值作為其預測值����。
④這兩個樹將預測空間(獨立變量)劃分為明顯的非重疊區(qū)域。為了簡單起見,你可以認為這些區(qū)域是高維盒子或箱子�����。
⑤這兩種樹模型都遵循的自上而下的貪婪的方法稱為遞歸二分分裂�����。我們之所以叫它為“自上而下”,是因為當所有的觀察值都在單個區(qū)域時它先從樹的頂端開始,然后向下將預測空間分為兩個分支�。它被稱為“貪婪”,是因為該算法(尋找最佳變量可用)關心的只有目前的分裂,而不是構建一個更好的樹的未來的分裂。
⑥這個分裂的過程一直持續(xù)到達到一個用戶定義的停止標準�����。例如:我們可以告訴該算法一旦觀察每個節(jié)點的數(shù)量少于50就停止����。
⑦在這兩種情況下,分裂過程達到停止標準后就會構建出一個成年樹。但是,成年樹可能會過度適應數(shù)據(jù),導致對未知數(shù)據(jù)的低準確性����。這就帶來了“修剪”。修剪是一個解決過度擬合的技術��。我們會在以下部分了解更多關于它的內(nèi)容�����。
3.樹模型是如何決定在哪分裂的?
制造戰(zhàn)略性的分裂決定將嚴重影響樹的準確性�。分類樹和回歸樹的決策標準是不同的。
決策樹算法使用多個算法決策將一個節(jié)點分裂成兩個或兩個以上的子節(jié)點�。子節(jié)點的創(chuàng)建增加了合成子節(jié)點的同質性�����。換句話說,我們可以說節(jié)點的純度隨著對目標變量得尊重而增加����。決策樹在所有可用的變量上分裂節(jié)點,然后選擇產(chǎn)生最均勻的子節(jié)點的分裂��。
算法的選擇也要基于目標變量的類型����。讓我們來看看這四個最常用的決策樹算法:
基尼系數(shù)
基尼系數(shù)表示,如果總量是純粹的,我們從總量中隨機選擇兩項����,那么這兩項必須是同一級別的,而且概率為1。
①它影響著無條件的分類目標變量的“成功”或“失敗”�。
②它只執(zhí)行二進制分裂。
③基尼值越高同質性越高�����。
④CART (分類樹和回歸樹)使用基尼系數(shù)方法創(chuàng)建二進制分裂�。
通過計算尼基系數(shù)來產(chǎn)生分裂的步驟:
①計算子節(jié)點的尼基系數(shù),使用公式計算成功和失敗的概率的平方和 (p ^ 2 + ^ 2)。
②使用加權尼基系數(shù)計算每個節(jié)點的分裂�����。
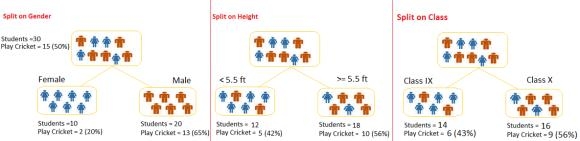
例子:參照上面使用的例子,我們要基于目標變量(或不玩板球)隔離學生�����。在下面的快照中,我們使用了性別和班級兩個輸入變量?,F(xiàn)在,我想使用基尼系數(shù)確定哪些分裂產(chǎn)生了更均勻的子節(jié)點。
性別節(jié)點:
①計算,女性子節(jié)點的基尼=(0.2)*(0.2)+(0.8)*(0.8)= 0.68
②男性子節(jié)點的基尼=(0.65)*(0.65)+(0.35)*(0.35)= 0.55
③為性別節(jié)點計算加權基尼=(10/30)* 0.68 +(20/30)* 0.55 = 0.59
班級節(jié)點的相似性:
①IX子節(jié)點的基尼=(0.43)*(0.43)+(0.57)*(0.57)= 0.51
②X子節(jié)點的基尼=(0.56)*(0.56)+(0.44)*(0.44)= 0.51
③計算班級節(jié)點的加權基尼=(14/30)* 0.51 +(16/30)* 0.51 = 0.51
以上,你可以看到基尼得分在性別上高于班級,因此,節(jié)點分裂將取于性別��。
l卡方
這是一個用來找出子節(jié)點和父節(jié)點之間差異的統(tǒng)計學意義的算法��。我們測量它的方法是�,計算觀察和期望頻率與目標變量之間標準差的平方和。
①它影響到無條件分類目標變量的“成功”或“失敗”���。
②它可以執(zhí)行兩個或更多的分裂�����。
③卡方值越高���,子節(jié)點和父節(jié)點之間差異的統(tǒng)計學顯著性越明顯。
④每個節(jié)點的卡方檢驗都是使用公式計算�。
⑤卡方=((實際-預期)^ 2 /預期)^ 1/2
⑥它生成樹稱為CHAID(卡方自動交互檢測器)
卡方計算節(jié)點分裂的步驟:
①通過計算成功與失敗的偏差為單個節(jié)點計算卡方����。
②通過計算每個節(jié)點成功和失敗的卡方和來計算卡方分割點����。
例子:讓我們使用上面用來計算基尼系數(shù)的例子。
性別節(jié)點:
①首先我們填充女性節(jié)點,填充的實際內(nèi)容為“打板球”和“不打板球”,這些分別為2和8����。
②計算期望值“打板球”和“不打板球”,這對雙方而言都是5,因為父節(jié)點有相同的50%的概率,我們應用相同的概率在女性計數(shù)上(10)�。
③通過使用公式計算偏差,實際—預期。實際上就是“打板球”(2 – 5 = -3),“不打板球”(8 – 5 = 3)��。
④計算卡方節(jié)點的“打板球”和“不打板球”的公式=((實際-預期)^ 2 /預期)^ 1/2�����。您可以參考下表計算����。
⑤遵循同樣的步驟計算男性節(jié)點卡方值。
⑥現(xiàn)在添加所有卡方值來計算卡方性別分裂點�。

班級節(jié)點:
執(zhí)行以上類似的步驟來計算班級分裂點,你就會得出下面的表。

以上,你也可以看到,卡方識別性別分裂比班級更重要����。
l信息增益
看看下面的圖片,你認為哪個節(jié)點容易描述�。我相信你的答案是C,因為它需要更少的信息,所有的值是相似的�����。另一方面,B需要更多的信息來描述它,A需要最大的信息�。換句話說,我們可以說,C是一個純粹的節(jié)點,B是較不純粹的��,而A是最不純粹的�。
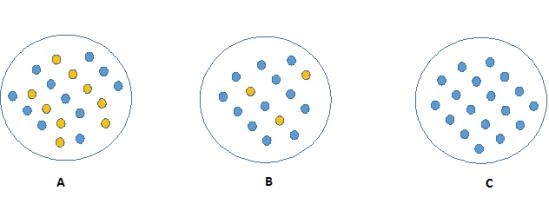
現(xiàn)在,我們可以提出一個結論:較不純粹的節(jié)點需要更少的信息來描述它,而純粹度越高需要的信息越多�����。定義這一個系統(tǒng)的無序程度的信息理論稱為熵���。如果樣品完全均勻,那么熵為0,如果樣品是同等劃分(50% – 50%),那么它的熵為1 ���。
熵可以使用公式計算:
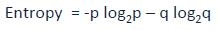
這里的p和q分別為成功和失敗的概率節(jié)點。熵也用于分類目標變量���。選擇相比父節(jié)點和其他節(jié)點分裂最低的熵����。熵越小越好。
計算熵分割的步驟:
①計算父節(jié)點的熵����。
②計算每個獨立節(jié)點分割的熵,并計算分裂中所有子節(jié)點得加權平均值�。
例子:我們用這種方法來為學生例子確定最佳分割點。
①父節(jié)點的熵= – (15/30)log2(15/30)-(15/30)log2(15/30)= 1���。1表示這是一個不純潔的節(jié)點���。
②女性節(jié)點的熵= -(2/10)log2(2/10)-(8/10)log2(8/10)= 0.72和男性節(jié)點,-(13/20)log2(13/20)(7/20)log2(7/20)= 0.93
③子節(jié)點性別分割的熵=加權熵=(10/30)* 0.72 +(20/30)* 0.72 = 0.86
④IX班級子節(jié)點的熵,-(6/14)log2(6/14)(8/14)log2(8/14)= 0.99 X班級子節(jié)點,-(9/16)log2(9/16)(7/16)log2(7/16)= 0.99。
⑤班級分割的熵=(14/30)* 0.99 +(16/30)* 0.99 = 0.99
以上,你可以看到性別分裂的熵在所有之中是最低的,所以這個樹模型將在性別上分裂����。我們可以得出信息熵作為1 -熵。
l減少方差
到現(xiàn)在,我們已經(jīng)討論了分類目標變量的算法���。減少方差算法用于連續(xù)目標變量(回歸問題)���。該算法使用標準方差公式選擇最佳分裂。選擇方差較低的分裂作為總量分裂的標準:
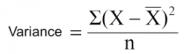
以上X指的是值,X是實際得值,n是值的數(shù)量���。
方差的計算方法:
①為每個節(jié)點計算方差�����。
②為每個節(jié)點方差做加權平均�����。
例子:——讓我們分配數(shù)值1為打板球和0為不玩板球。現(xiàn)在按以下步驟確定正確的分割:
①方差為根節(jié)點,這意味著值是(15 * 1 + 15 * 0)/ 30 = 0.5���,我們有15個 1和15個 0?�,F(xiàn)在方差是((1 – 0.5)^ 2 +(1 – 0.5)^ 2 +…�。+ 15倍(0 – 0.5)^ 2 +(0 – 0.5)^ 2 +…)/ 30的15倍,這可以寫成(15 *(1 – 0.5)^ 2 + 15 *(0 – 0.5)^ 2)/ 30 = 0.25
②女性節(jié)點的平均值=(2 * 1 + 8 * 0)/ 10 = 0.2和方差=(2 *(1 – 0.2)^ 2 + 8 *(0 – 0.2)^ 2)/ 10 = 0.16
③男性節(jié)點的平均值=(13 * 1 + 7 * 0)/ 20 = 0.65,方差=(13 *(1 – 0.65)^ 2 + 7 *(0 – 0.65)^ 2)/ 20 = 0.23
④分割性別的方差=子節(jié)點的加權方差=(10/30)* 0.16 +(20/30)* 0.16 = 0.21
⑤IX班級節(jié)點的平均值=(6 * 1 + 8 * 0)/ 14 = 0.43,方差=(6 *(1 – 0.43)^ 2 + 8 *(0 – 0.43)^ 2)/ 14 = 0.24
⑥X班級節(jié)點的平均值=(9 * 1 + 7 * 0)/ 16 = 0.56和方差=(9 *(1 – 0.56)^ 2 + 7 *(0 – 0.56)^ 2)/ 16 = 0.25
⑦分割性別的方差=(14/30)* 0.24 +(16/30)* 0.25 = 0.25
以上,你可以看到性別分割方差比父節(jié)點低,所以分割會發(fā)生在性別變量�。
到這里,我們就學會了基本的決策樹和選擇最好的分裂建立樹模型的決策過程。就像我說的,決策樹可以應用在回歸和分類問題上���。讓我們詳細了解這些方面�����。
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330