WePay機(jī)器學(xué)習(xí)反欺詐實(shí)踐:Python+scikit-learn+隨機(jī)森林
什么是shell selling?
雖然欺詐幾乎涉及各種領(lǐng)域�,但相對(duì)于傳統(tǒng)的買方或賣方僅僅擔(dān)心對(duì)方是否是騙子,支付平臺(tái)需要擔(dān)心的是交易雙方。如果其中任何一方存在信用詐騙���,真正的持卡人發(fā)現(xiàn)和撤銷費(fèi)用����,平臺(tái)自身就要進(jìn)行賬單償還�����。
shell selling是在這種情況下特別受關(guān)注的欺詐類型的一種�。基本上�,當(dāng)交易雙方都帶有欺騙性質(zhì)時(shí)���,這種模式便會(huì)發(fā)生,比如說有一個(gè)犯罪分子用偷來的一個(gè)信用卡賬戶來支付兩筆支付�����。
shell selling可能很難發(fā)現(xiàn),因?yàn)檫@些欺騙者姿態(tài)很低調(diào)�����。他們通常沒有多少“真正”的客戶�����,所以你不能依靠用戶反饋結(jié)果,用這種方式你會(huì)碰到更多傳統(tǒng)的欺騙者�����。當(dāng)一個(gè)商人在一個(gè)很短的時(shí)間段里獲得了來自同一個(gè)IP的一堆付款時(shí)�����,這很明顯��,但主導(dǎo)這種欺詐罪行的情況往往比這還要復(fù)雜很多���。他們常常使用各種各樣的技術(shù)來隱藏自己的身份和逃避偵測。
由于shell selling是一個(gè)普遍的難題�,而且很難被發(fā)現(xiàn)����,所以我們決定建立一個(gè)機(jī)器學(xué)習(xí)算法來幫助抓住它�����。
構(gòu)建機(jī)器學(xué)習(xí)算法注意事項(xiàng)
在WePay��,我們采用Python建立整個(gè)機(jī)器學(xué)習(xí)的流程,采用流行的scikit-learn開源學(xué)習(xí)機(jī)器學(xué)習(xí)工具包�����。如果你還沒有使用過scikit-learn��,我強(qiáng)烈建議你嘗試���。對(duì)于欺詐模型這類需要不斷重新訓(xùn)練和快速部署的任務(wù)��,它有很多優(yōu)點(diǎn):
scikit-learn使用一個(gè)統(tǒng)一的API來跨不同機(jī)器學(xué)習(xí)算法實(shí)現(xiàn)模型擬合與預(yù)測,使得不同算法之間的代碼復(fù)用真正有效����。
網(wǎng)絡(luò)服務(wù)(web services)的評(píng)分可以利用Django或Flask直接進(jìn)行基于Python的服務(wù)器托管����,從而使部署更為簡單����。我們只需要安裝scikit-learn,復(fù)制導(dǎo)出模型文件和必要的數(shù)據(jù)處理管道代碼到網(wǎng)絡(luò)服務(wù)實(shí)例用于啟動(dòng)。
整個(gè)模型的開發(fā)和部署周期完全用Python獨(dú)立編寫�。這給了我們一個(gè)超過其他流行機(jī)器學(xué)習(xí)語言像R或SAS的優(yōu)勢����,后者需要模型在投入生產(chǎn)之前被轉(zhuǎn)換成另一種語言。除了通過消除不必要的步驟簡化了開發(fā)���,這還給予我們更多的靈活性來嘗試不同的算法����,因?yàn)橥ǔG闆r下��,這個(gè)轉(zhuǎn)換過程并不好處理�,它們?cè)诹硪粋€(gè)環(huán)境中的麻煩會(huì)多于價(jià)值。
算法:隨機(jī)森林(Random Forest)
回到shell selling,我們測試了幾種算法��,然后選定能給以我們最好的性能的算法:隨機(jī)森林���。
隨機(jī)森林是Leo Breiman 和 Adele Cutler開發(fā)的一種基于樹形結(jié)構(gòu)的集成方法�����,由Breiman于2001年在機(jī)器學(xué)習(xí)期刊的評(píng)議文章中首次提出[1]。隨機(jī)森林在訓(xùn)練數(shù)據(jù)的隨機(jī)子集上訓(xùn)練許多決策樹�,然后使用單個(gè)樹的預(yù)測均值作為最終的預(yù)測。隨機(jī)子集是從原始的訓(xùn)練數(shù)據(jù)抽樣�,通過在記錄級(jí)有放回抽樣(bootstrap)和在特征級(jí)隨機(jī)二次抽樣得到。
我們嘗試的算法的召回率�,隨機(jī)森林提供了最佳的精度��,緊隨其后的是神經(jīng)網(wǎng)絡(luò)和另外一種集成方法AdaBoost。相比于其他算法����,隨機(jī)森林針對(duì)我們碰到的各類欺詐數(shù)據(jù)有許多的優(yōu)勢:
基于集成方法的樹可以同時(shí)很好地處理非線性和非單調(diào)性,這在欺詐信號(hào)中相當(dāng)普遍���。相比之下����,神經(jīng)網(wǎng)絡(luò)對(duì)非線性處理地相當(dāng)不錯(cuò)�����,但同時(shí)受到非單調(diào)性的羈絆��,而邏輯回歸都無法處理�����。對(duì)于使用后兩種方法來處理的非線性和/或非單調(diào)性��,我們需要廣泛的和適當(dāng)?shù)?a href='/map/tezheng/' style='color:#000;font-size:inherit;'>特征轉(zhuǎn)換�����。
隨機(jī)森林需要最小的特征預(yù)備和特征轉(zhuǎn)換����,它不需要神經(jīng)網(wǎng)絡(luò)和邏輯回歸要求的標(biāo)準(zhǔn)化輸入變量����,也不需要聚類和風(fēng)險(xiǎn)評(píng)級(jí)轉(zhuǎn)換為非單調(diào)變量。
隨機(jī)森林相比其他算法擁有最好的開箱即用的性能���。另一個(gè)基于樹的方法��,梯度提升決策樹(GBT),可以達(dá)到類似的性能���,但需要更多的參數(shù)調(diào)優(yōu)。
隨機(jī)森林輸出特征的重要性體現(xiàn)在作為模型訓(xùn)練的副產(chǎn)品�����,這對(duì)于特征選擇是非常有用的[2]��。
隨機(jī)森林與其他算法相比具有更好的過擬合(overfitting)容錯(cuò)性��,并且處理大量的變量也不會(huì)有太多的過擬合[1]�,因?yàn)?a href='/map/guonihe/' style='color:#000;font-size:inherit;'>過擬合可以通過更多的決策樹來削弱��。此外�,變量的選擇和減少也不像其他算法那么重要����。
下圖是隨機(jī)森林與其競爭對(duì)手的對(duì)比情況:

訓(xùn)練算法
我們的機(jī)器學(xué)習(xí)流程遵循一個(gè)標(biāo)準(zhǔn)程序����,包括數(shù)據(jù)抽取、數(shù)據(jù)清洗�����、特征推導(dǎo)、特征工程和轉(zhuǎn)換、特征選擇���、模型訓(xùn)練和模型性能評(píng)價(jià):
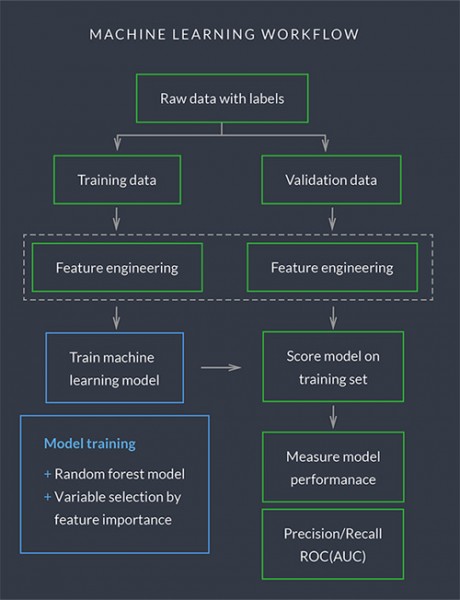
洞察
經(jīng)過大量的訓(xùn)練��,我們的隨機(jī)森林算法對(duì)于shell selling的識(shí)別已經(jīng)成為現(xiàn)實(shí)��,并且積極地阻止欺詐����。當(dāng)然我們還需要大量的工作去選擇���、訓(xùn)練和部署該算法��,但是它已經(jīng)使得我們的風(fēng)險(xiǎn)流程更加健壯�����,且有能力使用更少的人工來檢查抓住更多的欺詐�。在同一欺詐召回率��,這一模型的精度是不斷調(diào)整和優(yōu)化規(guī)則的2 – 3倍����。
使用這種算法�����,除了得到明顯的好處以外,我們對(duì)于數(shù)據(jù)和建模過程中使用的方法也有了更多的理解:
通過特征選擇的過程����,我們發(fā)現(xiàn)對(duì)這種欺詐行為最有預(yù)測力的特征是速度型的變量。這些包括用戶的交易量��、設(shè)備�、真正的IP和信用卡。我們還發(fā)現(xiàn)����,設(shè)備ID、銀行賬戶和信用卡等賬戶相關(guān)特性都是很有用的����,如多個(gè)賬戶登錄到一個(gè)設(shè)備,以及多重提款到一個(gè)銀行賬戶�����。
風(fēng)險(xiǎn)等級(jí)的分類變量���,如電子郵件域�����,應(yīng)用程序ID�、用戶的國家,以及一天中的時(shí)間風(fēng)險(xiǎn)評(píng)級(jí)����,也證明了高度預(yù)測性。
數(shù)字足跡諸如瀏覽器語言����、操作系統(tǒng)字體、屏幕分辨率����、用戶代理、flash版本等對(duì)于反欺詐是有點(diǎn)用的��。稍微有更多預(yù)測性的是在人們隱藏他們的數(shù)字足跡過程當(dāng)中����,例如VPN隧道或虛擬機(jī)和TOR的使用。
我們還發(fā)現(xiàn)模型性能迅速惡化��。這真的不是一個(gè)驚喜——騙子不斷改變他們的方法來避免檢測���,所以即使是最好的模型��,如果不改變也終將過時(shí)�����。但是我們非常驚訝這發(fā)生的速度有多快�。對(duì)shell selling而言���,在模型訓(xùn)練后僅僅第一個(gè)月精度便下降一半���。因此, 經(jīng)常刷新模型來保持高檢測精度對(duì)于欺詐檢測的成功是至關(guān)重要的。
不幸的是���,頻繁刷新暴露出他們自己的問題����。雖然刷新模型盡可能經(jīng)常是理想的�,但是在使用最近的事務(wù)數(shù)據(jù)來訓(xùn)練模型時(shí)必須格外小心。欺詐標(biāo)簽可以需要一個(gè)月成熟��,所以事實(shí)上使用最近的數(shù)據(jù)也會(huì)污染模型���。和我們最初的假設(shè)不同�����,利用最新數(shù)據(jù)在線學(xué)習(xí)并不會(huì)總能得到最好的結(jié)果����。
隨機(jī)森林是一個(gè)生產(chǎn)高性能模型的優(yōu)異的機(jī)器學(xué)習(xí)算法,然而��,它通常被用來作為一個(gè)黑盒方法���。這是一個(gè)問題����,因?yàn)槲覀儾⒉皇窃噲D要完全削減人類的全部過程���,而且很有可能無法做到即使我們?cè)敢?。人類分析師總是希望得到原因代碼���,告訴他們?yōu)槭裁词虑楸粯?biāo)記之后來引導(dǎo)他們的案件審查����。但隨機(jī)森林,就其本身而言����,不能隨時(shí)提供原因代碼���。解釋模型數(shù)據(jù)是困難的�����,而且還可能涉及挖掘“森林”的結(jié)構(gòu)����,這可以顯著提高評(píng)分的時(shí)間�。實(shí)際上,為了應(yīng)對(duì)這個(gè)問題�,WePay的數(shù)據(jù)科學(xué)團(tuán)隊(duì)發(fā)明了一種新的私有方法可以從隨機(jī)森林算生成原因代碼,我們?yōu)檫@種方法申請(qǐng)了臨時(shí)專利��。
結(jié)論
風(fēng)險(xiǎn)管理技術(shù)是WePay的核心�����。風(fēng)險(xiǎn)管理不僅僅是技術(shù),它還體現(xiàn)了人類和技術(shù)無縫合作的伙伴關(guān)系����。它在很大程度上仍然是人類不得不思考的方式,騙子可以攻擊一個(gè)支付系統(tǒng)�,編寫規(guī)則來阻止它們,而且還是一個(gè)經(jīng)驗(yàn)豐富的專業(yè)人員�����,當(dāng)它下跌到 “明顯欺詐”和“顯然合法” 之間的灰色地帶時(shí)��,它必須像經(jīng)常處理的那樣�����,做出判斷是否阻止交易�。
這就是為什么我們?nèi)绱伺d奮于機(jī)器學(xué)習(xí)和人工智能。我們并非試圖取代人類���,只是希望機(jī)器智能更加聰明更好地工作�,而我們可以集中人類智慧關(guān)注其他的大難題����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材��,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330