樸素貝葉斯分類和預(yù)測(cè)算法的原理及實(shí)現(xiàn)
決策樹和樸素貝葉斯是最常用的兩種分類算法,本篇文章介紹樸素貝葉斯算法���。貝葉斯定理是以英國數(shù)學(xué)家貝葉斯命名����,用來解決兩個(gè)條件概率之間的關(guān)系問題�。簡單的說就是在已知P(A|B)時(shí)如何獲得P(B|A)的概率。樸素貝葉斯(Naive Bayes)假設(shè)特征P(A)在特定結(jié)果P(B)下是獨(dú)立的�����。
1. 概率基礎(chǔ):
在開始介紹貝葉斯之前��,先簡單介紹下概率的基礎(chǔ)知識(shí)��。概率是某一結(jié)果出現(xiàn)的可能性��。例如���,拋一枚勻質(zhì)硬幣����,正面向上的可能性多大����?概率值是一個(gè)0-1之間的數(shù)字�,用來衡量一個(gè)事件發(fā)生可能性的大小�����。概率值越接近1��,事件發(fā)生的可能性越大��,概率值越接近0��,事件越不可能發(fā)生����。我們?nèi)粘I钪新牭阶疃嗟氖翘鞖忸A(yù)報(bào)中的降水概率��。概率的表示方法叫維恩圖���。下面我們通過維恩圖來說明貝葉斯公式中常見的幾個(gè)概率��。
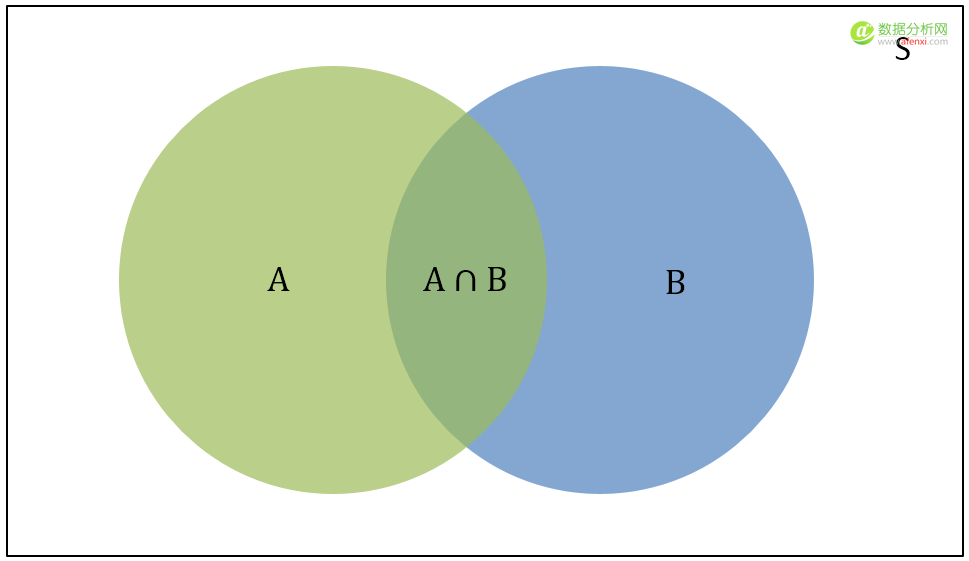
在維恩圖中:
S:S是樣本空間�,是所有可能事件的總和�。
P(A):是樣本空間S中A事件發(fā)生的概率����,維恩圖中綠色的部分�����。
P(B):是樣本空間S中B事件發(fā)生的概率�,維恩圖中藍(lán)色的部分。
P(A∩B):是樣本空間S中A事件和B事件同時(shí)發(fā)生的概率����,也就是A和B相交的區(qū)域。
P(A|B):是條件概率���,是B事件已經(jīng)發(fā)生時(shí)A事件發(fā)生的概率�����。
對(duì)于條件概率�,還有一種更清晰的表示方式叫概率樹����。下面的概率樹表示了條件概率P(A|B)。與維恩圖中的P(A∩B)相比�,可以發(fā)現(xiàn)兩者明顯的區(qū)別�����。P(A∩B)是事件A和事件B同時(shí)發(fā)現(xiàn)的情況,因此是兩者相交區(qū)域的概率���。而事件概率P(A|B)是事件B發(fā)生時(shí)事件A發(fā)生的概率。這里有一個(gè)先決條件就是P(B)要首先發(fā)生�����。

因?yàn)闂l件概率P(A|B)是在事件B已經(jīng)發(fā)生的情況下�,事件A發(fā)生的概率,因此P(A|B)可以表示為事件A與B的交集與事件B的比率�����。
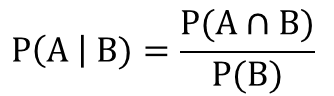
該公式還可以轉(zhuǎn)換為以下形式�����,以便我們下面進(jìn)行貝葉斯公式計(jì)算時(shí)使用�。
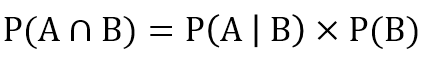
2. 貝葉斯公式:
貝葉斯算法通過已知的P(A|B),P(A),和P(B)三個(gè)概率計(jì)算P(B|A)發(fā)生的概率���。假設(shè)我們現(xiàn)在已知P(A|B)���,P(A)和P(B)三個(gè)概率��,如何計(jì)算P(B|A)呢��?通過前面的概率樹及P(A|B)的概率可知����,P(B|A)的概率是在事件A發(fā)生的前提下事件B發(fā)生的概率���,因此P(B|A)可以表示為事件B與事件A的交集與事件A的比率�����。
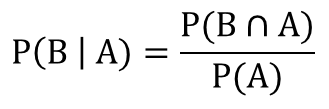
該公式同樣可以轉(zhuǎn)化為以下形式:
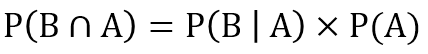
到這一步��,我們只需要證明P(A∩B)= P(B∩A)就可以證明在已知P(A|B)的情況下可以通過計(jì)算獲得P(B|A)的概率�。我們將概率樹轉(zhuǎn)化為下面的概率表���,分別列出P(A|B),P(B|A),P(A),和P(B)的概率�。
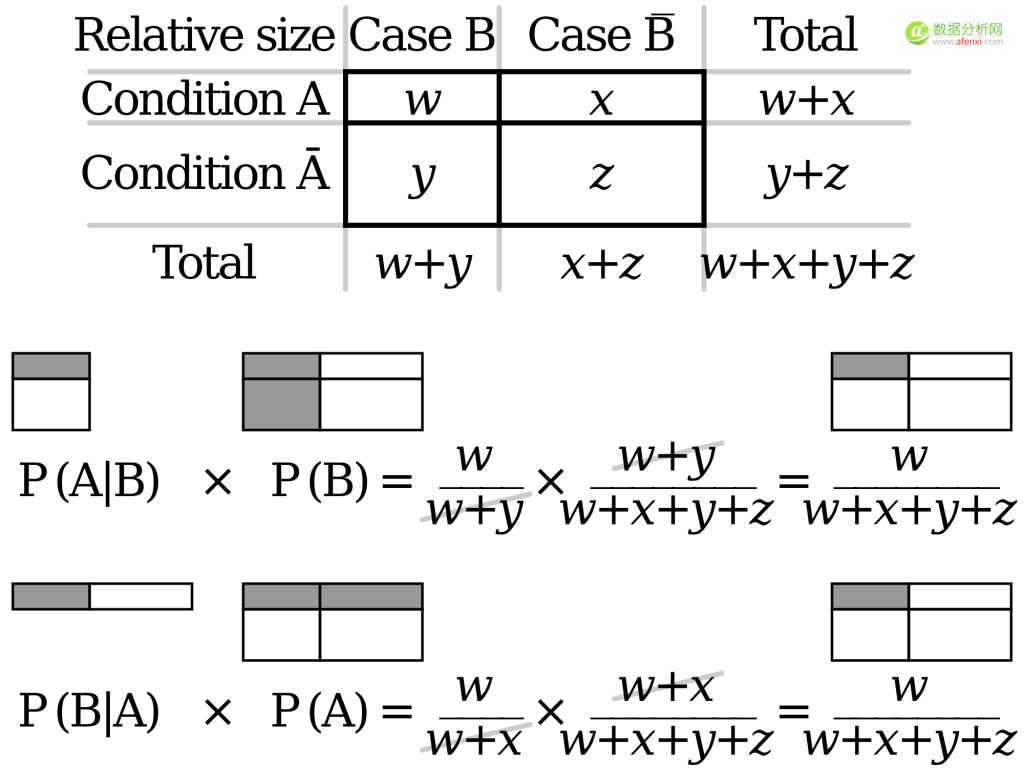
通過計(jì)算可以證明P(A|B)*P(B)和P(B|A)*P(A)最后求得的結(jié)果是概率表中的同一個(gè)區(qū)域的值,因此:

我們通過P(A∩B)= P(B∩A)證明了在已知P(A|B)���,P(A),和P(B)三個(gè)概率的情況下可以計(jì)算出P(B|A)發(fā)生的概率。整個(gè)推導(dǎo)和計(jì)算過程可以說得通����。但從統(tǒng)計(jì)學(xué)的角度來看,P(A|B)和P(B|A)兩個(gè)條件概率之間存在怎樣的關(guān)系呢���?我們從貝葉斯推斷里可以找到答案��。
3. 貝葉斯推斷:
貝葉斯推斷可以說明貝葉斯定理中兩個(gè)條件概率之間的關(guān)系。換句話說就是我們?yōu)槭裁纯梢酝ㄟ^P(A|B)����,P(A),和P(B)三個(gè)概率計(jì)算出P(B|A)發(fā)生的概率。

在貝葉斯推斷中���,每一種概率都有一個(gè)特定的名字:
P(B)是”先驗(yàn)概率”(Prior probability)���。
P(A)是”先驗(yàn)概率”(Prior probability),也作標(biāo)準(zhǔn)化常量(normalized constant)�����。
P(A|B)是已知B發(fā)生后A的條件概率�,叫做似然函數(shù)(likelihood)。
P(B|A)是已知A發(fā)生后B的條件概率����,是我們要求的值,叫做后驗(yàn)概率�。
P(A|B)/P(A)是調(diào)整因子�����,也被稱作標(biāo)準(zhǔn)似然度(standardised likelihood)��。
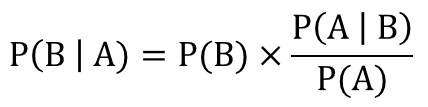
貝葉斯推斷中有幾個(gè)關(guān)鍵的概念需要說明下:
第一個(gè)是先驗(yàn)概率�����,先驗(yàn)概率是指我們主觀通過事件發(fā)生次數(shù)對(duì)概率的判斷�����。
第二個(gè)是似然函數(shù),似然函數(shù)是對(duì)某件事發(fā)生可能性的判斷�����,與條件概率正好相反���。通過事件已經(jīng)發(fā)生的概率推算事件可能性的概率。
維基百科中對(duì)似然函數(shù)與概率的解釋:
概率:是給定某一參數(shù)值���,求某一結(jié)果的可能性�����。
例如��,拋一枚勻質(zhì)硬幣,拋10次��,6次正面向上的可能性多大���?
似然函數(shù):給定某一結(jié)果�,求某一參數(shù)值的可能性�。
例如,拋一枚硬幣,拋10次���,結(jié)果是6次正面向上�����,其是勻質(zhì)的可能性多大�����?
第三個(gè)是調(diào)整因子:調(diào)整因子是似然函數(shù)與先驗(yàn)概率的比值����,這個(gè)比值相當(dāng)于一個(gè)權(quán)重��,用來調(diào)整后驗(yàn)概率的值���,使后驗(yàn)概率更接近真實(shí)概率�。調(diào)整因子有三種情況�����,大于1��,等于1和小于1。
-
調(diào)整因子P(A|B)/P(A)>1:說明事件可能發(fā)生的概率要大于事件已經(jīng)發(fā)生次數(shù)的概率�。
-
調(diào)整因子P(A|B)/P(A)=1:說明事件可能發(fā)生的概率與事件已經(jīng)發(fā)生次數(shù)的概率相等。
-
調(diào)整因子P(A|B)/P(A)<1:說明事件可能發(fā)生的概率與事件小于已經(jīng)發(fā)生次數(shù)的概率�����。
因此�,貝葉斯推斷可以理解為通過先驗(yàn)概率和調(diào)整因子來獲得后驗(yàn)概率。其中調(diào)整因子是根據(jù)事件已經(jīng)發(fā)生的概率推斷事件可能發(fā)生的概率(通過硬幣正面出現(xiàn)的次數(shù)來推斷硬幣均勻的可能性)����,并與已經(jīng)發(fā)生的先驗(yàn)概率(硬幣正面出現(xiàn)的概率)的比值。通過這個(gè)比值調(diào)整先驗(yàn)概率來獲得后驗(yàn)概率�����。
后驗(yàn)概率?���。健?a href='/map/xianyangailv/' style='color:#000;font-size:inherit;'>先驗(yàn)概率 x 調(diào)整因子
4. 實(shí)例1:垃圾郵件分類
貝葉斯分類器比較有名的實(shí)驗(yàn)場(chǎng)景是對(duì)垃圾郵件進(jìn)行分類和過濾。這里我們簡單介紹下通過貝葉斯算法過濾垃圾郵件的過程�。貝葉斯分類器需要依賴歷史數(shù)據(jù)進(jìn)行學(xué)習(xí)��,假定包含關(guān)鍵詞”中獎(jiǎng)”的就算作垃圾郵件���。我們先經(jīng)過人工篩選找出10封郵件���,并對(duì)包含關(guān)鍵詞”中獎(jiǎng)“的郵件標(biāo)注為垃圾郵件(Spam)��。

我們將普通郵件和垃圾郵件中出現(xiàn)“中獎(jiǎng)”關(guān)鍵詞的頻率進(jìn)行匯總�����,分別記錄普通郵件中出現(xiàn)和未出現(xiàn)該關(guān)鍵詞的次數(shù)和垃圾郵件中出現(xiàn)和未出現(xiàn)該關(guān)鍵詞的次數(shù)���,并分別進(jìn)行匯總。
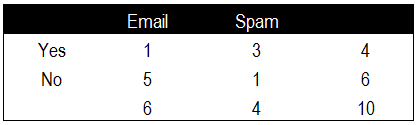
根據(jù)頻率表計(jì)算出貝葉斯算法中所需的關(guān)鍵概率值�����,這里我們已知普通郵件的概率P(Email)����,垃圾郵件的概率P(Spam),出現(xiàn)關(guān)鍵詞的概率P(Yes)���,未出現(xiàn)關(guān)鍵詞的概率P(No)�,以及垃圾郵件出現(xiàn)關(guān)鍵詞的概率P(Yes|Spam)�。

按照貝葉斯公式����,已知P(B|A)���,P(A)和P(B)的概率�。求P(A|B)的概率����。

我們將貝葉斯公式套用到垃圾郵件分類中,已知垃圾郵件中出現(xiàn)“中獎(jiǎng)”關(guān)鍵詞的概率��,和垃圾郵件及“中獎(jiǎng)”關(guān)鍵詞的概率����,求出現(xiàn)“中獎(jiǎng)”關(guān)鍵詞是垃圾郵件的概率。
P(A)=P(垃圾郵件)=0.40
P(B)=P(出現(xiàn)關(guān)鍵詞)=0.40
P(B|A)=P(出現(xiàn)關(guān)鍵詞|垃圾郵件)=0.75
P(A|B)=P(垃圾郵件|出現(xiàn)關(guān)鍵詞)

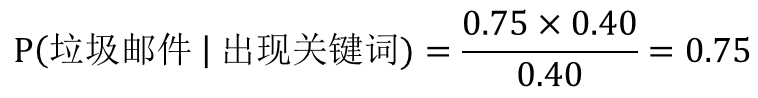
5. 實(shí)例2:病情預(yù)測(cè)
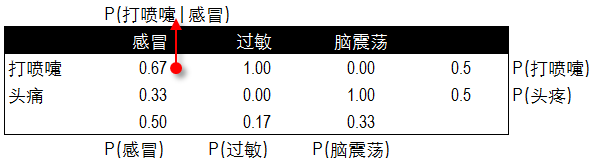
除了垃圾郵件分類���,再來看一個(gè)病情預(yù)測(cè)的實(shí)例�����。通過歷史數(shù)據(jù)已知幾類疾病的病癥及 患病人職業(yè)�����。那么如果新來的一位打噴嚏的建筑工人���,如何通過貝葉斯算法通過歷史數(shù)據(jù)來預(yù)測(cè)這位打噴嚏的建筑工人患感冒的概率呢?以下是6位歷史病例的數(shù)據(jù)��。

根據(jù)疾病的種類���,我們分別對(duì)不同病癥和不同職業(yè)患病的頻率進(jìn)行了統(tǒng)計(jì)�����。以下分別是不同癥狀與對(duì)應(yīng)疾病發(fā)生的頻率表��,和不同職業(yè)與所對(duì)應(yīng)疾病發(fā)生的頻率表��。
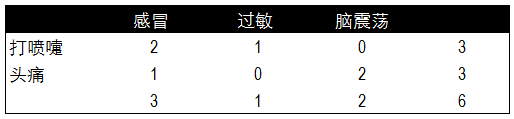
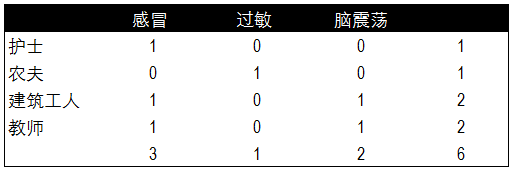
根據(jù)兩個(gè)頻率表分布計(jì)算出貝葉斯算法中所需的概率值��,這里我們已知每種疾病的概率�,不同職業(yè)和不同癥狀的概率�,以及患感冒后打噴嚏和職業(yè)為建筑工人的概率。

按照貝葉斯公式���,已知P(B*C|A)��,P(A)和P(B*C)的概率��。求P(A|B*C)的概率�����。
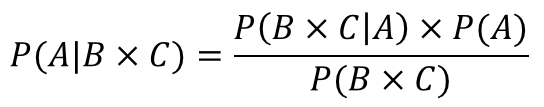
我們假設(shè)護(hù)士和打噴嚏這兩個(gè)特征在感冒這個(gè)結(jié)果下是獨(dú)立的�����,因此��,上面的貝葉斯公式可以轉(zhuǎn)化為樸素貝葉斯公式:
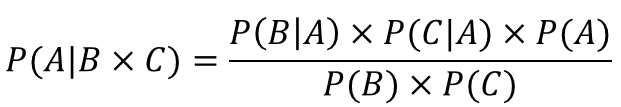
我們將貝葉斯公式套用到疾病預(yù)測(cè)中:
P(A)=P(感冒)=0.5
P(B)=P(打噴嚏)=0.5
P(C)=P(建筑工人)=0.33
P(B|A)= P(打噴嚏|感冒)=0.67
P(C|A)= P(建筑工人|感冒)=0.33

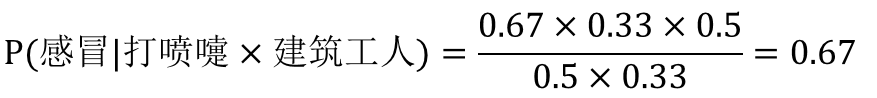
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材���,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫��,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330