SAS數(shù)據(jù)挖掘實(shí)戰(zhàn)篇【四】
今天主要是介紹一下SAS的聚類案例����,希望大家都動手做一遍�,很多問題只有在親自動手的過程中才會有發(fā)現(xiàn)有收獲有心得。
1 聚類分析介紹
1.1 基本概念
聚類就是一種尋找數(shù)據(jù)之間一種內(nèi)在結(jié)構(gòu)的技術(shù)���。聚類把全體數(shù)據(jù)實(shí)例組織成一些相似組���,而這些相似組被稱作聚類�����。處于相同聚類中的數(shù)據(jù)實(shí)例彼此相同����,處于不同聚類中的實(shí)例彼此不同�����。聚類技術(shù)通常又被稱為無監(jiān)督學(xué)習(xí),因?yàn)榕c監(jiān)督學(xué)習(xí)不同����,在聚類中那些表示數(shù)據(jù)類別的分類或者分組信息是沒有的����。
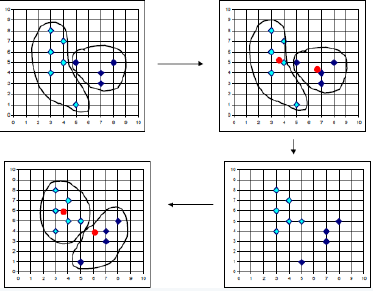
通過上述表述,我們可以把聚類定義為將數(shù)據(jù)集中在某些方面具有相似性的數(shù)據(jù)成員進(jìn)行分類組織的過程。因此�,聚類就是一些數(shù)據(jù)實(shí)例的集合�����,這個(gè)集合中的元素彼此相似�����,但是它們都與其他聚類中的元素不同����。在聚類的相關(guān)文獻(xiàn)中,一個(gè)數(shù)據(jù)實(shí)例有時(shí)又被稱為對象���,因?yàn)楝F(xiàn)實(shí)世界中的一個(gè)對象可以用數(shù)據(jù)實(shí)例來描述�。同時(shí)��,它有時(shí)也被稱作數(shù)據(jù)點(diǎn)(Data Point)����,因?yàn)槲覀兛梢杂胷 維空間的一個(gè)點(diǎn)來表示數(shù)據(jù)實(shí)例���,其中r 表示數(shù)據(jù)的屬性個(gè)數(shù)。下圖顯示了一個(gè)二維數(shù)據(jù)集聚類過程����,從該圖中可以清楚地看到數(shù)據(jù)聚類過程。雖然通過目測可以十分清晰地發(fā)現(xiàn)隱藏在二維或者三維的數(shù)據(jù)集中的聚類���,但是隨著數(shù)據(jù)集維數(shù)的不斷增加��,就很難通過目測來觀察甚至是不可能�。
1.2算法概述
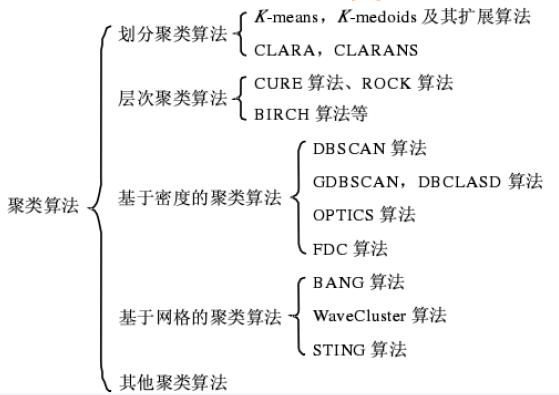
目前在存在大量的聚類算法����,算法的選擇取決于數(shù)據(jù)的類型、聚類的目的和具體應(yīng)用�����。大體上�,主要的聚類算法分為幾大類。
聚類算法的目的是將數(shù)據(jù)對象自動的歸入到相應(yīng)的有意義的聚類中����。追求較高的類內(nèi)相似度和較低的類間相似度是聚類算法的指導(dǎo)原則��。一個(gè)聚類算法的優(yōu)劣可以從以下幾個(gè)方面來衡量:
(1)可伸縮性:好的聚類算法可以處理包含大到幾百萬個(gè)對象的數(shù)據(jù)集�;
(2)處理不同類型屬性的能力:許多算法是針對基于區(qū)間的數(shù)值屬性而設(shè)計(jì)的���,但是有些應(yīng)用需要針對其它數(shù)據(jù)類型(如符號類型、二值類型等)進(jìn)行處理��;
(3)發(fā)現(xiàn)任意形狀的聚類:一個(gè)聚類可能是任意形狀的����,聚類算法不能局限于規(guī)則形狀的聚類;
(4)輸入?yún)?shù)的最小化:要求用戶輸入重要的參數(shù)不僅加重了用戶的負(fù)擔(dān)���,也使聚類的質(zhì)量
難以控制����;
(5)對輸入順序的不敏感:不能因?yàn)橛胁煌臄?shù)據(jù)提交順序而使聚類的結(jié)果不同�;
(6)高維性:一個(gè)數(shù)據(jù)集可能包含若干維或?qū)傩裕粋€(gè)好的聚類算法不能僅局限于處理二維
或三維數(shù)據(jù)�,而需要在高維空間中發(fā)現(xiàn)有意義的聚類;
(7)基于約束的聚類:在實(shí)際應(yīng)用中要考慮很多約束條件���,設(shè)計(jì)能夠滿足特定約束條件且具
有較好聚類質(zhì)量的算法也是一項(xiàng)重要的任務(wù)��;
(8)可解釋性:聚類的結(jié)果應(yīng)該是可理解的��、可解釋的����,以及可用的。
1.3 聚類應(yīng)用
在商業(yè)上�����,聚類分析被用來發(fā)現(xiàn)不同的客戶群����,并且通過購買模式刻畫不同的客戶群的特征。聚類分析是細(xì)分市場的有效工具����,同時(shí)也可用于研究消費(fèi)者行為,尋找新的潛在市場�����、選擇實(shí)驗(yàn)的市場�,并作為多元分析的預(yù)處理。在生物上,聚類分析被用來動植物分類和對基因進(jìn)行分類����,獲取對種群固有結(jié)構(gòu)的認(rèn)識。在地理上����,聚類能夠幫助在地球中被觀察的數(shù)據(jù)庫商趨于的相似性。在保險(xiǎn)行業(yè)上����,聚類分析通過一個(gè)高的平均消費(fèi)來鑒定汽車保險(xiǎn)單持有者的分組����,同時(shí)根據(jù)住宅類型,價(jià)值�����,地理位置來鑒定一個(gè)城市的房產(chǎn)分組����。在因特網(wǎng)應(yīng)用上,聚類分析被用來在網(wǎng)上進(jìn)行文檔歸類來修復(fù)信息�。在電子商務(wù)上,聚類分析在電子商務(wù)中網(wǎng)站建設(shè)數(shù)據(jù)挖掘中也是很重要的一個(gè)方面,通過分組聚類出具有相似瀏覽行為的客戶�����,并分析客戶的共同特征�,可以更好的幫助電子商務(wù)的用戶了解自己的客戶,向客戶提供更合適的服務(wù)��。
2kmeans 算法
2.1 基本思想
劃分聚類算法是根據(jù)給定的n 個(gè)對象或者元組的數(shù)據(jù)集�����,構(gòu)建k 個(gè)劃分聚類的方法��。每個(gè)劃分即為一個(gè)聚簇�,并且k ? n。該方法將數(shù)據(jù)劃分為k 個(gè)組���,每個(gè)組至少有一個(gè)對象���,每個(gè)對象必須屬于而且只能屬于一個(gè)組。1該方法的劃分采用按照給定的k 個(gè)劃分要求�,先給出一個(gè)初始的劃分,然后用迭代重定位技術(shù)�,通過對象在劃分之間的移動來改進(jìn)劃分。
為達(dá)到劃分的全局最優(yōu),劃分的聚類可能會窮舉所有可能的劃分�。但在實(shí)際操作中,往往采用比較流行的k-means 算法或者k-median 算法�。
2.2 算法步驟
k-means 算法最為簡單,實(shí)現(xiàn)比較容易��。每個(gè)簇都是使用對象的平均值來表示���。
步驟一:將所有對象隨機(jī)分配到k 個(gè)非空的簇中�����。
步驟二:計(jì)算每個(gè)簇的平均值���,并用該平均值代表相應(yīng)的值�。
步驟三:根據(jù)每個(gè)對象與各個(gè)簇中心的距離,分配給最近的簇�。
步驟四:轉(zhuǎn)到步驟二,重新計(jì)算每個(gè)簇的平均值�。這個(gè)過程不斷重復(fù)直到滿足某個(gè)準(zhǔn)則函數(shù)或者終止條件。終止(收斂)條件可以是以下任何一個(gè):沒有(或者最小數(shù)目)數(shù)據(jù)點(diǎn)被重新分配給不同的聚類��;沒有(或者最小數(shù)目)聚類中心再發(fā)生變化����;誤差平方和(SSE)局部最小��。
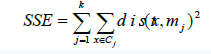
其中�, k 表示需要聚集的類的數(shù)目����, Cj表示第j 個(gè)聚類,mj表示聚類Cj的聚類中心�,
dist表示數(shù)據(jù)點(diǎn)x 和聚類中心mj之間的距離。利用該準(zhǔn)則可以使所生成的簇盡可能
的緊湊和獨(dú)立�����。
SAS kmeans 實(shí)現(xiàn)主要是通過proc fastclus 過程實(shí)現(xiàn)�����,示例如下:
proc import datafile="E:\SAS\cars.txt" out=cars dbms=dlm replace;
delimiter='09'x;
getnames=yes;
run;
proc print data=cars;
run;
proc standard data=cars out=stdcars mean=0 std=1;
var Mpg Weight Drive_Ratio Horsepower Displacement;
run;
proc fastclus data=stdcars summary maxc=5 maxiter=99
outseed=clusterseed out=clusterresult cluster=cluster least=2;
id Car;
var Mpg Weight Drive_Ratio Horsepower Displacement;
run;
2.3 算法分析
k-means 算法對于大型的數(shù)據(jù)庫是相對高效的��,一般情況下結(jié)束于局部最優(yōu)解�。但是,k-means 算法必須在平均值有意義的情況下才能使用�����,對分類變量不適用,事先還要給定生成聚類的數(shù)目���,對異常數(shù)據(jù)和數(shù)據(jù)噪聲比較敏感�����,不能對非凸面形狀的數(shù)據(jù)進(jìn)行處理��。另外���,k-means 算法在聚類過程中可能有的聚類中心沒有被分配任何數(shù)據(jù)而使得某些聚類變?yōu)榭眨@些聚類通常被稱為空聚類��。為了解決空聚類問題��,我們可以選擇一個(gè)數(shù)據(jù)點(diǎn)作為替代的聚類中心��。例如���,某一個(gè)含有大量數(shù)據(jù)的聚類的聚簇中心最遠(yuǎn)的數(shù)據(jù)點(diǎn)。如果算法的終止條件取決于誤差平方和����,具有最大誤差平方和的聚類可以被用來尋找另外的聚類中心��。
3.1基本思想
層次聚類主要有兩種類型:合并的層次聚類和分裂的層次聚類��。前者是一種自底向上的層次聚類算法�����,從最底層開始����,每一次通過合并最相似的聚類來形成上一層次中的聚類��,整個(gè)當(dāng)全部數(shù)據(jù)點(diǎn)都合并到一個(gè)聚類的時(shí)候停止或者達(dá)到某個(gè)終止條件而結(jié)束�,大部分層次聚類都是采用這種方法處理。后者是采用自頂向下的方法����,從一個(gè)包含全部數(shù)據(jù)點(diǎn)的聚類開始,然后把根節(jié)點(diǎn)分裂為一些子聚類�,每個(gè)子聚類再遞歸地繼續(xù)往下分裂,直到出現(xiàn)只包含一個(gè)數(shù)據(jù)點(diǎn)的單節(jié)點(diǎn)聚類出現(xiàn)�����,即每個(gè)聚類中僅包含一個(gè)數(shù)據(jù)點(diǎn)���。
層次聚類技術(shù)是一種無監(jiān)督學(xué)習(xí)的技術(shù)�,因此可能沒有確定的、一致的正確答案�。正是由于這個(gè)原因,并且在聚類的特定應(yīng)用的基礎(chǔ)之上�,可以設(shè)計(jì)出較少或較多數(shù)量的簇。定義了一個(gè)聚類層次����,就可以選擇希望數(shù)量的簇。在極端的情況下�����,所有的對象都自成一簇����。在這樣的情形下,聚類的對象之間非常相似����,并且不同于其他的聚類。當(dāng)然��,這種聚類技術(shù)就失去了實(shí)際意義��,因?yàn)榫垲惖哪康氖菍ふ覕?shù)據(jù)集中的有意義的模式�,方便用戶理解,而任何聚類的數(shù)目和數(shù)據(jù)對象一樣多的聚類算法都不能幫助用戶更好地理解數(shù)據(jù)�����,挖掘數(shù)據(jù)隱藏的真實(shí)含義����。這樣,關(guān)于聚類的很重要的一點(diǎn)就是應(yīng)該比原先的數(shù)據(jù)的數(shù)目更少的簇����。到底要形成多少個(gè)聚類數(shù)目,要根據(jù)實(shí)際業(yè)務(wù)的理解�,這是如何解釋實(shí)際項(xiàng)目的事情。層次聚類算法的好處是它可以讓用戶從這些簇中選擇所感興趣的簇�����,這樣更具有靈活性����。
層次聚類通常被看做成一棵樹���,其中最小的簇合并在一起創(chuàng)建下一個(gè)較高層次的簇,這一層次的簇再合并在一起就創(chuàng)建了再下一層次的簇�。通過這樣的過程,就可以生成一系列的聚類樹來完成聚類��。單點(diǎn)聚類處在樹的最底層�����,在樹的底層有一個(gè)根節(jié)點(diǎn)聚類�����。根節(jié)點(diǎn)聚類覆蓋了全部數(shù)據(jù)節(jié)點(diǎn)���,兄弟節(jié)點(diǎn)聚類則劃分了它們共同的父節(jié)點(diǎn)中的所有的數(shù)據(jù)點(diǎn)�����。圖1-5是采用統(tǒng)計(jì)分析軟件SAS對Cars2數(shù)據(jù)集進(jìn)行層次聚類的層次聚類結(jié)果圖�。通過該層次聚類樹,用戶可以選擇查看在樹的各個(gè)層次上的聚類情況。如圖所示�����。
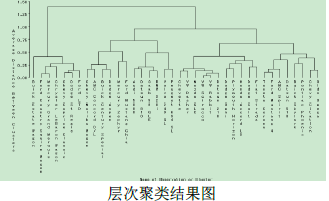
基于層次的聚類算法方法比較簡單�����,但是缺乏伸縮性�����,一旦一個(gè)合并或者分裂被執(zhí)行��,就不能撤銷����。為了改進(jìn)層次聚類的效果,可以將層次聚類算法和其他聚類算法結(jié)合使用�����,形成多階段的聚類算法�����。
3.2算法步驟
層次聚類(hierarchical clustering)算法遞歸的對對象進(jìn)行合并或者分裂��,直到滿足某一終止條件為止�����。層次聚類分為兩種�����,按自底向上層次分解稱為聚合的層次聚類���,反之��,稱為分解的層次聚類。層次聚類算法的計(jì)算復(fù)雜度為O(n2)����,適合小型數(shù)據(jù)集的分類����。
CURE�����、ROCK、BIRCH和CHAMELEON是聚合層次聚類中最具代表性的方法��。CURE(Clustering Using REpresentatives)算法采用了抽樣和分區(qū)的技術(shù)�����,選擇數(shù)據(jù)空間中固定數(shù)目的�����、具有代表性的一些點(diǎn)來代表相應(yīng)的類����,這樣就可以識別具有復(fù)雜形狀和不同大小的聚類����,從而很好的過濾孤立點(diǎn)��。ROCK(RObust Clustering using linKs)算法是對CURE算法的改進(jìn)����,除了具有CURE算法的一些優(yōu)良特性外��,還適用于類別屬性的數(shù)據(jù)�。BIRCH(Balanced Iterative Reducing and Clustering using Hierarchy)算法首次提出了通過局部聚類對數(shù)據(jù)庫進(jìn)行預(yù)處理的思想��。CHAMELEON是Karypis等人1999年提出的����,它在聚合聚類的過程中利用了動態(tài)建模技術(shù)。
SAS實(shí)例
options nocenter nodate pageno=1 linesize=132;
title h = 1 j = l 'File: cluster.mammalsteeth.sas';
title2 h = 1 j = l 'Cluster Analysis of Mammals'' teeth data';
data teeth;
input mammal $ 1-16
@21 (v1-v8) (1.);
label v1='Top incisors'
v2='Bottom incisors'
v3='Top canines'
v4='Bottom canines'
v5='Top premolars'
v6='Bottom premolars'
v7='Top molars'
v8='Bottom molars';
cards;
BROWN BAT 23113333
MOLE 32103333
SILVER HAIR BAT 23112333
PIGMY BAT 23112233
HOUSE BAT 23111233
RED BAT 13112233
PIKA 21002233
RABBIT 21003233
BEAVER 11002133
GROUNDHOG 11002133
GRAY SQUIRREL 11001133
HOUSE MOUSE 11000033
PORCUPINE 11001133
WOLF 33114423
BEAR 33114423
RACCOON 33114432
MARTEN 33114412
WEASEL 33113312
WOLVERINE 33114412
BADGER 33113312
RIVER OTTER 33114312
SEA OTTER 32113312
JAGUAR 33113211
COUGAR 33113211
FUR SEAL 32114411
SEA LION 32114411
GREY SEAL 32113322
ELEPHANT SEAL 21114411
REINDEER 04103333
ELK 04103333
DEER 04003333
MOOSE 04003333
;
proc princomp data=teeth out=teeth2;
var v1-v8;
run;
proc cluster data=teeth2 method=average outtree=ttree
ccc pseudo rsquare;
var v1-v8;
id mammal;
run;
proc tree data=ttree out=ttree2 nclusters=4;
id mammal;
run;
proc sort data=teeth2;
by mammal;
run;
proc sort data=ttree2;
by mammal;
run;
data teeth3;
merge teeth2 ttree2;
by mammal;
run;
symbol1 c=black f=, v='1';
symbol2 c=black f=, v='2';
symbol3 c=black f=, v='3';
symbol4 c=black f=, v='4';
proc gplot;
plot prin2*prin1=cluster;
run;
proc sort;
by cluster;
run;
proc print;
by cluster;
var mammal prin1 prin2;
run;
4SAS聚類分析案例
1問題背景
考慮下面案例���,一個(gè)棒球管理員希望根據(jù)隊(duì)員們的興趣相似性將他們進(jìn)行分組�。顯然,在該例子中�����,沒有響應(yīng)變量。管理者希望能夠方便地識別出隊(duì)員的分組情況。同時(shí)����,他也希望了解不同組之間隊(duì)員之間的差異性。
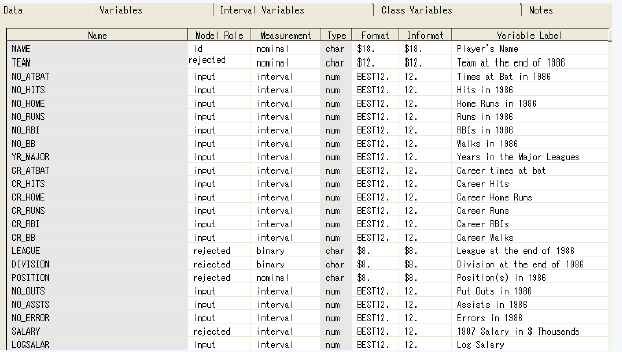
該案例的數(shù)據(jù)集是在SAMPSIO庫中的DMABASE數(shù)據(jù)集���。下面是數(shù)據(jù)集中的主要的變量的描述信息:
在這個(gè)案例中�,設(shè)置TEAM����,POSITION�����,LEAGUE,DIVISION和SALARY變量的模型角色為rejected����,設(shè)置SALARY變量的模型角色為rejected是由于它的信息已經(jīng)存儲在LOGSALAR中。在聚類分析和自組織映射圖中是不需要目標(biāo)變量的����。如果需要在一個(gè)目標(biāo)變量上識別分組,可以考慮預(yù)測建模技術(shù)或者定義一個(gè)分類目標(biāo)��。
2 聚類方法概述
聚類分析經(jīng)常和有監(jiān)督分類相混淆�����,有監(jiān)督分類是為定義的分類響應(yīng)變量預(yù)測分組或者類別關(guān)系�。而聚類分析,從另一方面考慮�,它是一種無監(jiān)督分類技術(shù)�����。它能夠在所有輸入變量的基礎(chǔ)上識別出數(shù)據(jù)集中的分組和類別信息��。這些組�����、簇�,賦予不同的數(shù)字��。然而����,聚類數(shù)目不能用來評價(jià)類別之間的近似關(guān)系。自組織映射圖嘗試創(chuàng)建聚類�,并且在一個(gè)圖上用圖形化的方式繪制出聚類信息,在此處我們并沒有考慮��。
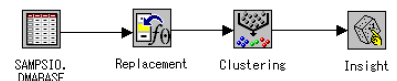
1) 建立初始數(shù)據(jù)流
2) 設(shè)置輸入數(shù)據(jù)源結(jié)點(diǎn)
打開輸入數(shù)據(jù)源結(jié)點(diǎn)
從SAMPSIO庫中選擇DMABASE數(shù)據(jù)集
設(shè)置NAME變量的模型角色為id����,TEAM,POSIOTION��,LEAGUE,DIVISION和SALARY變量的模型角色為rejected
探索變量的分布和描述性統(tǒng)計(jì)信息
選擇區(qū)間變量選項(xiàng)卡��,可以觀察到只有LOGSALAR和SALARY變量有缺失值��。選擇類別變量選項(xiàng)卡�����,可以觀察到?jīng)]有缺失值�。在本例中���,沒有涉及到任何類別變量����。
3) 設(shè)置替代結(jié)點(diǎn)
雖然并不是總是要處理缺失值,但是有時(shí)候缺失值的數(shù)量會影響聚類結(jié)點(diǎn)產(chǎn)生的聚類解決方案����。為了產(chǎn)生初始聚類��,聚類結(jié)點(diǎn)往往需要一些完整的觀測值�����。當(dāng)缺失值太多的時(shí)候����,需要用替代結(jié)點(diǎn)來處理���。雖然這并不是必須的���,但是在本例中使用到了。
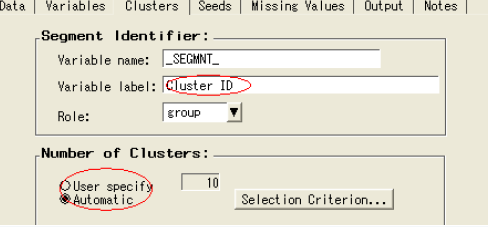
4) 設(shè)置聚類結(jié)點(diǎn)
打開聚類結(jié)點(diǎn)�����,激活變量選項(xiàng)卡���。K-means聚類對輸入數(shù)據(jù)是敏感的����。一般情況下,考慮對數(shù)據(jù)集進(jìn)行標(biāo)準(zhǔn)化處理����。
在變量選項(xiàng)卡,選擇標(biāo)準(zhǔn)偏差單選框
選擇聚類選項(xiàng)卡
觀察到默認(rèn)選擇聚類數(shù)目的方法是自動的
關(guān)閉聚類結(jié)點(diǎn)
5) 聚類結(jié)果
在聚類結(jié)點(diǎn)處運(yùn)行流程圖�����,查看聚類結(jié)果�。
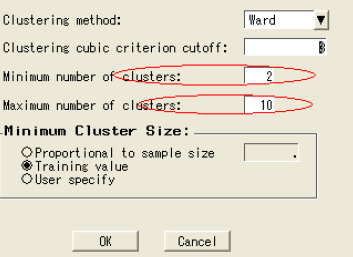
6) 限定聚類數(shù)目
打開聚類結(jié)點(diǎn)
選擇聚類選項(xiàng)卡
在聚類數(shù)目選擇部分���,點(diǎn)擊選擇標(biāo)準(zhǔn)按鈕
輸入最大聚類數(shù)目為10
點(diǎn)擊ok�����,關(guān)閉聚類結(jié)點(diǎn)
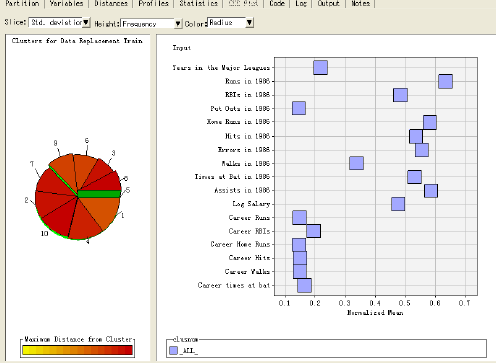
7)結(jié)果解釋
我們可以定義每個(gè)類別的信息�����,結(jié)合背景識別每個(gè)類型的特征�����。選擇箭頭按鈕����,
 選擇三維聚類圖的某一類別,
選擇三維聚類圖的某一類別,
 在工具欄選擇刷新輸入均值圖圖標(biāo)�����,
在工具欄選擇刷新輸入均值圖圖標(biāo)�����,
 點(diǎn)擊該圖標(biāo)�����,可以查看該類別的規(guī)范化均值圖
點(diǎn)擊該圖標(biāo)�����,可以查看該類別的規(guī)范化均值圖
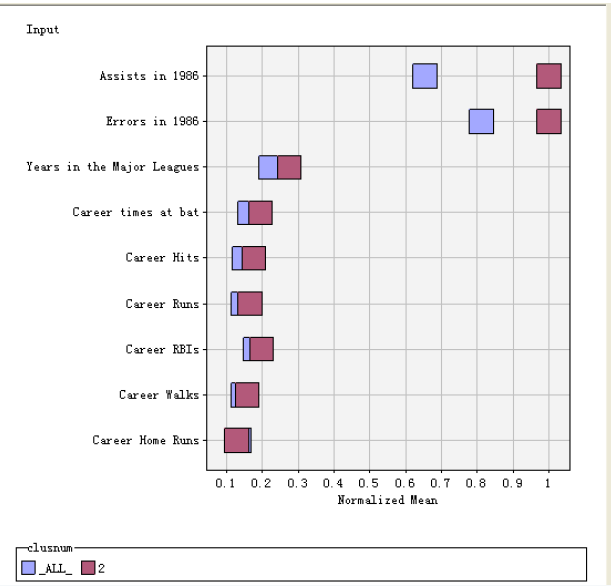
同理�����,可以根據(jù)該方法對其他類別進(jìn)行解釋����。
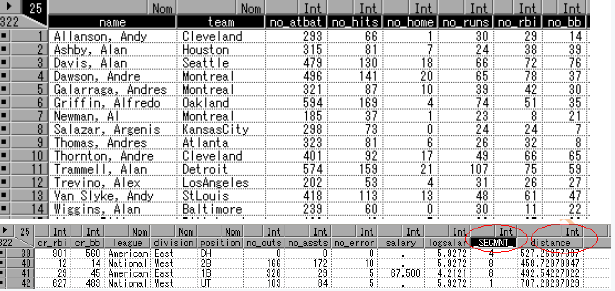
8)運(yùn)用Insight結(jié)點(diǎn)
Insight結(jié)點(diǎn)可以用來比較不同屬性之間的異常。打開insight結(jié)點(diǎn)����,選擇整個(gè)數(shù)據(jù)集,關(guān)閉結(jié)點(diǎn)��。
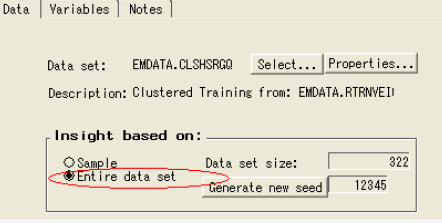 從insight結(jié)點(diǎn)處運(yùn)行。
從insight結(jié)點(diǎn)處運(yùn)行。
變量_SEGMNT_標(biāo)識類別�����,distance標(biāo)識觀測值到所在類別中心的距離�。運(yùn)用insight窗口的analyze工具評估和比較聚類結(jié)果。
首先把_SEGMNT_的度量方式從interval轉(zhuǎn)換成nominal�。
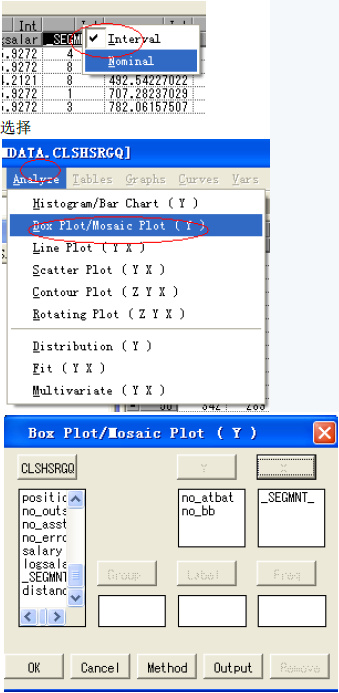
點(diǎn)擊ok即可
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試���,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情��;
? 想學(xué)習(xí)CDA考試教材,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫�,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量����,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330