探索大數(shù)據(jù)背景下的基因研究
基于高性能計算集群這樣的新一代測序器和快速演化分析平臺�,基因研究領域已經(jīng)被海量數(shù)據(jù)淹沒�。眾多基因���、癌癥、醫(yī)學研究機構(gòu)和制藥公司不斷產(chǎn)生的海量數(shù)據(jù)��,已不再能被及時的處理并恰當?shù)拇鎯Γ踔镣ㄟ^常規(guī)通訊線路進行傳輸都
變得困難����。而通常情況下,這些數(shù)據(jù)必須能被快速存儲�����、分析��、共享和歸檔���,以適應基因研究的需要����。于是他們不得不訴諸于磁盤驅(qū)動器及運輸公司��,來轉(zhuǎn)移原始數(shù)
據(jù)到國外的計算中心��,這為快速訪問和分析數(shù)據(jù)帶來了巨大障礙�。與規(guī)模和速度同等重要的是,所有基因組信息都能基于數(shù)據(jù)模型和類別被鏈接���,并以機器或人類語
言進行標注����,這樣智能化的數(shù)據(jù)就能被分解成方程式,在處理基因�����、臨床和環(huán)境數(shù)據(jù)時應用于普通分析平臺�����。
概述
機遇與挑戰(zhàn)并存的基因組醫(yī)學革命
自人類啟動基因組計劃以來�����,各項工程已逐步開始揭示人類基因組與疾病間關聯(lián)的奧秘�����。隨著測序技術的不斷進步�,僅用1000美元即可識別出基因組��。

圖1 基因組醫(yī)學技術進步的十年
人類基因組計劃是首個用來確定人類基因組序列的科研項目���。該項目歷時13年�,耗費近30億美元,于2003年完成����,是目前為止最大的生物學合作項目。從那
時起���,一系列的技術進步在DNA測序和大規(guī)?;蚪M數(shù)據(jù)分析中展露頭腳�����,對單個人類全基因組進行測序的時間和成本隨之急劇下降���,下降速度甚至超過了摩爾定
律�。
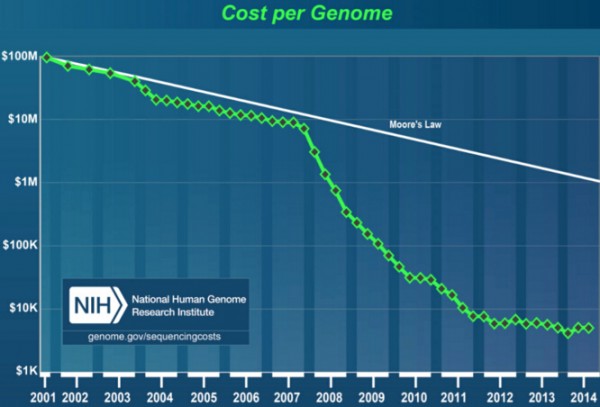
圖2 DNA測序成本的快速下降
(自2001年以來���,美國國家人類基因組研究所(NHGRI)對由美國國立衛(wèi)生研究院(NIH)資助的測序中心所進行的所有DNA測序工作進行了跟蹤���,并
統(tǒng)計了相關費用,這些信息已作為DNA測序的重要改進評估基準����。圖中展現(xiàn)出近年來DNA測序技術和數(shù)據(jù)產(chǎn)生流程的顯著改善�。
作為測序技術進步的一個例子�,Illumina公司在2014年發(fā)布了新一代測序器HiSeq
X10,它以每個基因組僅1000美元的成本�,一年可解密18000個人類全基因組。這個所謂的“千元基因組技術”使人類全基因組測序比以往任何時候更廉
價可行���,并有望對醫(yī)療保健和生命科學行業(yè)產(chǎn)生巨大影響����。
新技術和研究方法的成功同樣帶來了相當大的成本��,海量數(shù)據(jù)成為亟待解決的難題:
基因組數(shù)據(jù)在過去的8年中�,每5個月翻一番。
基因編碼項目為80%的基因組賦予了明確的含義�����,所以獲取全基因組序列變得尤為重要���。
癌癥基因組研究揭示了一組不同的癌細胞基因變體,通過全基因組測序的跟蹤和監(jiān)控����,每次分析都會產(chǎn)生約1TB的數(shù)據(jù)�����。
已有越來越多的國家啟動了基因組測序項目��,如美國�����、英國����、中國和卡塔爾�����。這些項目動輒就會產(chǎn)生數(shù)以百PB級的測序數(shù)據(jù)�。
對端到端架構(gòu)的要求
為了滿足基因醫(yī)藥研究對于速度、規(guī)模和智能化的苛刻要求�,需要端到端參考架構(gòu)涵蓋基因計算的關鍵功能,如數(shù)據(jù)管理(數(shù)據(jù)集線器)���,負載編排(負載編排器)
和企業(yè)接入(應用中心)等����。為了確定參考架構(gòu)(能力與功能)和映射解決方案(硬件與軟件)的內(nèi)容和優(yōu)先級,需要遵循以下三個主要原則:
1.軟件定義: 即基于軟件的抽象層進行計算���、存儲和云服務����,以此定義基礎架構(gòu)和部署模式���,以便在未來通過數(shù)據(jù)量和計算負載的積累進行基因組基礎設施的增長和擴展���。
2.數(shù)據(jù)中心: 以數(shù)據(jù)管理功能面向基因組研究、成像和臨床數(shù)據(jù)的爆炸式增長���。
3.應用就緒: 整合多種應用到一致的環(huán)境���,提供數(shù)據(jù)管理、版本控制�、負載管理、工作流編排�����,以及通過訪問執(zhí)行和監(jiān)控等多種功能���。
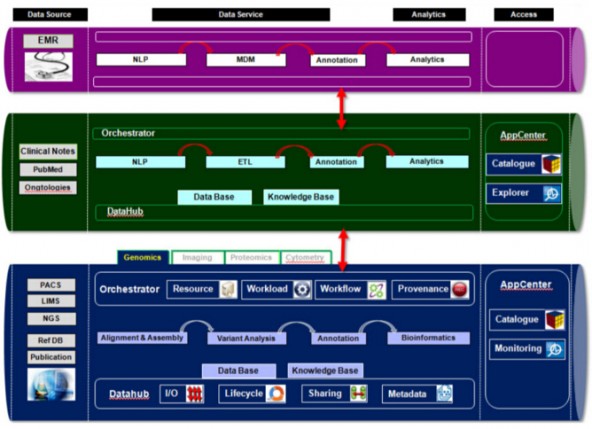
圖3 基因組研究參考架構(gòu)示例
圖中藍色表示基因組研究平臺�����、綠色表示轉(zhuǎn)化平臺�、紫色表示個性化醫(yī)療平臺�����。這三個平臺共享企業(yè)級功能:負責數(shù)據(jù)管理的集線器����、負載負載管理的編排器和負責訪問管理的應用中心。
架構(gòu)部署總體規(guī)劃
架構(gòu)需要以各種基礎設施和信息技術進行部署��。如下是一些部署模型���,以及被映射到數(shù)據(jù)集線器����、負載編排器和應用中心的技術�、解決方案與產(chǎn)品示例�。
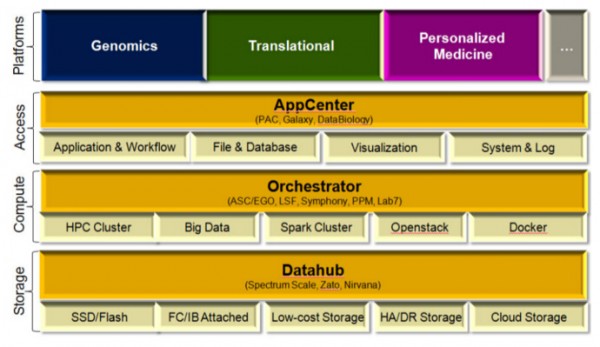
圖4 參考架構(gòu)部署模型
如圖中所示��,存儲基礎技術(固態(tài)硬盤�����、閃存���、普通硬盤�����、云)��,計算(高性能計算��、大數(shù)據(jù)�、Spark��、OpenStack�、Docker)和用戶訪問的信息技術(應用工作流、文件協(xié)議���、數(shù)據(jù)庫查詢����、可視化��、監(jiān)控)由三個企業(yè)功能數(shù)據(jù)集線器��、負載編排器和應用中心統(tǒng)一管理��。
許多解決方案和產(chǎn)品可應用于該模型中成為可部署平臺����,用于基因組研究、數(shù)據(jù)轉(zhuǎn)化和個性化醫(yī)療��,如開源解決方案Galaxy���,IBM頻譜系解決方案GPFS?等�����。
以參考架構(gòu)為藍本增長
對端到端參考架構(gòu)的另一項需求�,是通過集成能被映射到不同需求的各種新舊構(gòu)建塊�,使平臺和基礎設施有機增長,這些構(gòu)建塊可以是不同的類型�����、模式、大小和系
統(tǒng)架構(gòu)�,如獨立服務器、云虛擬機���、高性能計算集群����、低延遲網(wǎng)絡�����、擴展型存儲系統(tǒng)�����、大數(shù)據(jù)集群����、磁帶歸檔或元數(shù)據(jù)管理系統(tǒng)等等。對于可融入架構(gòu)的構(gòu)建塊���,需
遵循行業(yè)標準化數(shù)據(jù)格式��,通用軟件框架和硬件協(xié)同操作性三項標準��,這樣實施和擴展基因組基礎設施可以多種靈活的方式進行:
小規(guī)模起步: 由于是基于軟件定義����,如果關鍵能力和功能到位�����,為符合有限的預算���,系統(tǒng)��、平臺和基礎設施可以相當小�。例如��,臨床測序?qū)嶒炇铱刹渴鹨粋€僅由1至2個服務器組成的小型系統(tǒng)��,并提供少量磁盤存儲和關鍵軟件進行管理�。
快速增長:
由于計算和存儲的增長,已有的基礎設施可在不中斷操作的情況下迅速擴展到很大規(guī)模����。如2013年底���,錫德拉灣醫(yī)療研究中心建立了屬于它們自己的基因組研究
基礎設施,隨后通過參考架構(gòu)添加了一個新的構(gòu)建塊(60個節(jié)點的高性能計算集群)��,最終于2014年中期將存儲基礎設施增加了三倍��。這一健壯的能力使得錫
德拉灣成為阿拉伯卡塔爾基因項目的基礎設施供應者�。
跨地域分布: 這是高性能計算領域近期出現(xiàn)的新功能,即數(shù)據(jù)的共享和聯(lián)合特性:數(shù)據(jù)和計算資源被部署在不同的位置�����,與此同時仍可供用戶��、應用和工作流訪問��。在參考架構(gòu)中���,數(shù)據(jù)集線器和負載編排器與此緊密相關���。
很多全球領先的醫(yī)療保健和生命科學機構(gòu)都在積極探索這樣的架構(gòu),以支持他們的綜合研究計算基礎設施����。下面的章節(jié)��,將闡述此類參考架構(gòu)的關鍵部件�、各種最佳實踐及項目經(jīng)驗���。
數(shù)據(jù)集線器
數(shù)據(jù)管理是基因組研究平臺最根本的能力�,因為海量的數(shù)據(jù)需要在正確的時間和地點以恰當?shù)某杀具M行處理�����。時間方面���,可以是在高性能計算系統(tǒng)中進行數(shù)小時的數(shù)
據(jù)分析,如果數(shù)據(jù)需要從存儲歸檔中調(diào)出進行再分析��,可能需要數(shù)年的時間�。空間方面���,可以在當?shù)氐幕A設施間實施近線存儲��,或是云端遠程物理存儲�����。
數(shù)據(jù)管理的挑戰(zhàn)
大數(shù)據(jù)的四個V恰恰是基因組數(shù)據(jù)管理的挑戰(zhàn):非常大的數(shù)據(jù)流和容量(數(shù)據(jù)量Volume)�����,苛刻的I/O速度和吞吐量要求(數(shù)據(jù)存取速度
Velocity)��,快速進化的數(shù)據(jù)類型和分析方法(數(shù)據(jù)多樣性Variety)���,以及共享能力和探索大量數(shù)據(jù)的環(huán)境和可靠性(數(shù)據(jù)置信度
Veracity)����。此外���,還有法規(guī)(患者數(shù)據(jù)隱私與保護)�,種源管理(全版本控制與審計跟蹤)和工作流編排等額外的需求�,使數(shù)據(jù)管理難上加難。
數(shù)據(jù)量
基因組數(shù)據(jù)因測序成本的急劇下降不斷涌現(xiàn)��,對于配備了新一代測序技術的學術醫(yī)學研究中心AMRC����,數(shù)據(jù)存儲容量每6至12個月翻一番已變得司空見慣。
AMRC作為紐約的尖端研究機構(gòu),于2013年以300TB的數(shù)據(jù)存儲能力起步����,截至2013年底,存儲量激增超過1PB(1000TB)�,超12個月前
存儲總量三倍。更令人吃驚的是�,這一增長仍在加速并一直延續(xù)至今。對一些世界領先的基因組醫(yī)藥項目�,如英格蘭基因組(英國)、沙特阿拉伯基因組(卡塔
爾)����、百萬精英項目(美國)以及中國國家基因庫等,數(shù)據(jù)量的起點或基準都不再以千兆字節(jié)(TB)計���,而是成百上千拍字節(jié)(PB)。
數(shù)據(jù)存取速度
基因組平臺對數(shù)據(jù)存取速度的需求非??量蹋蛴腥c:
1.文件非常大
:在基因研究中�,文件通常用來存放研究對象的基因組信息,它可以是單個患者的�����,亦或是一組患者的。主要有兩種類型:二進制隊列或圖即BAM(由基因組序列
比對產(chǎn)生)和變型調(diào)用文件即VCF(處理后得到的基因變型)����,此類文件往往大于1TB,可占用典型基因組數(shù)據(jù)倉庫存儲總量的一半����。此外,通過擴大研究范
圍�,使用更高的覆蓋分辨率,可得出更多的基因組信息(如30至100倍全基因組)����,這會使存儲文件迅速增大。由于基因組研究通常從對罕見變異的研究(單個
病人變異提取)演變?yōu)槌R娮儺愌芯?���,于是出現(xiàn)了一種新的需求:共享成千上萬患者的提取樣本。以布羅德研究所提供的一個假設為例:對于57000個共享提取
的樣品�,BAM輸入文件有1.4PB,而VCF輸出文件有2.35TB���,兩者以現(xiàn)有水準衡量都是海量數(shù)據(jù)�,但可能在不久的將來變得很普遍�����。
2.小文件很多:
此類文件用于存儲原始或臨時的基因組信息,如測序器輸出(像Illumina公司的BCL格式文件)�。它們通常小于64KB,可占典型基因組數(shù)據(jù)倉庫文件
數(shù)量一半以上�����。與處理大文件不同�,因為每個文件的I/O都需要對數(shù)據(jù)和元數(shù)據(jù)進行兩次操作,生成和訪問大量文件的負載會非常大����,如果按每秒操作數(shù)
(IOPS)衡量速度,底層存儲系統(tǒng)的IOPS可達數(shù)百萬次���。由此可以想到�,對于AMRC在圣地亞哥的基礎設施�����,未曾對小文件處理的存儲做過任何優(yōu)化����,諸
如BCL轉(zhuǎn)換(像Illumina公司的CASAVA算法)這樣的負載會因基礎設施有限的I/O能力(尤其是IOPS),導致計算資源枯竭而最終癱瘓�。基
準測試證實���,因計算能力浪費在等待數(shù)據(jù)就位上����,CPU效率會下降至個位數(shù)�。為了緩解這種計算瓶頸,需要使用數(shù)據(jù)緩存技術將I/O操作從磁盤轉(zhuǎn)移到內(nèi)存�。
3.并行和工作流操作:
為提高性能、加快時間���,基因組計算通常以編排好的工作流批量進行��。從小范圍目標測序到大范圍全基因組測序�,為使負載在快速運轉(zhuǎn)中發(fā)揮更高效能���,并行操作不
可或缺�����。隨著成百上千種不同的負載在并行計算環(huán)境中同時運行�,以I/O帶寬和IOPS衡量的存儲速度將不斷累積并爆發(fā)式增長。紐約AMRC的生物信息學應
用可并發(fā)運行在2500個計算核心��,以每秒寫一個文件的速度創(chuàng)建百萬級數(shù)據(jù)對象�,無論是2500個目錄、每個目錄2500個文件���,亦或是一個目錄中的
1400萬個文件都能被及時處理�����。而對于一個擁有6億對象�、900萬目錄�����、每個目錄僅含一個文件的數(shù)據(jù)倉庫���,這僅僅是其眾多負載中的一小部分�����。由于元數(shù)據(jù)
是海量的���,IOPS負荷會約束整體性能,即使一個列出文件的系統(tǒng)命令(如Linux的ls)也不得不耗費幾分鐘的時間才能完成���,并行應用程序如GATK隊
列也遭遇了這種低性能���。2014年初,文件系統(tǒng)以改善元數(shù)據(jù)基礎結(jié)構(gòu)為著眼點進行了大幅修正���,帶寬和IOPS性能均得到顯著改善��,基準測試顯示���,在沒有任
何應用程序調(diào)整的情況下,基因疾病應用程序的計算加速了10倍���。
數(shù)據(jù)多樣性
按存儲和訪問方式����,數(shù)據(jù)格式可有多種類型�,如多步工作流生成的中間文件,亦或是一些輸出文件�,其中包含維持生命必需的基因組信息參考數(shù)據(jù),而這些數(shù)據(jù)需要
謹慎的進行版本控制��。目前常規(guī)的方法是,不考慮費用��,在一個存儲層把所有數(shù)據(jù)在線或近線存儲�����,這樣做會導致大數(shù)據(jù)生命周期管理能力的缺失�。如果基因組數(shù)據(jù)
倉庫要用很長時間掃描文件系統(tǒng),遷移或備份就不可能及時被完成���。一家美國大型基因組中心�����,在采用了Illumina公司的X10全基因組測序算法后���,一直
掙扎于如何管理快速增長的數(shù)據(jù)。目前他們完成整個文件系統(tǒng)的掃描需要四天���,使得每日或更長一點時間的備份變得不可能���。其結(jié)果是,數(shù)據(jù)在單層存儲快速堆積,
元數(shù)據(jù)掃描性能不斷下降�,導致數(shù)據(jù)管理惡性循環(huán)。
另一個新的挑戰(zhàn)是數(shù)據(jù)位置的管理���。由于機構(gòu)間的合作變得越來越普遍,大量的數(shù)據(jù)需要共享或聯(lián)合�����,這使得地理位置成為數(shù)據(jù)不可缺少的一個特征�����。同樣的數(shù)據(jù)
集��,特別是參照數(shù)據(jù)或輸出數(shù)據(jù)���,可以在不同地理位置存在多個拷貝����,或者因法規(guī)要求在同一位置存在多個拷貝(如因臨床測序平臺與研究機構(gòu)物理隔離產(chǎn)生的多重
數(shù)據(jù)副本)�����。在這種情況下,有效的管理元數(shù)據(jù)以減少數(shù)據(jù)移動或復制����,不僅能降低額外存儲所需成本,還能減少版本同步帶來的問題����。
數(shù)據(jù)置信度
許多復雜的身心機能失調(diào),如糖尿病����、肥胖、心臟病��、阿爾茨海默氏癥和自閉癥譜系障礙等�����,要研究它們的多因素特性����,需要在廣泛的來源中實施縝密復雜的計算,
統(tǒng)計分析大流量數(shù)據(jù)(基因組����、蛋白質(zhì)組����、成像)和觀察點(臨床�、癥狀、環(huán)境����、現(xiàn)實證據(jù))。全球數(shù)據(jù)共享和網(wǎng)絡聯(lián)合保證了訪問和分析數(shù)據(jù)的進程以前所未有的
規(guī)模和維度不斷創(chuàng)新和智能化�����,數(shù)據(jù)庫和文件倉庫的進化也由此相互關聯(lián)在一起���。在這樣的前提下,數(shù)據(jù)置信度作為一個不可或缺的元素在研究中得以被考量���。例
如��,臨床數(shù)據(jù)(基因組和成像)需要被恰當和完整的標識以保護研究課題的機密性�?��;蚪M數(shù)據(jù)需要端到端的溯源以提供完整的審計跟蹤和可重復能力�。數(shù)據(jù)的著作
權和所有權需要由一個多用戶協(xié)作機構(gòu)恰當申明。借助內(nèi)置特性處理數(shù)據(jù)準確性�,基因組計算機構(gòu)可以讓研究人員和數(shù)據(jù)科學家根據(jù)上下文和置信度分享和探討大量
數(shù)據(jù)。
數(shù)據(jù)集線器的功能
為了解決基因組數(shù)據(jù)管理中遇到的問題�����,構(gòu)建一個可伸縮�����、可擴展層提供數(shù)據(jù)和元數(shù)據(jù)給負載����,這樣的企業(yè)級功能可被命名為數(shù)據(jù)集線器。它可以存儲�����、移動���、共享和索引海量基因組的原始和處理后數(shù)據(jù)���。它還管理著從固態(tài)硬盤或閃存到磁盤、磁帶�����、以及云的底層異構(gòu)存儲結(jié)構(gòu)。
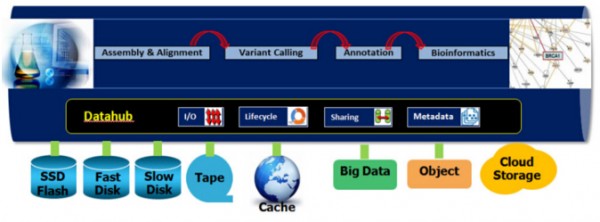
圖5 數(shù)據(jù)集線器概述
作為提供數(shù)據(jù)和元數(shù)據(jù)給所有負載的企業(yè)級功能��,它定義了一個可伸縮���、可擴展層把所有的存儲資源虛擬化��、全球化到一個全局命名空間�����,旨在提供四個主要功能:
1.高性能的數(shù)據(jù)輸入與輸出(I/O)
2.策略驅(qū)動的信息生命周期管理(ILM)
3.通過緩存和必要的復制高效分享數(shù)據(jù)
4.大型元數(shù)據(jù)管理
對于物理部署,它支持越來越多的存儲技術作為模塊化構(gòu)建塊�����,例如:
固態(tài)硬盤和閃存存儲系統(tǒng)
高性能快速存儲磁盤
大容量慢速磁盤(每驅(qū)動器4TB)
高密度低成本磁帶庫
可本地或全局分布的外部存儲緩存
基于Hadoop的大數(shù)據(jù)存儲
基于云的外部存儲
四個功能可分別映射到數(shù)據(jù)集線器:
1.I/O管理:
針對大型和可擴展I/O���,有兩個方面的能力����。一是服務像BAM這種大文件的I/O帶寬��,二是服務像BCL和FASTQ這種大量小文件的IOPS。由于這些
不同的需求����,傳統(tǒng)的額定量架構(gòu)很難勝任性能和規(guī)模需求。數(shù)據(jù)集線器I/O管理通過引入池的概念��,將小文件元數(shù)據(jù)的I/O操作與大文件的操作分離�,解決了這
一問題。這些存儲池����,在映射到不同底層硬件,提供最佳存儲性能的同時�,仍能在文件系統(tǒng)級達到統(tǒng)一,對所有數(shù)據(jù)和元數(shù)據(jù)提供唯一的全局命名空間�,并對用戶透
明。
2.生命周期管理:
對數(shù)據(jù)被創(chuàng)建�����、刪除和保存的整個生命周期進行全線管理��。如果以溫度作比喻來描述數(shù)據(jù)需要被捕獲���、處理�、遷移和歸檔的階段和及時性。使用像高通量測序儀這樣
的工具捕獲而來的原始數(shù)據(jù)溫度最高���,并需要有健壯I/O性能的高性能計算集群(所謂的原始存儲)來處理�����。初步處理后���,原始和處理后數(shù)據(jù)變得暖起來,因為它
會采取一個基于策略的過程�����,以確定最終操作���,如刪除、保留在一個長期存儲池或存檔等���。這個過程會在帳戶文件中記錄文件類型���、大小、使用情況(如用戶最后訪
問的時間)和系統(tǒng)使用信息����。任何符合操作需求的文件要么被刪除�����,要么從一個存儲池遷移到另一個��,比如一個更大容量��、但低效率且廉價的存儲池����。這種目標層可
以是一個磁帶庫����,通過配備存儲池和諸如磁帶這樣的低成本介質(zhì),可高效利用底層存儲硬件并顯著降低成本���。
3.共享管理:
針對存儲設施邏輯域內(nèi)部和之間數(shù)據(jù)共享的需求�����。隨著基因組樣品和參考數(shù)據(jù)集變得更大(某些情況下每負載工作量可超1PB)�����,為了共享和協(xié)作��,移動和復制數(shù)
據(jù)變得越發(fā)困難��。為最小化數(shù)據(jù)復制對數(shù)據(jù)共享造成的影響���,數(shù)據(jù)集線器在共享管理下需要具備三個特點����,從而使數(shù)據(jù)共享和移動可發(fā)生在私有高性能網(wǎng)絡或廣域
網(wǎng)���,并高度依賴安全和容錯性����。
(1)多集群存儲: 即計算集群可直接訪問遠程系統(tǒng)并按需要存取數(shù)據(jù)��。
(2)云數(shù)據(jù)緩存: 即特定數(shù)據(jù)倉庫(主機)的元數(shù)據(jù)索引和全數(shù)據(jù)集��,可被有選擇的異步緩存到遠程(客戶端)系統(tǒng)����,以實現(xiàn)本地快速訪問��。
(3)聯(lián)合數(shù)據(jù)庫: 可使分布式數(shù)據(jù)庫間安全聯(lián)合。
4.元數(shù)據(jù)管理:
此功能為前面三點提供了基礎�����。存儲�����、管理和分析數(shù)十億數(shù)據(jù)對象對任何數(shù)據(jù)倉庫而言都是必須具備的能力�����,尤其是擴展超出PB級的數(shù)據(jù)倉庫�,而這正成為基因組
基礎設施的發(fā)展趨勢。元數(shù)據(jù)包括系統(tǒng)元數(shù)據(jù)�����,如文件名���、路徑�����、大小�����、池名稱��、創(chuàng)建時間��、修改或訪問時間等�,也涵蓋以鍵值對形式存在的自定義元數(shù)據(jù),這樣被
應用程序��、工作流或用戶所使用的文件可與之創(chuàng)建關聯(lián)���,從而用于實現(xiàn)以下目標�����。
基于大小���、類型或使用情況放置和移動文件以方便I/O管理。
基于對元數(shù)據(jù)的閃電掃描收集信息��,啟用基于策略的數(shù)據(jù)生命周期管理�����。
啟用數(shù)據(jù)緩存����,使元數(shù)據(jù)可輕量分布并弱依賴于網(wǎng)絡。
數(shù)據(jù)集線器解決方案和應用案例
頻譜規(guī)模的特性是高性能���、可伸縮和可擴展�����,它專為高性能并行計算優(yōu)化而研發(fā)�,在計算系統(tǒng)的所有并聯(lián)計算節(jié)點之間����,頻譜規(guī)模可服務于高帶寬大數(shù)據(jù)����。鑒于基因
組工作流可由數(shù)百個應用程序組成,同時這些應用參與著大量文件的并行數(shù)據(jù)處理�����,這種能力對計算基因工作流提供數(shù)據(jù)而言至關重要。
因為基因組工作流可產(chǎn)生大量元數(shù)據(jù)和數(shù)據(jù)����,以高IOPS固態(tài)硬盤和閃存構(gòu)建系統(tǒng)池的文件系統(tǒng),可專注于把元數(shù)據(jù)存儲為文件和目錄�,在某些情況下也可直接存儲為小文件。這大大提高了文件系統(tǒng)的性能和大負荷元數(shù)據(jù)操作的響應能力����,如列出目錄中的所有文件。
對于可進行大數(shù)據(jù)并行計算的文件系統(tǒng)���,數(shù)據(jù)集線器可在同一計算節(jié)點服務于大數(shù)據(jù)并行計算和大數(shù)據(jù)作業(yè)���,從而省去了Hadoop分布式文件系統(tǒng)(HDFS)的復雜需求。
基于策略的數(shù)據(jù)生命周期管理能力允許數(shù)據(jù)集線器把數(shù)據(jù)從一個存儲池移動到另一個���,最大化I/O性能和存儲效率�,并有效減少運營成本�。這些存儲池的范圍可涵蓋高I/O閃存盤、大容量存儲基礎設施��,以及繼承了磁帶管理解決方案的低成本磁帶介質(zhì)����。
基因組研究基礎設施的日益分散性也要求更大甚至全球規(guī)模上的數(shù)據(jù)管理��。數(shù)據(jù)不僅需要在不同的地點移動或共享�����,還需與負載和工作流相協(xié)調(diào)。為實現(xiàn)這一目標���,
數(shù)據(jù)集線器依賴頻譜規(guī)?;顒游募芾?AFM)進行共享�。AFM可擴展全局命名空間到多個站點,允許共享元數(shù)據(jù)目錄或映射遠程客戶端家目錄到本地作為緩存
副本���。如基因組研究中心可擁有���、運營和版本控制所有的參考數(shù)據(jù)庫或數(shù)據(jù)集,而附屬�、合作網(wǎng)站或中心可通過這種共享功能訪問參考數(shù)據(jù)集。當數(shù)據(jù)庫的核心副本
得到更新�,其他站點的緩存副本也會迅速更新。
有了數(shù)據(jù)集線器�����,全系統(tǒng)元數(shù)據(jù)引擎還可用來索引和搜索所有的基因組和臨床數(shù)據(jù),以挖掘出強大的下游分析和轉(zhuǎn)化研究能力���。
負載編排器
本節(jié)介紹基因組負載編排所面臨的挑戰(zhàn)����,并利用編排工具幫助減少負載管理工作��。
基因組負載管理的挑戰(zhàn)
基因組負載管理是非常復雜的���。隨著基因組應用程序越來越多���,它們的成熟度和編程模型也不斷分化:許多是單線程(如R)或易并行(如BWA)的,也有的是多
線程或啟用了MPI的(如MPI BLAST)����。但相同的是,所有應用程序都需要在高吞吐量��、高性能模式下工作��,以產(chǎn)生最終結(jié)果���。
編排功能
通過編排工具����,可以編排資源、負載和工作流�����。負載管理器和工作流引擎�,可以鏈接和協(xié)調(diào)一系列頻譜級計算和分析作業(yè)到易構(gòu)建�、可自定義、可共享�����、可通用平臺運行的全自動工作流��,為具有GPU高性能計算集群或云端大數(shù)據(jù)集群的底層基礎設施提供必要的應用抽象��。
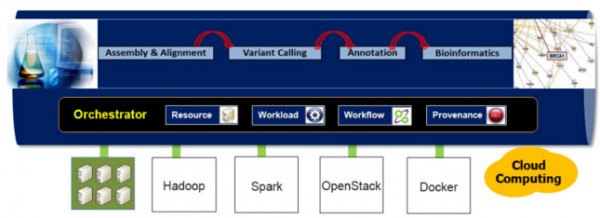
圖6 負載編排器概述
編排器是企業(yè)級功能����,可用來編排資源、負載和管理追溯��,被設計為以下四個主要功能:
1.資源管理:按需求動態(tài)、彈性的分配計算資源�。
2.負載管理:通過分配作業(yè)到本地或遠程集群等不同計算資源,有效進行負載管理�����。
3.工作流管理:通過邏輯和自動化流程把應用程序聯(lián)系在一起�����。
4.溯源管理:關聯(lián)元數(shù)據(jù)記錄和保存負載和工作流��。
基于工作流邏輯和應用需求(如架構(gòu)����、CPU、內(nèi)存�、I/O),通過映射和分配負載到有彈性的異構(gòu)資源(如HPC��、Hadoop����、Spark、OpenStack/Docker、Cloud)�����,編排器在不同的計算基礎設施和高速增長的基因組計算數(shù)組間定義出抽象層�。
資源管理器
該功能以策略驅(qū)動的方式分配計算資源,以滿足基因組負載的計算需求���。最常用的資源是高性能計算裸機集群(HPC)���。該資源管理器提供一次性資源,或可動態(tài)
轉(zhuǎn)換和分配的資源����。如果說數(shù)據(jù)集線器I/O管理提供了存儲服務層��,那么可以認為資源管理器提供了計算服務�����。此外��,新型的基礎設施可被添加到資源池����,包括大
數(shù)據(jù)Hadoop集群�、Spark集群���、OpenStack虛擬機集群和Docker集群�。
基于負載信息管理轉(zhuǎn)換資源是對資源管理器的基本需求�。例如,對于被批量比對作業(yè)和Spark機器學習作業(yè)共用的基因組基礎設施�,在運行時負載會產(chǎn)生波動,資源管理器能通過感知利用率轉(zhuǎn)移資源���,以計算槽或容器的形式支持各作業(yè)的運行�����。
負載管理器
基因組計算資源需要在資源管理器的控制下有效共享����、使用并提供最佳性能給基因組應用程序�����。負載管理器能處理要求苛刻的��、分布式的關鍵任務應用程序,如
Illumina公司的ISSAC��,CASAVA���,bcltofastq�,BWA��,Samtools����,SOAP(短寡核苷酸分析軟件包)以及GATK。負
載管理器還需要高度可擴展和可靠性以管理批量提交的大型作業(yè)�,這是中大型基因組計算機構(gòu)的通用需求。例如紐約一家醫(yī)學院的基因組計算集群通常需要處理含
25萬個作業(yè)的排隊系統(tǒng)��,其間不能崩潰或當機�。世界上一些大型的基因組中心,負載管理器隊列有時會存在上百萬個作業(yè)�����。對于成熟度不同����、架構(gòu)需求(如
CPU,GPU����,大內(nèi)存,MPI等)也不同�、且日益增加的基因組研究應用程序,負載管理器提供了必要的資源抽象使作業(yè)可在提交�、放置、監(jiān)控和記錄時保持對
用戶透明���。
工作流引擎
針對基因組的工作流程管理��,工作流引擎致力于把作業(yè)連接為一個邏輯網(wǎng)絡����。該網(wǎng)絡可按多個步驟讓計算流線性開展���,比如序列對齊���、組合、然后變形提取�,也可以基于用戶定義的標準和完成條件以更加復雜的分支來運行。
編排器工作流引擎需要動態(tài)��、快速的復雜工作流處理能力。獨立的負載和作業(yè)可通過用戶界面���,結(jié)合變量����、參數(shù)和數(shù)據(jù)被定義到標準工作流模板����。有許多負載類型可
被集成到工作流引擎,如并行高性能計算應用程序���,大數(shù)據(jù)應用程序�,或者分析負載的R腳本��。在被定義和驗證后���,用戶可使用該模板從他們的工作站直接啟動工作
流,或者發(fā)布至企業(yè)站點為他人所用����。
工作流編排引擎還需提供以下功能:
1.作業(yè)數(shù)組: 最大限度提高基因組測序分析工作流的吞吐量�����,特殊類型的負載可按作業(yè)數(shù)組劃分為多個并行作業(yè)來處理。
2.子流程: 可定義多個子流程���,用來在基因組比對后并行進行變型分析�����,每個子流程的結(jié)果可合并為單一輸出供分析師以多種工具進行比對�。
3.可重用的模塊: 工作流也可被設計為一個模塊�,作為動態(tài)構(gòu)建塊嵌入更大的工作流。這樣不僅能有效構(gòu)建和重用工作流����,也能幫助大型科研機構(gòu)用戶更好的協(xié)同共享基因組工作流。
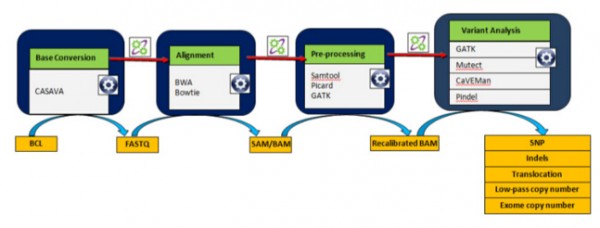
圖7 用編排器集成的基因組工作流
圖中從左至右依次有以下部件:
框1:數(shù)據(jù)(如BCL文件)到達后自動觸發(fā)CASAVA作為工作流第一步���。
框2:動態(tài)子流使用BWA比對序列����。
框3:Samtool以作業(yè)數(shù)組的運行方式進行后處理��。
框4:不同的變型分析子流并行被觸發(fā)�����。
基因組工作流結(jié)合一些應用程序和工具,把原始序列數(shù)據(jù)(BCL)處理為變型(VCF)數(shù)據(jù)����。每個框表示一個工作流功能模塊,它由映射到功能的基因組應用程
序組成����,如基因組堿基轉(zhuǎn)換、序列比對�����、前處理�、以及變型提取和分析。這些模塊自身可作為獨立工作流被集成����,并按照邏輯和條件關系被連接到一個更大的工作流
中。
隨著越來越多的機構(gòu)以分布式資源部署混合云解決方案���,編排器可基于數(shù)據(jù)位置預定義策略���、臨界值和資源有效性實時輸入來均衡負載�。如工作流可被設計用于處理
基因組原始數(shù)據(jù)�����,以使其更切合測序器需要�,并使用遠程大數(shù)據(jù)集群的MapReduce模型進行序列比對和組合;也可設計為當基因處理達50%完成率時�,觸
發(fā)代理事件把數(shù)據(jù)從衛(wèi)星系統(tǒng)轉(zhuǎn)移到中央高性能計算集群,從而使數(shù)據(jù)遷移和計算可并發(fā)進行以節(jié)省時間和成本���。
由研究機構(gòu)發(fā)布基因組流程與他人共享��,是對另一個編排器的需求����。由于工作流模板可被保存和分發(fā)����,一些美國和卡塔爾的主要癌癥和醫(yī)學研究機構(gòu)已開始通過交換基因組工作流進行合作。
溯源管理
有許多計算方法和應用可應用于收集���、分析和注釋基因組序列�����。應用程序��、基準數(shù)據(jù)和運行時變量是重要的溯源信息�,它們可對基因組分析的解讀和維護產(chǎn)生重要影
響。目前����,很少用不公開標準或慣例來捕捉溯源信息,因為它可能導致重要計算分析數(shù)據(jù)的缺失�。這個問題同樣潛伏在其他因素中,例如以復雜數(shù)據(jù)���、工作流程或渠
道作為高層次分析過程����,或者所用的應用程序頻繁發(fā)布更新���。
因此����,溯源管理成為編排器需要的一個可與數(shù)據(jù)集線器元數(shù)據(jù)管理功能相媲美重要功能�。溯源數(shù)據(jù)也可被理解為負載元數(shù)據(jù),溯源管理器的功能需求是捕捉、存儲和索引用戶定義的溯源數(shù)據(jù)�����,以透明無中斷的方式追溯到任何已有的計算負載或工作流�。
基于這樣的需求,多種技術和解決方案正在研發(fā)�,有些已經(jīng)完成并已投入商用���,如Lab7的ESP平臺和General Atomics的Nirvana���。IBM也致力于開發(fā)了一種用于大規(guī)模、近實時的元數(shù)據(jù)管理系統(tǒng)��,可與數(shù)據(jù)集線器和編排器協(xié)同工作�。
應用中心
概述
應用中心是訪問數(shù)據(jù)集線器和負載編排器的用戶接口。它基于角色訪問和安全控制提供了一個企業(yè)門戶��,使研究人員��、數(shù)據(jù)科學家��、臨床醫(yī)生方便的訪問數(shù)據(jù)����、工具�����、應用程序和工作流��。它的目標是讓沒有計算機編程經(jīng)驗的研究員和數(shù)據(jù)科學家能使用復雜的基因組研究平臺����。
應用中心具有可重用優(yōu)勢�����,可作為個性化轉(zhuǎn)型基因醫(yī)藥平臺的組成部分��。
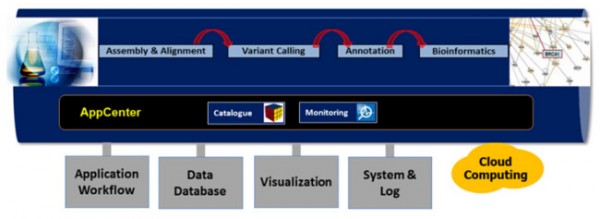
圖8 應用中心概述
圖中描述了啟動和監(jiān)測負載�,查詢和瀏覽數(shù)據(jù),可視化分析輸出����,以及跟蹤系統(tǒng)日志和使用信息等環(huán)節(jié)。它定義了用戶(研究人員���,醫(yī)生和分析師)和數(shù)據(jù)集線器與負載編排器間的抽象層���。
對應用中心要求
對應用中心的要求包括如下兩點:
1.基于站點的目錄功能:它可訪問應用程序�、工作流和數(shù)據(jù)集�,并將它們可視化。
2.監(jiān)測功能:可監(jiān)測����、跟蹤、報告和管理特定應用信息���。
基于站點的目錄功能
數(shù)據(jù)科學家通常想直觀訪問基因組工作流和數(shù)據(jù)集���,而基因組分析通常極其復雜���,為最大限度消除兩者之間的障礙��,應用中心目錄應運而生��。它提供了預編譯和預驗證的應用程序模板和工作流定義����,用戶能簡單直接啟動站點中的作業(yè)或工作流���。
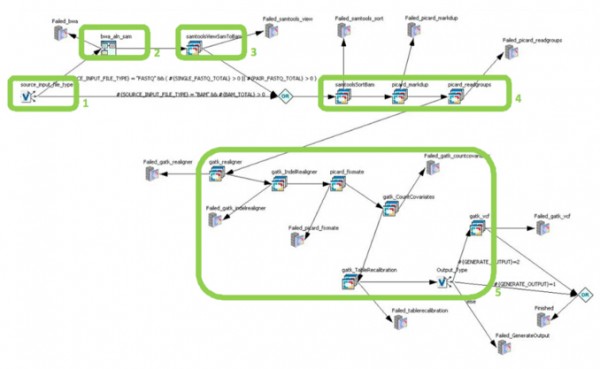
圖9 應用中心基因組工作流
圖中表示了端到端基因組工作流(BWA-GATK)���,通過應用中心站點被啟動并可視化����,從左側(cè)開始依次為:
框1:數(shù)據(jù)到達后自動觸發(fā)工作流開始工作����。
框2:使用BWA進行序列比對的動態(tài)子流。
框3:使用Samtool進行作業(yè)數(shù)組后處理���。
框4:BAM文件再校準���。
框5:GATK進行變型提取。
應用中心目錄可用云數(shù)據(jù)瀏覽器進行配置�����,來管理基因組計算需要的數(shù)據(jù)���。在基于站點的瀏覽器中�,用戶可通過瀏覽和搜索所有遠程或本地存儲服務器(數(shù)據(jù)集線
器)的文件和目錄找到基因組數(shù)據(jù)��。無論文件在哪里,都可以追加文件啟動作業(yè)����。使用數(shù)據(jù)瀏覽器,用戶可通過標記文件目錄快捷的找到它�。例如,一個為基因組計
算用戶標記的可用目錄能用來存儲經(jīng)常訪問的參考數(shù)據(jù)集�����。
最后��,數(shù)據(jù)瀏覽器也可以方便數(shù)據(jù)傳輸���,用戶可把文件從瀏覽器桌面拖放到當前遠程目錄以同時上傳多個文件���。
實時監(jiān)控
應用中心監(jiān)控還需提供了一個基于門戶的儀表板�����,提供全面的負載監(jiān)控��、報告和管理功能����。作為監(jiān)控工具���,不僅單方面專注于系統(tǒng)監(jiān)控,還提供完整的���、集成化的負
載監(jiān)控設施���。通過基因組應用程序的多樣化配置(如大內(nèi)存、并行或單線程)���,跟蹤和匯總同作業(yè)與應用程序相關的計算機CPU�����、內(nèi)存和存儲I/O實用信息����,幫
助提高應用程序效率���。
結(jié)束語
為了滿足基因研究對于速度�、規(guī)模和智能化的苛刻需求���,面向負責創(chuàng)建和提供生命科學解決方案的專業(yè)技術人員(如科學家����,咨詢顧問,IT架構(gòu)師和IT專家
等)���,該領域出現(xiàn)的端到端參考架構(gòu)正結(jié)合各種基礎設施和信息技術被部署到越來越多的研究機構(gòu)中�,而基于這種架構(gòu)的客戶和合作伙伴生態(tài)系統(tǒng)也在不斷生長����,逐
步豐富著相應的解決方案和產(chǎn)品。隨著技術的發(fā)展�,基因藥物有望徹底改變生物醫(yī)學研究和臨床護理。結(jié)合生物學途徑�、藥物相互作用機理及環(huán)境因素對人類基因進
行研究,使得基因科學家和臨床醫(yī)生有可能識別疾病高危人群����,為他們提供基于生化標志的早期診斷,并推薦有效的治療方法��。
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330