數(shù)據(jù)分析:數(shù)據(jù)清洗的一些梳理
數(shù)據(jù)清洗��, 是整個數(shù)據(jù)分析過程中不可缺少的一個環(huán)節(jié)����,其結果質量直接關系到模型效果和最終結論���。在實際操作中,數(shù)據(jù)清洗通常會占據(jù)分析過程的50%—80%的時間��。國外有些學術機構會專門研究如何做數(shù)據(jù)清洗�����,相關的書籍也不少�����。
(美亞搜data cleaning的結果���,可以看到這書還挺貴)
我將在這篇文章中�,嘗試非常淺層次的梳理一下數(shù)據(jù)清洗過程����,供各位參考�����。
照例���,先上圖:
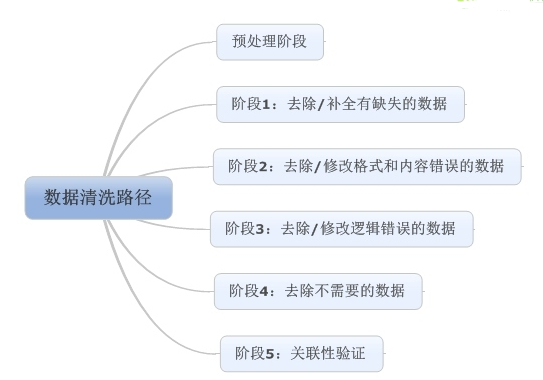
預處理階段
預處理階段主要做兩件事情:一是將數(shù)據(jù)導入處理工具。通常來說��,建議使用數(shù)據(jù)庫�,單機跑數(shù)搭建MySQL環(huán)境即可。如果數(shù)據(jù)量大(千萬級以上)��,可以使用文本文件存儲+Python操作的方式��。
二是看數(shù)據(jù)�����。這里包含兩個部分:一是看元數(shù)據(jù)���,包括字段解釋�、數(shù)據(jù)來源�����、代碼表等等一切描述數(shù)據(jù)的信息;二是抽取一部分數(shù)據(jù)��,使用人工查看方式��,對數(shù)據(jù)本身有一個直觀的了解��,并且初步發(fā)現(xiàn)一些問題��,為之后的處理做準備���。
第一步:缺失值清洗
缺失值是最常見的數(shù)據(jù)問題,處理缺失值也有很多方法�����,我建議按照以下四個步驟進行:
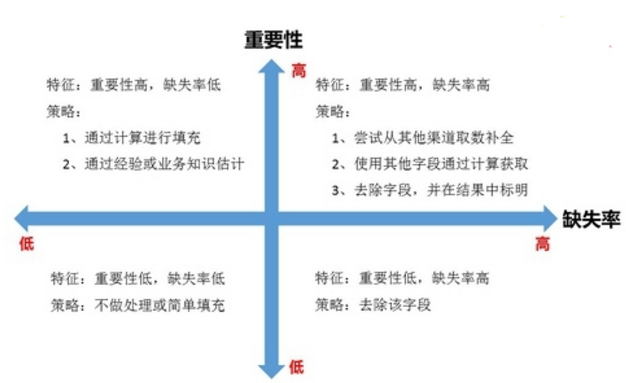
1����、確定缺失值范圍:對每個字段都計算其缺失值比例,然后按照缺失比例和字段重要性��,分別制定策略��,可用下圖表示:
2、去除不需要的字段:這一步很簡單��,直接刪掉即可……但強烈建議清洗每做一步都備份一下���,或者在小規(guī)模數(shù)據(jù)上試驗成功再處理全量數(shù)據(jù)���,不然刪錯了會追悔莫及(多說一句,寫SQL的時候delete一定要配where?����。?�。
3�����、填充缺失內容:某些缺失值可以進行填充����,方法有以下三種:
以業(yè)務知識或經驗推測填充缺失值
以同一指標的計算結果(均值、中位數(shù)����、眾數(shù)等)填充缺失值
以不同指標的計算結果填充缺失值
前兩種方法比較好理解�����。關于第三種方法�����,舉個最簡單的例子:年齡字段缺失,但是有屏蔽后六位的身份證號����,so……4、重新取數(shù):如果某些指標非常重要又缺失率高���,那就需要和取數(shù)人員或業(yè)務人員了解����,是否有其他渠道可以取到相關數(shù)據(jù)�。
以上,簡單的梳理了缺失值清洗的步驟�����,但其中有一些內容遠比我說的復雜,比如填充缺失值��。很多講統(tǒng)計方法或統(tǒng)計工具的書籍會提到相關方法����,有興趣的各位可以自行深入了解。
第二步:格式內容清洗
如果數(shù)據(jù)是由系統(tǒng)日志而來���,那么通常在格式和內容方面��,會與元數(shù)據(jù)的描述一致����。而如果數(shù)據(jù)是由人工收集或用戶填寫而來���,則有很大可能性在格式和內容上存在一些問題����,簡單來說����,格式內容問題有以下幾類:1、時間���、日期�、數(shù)值、全半角等顯示格式不一致
這種問題通常與輸入端有關���,在整合多來源數(shù)據(jù)時也有可能遇到�����,將其處理成一致的某種格式即可�����。
2��、內容中有不該存在的字符
某些內容可能只包括一部分字符,比如身份證號是數(shù)字+字母����,中國人姓名是漢字(趙C這種情況還是少數(shù))。最典型的就是頭����、尾、中間的空格���,也可能出現(xiàn)姓名中存在數(shù)字符號��、身份證號中出現(xiàn)漢字等問題�����。這種情況下����,需要以半自動校驗半人工方式來找出可能存在的問題,并去除不需要的字符�����。
3�、內容與該字段應有內容不符
姓名寫了性別,身份證號寫了手機號等等�,均屬這種問題。 但該問題特殊性在于:并不能簡單的以刪除來處理�����,因為成因有可能是人工填寫錯誤�����,也有可能是前端沒有校驗,還有可能是導入數(shù)據(jù)時部分或全部存在列沒有對齊的問題��,因此要詳細識別問題類型��。
格式內容問題是比較細節(jié)的問題��,但很多分析失誤都是栽在這個坑上����,比如跨表關聯(lián)或VLOOKUP失敗(多個空格導致工具認為“陳丹奕”和“陳 丹奕”不是一個人)����、統(tǒng)計值不全(數(shù)字里摻個字母當然求和時結果有問題)、模型輸出失敗或效果不好(數(shù)據(jù)對錯列了�����,把日期和年齡混了�,so……)����。因此,請各位務必注意這部分清洗工作��,尤其是在處理的數(shù)據(jù)是人工收集而來,或者你確定產品前端校驗設計不太好的時候……
第三步:邏輯錯誤清洗
這部分的工作是去掉一些使用簡單邏輯推理就可以直接發(fā)現(xiàn)問題的數(shù)據(jù)��,防止分析結果走偏��。主要包含以下幾個步驟:
1�����、去重
有的分析師喜歡把去重放在第一步�����,但我強烈建議把去重放在格式內容清洗之后�,原因已經說過了(多個空格導致工具認為“陳丹奕”和“陳 丹奕”不是一個人,去重失?����。?�。而且����,并不是所有的重復都能這么簡單的去掉……
我曾經做過電話銷售相關的數(shù)據(jù)分析,發(fā)現(xiàn)銷售們?yōu)榱藫寙魏喼睙o所不用其極……舉例�,一家公司叫做“ABC管家有限公司“����,在銷售A手里�����,然后銷售B為了搶這個客戶���,在系統(tǒng)里錄入一個”ABC官家有限公司“��。你看�,不仔細看你都看不出兩者的區(qū)別�,而且就算看出來了,你能保證沒有”ABC官家有限公司“這種東西的存在么……這種時候�����,要么去抱RD大腿要求人家給你寫模糊匹配算法�,要么肉眼看吧。
上邊這個還不是最狠的�����,請看下圖:
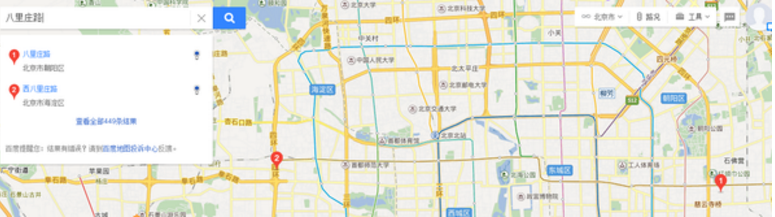
你用的系統(tǒng)里很有可能兩條路都叫八里莊路����,敢直接去重不?(附送去重小tips:兩個八里莊路的門牌號范圍不一樣)
當然��,如果數(shù)據(jù)不是人工錄入的�����,那么簡單去重即可����。
2、去除不合理值
一句話就能說清楚:有人填表時候瞎填����,年齡200歲,年收入100000萬(估計是沒看見”萬“字)����,這種的就要么刪掉,要么按缺失值處理�����。這種值如何發(fā)現(xiàn)����?提示:可用但不限于箱形圖(Box-plot).
3�、修正矛盾內容
有些字段是可以互相驗證的����,舉例:身份證號是1101031980XXXXXXXX,然后年齡填18歲����,我們雖然理解人家永遠18歲的想法,但得知真實年齡可以給用戶提供更好的服務?����。ㄓ窒钩丁?���。在這種時候,需要根據(jù)字段的數(shù)據(jù)來源��,來判定哪個字段提供的信息更為可靠���,去除或重構不可靠的字段����。
邏輯錯誤除了以上列舉的情況��,還有很多未列舉的情況�,在實際操作中要酌情處理。另外����,這一步驟在之后的數(shù)據(jù)分析建模過程中有可能重復,因為即使問題很簡單���,也并非所有問題都能夠一次找出����,我們能做的是使用工具和方法����,盡量減少問題出現(xiàn)的可能性,使分析過程更為高效�。
這一步說起來非常簡單:把不要的字段刪了。
但實際操作起來���,有很多問題��,例如:
把看上去不需要但實際上對業(yè)務很重要的字段刪了���;
某個字段覺得有用�����,但又沒想好怎么用�,不知道是否該刪�����;
一時看走眼�,刪錯字段了。
前兩種情況我給的建議是:如果數(shù)據(jù)量沒有大到不刪字段就沒辦法處理的程度�,那么能不刪的字段盡量不刪。第三種情況�,請勤備份數(shù)據(jù)……
第五步:關聯(lián)性驗證
如果你的數(shù)據(jù)有多個來源,那么有必要進行關聯(lián)性驗證����。例如,你有汽車的線下購買信息��,也有電話客服問卷信息����,兩者通過姓名和手機號關聯(lián)�,那么要看一下��,同一個人線下登記的車輛信息和線上問卷問出來的車輛信息是不是同一輛����,如果不是(別笑��,業(yè)務流程設計不好是有可能出現(xiàn)這種問題的?。敲葱枰{整或去除數(shù)據(jù)��。
嚴格意義上來說�����,這已經脫離數(shù)據(jù)清洗的范疇了�����,而且關聯(lián)數(shù)據(jù)變動在數(shù)據(jù)庫模型中就應該涉及����。但我還是希望提醒大家�����,多個來源的數(shù)據(jù)整合是非常復雜的工作����,一定要注意數(shù)據(jù)之間的關聯(lián)性��,盡量在分析過程中不要出現(xiàn)數(shù)據(jù)之間互相矛盾��,而你卻毫無察覺的情況�。
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330