數(shù)據(jù)處理流程����、分析方法和實戰(zhàn)案例(二)
四���、數(shù)據(jù)分析方法
接下來看一下互聯(lián)網(wǎng)產(chǎn)品采用的數(shù)據(jù)分析方法�。
對于互聯(lián)網(wǎng)產(chǎn)品常用的用戶消費分析來說�,有四種:
第一種是多維事件的分析,分析維度之間的組合�、關(guān)系。
第二種是漏斗分析��,對于電商��、訂單相關(guān)的這種行為的產(chǎn)品來說非常重要,要看不同的渠道轉(zhuǎn)化這些東西��。
第三種留存分析����,用戶來了之后我們希望他不斷的來,不斷的進(jìn)行購買����,這就是留存��。
第四種回訪,回訪是留存的一種特別的形式�,可以看他一段時間內(nèi)訪問的頻次,或者訪問的時間段的情況
方法1:多維事件分析法
首先來看多維事件的分析���,這塊常見的運營����、產(chǎn)品改進(jìn)這種效果分析���。其實���,大部分情況都是能用多維事件分析,然后對它進(jìn)行一個數(shù)據(jù)上的統(tǒng)計���。
1. 三個關(guān)鍵概念
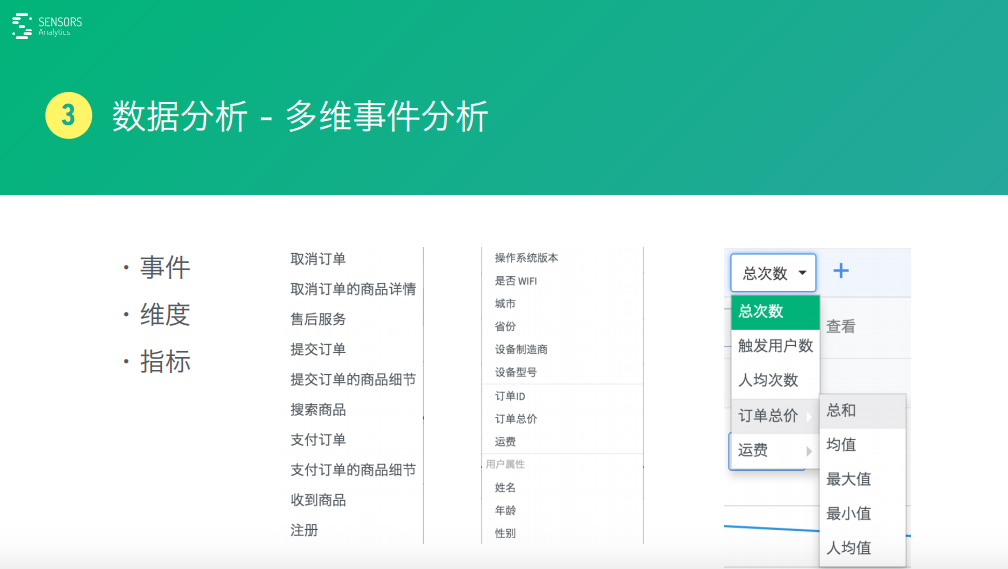
這里面其實就是由三個關(guān)鍵的概念���,一個就是事件,一個是維度����,一個是指標(biāo)組成。
事件就是說任何一個互聯(lián)網(wǎng)產(chǎn)品��,都可以把它抽象成一系列事件����,比如針對電商產(chǎn)品來說����,可抽象到提交、訂單�����、注冊�、收到商品一系列事件用戶行為。
每一個事件里面都包括一系列屬性。比如��,他用操作系統(tǒng)版本是否連wifi�;比如,訂單相關(guān)的運費����,訂單總價這些東西,或者用戶的一些職能屬性����,這些就是一系列維度。
基于這些維度看一些指標(biāo)的情況����。比如,對于提交訂單來說�����,可能是他總提交訂單的次數(shù)做成一個指標(biāo)���,提交訂單的人數(shù)是一個指標(biāo)�����,平均的人均次數(shù)這也是一個指標(biāo)��;訂單的總和�����、總價這些也是一個指標(biāo)����,運費這也是一個指標(biāo),統(tǒng)計一個數(shù)后就能把它抽樣成一個指標(biāo)����。
2. 多維分析的價值
來看一個例子,看看多維分析它的價值��。
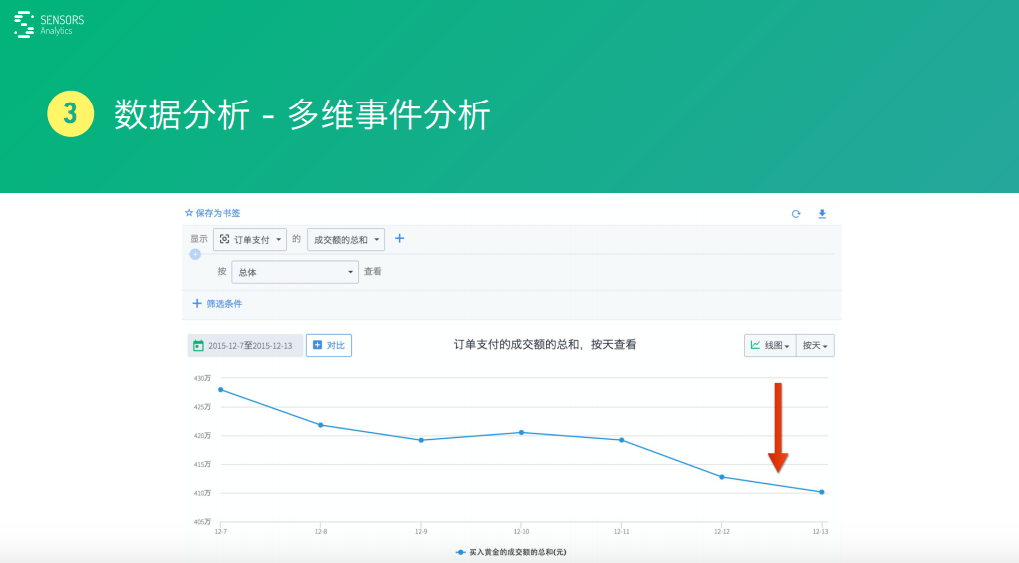
比如���,對于訂單支付這個事件來說,針對整個總的成交額這條曲線��,按照時間的曲線會發(fā)現(xiàn)它一路在下跌����。但下跌的時候,不能眼睜睜的看著它,一定要分析原因�����。
怎么分析這個原因呢�����?常用的方式就是對維度進(jìn)行一個拆解��,可以按照某些維度進(jìn)行拆分�,比如我們按照地域,或者按照渠道��,或者按照其他一些方式去拆開�����,按照年齡段����、按照性別去拆開,看這些數(shù)據(jù)到底是不是整體在下跌����,還是說某一類數(shù)據(jù)在下跌��。
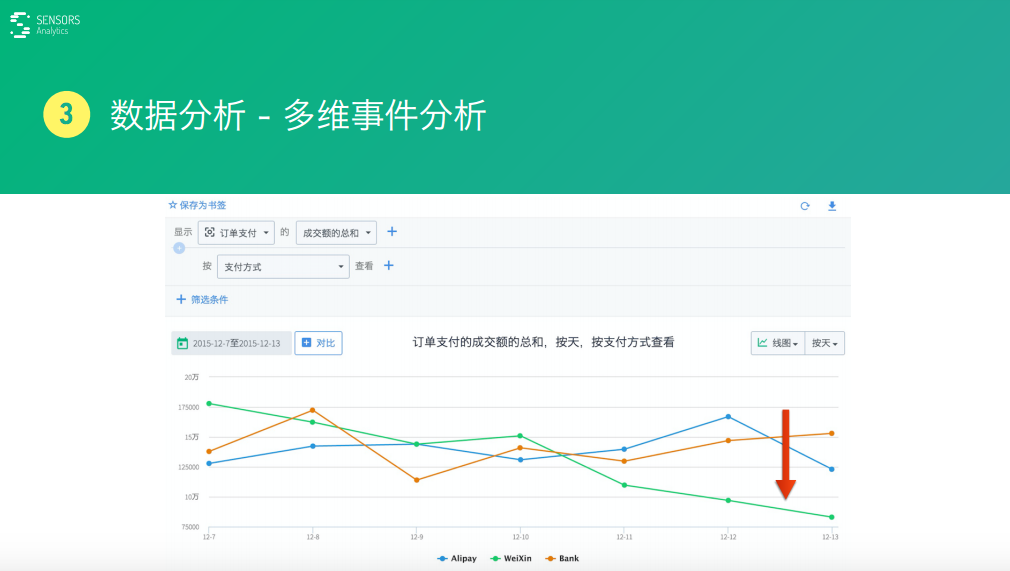
這是一個假想的例子——按照支付方式進(jìn)行拆開之后���,支付方式有三種,有用支付寶�����、阿里PAY��,或者用微信支付����,或者用銀行看內(nèi)的支付這三種方式。
通過數(shù)據(jù)可以看到支付寶�、銀行支付基本上是一個沉穩(wěn)的一個狀態(tài)。但是��,如果看微信支付�,會發(fā)現(xiàn)從最開始最多��,一路下跌到非常少����,通過這個分析就知道微信這種支付方式��,肯定存在某些問題����。
比如:是不是升級了這個接口或者微信本身出了什么問題����,導(dǎo)致了它量下降下去了?
方法2:漏斗分析
漏斗分析會看���,因為數(shù)據(jù)�����,一個用戶從做第一步操作到后面每一步操作�����,可能是一個雜的過程���。
比如,一批用戶先瀏覽了你的首頁�����,瀏覽首頁之后可能一部分人就直接跑了,還有一部分人可能去點擊到一個商品里面去�,點擊到商品可能又有很多人跑了,接下來可能有一部分人就真的購買了�����,這其實就是一個漏斗�。
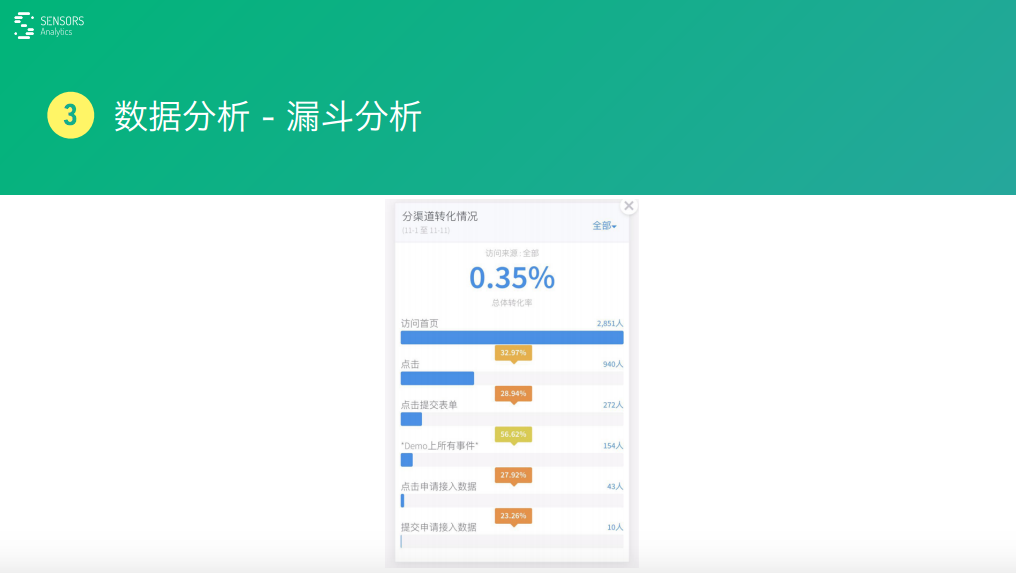
通過這個漏斗,就能分析一步步的轉(zhuǎn)化情況�,然后每一步都有流失,可以分析不同的渠道其轉(zhuǎn)化情況如何���。比如���,打廣告的時候發(fā)現(xiàn)來自百度的用戶漏斗轉(zhuǎn)化效果好,就可能在廣告投放上就在百度上多投一些�。
方法3:留存分析
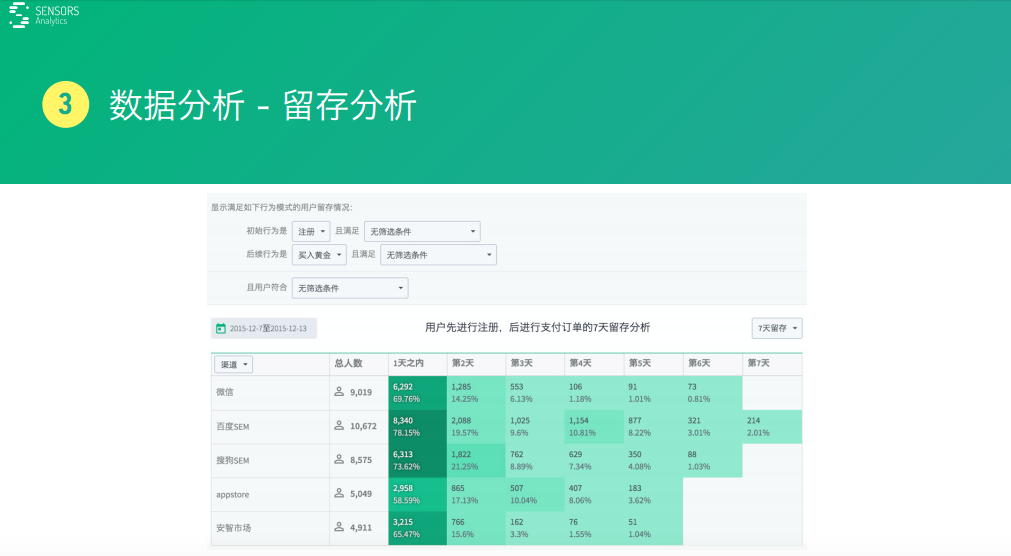
比如,搞一個地推活動�,然后來了一批注冊用戶,接下來看它的關(guān)鍵行為上面操作的特征�,比如當(dāng)天它有操作,第二天有多少人會關(guān)鍵操作�����,第N天有多少操作���,這就是看它留下來這個情況�����。
方法4:回訪分析
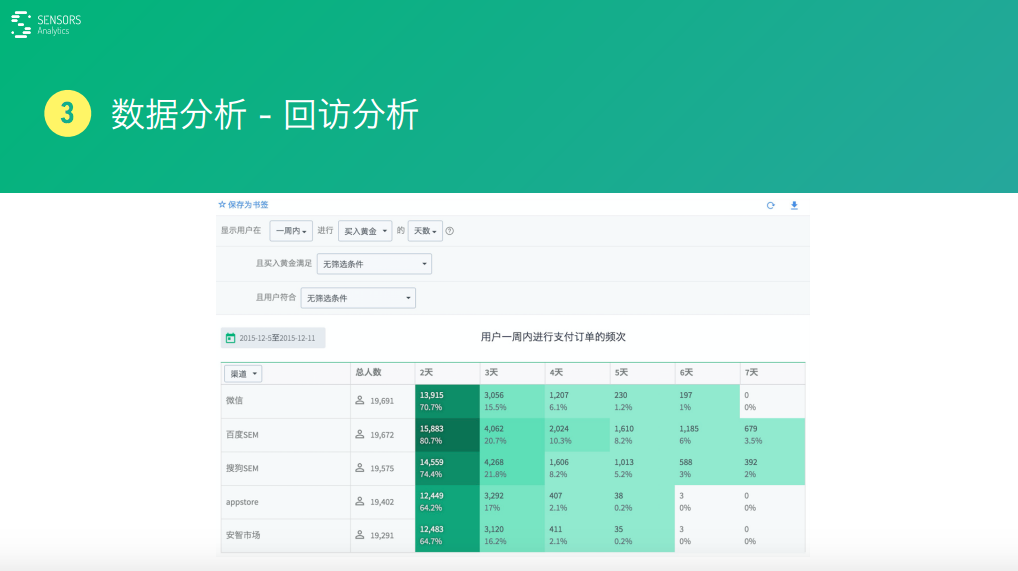
回訪就是看進(jìn)行某個行為的一些中度特征�,如對于購買黃金這個行為來說���,在一周之內(nèi)至少有一天購買黃金的人有多少人�����,至少有兩天的有多少人����,至少有7天的有多少人����,或者說購買多少次數(shù)這么一個分布,就是回訪回購這方面的分析��。
上面說的四種分析結(jié)合起來去使用��,對一個產(chǎn)品的數(shù)據(jù)支撐、數(shù)據(jù)驅(qū)動的這種深度就要比只是看一個宏觀的訪問量或者活躍用戶數(shù)就要深入很多����。
五、運營分析實踐
下面結(jié)合個人在運營和分析方面的實踐����,給大家分享一下。
案例1:UGC產(chǎn)品

首先��,來看UGC產(chǎn)品的數(shù)據(jù)分析的例子���?���?赡軙治鏊脑L問量是多少����,新增用戶數(shù)是多少,獲得用戶數(shù)多少��,發(fā)帖量�、減少量。
諸如貼吧、百度知道����,還有知乎都屬于這一類的產(chǎn)品��。對于這樣一個產(chǎn)品��,會有很多數(shù)據(jù)指標(biāo)�����,可以從某一個角度去觀察這個產(chǎn)品的情況���。那么�,問題就來了——這么多的指標(biāo)�����,到底要關(guān)注什么�����?不同的階段應(yīng)該關(guān)注什么指標(biāo)�?這里,就牽扯到一個本身指標(biāo)的處理,還有關(guān)鍵指標(biāo)的問題�����。
案例2:百度知道

2007年我加入百度知道之后,開始剛進(jìn)去就寫東西了�。作為RB,我每天也收到一系列報表郵件�,這些報表里面有很多統(tǒng)計的一些數(shù)據(jù)����。比如,百度知道的訪問量���、減少量�、IP數(shù)�����、申請數(shù)��、提問量���、回答量�,設(shè)置追加答案,答案的數(shù)量�����,這一系列指標(biāo)�����。當(dāng)時��,看的其實感覺很反感�����。
我在思考:這么多的指標(biāo)�,不能說這也提高�����,那也提高吧�?每個階段肯定要思考哪個事最關(guān)鍵的,重點要提高哪些指標(biāo)�����。開始的時候其實是沒有任何區(qū)分的,不知道什么是重要��、什么是不重要�。
后來,慢慢有一些感觸和認(rèn)識�����,就發(fā)現(xiàn)其實對于訪問量��、減少量這些相關(guān)的��。因為百度知道需要流量都是來自于大搜索����,把它展現(xiàn)做一下調(diào)整或者引導(dǎo),對量的影響非常大����。雖然,跟百度知道本身做的好壞也有直接關(guān)系�,但是它很受渠道的影響——大搜索這個渠道的影響。
提 問量開始的時候����,我認(rèn)為非常重要�����,怎么提升提問量����,那么整個百度知道平臺的這個問題就多了��。提升回答量��,讓這些問題得到回答�����,高質(zhì)量的內(nèi)容就非常多了���,又 提升提問量,而后再提升回答量——其實等于是兩類人了����。而怎么把它做上去,我當(dāng)時有一些困惑����,有一些矛盾����,到底什么東西是最關(guān)鍵的�����。
有一次產(chǎn)品會���,每一個季度都有一個產(chǎn)品會���。那個時候,整個部門的產(chǎn)品負(fù)責(zé)人是孫云豐����,可能在百度待過的或者說對百度產(chǎn)品體系有了解的都會知道這么一個人,非常厲害的一個產(chǎn)品經(jīng)理����。我當(dāng)時就問了他這個問題,我對提問量�����、回答量都要提升這個困惑�����。

他就說了一點,其實提問量不是一個關(guān)鍵的問題���,為什么�����?我們可以通過大搜索去找�,如果一個用戶在大搜索里面進(jìn)行搜索�����,發(fā)現(xiàn)這個搜索沒有一個好的答案���,那就可以引導(dǎo)他進(jìn)行一個提問,這樣其實這個提問量就可以迅速提升上去�。
我一聽一下就解決了這個困惑,最關(guān)鍵的就是一個回答量���,我所做的事情其實怎么去提升回答量就可以了�。

這里面把百度知道這個產(chǎn)品抽樣成了最關(guān)鍵的一個提升——那就是如何提升回答量���,在這個問題上當(dāng)時做了一個事情就是進(jìn)行問題推薦�����。
百度知道有一批活躍用戶����,這些用戶就喜歡回答問題。于是�,我們思考:能不能把一些他們可以回答問題推薦給他們,讓他們回答各種各樣的問題——這個怎么去做呢�����?
這個思路也很簡單���,現(xiàn)在個性化推薦都是比較正常的����,大家默認(rèn)知道這么一回事����。但是,2008年做推薦這個事情其實還是比較領(lǐng)先的���,從我了解的情況來看���,國內(nèi)的是2010年個性化推薦引擎這塊技術(shù)火了���,但后來有些公司做這方面后來都倒掉了。
實現(xiàn)策略是非常簡單的���,我們就看一個用戶歷史的回答記錄�����,看他回答的這些問題開頭是什么����、內(nèi)容是什么��。
由于百度很擅長做自然語言的處理��,基于這些�,通過這里面的抽取用戶的興趣詞�,感興趣的話題,然后把待解的問題�����,與該問題相關(guān)話題的相關(guān)用戶進(jìn)行一個匹配,匹配上了就把這個問題推薦給這個用戶�。
當(dāng)時,我們做的一個事情就是:把推薦幾個月有過回答量比較高的用戶進(jìn)行一個抽取���,對他們訓(xùn)練一個模式——就是對每個用戶有一系列的話題興趣點�,然后每個點都有一個程度���,這就是一個用戶的模型項量��,就是一個興趣項量��,當(dāng)時抽了35萬個用戶��。
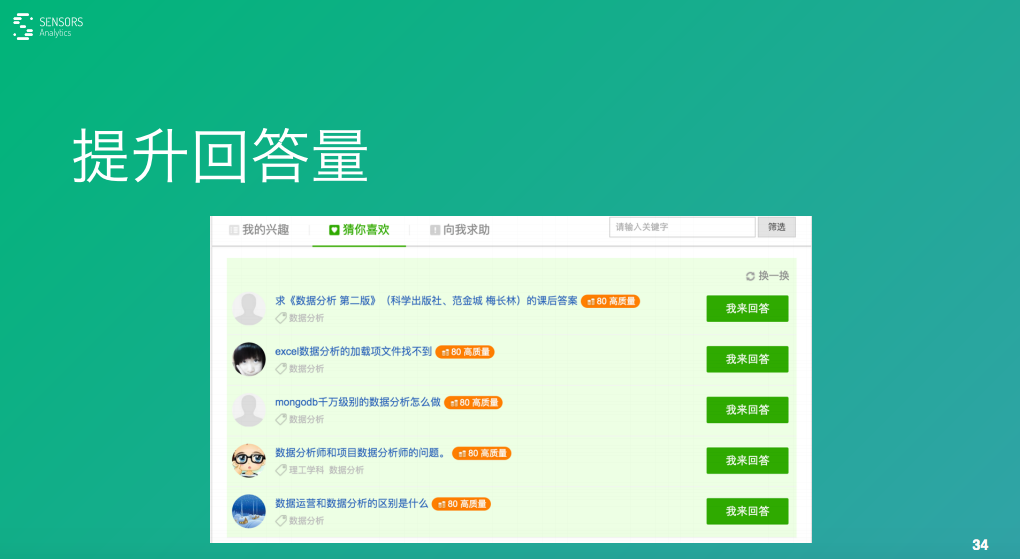
這個效果是這樣的���,現(xiàn)在我已經(jīng)找了我們當(dāng)年做的圖片,整個樣式其實這是我前一段時間截的圖���,大體類似�����。比如����,我對數(shù)據(jù)分析相關(guān)的問題回答了不少,它就會給我推薦數(shù)據(jù)分析相關(guān)的問題��。
我們這個功能差不多做了有三個月�,把它推上線我們其實是滿懷期待的,結(jié)果效果如何呢�����?
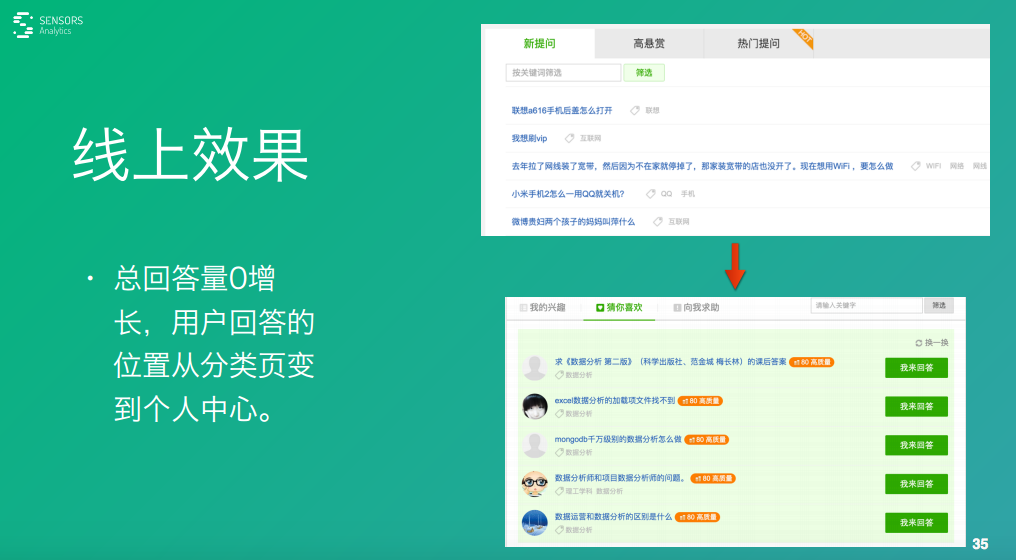
上線之后很悲劇���,我們發(fā)現(xiàn)總的回答量沒有變化��。于是����,我們又進(jìn)一步分析了一下原因����。當(dāng)時��,最開始這些核心用戶在回答問題的時候都是找分類頁。比如:電腦這個分類��,然后看電腦相關(guān)的問題����,有興趣的就回答。
后來����,我們做了一個體驗:在個人中心里面加了一個猜他喜歡的那個問題,然后推給他��,結(jié)果用戶從分類頁回答這個問題轉(zhuǎn)到了個人中心�。但是,平均一個人回答量并沒有變化����,當(dāng)時做的這些統(tǒng)計,這些核心用戶就回答六個問題��,超過六個他就沒動力回答了���。
我們事后分析原因�����,有一個原因他可能本身的回答量就是這么一條線����,誰能天天在哪里源源不斷的回復(fù)問題。還有一個同事就分析當(dāng)時讓他一個痛苦的地方���,因為我們是源源不斷地推薦��,然后他就發(fā)現(xiàn)回答幾個之后還有幾個��,回答了幾次就感覺要崩潰了����,就不想再這么回答下去了���。
其實�,年前時知乎在問題推薦上也做了不少功夫��,做了許多測試��。年前有一段時間���,它天天給我推一些新的問題���,然后我去回答��。后來,發(fā)現(xiàn)推的太多了�,就沒回答的動力了。
針對這些核心用戶會發(fā)現(xiàn)從他們上面榨取不了新的價值了�。于是,我們調(diào)轉(zhuǎn)了矛頭��,從另一個角度——能不能去廣撒網(wǎng)�����,吸引更多的用戶來回答問題���,這個做的就是一個庫里推薦�����。

訪 問百度的時候����,百度不管用戶是否登錄,會在用戶的庫里面去設(shè)置一個用戶標(biāo)識��。通過這個標(biāo)識能夠?qū)@個用戶進(jìn)行一個跟蹤����,雖然不知道用戶是誰,但是��,起碼能 把同一個用戶這個行為給它檢起來�。這樣,就可以基于他歷史的檢索���,各種搜索詞��,還有他流量的各種頁面的記錄�����,然后去提取一些證據(jù)���,然后給這些庫題建一個模 型���。
這樣有一個好處���,能夠覆蓋的用戶量非常大�,前面講的核心用戶推薦只覆蓋了只有35萬的核心用戶�����,但是通過這種方式可以覆蓋幾億百度用戶���,每一次用戶登錄之后或者訪問百度知道之后我們就基于他本身興趣然后走一次檢索,在解決問題里面檢索一下跟他匹配的就給他推薦出來�����。
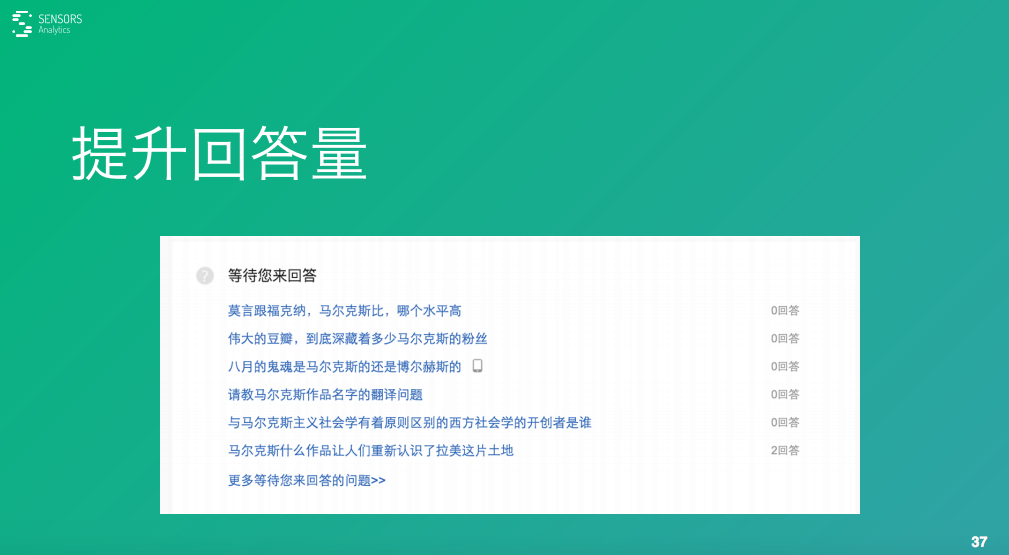
比如前一段����,我自己在沒有登錄的時候,其實我是會看馬爾克斯。我比較喜歡馬爾克斯的作品�,我當(dāng)時搜了馬爾克斯的一些相關(guān)的內(nèi)容。它就抽取出來我對馬爾克斯什么感興趣��,就給我推薦了馬爾克斯相關(guān)的問題�����,可能我知道我不可能就會點進(jìn)去回答�。
這 個功能上了之后效果還是很不錯的�,讓整體的回答量提升了7.5%。要知道�,百度知道產(chǎn)品從2005年開始做����,做到2007年����、2008年的時間這個產(chǎn)品已 經(jīng)很成熟了。在一些關(guān)鍵指標(biāo)進(jìn)行大的提升還是非常有挑戰(zhàn)的�����,這種情況下我們通過這種方式提升了7.5%的回答量�,感覺還是比較有成就感�����,我當(dāng)時也因為這個 事情得了季度之星�。
案例3:流失用戶召回
這種形式可能對其他產(chǎn)品就很有效,但是對我們這個產(chǎn)品來說�����,因為我們這是一個相對來說目標(biāo)比較明確并且比較小眾一點的差別,所以這個投放的效果可能就沒那么明顯���。
在今年元旦的時候�,因為之前申請試用我們那個產(chǎn)品已經(jīng)有很多人�,但是這里面有一萬人我們給他發(fā)了帳號他也并沒有回來,我們過年給大家拜拜年�����,然后去匯報一下進(jìn)展看能不能把他們撈過來一部分���。
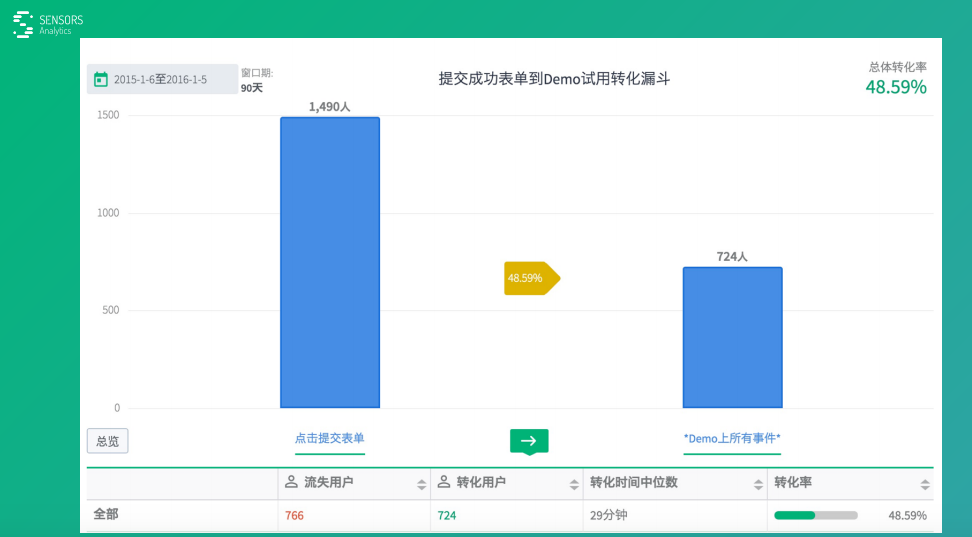
這是元旦的時候我們產(chǎn)品的整體用戶情況����,到了元旦為止�����,9月25號發(fā)布差不多兩三個月時間,那個時候差不多有1490個人申請試用了我們這個產(chǎn)品��。但是��,真正試用的有724個����,差不多有一半,另外一半就跑了���,就流失了���。
我們就想把這部分人抽出來給他們進(jìn)行一個招回活動,這里面流失用戶我們就可以把列表導(dǎo)出來�����,這是我們自己的產(chǎn)品就有這樣的功能��。有人可能疑惑我們怎么拿到用戶的這些信息呢��?
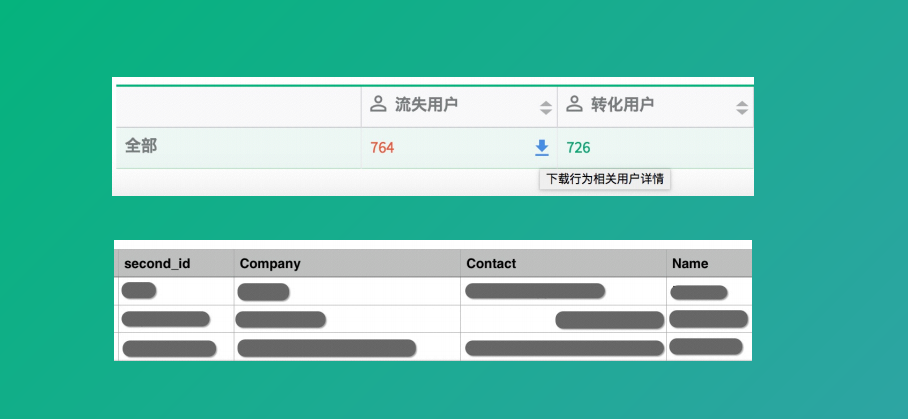
這些不至于添加��,因為我們申請試用的時候就讓他填一下姓名���、聯(lián)系方式���,還有他的公司這些信息。對于填郵箱的我們就給發(fā)郵件的���,對于發(fā)手機(jī)號的我們就給他發(fā)短信���,我們分析這兩種渠道帶來的效果。
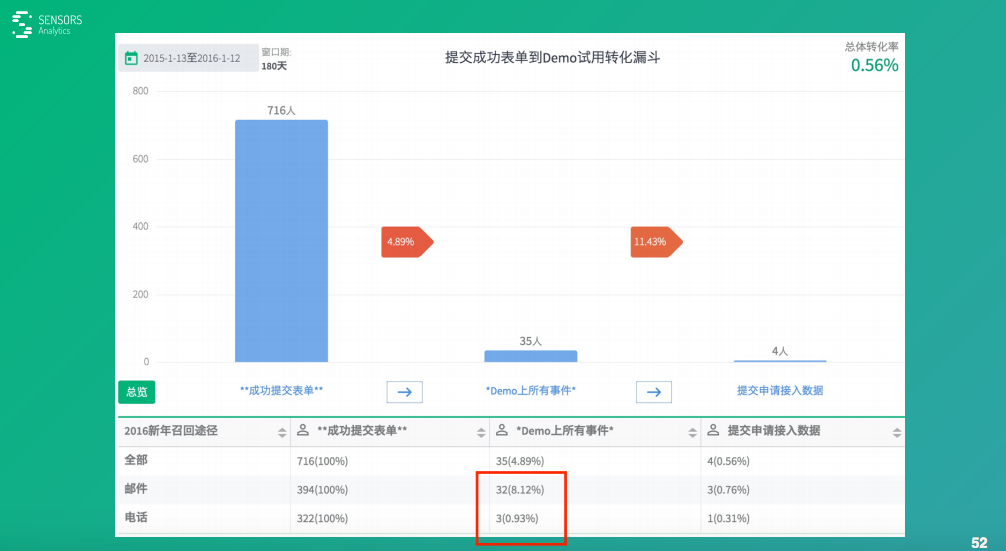
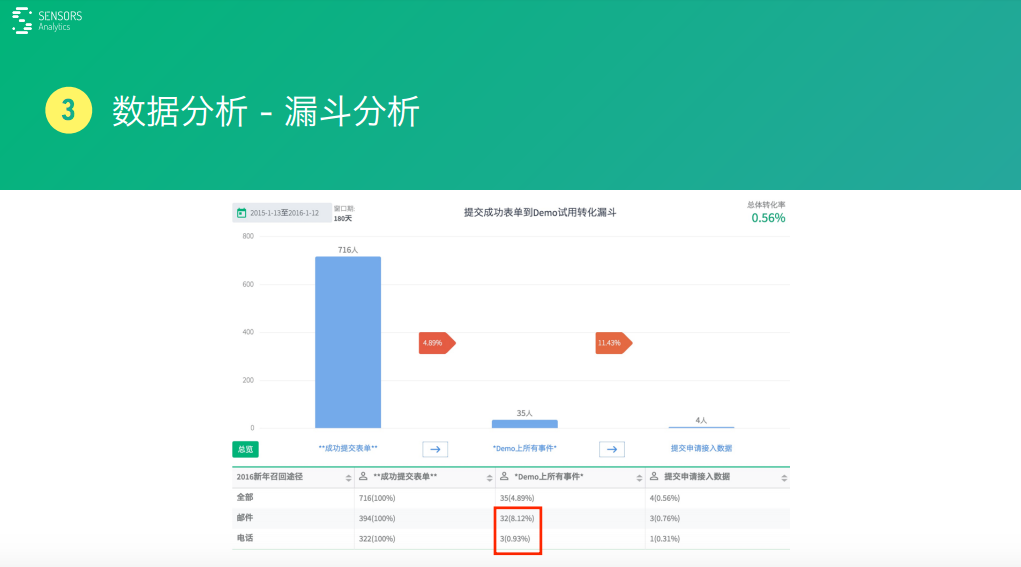
先說總體��,總體我們發(fā)了716個人�����,這里面比前面少了一點����,我把一些不靠譜的這些信息人工給它干掉了。接下來�,看看真正有35個人去體驗了這個產(chǎn)品,然后35個人里面有4個人申請接入數(shù)據(jù)���。
因為我們在產(chǎn)品上面做了一個小的改進(jìn)��,在測試環(huán)境上面��,對于那些測試環(huán)境本身是一些數(shù)據(jù)他玩一玩����,玩了可能感興趣之后就會試一下自己的真實數(shù)據(jù)。這個時候��,我們上來有一個鏈接引導(dǎo)他們?nèi)ド暾埥尤胱约旱臄?shù)據(jù)����,走到這一步之后就更可能轉(zhuǎn)化成我們的正式客戶。
這兩種方式轉(zhuǎn)化效果我們其實也很關(guān)心����,招回的效果怎么樣,我們看下面用紅框表示出來����,郵件發(fā)了394封。最終有32個人真正過來試用了�,電話手機(jī)號322封�,跟郵件差不多���,但只有3個過來,也就是說兩種效果差了8倍��。
這其實也提醒大家����,短信這種方式可能許多人看短信的比較少。當(dāng)然����,另一方面跟我們自己產(chǎn)品特征有關(guān)系,我們這個產(chǎn)品是一個PC上用起來更方便的一個產(chǎn)品��。許多人可能在手機(jī)上看到這個鏈接也不方便點開����,點開之后輸入帳號也麻煩一點。所以�����,導(dǎo)致這個效果比較差���。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330