數(shù)據(jù)處理流程�、分析方法和實(shí)戰(zhàn)案例(一)
一、大數(shù)據(jù)思維
在2011年�、2012年大數(shù)據(jù)概念火了之后,可以說這幾年許多傳統(tǒng)企業(yè)也好��,互聯(lián)網(wǎng)企業(yè)也好��,都把自己的業(yè)務(wù)給大數(shù)據(jù)靠一靠��,并且提的比較多的大數(shù)據(jù)思維�。
那么大數(shù)據(jù)思維是怎么回事?我們來看兩個(gè)例子:
案例1:輸入法
首先�,我們來看一下輸入法的例子��。
我2001年上大學(xué)�����,那時(shí)用的輸入法比較多的是智能ABC����,還有微軟拼音��,還有五筆���。那時(shí)候的輸入法比現(xiàn)在來說要慢的很多�,許多時(shí)候輸一個(gè)詞都要選好幾次�����,去選詞還是調(diào)整才能把這個(gè)字打出來�,效率是非常低的。
到了2002年��,2003年出了一種新的輸出法——紫光拼音��,感覺真的很快�,鍵盤沒有按下去字就已經(jīng)跳出來了���。但是,后來很快發(fā)現(xiàn)紫光拼音輸入法也有它的問題���,比如當(dāng)時(shí)互聯(lián)網(wǎng)發(fā)展已經(jīng)比較快了,會經(jīng)常出現(xiàn)一些新的詞匯�,這些詞匯在它的詞庫里沒有的話,就很難敲出來這個(gè)詞�。
在2006年左右,搜狗輸入法出現(xiàn)了���。搜狗輸入法基于搜狗本身是一個(gè)搜索����,它積累了一些用戶輸入的檢索詞這些數(shù)據(jù)���,用戶用輸入法時(shí)候產(chǎn)生的這些詞的信息����,將它們進(jìn)行統(tǒng)計(jì)分析���,把一些新的詞匯逐步添加到詞庫里去����,通過云的方式進(jìn)行管理。

比 如���,去年流行一個(gè)詞叫“然并卵”��,這樣的一個(gè)詞如果用傳統(tǒng)的方式�,因?yàn)樗且粋€(gè)重新構(gòu)造的詞�,在輸入法是沒辦法通過拼音“ran bing luan”直接把它找出來的。然而���,在大數(shù)據(jù)思維下那就不一樣了��,換句話說��,我們先不知道有這么一個(gè)詞匯����,但是我們發(fā)現(xiàn)有許多人在輸入了這個(gè)詞匯����,于是, 我們可以通過統(tǒng)計(jì)發(fā)現(xiàn)最近新出現(xiàn)的一個(gè)高頻詞匯�����,把它加到司庫里面并更新給所有人,大家在使用的時(shí)候可以直接找到這個(gè)詞了����。
案例2:地圖
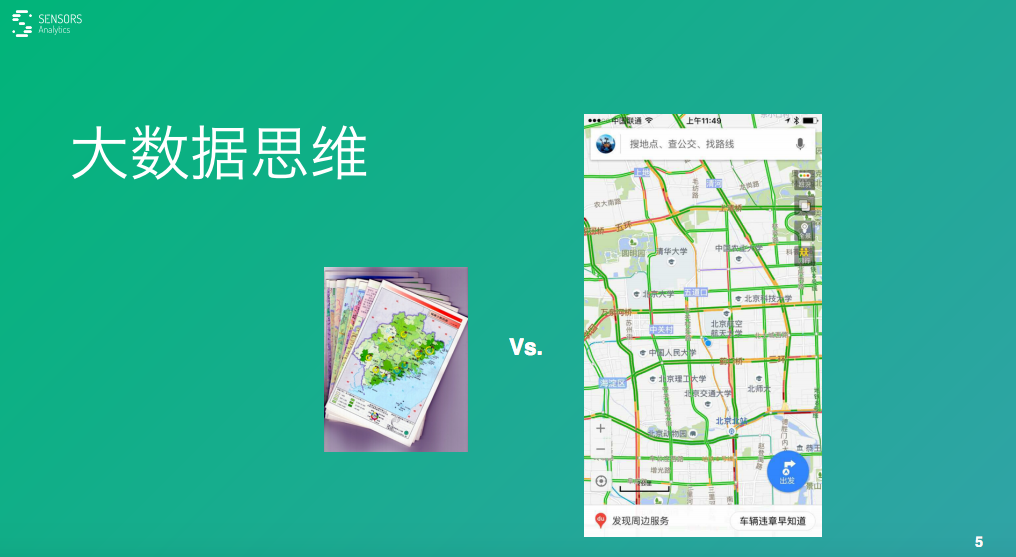
再 來看一個(gè)地圖的案例,在這種電腦地圖�����、手機(jī)地圖出現(xiàn)之前���,我們都是用紙質(zhì)的地圖。這種地圖差不多就是一年要換一版��,因?yàn)樵S多地址可能變了�,并且在紙質(zhì)地圖 上肯定是看不出來,從一個(gè)地方到另外一個(gè)地方怎么走是最好的�?中間是不是堵車?這些都是有需要有經(jīng)驗(yàn)的各種司機(jī)才能判斷出來�。
在有了百度地圖這樣的產(chǎn)品就要好很多,比如:它能告訴你這條路當(dāng)前是不是堵的����?或者說能告訴你半個(gè)小時(shí)之后它是不是堵的�����?它是不是可以預(yù)測路況情況���?
此 外,你去一個(gè)地方它可以給你規(guī)劃另一條路線����,這些就是因?yàn)樗杉皆S多數(shù)據(jù)。比如:大家在用百度地圖的時(shí)候����,有GPS地位信息,基于你這個(gè)位置的移動信 息���,就可以知道路的擁堵情況����。另外,他可以收集到很多用戶使用的情況,可以跟交管局或者其他部門來采集一些其他攝像頭��、地面的傳感器采集的車輛的數(shù)量的數(shù) 據(jù),就可以做這樣的判斷了。

這里�,我們來看一看紙質(zhì)的地圖跟新的手機(jī)地圖之間,智能ABC輸入法跟搜狗輸入法都有什么區(qū)別����?
這 里面最大的差異就是有沒有用上新的數(shù)據(jù)。這里就引來了一個(gè)概念——數(shù)據(jù)驅(qū)動����。有了這些數(shù)據(jù),基于數(shù)據(jù)上統(tǒng)計(jì)也好�����,做其他挖掘也好�����,把一個(gè)產(chǎn)品做的更加智 能�����,變得更加好����,這個(gè)跟它對應(yīng)的就是之前可能沒有數(shù)據(jù)的情況,可能是拍腦袋的方式�����,或者說我們用過去的���,我們想清楚為什么然后再去做這個(gè)事情�。這些相比之 下數(shù)據(jù)驅(qū)動這種方式效率就要高很多���,并且有許多以前解決不了的問題它就能解決的非常好��。
二���、數(shù)據(jù)驅(qū)動
對于數(shù)據(jù)驅(qū)動這一點(diǎn),可能有些人從沒有看數(shù)的習(xí)慣到了看數(shù)的習(xí)慣那是一大進(jìn)步��,是不是能看幾個(gè)數(shù)這就叫數(shù)據(jù)驅(qū)動了呢����?這還遠(yuǎn)遠(yuǎn)不夠,這里來說一下什么是數(shù)據(jù)驅(qū)動��?或者現(xiàn)有的創(chuàng)業(yè)公司在進(jìn)行數(shù)據(jù)驅(qū)動這件事情上存在的一些問題��。

一種情況大家在公司里面有一個(gè)數(shù)據(jù)工程師,他的工作職責(zé)就是跑數(shù)據(jù)��。
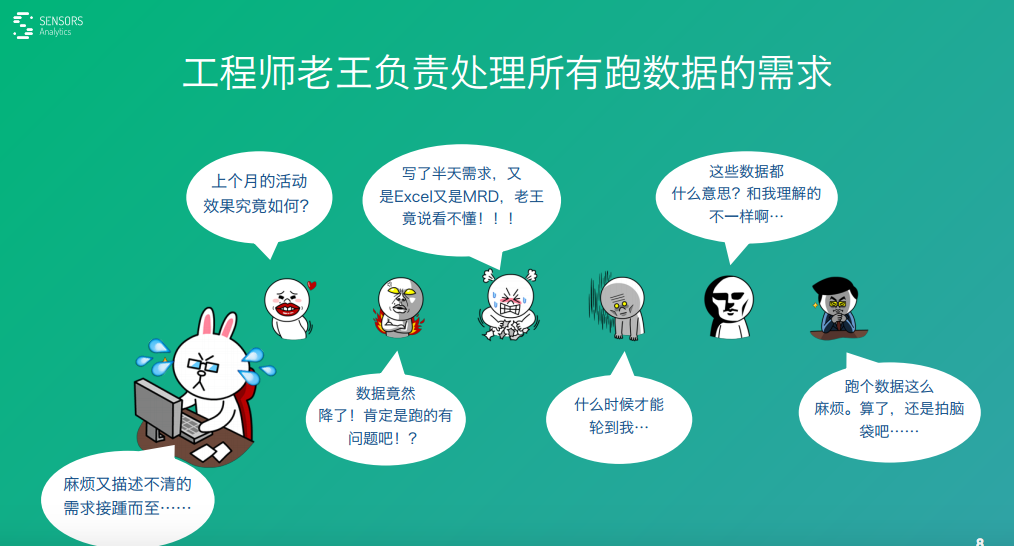
不 管是市場也好�,產(chǎn)品也好,運(yùn)營也好����,老板也好,大家都會有各種各樣的數(shù)據(jù)需求���,但都會提給他�。然而�����,這個(gè)資源也是有限的�,他的工作時(shí)間也是有限的,只能一 個(gè)一個(gè)需求去處理���,他本身工作很忙,大家提的需求之后可能并不會馬上就處理�,可能需要等待一段時(shí)間。即使處理了這個(gè)需求���,一方面他可能數(shù)據(jù)準(zhǔn)備的不全����,他 需要去采集一些數(shù)據(jù),或做一些升級�,他要把數(shù)據(jù)拿過來。拿過來之后又在這個(gè)數(shù)據(jù)上進(jìn)行一些分析���,這個(gè)過程本身可能兩三天時(shí)間就過去了�����,如果加上等待的時(shí)間 更長�。
對于有些人來說�,這個(gè)等待周期太長,整個(gè)時(shí)機(jī)可能就錯(cuò)過了���。比如����,你重要的就 是考察一個(gè)節(jié)日或者一個(gè)開學(xué)這樣一個(gè)時(shí)間點(diǎn)��,然后想搞一些運(yùn)營相關(guān)的事情�����,這個(gè)時(shí)機(jī)可能就錯(cuò)過去了,許多人等不到了�����,有些同學(xué)可能就干脆還是拍腦袋�,就不 等待這個(gè)數(shù)據(jù)了。這個(gè)過程其實(shí)就是說效率是非常低的�����,并不是說拿不到這個(gè)數(shù)據(jù)����,而是說效率低的情況下我們錯(cuò)過了很多機(jī)會。

對于還有一些公司來說��,之前可能連個(gè)數(shù)都沒有�,現(xiàn)在有了一個(gè)儀表盤,有了儀表盤可以看到公司上個(gè)季度�、昨天總體的這些數(shù)據(jù),還是很不錯(cuò)的�����。

對老板來說肯定還是比較高興�,但是,對于市場���、運(yùn)營這些同學(xué)來說可能就還不夠���。
比 如,我們發(fā)現(xiàn)某一天的用戶量跌了20%�����,這個(gè)時(shí)候肯定不能放著不管��,需要查一查這個(gè)問題出在哪�����。這個(gè)時(shí)候�����,只看一個(gè)宏觀的數(shù)那是遠(yuǎn)遠(yuǎn)不夠的�,我們一般要對 這個(gè)數(shù)據(jù)進(jìn)行切分,按地域����、按渠道�,按不同的方式去追查���,看到底是哪少了����,是整體少了��,還是某一個(gè)特殊的渠道獨(dú)特的地方它這個(gè)數(shù)據(jù)少了���,這個(gè)時(shí)候單單靠一 個(gè)儀表盤是不夠的�。

理想狀態(tài)的數(shù)據(jù)驅(qū)動應(yīng)該是怎么樣的�����?就是一個(gè)自助式的數(shù)據(jù)分析�����,讓業(yè)務(wù)人員每一個(gè)人都能自己去進(jìn)行數(shù)據(jù)分析��,掌握這個(gè)數(shù)據(jù)�����。
前 面我講到一個(gè)模式�����,我們源頭是一堆雜亂的數(shù)據(jù)����,中間有一個(gè)工程師用來跑這個(gè)數(shù)據(jù),然后右邊是接各種業(yè)務(wù)同學(xué)提了需求��,然后排隊(duì)等待被處理��,這種方式效率是 非常低的��。理想狀態(tài)來說����,我們現(xiàn)象大數(shù)據(jù)源本身整好,整全整細(xì)了����,中間提供強(qiáng)大的分析工具,讓每一個(gè)業(yè)務(wù)員都能直接進(jìn)行操作��,大家并發(fā)的去做一些業(yè)務(wù)上的 數(shù)據(jù)需求,這個(gè)效率就要高非常多��。
三���、數(shù)據(jù)處理的流程
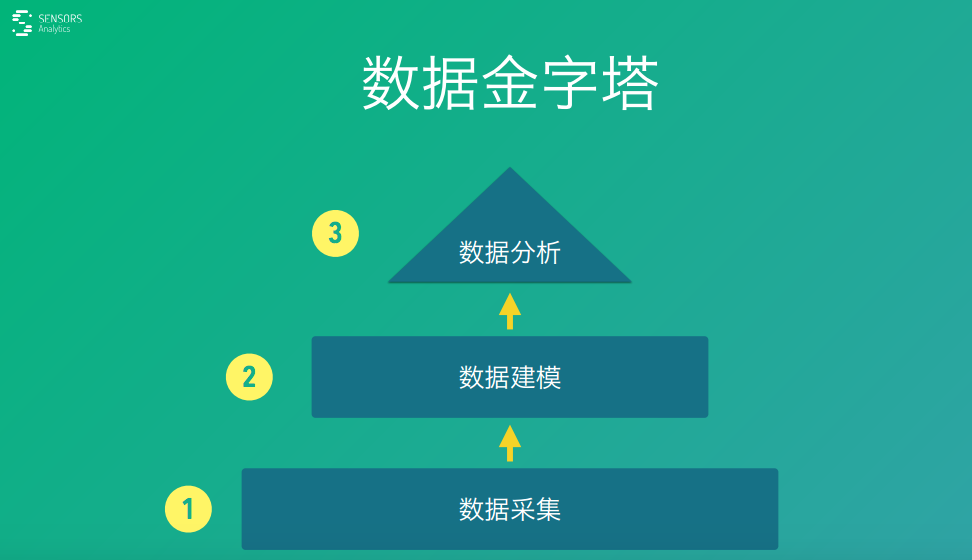
大數(shù)據(jù)分析這件事用一種非技術(shù)的角度來看的話��,就可以分成金字塔�,自底向上的是三個(gè)部分�,第一個(gè)部分是數(shù)據(jù)采集,第二個(gè)部分是數(shù)據(jù)建模�,第三個(gè)部分是數(shù)據(jù)分析,我們來分別看一下����。
數(shù)據(jù)采集

首先來說一下數(shù)據(jù)采集,我在百度干了有七年是數(shù)據(jù)相關(guān)的事情��。我最大的心得——數(shù)據(jù)這個(gè)事情如果想要更好�����,最重要的就是數(shù)據(jù)源���,數(shù)據(jù)源這個(gè)整好了之后�,后面的事情都很輕松。
用一個(gè)好的查詢引擎�����、一個(gè)慢的查詢引擎無非是時(shí)間上可能消耗不大一樣����,但是數(shù)據(jù)源如果是差的話�����,后面用再復(fù)雜的算法可能都解決不了這個(gè)問題���,可能都是很難得到正確的結(jié)論��。
我覺得好的數(shù)據(jù)處理流程有兩個(gè)基本的原則�,一個(gè)是全�,一個(gè)是細(xì)。
全:
就 是說我們要拿多種數(shù)據(jù)源���,不能說只拿一個(gè)客戶端的數(shù)據(jù)源����,服務(wù)端的數(shù)據(jù)源沒有拿,數(shù)據(jù)庫的數(shù)據(jù)源沒有拿���,做分析的時(shí)候沒有這些數(shù)據(jù)你可能是搞歪了��。另外�����, 大數(shù)據(jù)里面講的是全量����,而不是抽樣���。不能說只抽了某些省的數(shù)據(jù)�,然后就開始說全國是怎么樣���??赡苡行┦》浅L厥?��,比如新疆�����、西藏這些地方客戶端跟內(nèi)地可能 有很大差異的��。
細(xì):
其 實(shí)就是強(qiáng)調(diào)多維度���,在采集數(shù)據(jù)的時(shí)候盡量把每一個(gè)的維度�����、屬性、字段都給它采集過來��。比如:像where����、who、how這些東西給它替補(bǔ)下來���,后面分析 的時(shí)候就跳不出這些能夠所選的這個(gè)維度����,而不是說開始的時(shí)候也圍著需求��。根據(jù)這個(gè)需求確定了產(chǎn)生某些數(shù)據(jù),到了后面真正有一個(gè)新的需求來的時(shí)候��,又要采集 新的數(shù)據(jù)��,這個(gè)時(shí)候整個(gè)迭代周期就會慢很多�����,效率就會差很多���,盡量從源頭抓的數(shù)據(jù)去做好采集�����。
有了數(shù)據(jù)之后����,就要對數(shù)據(jù)進(jìn)行加工��,不能把原始的數(shù)據(jù)直接報(bào)告給上面的業(yè)務(wù)分析人員�,它可能本身是雜亂的,沒有經(jīng)過很好的邏輯的��。
這里就牽扯到數(shù)據(jù)建框���,首先�����,提一個(gè)概念就是數(shù)據(jù)模型��。許多人可能對數(shù)據(jù)模型這個(gè)詞產(chǎn)生一種畏懼感�,覺得模型這個(gè)東西是什么高深的東西,很復(fù)雜�,但其實(shí)這個(gè)事情非常簡單。
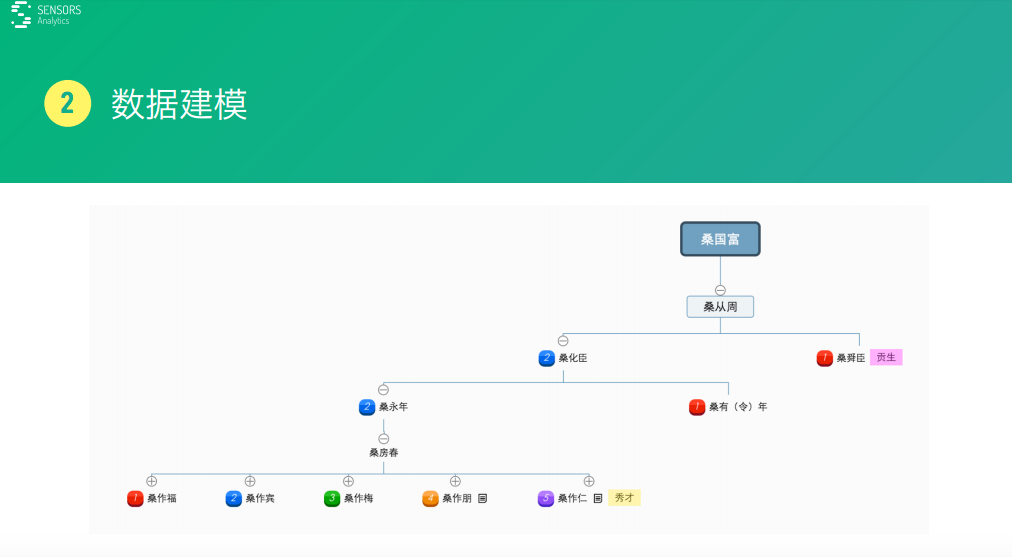
我春節(jié)期間在家干過一件事情���,我自己家里面家譜在文革的時(shí)候被燒了��,后來家里的長輩說一定要把家譜這些東西給存檔一下��,因?yàn)槲視娔X,就幫著用電腦去理了一下這些家族的數(shù)據(jù)這些關(guān)系����,整個(gè)族譜這個(gè)信息。
我們現(xiàn)實(shí)是一個(gè)個(gè)的人��,家譜里面的人�����,通過一個(gè)樹型的結(jié)構(gòu),還有它們之間數(shù)據(jù)關(guān)系�,就能把現(xiàn)實(shí)實(shí)體的東西用幾個(gè)簡單圖給表示出來,這里就是一個(gè)數(shù)據(jù)模型�。
數(shù)據(jù)模型就是對現(xiàn)實(shí)世界的一個(gè)抽象化的數(shù)據(jù)的表示。我們這些創(chuàng)業(yè)公司經(jīng)常是這么一個(gè)情況����,我們現(xiàn)在這種業(yè)務(wù),一般前端做一個(gè)請求����,然后對請求經(jīng)過處理,再更新到數(shù)據(jù)庫里面去���,數(shù)據(jù)庫里面建了一系列的數(shù)據(jù)表�����,數(shù)據(jù)表之間都是很多的依賴關(guān)系���。
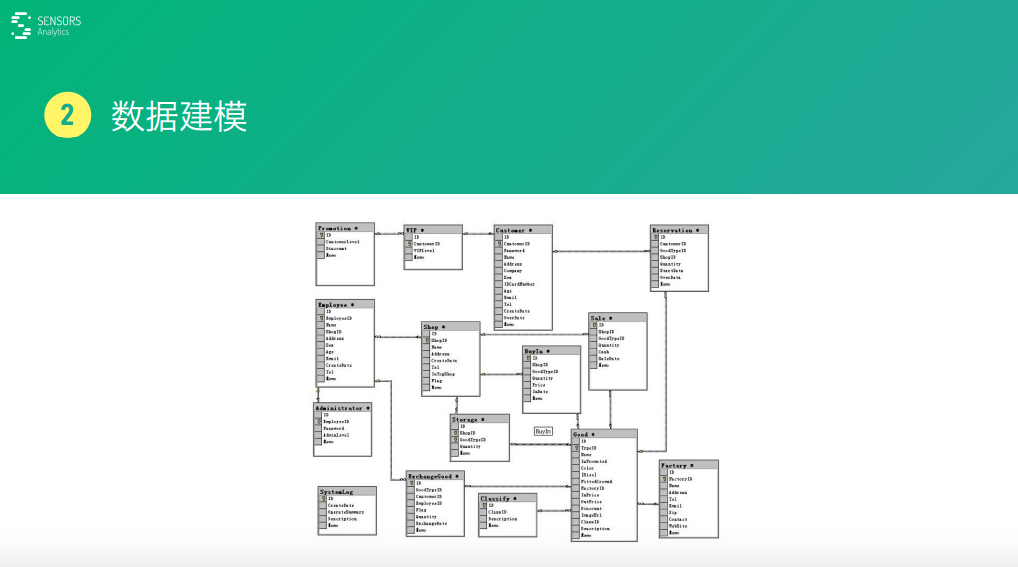
比如,就像我圖片里面展示的這樣�����,這些表一個(gè)業(yè)務(wù)項(xiàng)發(fā)展差不多一年以上它可能就牽扯到幾十張甚至上百張數(shù)據(jù)表,然后把這個(gè)表直接提供給業(yè)務(wù)分析人員去使用���,理解起來難度是非常大的����。
這個(gè)數(shù)據(jù)模型是用于滿足你正常的業(yè)務(wù)運(yùn)轉(zhuǎn)���,為產(chǎn)品正常的運(yùn)行而建的一個(gè)數(shù)據(jù)模型�����。但是�����,它并不是一個(gè)針對分析人員使用的模型���。如果�,非要把它用于數(shù)據(jù)分析那就帶來了很多問題。比如:它理解起來非常麻煩�。
另外����,數(shù)據(jù)分析很依賴表之間的這種格子��,比如:某一天我們?yōu)榱颂嵘阅?�,對某一表進(jìn)行了拆分���,或者加了字段���、刪了某個(gè)字短,這個(gè)調(diào)整都會影響到你分析的邏輯���。

這里�����,最好要針對分析的需求對數(shù)據(jù)重新進(jìn)行解碼���,它內(nèi)容可能是一致的,但是我們的組織方式改變了一下�����。就拿用戶行為這塊數(shù)據(jù)來說,就可以對它進(jìn)行一個(gè)抽象�,然后重新把它作為一個(gè)判斷表。
用 戶在產(chǎn)品上進(jìn)行的一系列的操作��,比如瀏覽一個(gè)商品��,然后誰瀏覽的�����,什么時(shí)間瀏覽的�,他用的什么操作系統(tǒng),用的什么瀏覽器版本�,還有他這個(gè)操作看了什么商 品,這個(gè)商品的一些屬性是什么�,這個(gè)東西都給它進(jìn)行了一個(gè)很好的抽象。這種抽樣的很大的好處很容易理解�,看過去一眼就知道這表是什么,對分析來說也更加方 便�。

在數(shù)據(jù)分析方,特別是針對用戶行為分析方面���,目前比較有效的一個(gè)模型就是多維數(shù)據(jù)模型���,在線分析處理這個(gè)模型,它里面有這個(gè)關(guān)鍵的概念����,一個(gè)是維度,一個(gè)是指標(biāo)��。
維度比如城市����,然后北京、上海這些一個(gè)維度�,維度西面一些屬性,然后操作系統(tǒng)�����,還有IOS��、安卓這些就是一些維度�,然后維度里面的屬性。
通過維度交叉���,就可以看一些指標(biāo)問題���,比如用戶量����、銷售額�,這些就是指標(biāo)。比如�����,通過這個(gè)模型就可以看來自北京���,使用IOS的�����,他們的整體銷售額是怎么樣的��。
這里只是舉了兩個(gè)維度�����,可能還有很多個(gè)維度����。總之�����,通過維度組合就可以看一些指標(biāo)的數(shù)�����,大家可以回憶一下���,大家常用的這些業(yè)務(wù)的數(shù)據(jù)分析需求是不是許多都能通過這種簡單的模式給抽樣出來。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材��,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫�,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量���,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330