以性別預(yù)測(cè)為例,談?wù)?a href='/map/shujuwajue/' style='color:#000;font-size:inherit;'>數(shù)據(jù)挖掘中的分類(lèi)問(wèn)題
互聯(lián)網(wǎng)的迅猛發(fā)展���,催生了數(shù)據(jù)的爆炸式增長(zhǎng)����。面對(duì)海量的數(shù)據(jù)�,如何挖掘數(shù)據(jù)的價(jià)值,成為一個(gè)越來(lái)越重要的問(wèn)題�。本文首先介紹數(shù)據(jù)挖掘的基本內(nèi)容,然后按照數(shù)據(jù)挖掘基本的處理流程�����,以性別預(yù)測(cè)實(shí)例來(lái)講解一個(gè)具體的數(shù)據(jù)挖掘任務(wù)是如何實(shí)現(xiàn)的�����。
數(shù)據(jù)挖掘的基本內(nèi)容
首先����,對(duì)于數(shù)據(jù)挖掘的概念,目前比較廣泛認(rèn)可的一種解釋如下:
Data mining is the use of efficient techniques for the analysis of very large collections of data and the extraction of useful and possibly unexpected patterns in data.
數(shù)據(jù)挖掘是一種通過(guò)分析海量數(shù)據(jù)����,從數(shù)據(jù)中提取潛在的但是非常有用的模式的技術(shù)。
主要的數(shù)據(jù)挖掘任務(wù)
數(shù)據(jù)挖掘任務(wù)可以分為預(yù)測(cè)性任務(wù)和描述性任務(wù)���。預(yù)測(cè)性任務(wù)主要是預(yù)測(cè)可能出現(xiàn)的情況;描述性任務(wù)則是發(fā)現(xiàn)一些人類(lèi)可以解釋的模式或規(guī)律���。數(shù)據(jù)挖掘中比較常見(jiàn)的任務(wù)包括分類(lèi)�、聚類(lèi)��、關(guān)聯(lián)規(guī)則挖掘��、時(shí)間序列挖掘�����、回歸等��,其中分類(lèi)�����、回歸屬于預(yù)測(cè)性任務(wù)��,聚類(lèi)��、關(guān)聯(lián)規(guī)則挖掘����、時(shí)間序列分析等則都是解釋性任務(wù)。
按照數(shù)據(jù)挖掘的基本流程,來(lái)談?wù)劮诸?lèi)問(wèn)題
在簡(jiǎn)單介紹了數(shù)據(jù)挖掘的基本內(nèi)容后���,我們來(lái)切入主題�����。以數(shù)據(jù)挖掘的流程為主線,穿插性別預(yù)測(cè)的實(shí)例����,來(lái)講解分類(lèi)問(wèn)題。根據(jù)經(jīng)典教科書(shū)和實(shí)際工作經(jīng)驗(yàn)來(lái)看�,數(shù)據(jù)挖掘的基本流程主要包括五部分,首先是明確問(wèn)題����,第二是對(duì)數(shù)據(jù)進(jìn)行預(yù)處理,第三是對(duì)數(shù)據(jù)進(jìn)行特征工程�,轉(zhuǎn)化為問(wèn)題所需要的特征,第四是根據(jù)問(wèn)題的評(píng)價(jià)標(biāo)準(zhǔn)選擇最優(yōu)的模型和算法�,最后將訓(xùn)練的模型用于實(shí)際生產(chǎn),產(chǎn)出所需結(jié)果(如圖1所示)��。
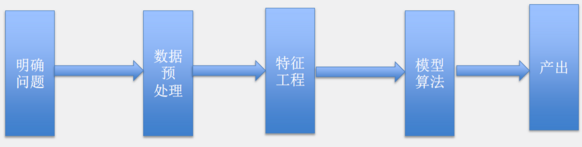
圖1 數(shù)據(jù)挖掘的基本流程
下面我們分別介紹各環(huán)節(jié)涉及的主要內(nèi)容:
1.明確問(wèn)題和了解數(shù)據(jù)
這一環(huán)節(jié)最重要的是需求和數(shù)據(jù)的匹配���。首先需要明確需求��,有著怎樣的需求?是需要做分類(lèi)���、聚類(lèi)���、推薦還是其他?實(shí)際數(shù)據(jù)是否支持該需求?比如,分類(lèi)問(wèn)題需要有或者可以構(gòu)造出training set�����,如果沒(méi)有training set�,就沒(méi)有辦法按照分類(lèi)問(wèn)題來(lái)解決。此外�,數(shù)據(jù)的規(guī)模、重要feature的覆蓋度等��,也是需要特別考慮的問(wèn)題�。
2.數(shù)據(jù)預(yù)處理
1)數(shù)據(jù)集成,數(shù)據(jù)冗余�����,數(shù)值沖突
數(shù)據(jù)挖掘中準(zhǔn)備數(shù)據(jù)的時(shí)候�,需要盡可能地將相關(guān)數(shù)據(jù)集成在一起。如果集成的數(shù)據(jù)中,有兩列或多列值一樣��,則不可避免地會(huì)產(chǎn)生數(shù)值沖突或數(shù)據(jù)冗余���,可能需要根據(jù)數(shù)據(jù)的質(zhì)量來(lái)決定保留沖突中的哪一列�。
2)數(shù)據(jù)采樣
一般來(lái)說(shuō)�����,有效的采樣方式如下:如果樣本是有代表性的���,則使用樣本數(shù)據(jù)和使用整個(gè)數(shù)據(jù)集的效果幾乎是一樣的。抽樣方法有很多�,需要考慮是有放回的采樣,還是無(wú)放回的采樣����,以及具體選擇哪種采樣方式��。
3)數(shù)據(jù)清洗、缺失值處理與噪聲數(shù)據(jù)
現(xiàn)實(shí)世界中的數(shù)據(jù)��,是真實(shí)的數(shù)據(jù)�,不可避免地會(huì)存在各種各樣的異常情況。比如某列的值缺失�����,或者某列的值是異常的����,所以,我們需要在數(shù)據(jù)預(yù)處理階段進(jìn)行數(shù)據(jù)清洗�����,來(lái)減少噪音數(shù)據(jù)對(duì)模型訓(xùn)練和預(yù)測(cè)結(jié)果的影響�。
3.特征工程
數(shù)據(jù)和特征決定了機(jī)器學(xué)習(xí)的上限,而模型和算法只是逼近這個(gè)上限而已�。下面的觀點(diǎn)說(shuō)明了特征工程的特點(diǎn)和重要性。
Feature engineering is another topic which doesn’t seem to merit any review papers or books, or even chapters in books, but it is absolutely vital to ML success. […] Much of the success of machine learning is actually success in engineering features that a learner can understand.
— Scott Locklin, in “Neglected machine learning ideas”
1)特征:對(duì)所需解決問(wèn)題有用的屬性
特征是對(duì)你所需解決問(wèn)題有用或者有意義的屬性���。比如���,在計(jì)算機(jī)視覺(jué)領(lǐng)域�����,圖片作為研究對(duì)象���,可能圖片中的一個(gè)線條就是一個(gè)特征;在自然語(yǔ)言處理領(lǐng)域中,研究對(duì)象是文檔���,文檔中的一個(gè)詞語(yǔ)的出現(xiàn)次數(shù)就是一個(gè)特征;在語(yǔ)音識(shí)別領(lǐng)域中��,研究對(duì)象是一段話���,phoneme(音位)可能就是一個(gè)特征。
2)特征的提取�����、選擇和構(gòu)造
既然特征是對(duì)我們所解決的問(wèn)題最有用的屬性�����。首先我們需要處理的是根據(jù)原始數(shù)據(jù)抽取出所需要的特征�。亟需注意的是���,并不是所有的特征對(duì)所解決的問(wèn)題產(chǎn)生的影響一樣大��,有些特征可能對(duì)問(wèn)題產(chǎn)生特別大的影響���,但有些則可能影響甚微�����,和所解決的問(wèn)題不相關(guān)的特征需要被剔除掉��。因此���,我們需要針對(duì)所解決的問(wèn)題選擇最有用的特征集合,一般可以通過(guò)相關(guān)系數(shù)等方式來(lái)計(jì)算特征的重要性����。當(dāng)然,有些模型本身會(huì)輸出feature重要性�,如Random Forest等算法。而對(duì)于圖片���、音頻等原始數(shù)據(jù)形態(tài)特別大的對(duì)象�,則可能需要采用像PCA這樣的自動(dòng)降維技術(shù)����。另外�����,還可能需要本人對(duì)數(shù)據(jù)和所需解決的問(wèn)題有深入的理解��,能夠通過(guò)特征組合等方法構(gòu)造出新的特征����,這也正是特征工程被稱(chēng)之為是一門(mén)藝術(shù)的原因之一����。
實(shí)例講解(一)
接下來(lái),我們通過(guò)一個(gè)性別預(yù)測(cè)的實(shí)例來(lái)說(shuō)明數(shù)據(jù)挖掘處理流程中的“明確問(wèn)題”��、“數(shù)據(jù)預(yù)處理”和“特征工程”三個(gè)部分����。
假設(shè)我們有如下兩種數(shù)據(jù)��,想根據(jù)數(shù)據(jù)訓(xùn)練一個(gè)預(yù)測(cè)用戶(hù)性別的模型�����。
數(shù)據(jù)1: 用戶(hù)使用App的行為數(shù)據(jù);
數(shù)據(jù)2: 用戶(hù)瀏覽網(wǎng)頁(yè)的行為數(shù)據(jù);
第一步:明確問(wèn)題
首先明確該問(wèn)題屬于數(shù)據(jù)挖掘常見(jiàn)問(wèn)題中的哪一類(lèi), 是分類(lèi)����、聚類(lèi),推薦還是其他?假設(shè)本實(shí)例數(shù)據(jù)有部分?jǐn)?shù)據(jù)帶有男女性別����,則該問(wèn)題為分類(lèi)問(wèn)題;
數(shù)據(jù)集是否夠大?我們需要足夠大的數(shù)據(jù)來(lái)訓(xùn)練模型,如果數(shù)據(jù)集不夠大�,那么所訓(xùn)練的模型和真實(shí)情況偏差會(huì)比較大;
數(shù)據(jù)是否滿(mǎn)足所解決問(wèn)題的假設(shè)?統(tǒng)計(jì)發(fā)現(xiàn)男人和女人使用的App不太一致,瀏覽網(wǎng)頁(yè)的內(nèi)容也不太一致�����,則說(shuō)明我們通過(guò)數(shù)據(jù)可以提取出對(duì)預(yù)測(cè)性別有用的特征����,來(lái)幫助解決問(wèn)題。如果根據(jù)數(shù)據(jù)提取不出有用的特征��,那么針對(duì)當(dāng)前數(shù)據(jù)���,問(wèn)題是沒(méi)法處理的�����。
第二步:數(shù)據(jù)預(yù)處理
實(shí)際工作中�����,在數(shù)據(jù)預(yù)處理之前需要確定整個(gè)項(xiàng)目的編程語(yǔ)言(如Python����、Java、 Scala)和開(kāi)發(fā)工具(如Pig�����、Hive�、Spark)。通常而言����,編程語(yǔ)言和開(kāi)發(fā)工具的選擇都依賴(lài)于所處的數(shù)據(jù)平臺(tái)環(huán)境;
選取多少數(shù)據(jù)做模型訓(xùn)練?這是常說(shuō)的數(shù)據(jù)采樣問(wèn)題。一般認(rèn)為采樣數(shù)據(jù)量越大����,對(duì)所解決的任務(wù)幫助越大,但是數(shù)據(jù)量越大��,計(jì)算代價(jià)也越大���,因此��,需要在解決問(wèn)題的效果和計(jì)算代價(jià)之間折中一下;
把所有相關(guān)的數(shù)據(jù)聚合在一起�,如果有相同字段則存在數(shù)據(jù)冗余的問(wèn)題��,需要根據(jù)數(shù)據(jù)的質(zhì)量剔除掉冗余的數(shù)據(jù);數(shù)據(jù)中可能存在異常值�����,則需要過(guò)濾掉;數(shù)據(jù)中可能有的值有缺失�,則需要填充默認(rèn)值。
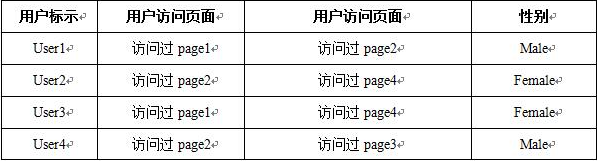
數(shù)據(jù)預(yù)處理后可能的結(jié)果(如表1��、表2所示):
表1 數(shù)據(jù)1預(yù)處理后結(jié)果
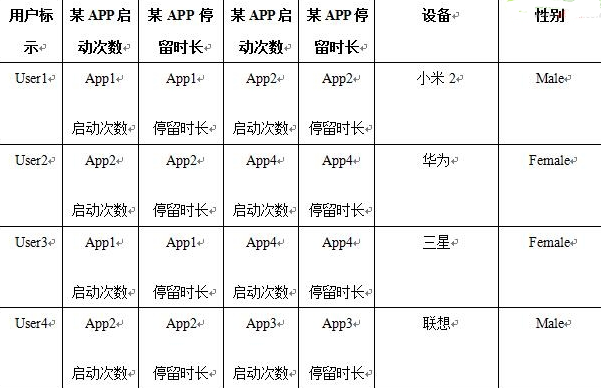
表2 數(shù)據(jù)2預(yù)處理后結(jié)果
第三步:特征工程
由于數(shù)據(jù)1和數(shù)據(jù)2的類(lèi)型不太一樣���,所以進(jìn)行特征工程時(shí)����,所采用的方法也不太一樣�,下面分別介紹一下:
數(shù)據(jù)1的特征工程
數(shù)據(jù)1的單個(gè)特征的分析主要包括以下內(nèi)容:
數(shù)值型特征的處理,比如App的啟動(dòng)次數(shù)是個(gè)連續(xù)值���,可以按照低����、中、高三個(gè)檔次將啟動(dòng)次數(shù)分段成離散值;
類(lèi)別型特征的處理��,比如用戶(hù)使用的設(shè)備是三星或者聯(lián)想����,這是一個(gè)類(lèi)別特征,可以采用0-1編碼來(lái)處理;
需要考慮特征是否需要?dú)w一化�����。
數(shù)據(jù)1的多個(gè)特征的分析主要包括以下內(nèi)容:
使用的設(shè)備類(lèi)型是否決定了性別?需要做相關(guān)性分析���,通常計(jì)算相關(guān)系數(shù);
App的啟動(dòng)次數(shù)和停留時(shí)長(zhǎng)是否完全正相關(guān)��,結(jié)果表明特別相關(guān)����,則說(shuō)明App的停留時(shí)長(zhǎng)是無(wú)用特征��,將App的停留時(shí)長(zhǎng)這個(gè)特征過(guò)濾掉;
如果特征太多�,可能需要做降維處理�。
2.數(shù)據(jù)2的特征工程
數(shù)據(jù)2是典型的文本數(shù)據(jù)���,文本數(shù)據(jù)常用的處理步驟包含以下幾個(gè)部分:
網(wǎng)頁(yè) → 分詞 → 去停用詞 → 向量化
分詞?�?梢圆捎肑ieba分詞(Python庫(kù))或張華平老師的ICTCLAS;
去除停用詞�。停用詞表除了加入常規(guī)的停用詞外,還可以將DF(Document Frequency)比較高的詞加入停用詞表�����,作為領(lǐng)域停用詞;
向量化��。一般是將文本轉(zhuǎn)化為T(mén)F或TF-IDF向量�。
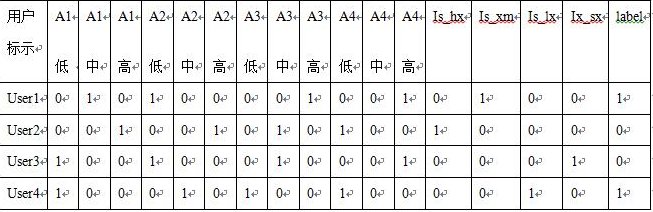
特征工程后數(shù)據(jù)1的結(jié)果(如表3所示,A1低表示啟動(dòng)App1的次數(shù)比較低��,以此類(lèi)推�,is_hx表示設(shè)備是否是華為,Label為1表示Male)�。
表3 數(shù)據(jù)1特征工程后結(jié)果
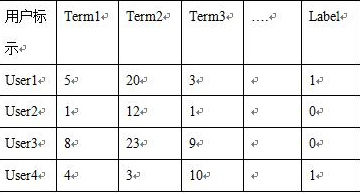
特征工程后數(shù)據(jù)2的結(jié)果(如表4所示,term1=5表示user1瀏覽的網(wǎng)頁(yè)中出現(xiàn)詞1的頻率�,以此類(lèi)推)。
表4 數(shù)據(jù)2特征工程后結(jié)果
第四步:算法和模型
做完特征工程后�,下一步就是選擇合適的模型和算法。算法和模型的選擇主要考慮一下幾個(gè)方面:
訓(xùn)練集的大小;
特征的維度大小;
所解決問(wèn)題是否是線性可分的;
所有的特征是獨(dú)立的嗎?
需要不需要考慮過(guò)擬合的問(wèn)題;
對(duì)性能有哪些要求?
上面中提到的很多問(wèn)題沒(méi)法直接回答,可能我們還是不知道該選擇哪種模型和算法��,但是奧卡姆剃刀原理給出了模型和算法的選擇方法:
Occam’s Razor principle: use the least complicated algorithm that can address your needs and only go for something more complicated if strictly necessary.
業(yè)界比較通用的算法選擇一般是這樣的規(guī)律:如果LR可以�,則使用LR;如果LR不適合,則選擇Ensemble的方式;如果Ensemble方式不適合����,則考慮是否嘗試Deep Learning。下面主要介紹一下LR算法和Ensemble方法的相關(guān)內(nèi)容��。
LR算法(Logistic Regression����,邏輯回歸算法)
只要認(rèn)為問(wèn)題是線性可分的,就可采用LR�����,通過(guò)特征工程將一些非線性特征轉(zhuǎn)化為線性特征����。 模型比較抗噪,而且可以通過(guò)L1�����、L2范數(shù)來(lái)做參數(shù)選擇。LR可以應(yīng)用于數(shù)據(jù)特別大的場(chǎng)景����,因?yàn)樗乃惴ㄐ侍貏e高,且很容易分布式實(shí)現(xiàn)����。
區(qū)別于其他大多數(shù)模型���,LR比較特別的一點(diǎn)是結(jié)果可以解釋為概率����,能將問(wèn)題轉(zhuǎn)為排序問(wèn)題而不是分類(lèi)問(wèn)題��。
Ensemble方法(組合方法)
組合方法的原理主要是根據(jù)training set訓(xùn)練多個(gè)分類(lèi)器�,然后綜合多個(gè)分類(lèi)器的結(jié)果,做出預(yù)測(cè)(如圖2所示)���。
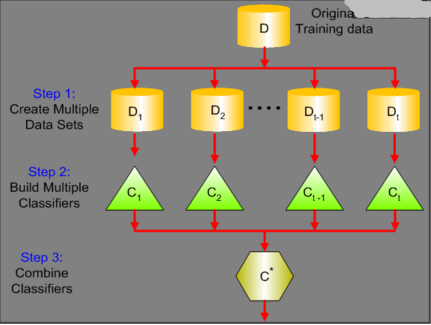
圖2 組合方法的基本流程
組合方式主要分為Bagging和Boosting�����。Bagging是Bootstrap Aggregating的縮寫(xiě)�����,基本原理是讓學(xué)習(xí)算法訓(xùn)練多輪���,每輪的訓(xùn)練集由從初始的訓(xùn)練集中隨機(jī)取出的n個(gè)訓(xùn)練樣本組成(有放回的隨機(jī)抽樣)�����,訓(xùn)練之后可得到一個(gè)預(yù)測(cè)函數(shù)集合��,通過(guò)投票方式?jīng)Q定預(yù)測(cè)結(jié)果�����。
而B(niǎo)oosting中主要的是AdaBoost(Adaptive Boosting)��?����;驹硎浅跏蓟瘯r(shí)對(duì)每一個(gè)訓(xùn)練樣本賦相等的權(quán)重1/n��,然后用學(xué)習(xí)算法對(duì)訓(xùn)練集訓(xùn)練多輪�,每輪結(jié)束后�����,對(duì)訓(xùn)練失敗的訓(xùn)練樣本賦以較大的權(quán)重。也就是讓學(xué)習(xí)算法在后續(xù)的學(xué)習(xí)中集中對(duì)比較難的訓(xùn)練樣本進(jìn)行學(xué)習(xí)����,從而得到一個(gè)預(yù)測(cè)函數(shù)集合。每個(gè)預(yù)測(cè)函數(shù)都有一定的權(quán)重�����,預(yù)測(cè)效果好的預(yù)測(cè)函數(shù)權(quán)重較大�����,反之較小����,最終通過(guò)有權(quán)重的投票方式來(lái)決定預(yù)測(cè)結(jié)果�。
Bagging和Boosting的主要區(qū)別如下:
取樣方式不同。Bagging采用均勻取樣����,而B(niǎo)oosting根據(jù)錯(cuò)誤率來(lái)取樣,因此理論上來(lái)講Boosting的分類(lèi)精度要優(yōu)于Bagging;
訓(xùn)練集的選擇方式不同�。Bagging的訓(xùn)練集的選擇是隨機(jī)的���,各輪訓(xùn)練集之間相互獨(dú)立,而B(niǎo)oostng的各輪訓(xùn)練集的選擇與前面的學(xué)習(xí)結(jié)果有關(guān);
預(yù)測(cè)函數(shù)不同�。Bagging的各預(yù)測(cè)函數(shù)沒(méi)有權(quán)重,而B(niǎo)oosting是有權(quán)重的�。Bagging的各個(gè)預(yù)測(cè)函數(shù)可以并行生成,而B(niǎo)oosting的各個(gè)預(yù)測(cè)函數(shù)只能順序生成�����。
對(duì)于像神經(jīng)網(wǎng)絡(luò)這樣極其耗時(shí)的學(xué)習(xí)方法��,Bagging可通過(guò)并行訓(xùn)練節(jié)省大量時(shí)間開(kāi)銷(xiāo)�。Bagging和Boosting都可以有效地提高分類(lèi)的準(zhǔn)確性。在大多數(shù)數(shù)據(jù)集中���,Boosting的準(zhǔn)確性比Bagging要高�。
分類(lèi)算法的評(píng)價(jià)
上一部分介紹了常用的模型和算法���,不同的算法在不同的數(shù)據(jù)集上會(huì)產(chǎn)生不同的效果��,我們需要量化算法的好壞���,這就是分類(lèi)算法的評(píng)價(jià)���。在本文中,筆者將主要介紹一下混淆矩陣和主要的評(píng)價(jià)指標(biāo)���。
1.混淆矩陣(如圖3所示)
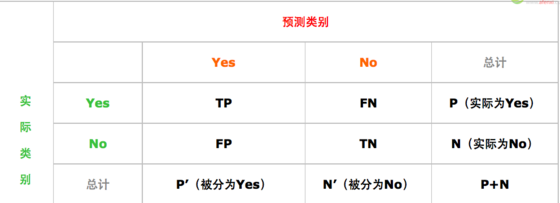
圖3 混淆矩陣
1)True positives(TP):即實(shí)際為正例且被分類(lèi)器劃分為正例的樣本數(shù);
2)False positives(FP):即實(shí)際為負(fù)例但被分類(lèi)器劃分為正例的樣本數(shù);
3)False negatives(FN):即實(shí)際為正例但被分類(lèi)器劃分為負(fù)例的樣本數(shù);
4)True negatives(TN):即實(shí)際為負(fù)例且被分類(lèi)器劃分為負(fù)例的樣本數(shù)�。
2.主要的評(píng)價(jià)指標(biāo)
1)準(zhǔn)確率accuracy=(TP+TN)/(P+N)��。這個(gè)很容易理解�����,就是被分對(duì)的樣本數(shù)除以所有的樣本數(shù)����。通常來(lái)說(shuō)���,準(zhǔn)確率越高�,分類(lèi)器越好;
2)召回率recall=TP/(TP+FN)���。召回率是覆蓋面的度量��,度量有多少個(gè)正例被分為正例�����。
3)ROC和AUC����。
實(shí)例講解(二)
實(shí)例(一)產(chǎn)出的特征數(shù)據(jù),經(jīng)過(guò)“模型和算法”以及“算法的評(píng)價(jià)”兩部分所涉及的代碼實(shí)例如圖4所示�����。
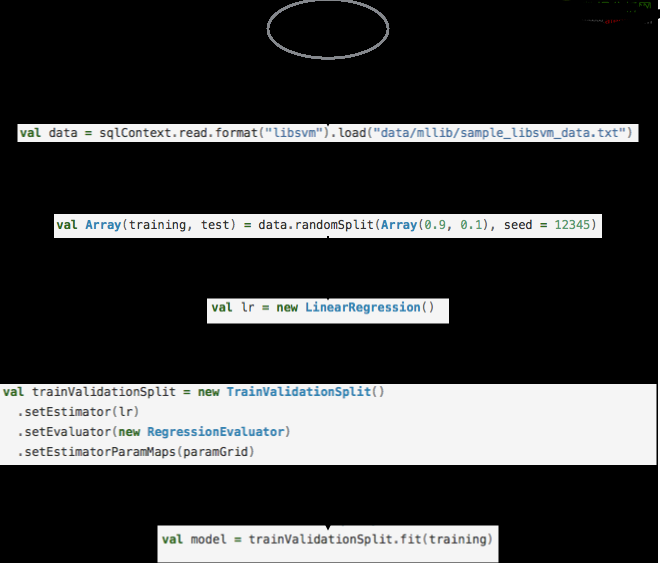
圖4 模型訓(xùn)練示例代碼
總結(jié)
本文以數(shù)據(jù)挖掘的基本處理流程為主線���,以性別預(yù)測(cè)為具體實(shí)例�����,介紹了處理一個(gè)數(shù)據(jù)挖掘的分類(lèi)問(wèn)題所涉及的方方面面����。對(duì)于一個(gè)數(shù)據(jù)挖掘問(wèn)題��,首先要明確問(wèn)題��,確定已有的數(shù)據(jù)是否能夠解決所需要解決的問(wèn)題,然后就是數(shù)據(jù)預(yù)處理和特征工程階段����,這往往是在實(shí)際工程中最耗時(shí)、最麻煩的階段�。經(jīng)過(guò)特征工程后,需要選擇合適的模型進(jìn)行訓(xùn)練��,并且根據(jù)評(píng)價(jià)標(biāo)準(zhǔn)選擇最優(yōu)模型和最優(yōu)參數(shù)����, 最后根據(jù)最優(yōu)模型對(duì)未知數(shù)據(jù)進(jìn)行預(yù)測(cè),產(chǎn)出結(jié)果�����。希望本文的內(nèi)容對(duì)大家有所幫助����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情��;
? 想學(xué)習(xí)CDA考試教材�����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫(kù)���,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情;
? 想了解CDA考試含金量��,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330