數(shù)據(jù)挖掘必須要具備知識結(jié)構(gòu)類型
一���、概念/類描述
概念/類描述就是通過對某類對象關(guān)聯(lián)數(shù)據(jù)的匯總,分析和比較,用匯總的簡潔的精確的方式對此類對象的內(nèi)涵進(jìn)行描述,并概括這類對象的有關(guān)特征��。概念描述分為:特征性描述和區(qū)別性描述����。
特征性描述:是指從與某類對象相關(guān)的一組數(shù)據(jù)中提取出關(guān)于這些對象的共同特征。生成一個類的特征性描述只涉及該類對象中所有對象的同性����。。
區(qū)別性描述:描述兩個或者更多不同類對象之間的差異��。生成區(qū)別性描述則涉及目標(biāo)類和對比類中對象的共性��。
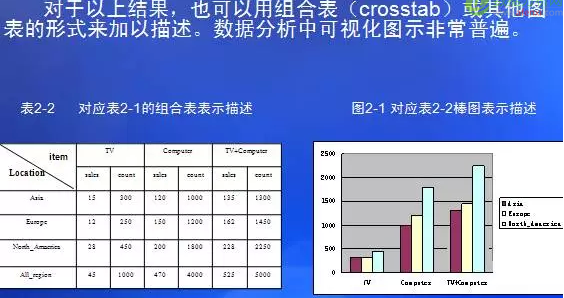
數(shù)據(jù)特征的輸出可以用多種形式提供:包括 餅圖�,條圖,曲線�����,多維數(shù)據(jù)方和包括交叉表在內(nèi)的多維表�����。結(jié)果描述也可以用泛化關(guān)系或規(guī)則(稱作特征性規(guī)則)形式提供
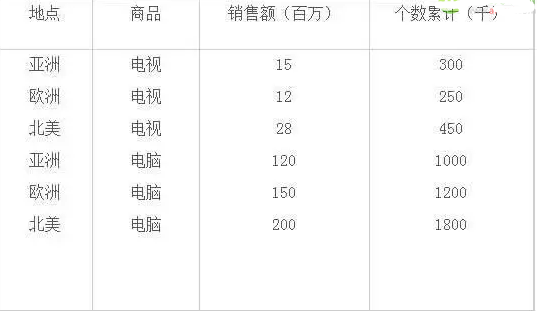
例如:利用面向?qū)傩缘臍w納方法(AOI)�,在一個商場數(shù)據(jù)庫(2000銷售)中進(jìn)行屬性歸納操作���,獲得了如下的歸納結(jié)果:
表2-1 AOI方法挖掘結(jié)果表格表示示意描述
區(qū)別性描述是將目標(biāo)類對象的一般特性與一個或多個對比類對象的一般特性比較��,這種比較必須是在具備可比性的兩個或多個類之間進(jìn)行�。
例如,對某校講師和副教授的特征進(jìn)行比較��,可能會得到這樣一條規(guī)則: “講師:(78%)(paper<3)and (teaching course<2)”���,而 “副教授:(66%)(paper>=3)and (teaching course>=2)”; 該對比規(guī)則表示該校講師中約有四分至三的人發(fā)表論文少于三篇且主講課程不超過一門;而對比之下該校副教授中約有三分至二 的人發(fā)表論文不少于三篇且主講課程不少于一門���。
二、關(guān)聯(lián)模式
關(guān)聯(lián)模式挖掘旨在從大量的數(shù)據(jù)當(dāng)中發(fā)現(xiàn)特征之間或者數(shù)據(jù)之間的相互依賴關(guān)系����。這種存在于給定數(shù)據(jù)集中的頻繁出現(xiàn)的關(guān)聯(lián)模式,又稱為關(guān)聯(lián)規(guī)則���。關(guān)聯(lián)可以分為簡單關(guān)聯(lián)���,時序關(guān)聯(lián),因果關(guān)聯(lián)等�����。這些關(guān)聯(lián)并不總是事先知道,而是通過數(shù)據(jù)庫中數(shù)據(jù)的關(guān)聯(lián)分析獲得的�,其對商業(yè)決策具有重要的價值,因而關(guān)聯(lián)分析廣泛用于市場營銷�����,事物分析等領(lǐng)域�����。
挖掘關(guān)聯(lián)知識的一個典型應(yīng)用實例就是市場購物分析���。根據(jù)被放到一個購物袋的(購物)內(nèi)容記錄數(shù)據(jù)而發(fā)現(xiàn)的不同(被購買)商品之間所存在的關(guān)聯(lián)知識無疑將會幫助商家分析顧客的購買習(xí)慣����。發(fā)現(xiàn)常在一起被購買的商品(關(guān)聯(lián)知識)將幫助商家指定有針對性的市場策略���。
比如:顧客在購買牛奶時�,是否也可能同時購買面包或會購買哪個牌子的面包����,顯然能夠回答這些問題的有關(guān)信息肯定回有效地幫助商家進(jìn)行有針對性的促銷,以及進(jìn)行合適的貨架商品擺放�����。如可以將牛奶和面包放在相近的地方或許會促進(jìn)這兩個商品的銷售���。
根據(jù)關(guān)聯(lián)規(guī)則所涉及變量的多少�����,可以分為多維關(guān)聯(lián)規(guī)則和單維關(guān)聯(lián)規(guī)則���, 通常,關(guān)聯(lián)規(guī)則具有:X=>Y的形式���,即:A1^…^Am=>B1^…^Bn的規(guī)則����,其中, Ai (i屬于{1,…,m}), Bj (j屬于{1,…,n})是屬性-值對���。關(guān)聯(lián)規(guī)則X => Y解釋為“滿足X中條件的數(shù)據(jù)庫元組多半也滿足Y中條件”��。
例如:一個數(shù)據(jù)挖掘系統(tǒng)可以從一個商場的銷售(交易事務(wù)處理)記錄數(shù)據(jù)中��,挖掘出如下所示的關(guān)聯(lián)規(guī)則: age(X,”20-29”)∧income(X,”20K-30K”) Tbuys(X�,”mp3”)[support=2%,confidence=60%]上述關(guān)聯(lián)規(guī)則表示:該商場有的顧客年齡在20歲到29歲且收入在2 萬到3萬之間,這群顧客中有60%的人購買了MP3�����,或者說這群顧客購買MP3的概率為六成�。這一規(guī)則涉及到年齡、收入和購買三個變量(即三維)�����,可稱為多維關(guān)聯(lián)規(guī)則���。
對于一個商場經(jīng)理����,或許更想知道哪些商品是常被一起購買�����,描述這種情況的一條關(guān)聯(lián)規(guī)則可能是:Contains(X,”computer”) =>contain(X,”software”) [support=1%,confidence=60%]上述關(guān)聯(lián)規(guī)則表示:該商場1%銷售交易事物記錄中包含“computer”和 “software”兩個商品;而對于一條包含(購買)“computer”商品的交a易事物記錄有60%可能也包含(購買)”software”商品��。這條記錄中由于只涉及到購買事物這一個變量����,所以稱為單維關(guān)聯(lián)規(guī)則�����。
三、分類
分類是數(shù)據(jù)挖掘中一項非常重要的任務(wù)���,利用分類可以從數(shù)據(jù)集中提取描述數(shù)據(jù)類的一個函數(shù)或模型(也常稱為分類器)�,并把數(shù)據(jù)集中的每個對象歸結(jié)到某個已知的對象類中���。從機(jī)器學(xué)習(xí)的觀點����,分類技術(shù)是一種有指導(dǎo)(我們通常稱之為有監(jiān)督)的學(xué)習(xí)��,即每個訓(xùn)練樣本的數(shù)據(jù)對象已經(jīng)有類的標(biāo)識���,通過學(xué)習(xí)可以形成表達(dá)數(shù)據(jù)對象與類標(biāo)識間對應(yīng)的知識��。從這個意義上說�,數(shù)據(jù)挖掘的目標(biāo)就是根據(jù)樣本數(shù)據(jù)形成的類知識并對源數(shù)據(jù)進(jìn)行分類���,進(jìn)而也可以預(yù)測未來數(shù)據(jù)的分類�����。(十一城注:這里的分類和日常生活中的分類含義有些不一樣��,它是將數(shù)據(jù)映射到預(yù)先定好的群組或者類中��。所以很明顯����,它是有監(jiān)督/指導(dǎo)的,即它預(yù)先定好了東西來引導(dǎo)別人分類����。)
分類挖掘所獲的分類模型可以采用多種形式加以描述輸出,其中主要的表示方法有:分類規(guī)則(IF-THEN)����,決策樹(decision tree),數(shù)學(xué)公式(mathematical formulae)和神經(jīng)網(wǎng)絡(luò)����。
決策樹是一個類似于流程圖的結(jié)構(gòu),每個節(jié)點代表一個屬性上的值��,每個分枝代表測試的一個輸出�����,樹葉代表類或者類分布。決策樹容易轉(zhuǎn)換成分類規(guī)則�。
神經(jīng)網(wǎng)絡(luò)用于分類的時候,是一組類似于神經(jīng)元的處理單元�����,單元之間加權(quán)連接���。
另外,最近有興起了一種新的方法—粗糙集(rough set)其知識表示是生產(chǎn)式規(guī)則��。
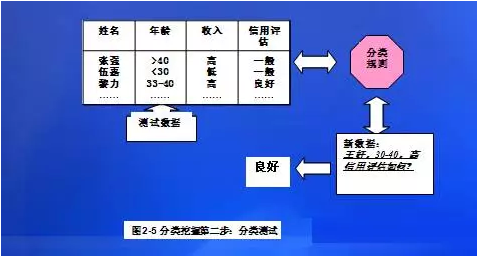
分類通常用來預(yù)測對象的類標(biāo)號��。例如��,銀行信貸部門可以根據(jù)一個顧客信用信息數(shù)據(jù)庫�,將功課的信用等級記錄為一般或良好,然后根據(jù)挖掘得出信用良好的顧客信息特征�����,應(yīng)用這些特征描述���,可以有效發(fā)現(xiàn)優(yōu)質(zhì)客戶��。這一分類過程主要含有兩個步驟:
(1)建立一個已知數(shù)據(jù)集類別或概念的模型����。
(2)對學(xué)習(xí)所獲模型的準(zhǔn)確率進(jìn)行測試。如下圖所示
四�����、聚類分析
與分類技術(shù)不同�����,在機(jī)器學(xué)習(xí)中���,聚類是一種無指導(dǎo)學(xué)習(xí)�。也就是說���,聚類分析是在預(yù)先不知道欲劃分類的情況下�����,根據(jù)信息相似度原則進(jìn)行信息集聚的一種方法��。聚類的目的是使得屬于同一類別的個體之間的差別盡可能的小��,而不同類別上的個體見的差別盡可能的大��。因此��,聚類的意義就在于將觀察到的內(nèi)容組織成類分層結(jié)構(gòu)�,把類似的事物組織在一起。通過聚類����,人們能夠識別密集的和稀疏的區(qū)域���,因而發(fā)現(xiàn)全局的分布模式����,以及數(shù)據(jù)屬性之間的有趣的關(guān)系�����。(十一城注:聚類和分類的區(qū)別在于聚類是無監(jiān)督學(xué)習(xí)���,分類是有監(jiān)督學(xué)習(xí)��。聚類其實也可以理解為是一種分類��,只是它這種分類)
數(shù)據(jù)聚類分析是一個正在蓬勃發(fā)展的領(lǐng)域�����。聚類技術(shù)主要是以統(tǒng)計方法��、機(jī)器學(xué)習(xí)��、神經(jīng)網(wǎng)絡(luò)等方法為基礎(chǔ)��。比較有代表性的聚類技術(shù)是基于幾何距離的聚類方法��,如歐氏距離�、曼哈坦(Manhattan)距離、明考斯基(Minkowski)距離等���。
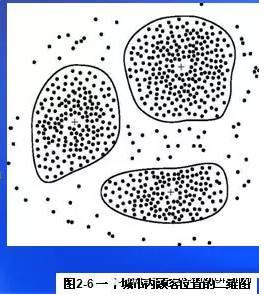
聚類分析廣泛應(yīng)用于商業(yè)���、生物、地理�����、網(wǎng)絡(luò)服務(wù)等多種領(lǐng)域。例如���,聚類可以幫助市場分析人員從客戶基本庫中發(fā)現(xiàn)不同的客戶群�����,并能用不同的購買模式來刻畫不同的客戶群的特征�����,如圖2-6顯示了一個城市內(nèi)顧客位置的二維圖���,數(shù)據(jù)點的三個簇是顯而易見的。聚類還可以從地球觀測數(shù)據(jù)庫中幫助識別具有相似土地使用情況的區(qū)域;以及可以幫助分類識別互聯(lián)網(wǎng)上的文檔以便進(jìn)行信息發(fā)現(xiàn)等等�。
五��、預(yù)測
預(yù)測型知識(Prediction)是指由歷史的和當(dāng)前的數(shù)據(jù)產(chǎn)生的并能推測未來數(shù)據(jù)趨勢的知識�。這類知識可以被認(rèn)為是以時間為關(guān)鍵屬性的關(guān)聯(lián)知識,因此上面介紹的關(guān)聯(lián)知識挖掘方法可以應(yīng)用到以時間為關(guān)鍵屬性的源數(shù)據(jù)挖掘中�����。
前面介紹分類知識挖掘時曾經(jīng)提到過:分類通常用來預(yù)測對象的類標(biāo)號。然而�,在某些應(yīng)用中,人們可能希望預(yù)測某些遺漏的或不知道的數(shù)據(jù)值�����,而不是類標(biāo)號�。當(dāng)被預(yù)測的值是數(shù)值數(shù)據(jù)時,通常稱之為預(yù)測���。
也就是說�,預(yù)測用于預(yù)測數(shù)據(jù)對象的連續(xù)取值��,如:可以構(gòu)造一個分類模型來對銀行貸款進(jìn)行風(fēng)險評估(安全或危險);也可建立一個預(yù)測模型以利用顧客收入與職業(yè)(參數(shù))預(yù)測其可能用于購買計算機(jī)設(shè)備的支出大小
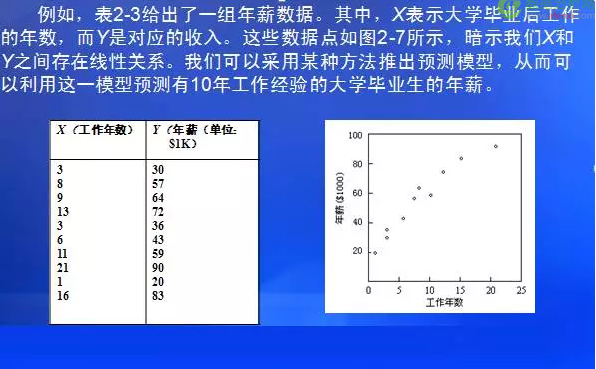
預(yù)測型知識的挖掘可以利用統(tǒng)計學(xué)中的回歸方法�,通過歷史數(shù)據(jù)直接產(chǎn)生連續(xù)的對未來數(shù)據(jù)的預(yù)測值;可以借助于經(jīng)典的統(tǒng)計方法、神經(jīng)網(wǎng)絡(luò)和機(jī)器學(xué)習(xí)等技術(shù)�。無論如何,經(jīng)典的統(tǒng)計學(xué)方法是挖掘預(yù)測知識的基礎(chǔ)���。
六��、時間序列
具有一個或多個時間屬性的預(yù)測應(yīng)用稱為時間序列問題���。時間序列是數(shù)據(jù)存在的特殊形式��,序列的過去值會影響到將來值��,這種影響的大小以及影響的方式可由時間序列中的趨勢周期及非平穩(wěn)等行為來刻畫�����。
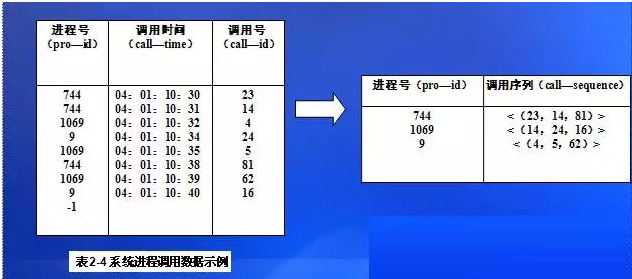
例如:系統(tǒng)調(diào)用日志記錄了操作系統(tǒng)及其系統(tǒng)進(jìn)程調(diào)用的時間序列�����,通過對正常調(diào)用序列的學(xué)習(xí)可以預(yù)測隨后發(fā)生的系統(tǒng)調(diào)用序列���、發(fā)現(xiàn)異常的調(diào)用。表2-4給出了一個系統(tǒng)調(diào)用數(shù)據(jù)表��。 這樣的數(shù)據(jù)源可以通過適當(dāng)?shù)臄?shù)據(jù)整理使之成為調(diào)用序列���,如表2-5��,再通相應(yīng)的挖掘算法達(dá)到跟蹤和分析操作系統(tǒng)審計數(shù)據(jù)的目的���。
七�、偏差檢測
偏差檢測(deviation detection)就是對數(shù)據(jù)集中的偏差數(shù)據(jù)進(jìn)行檢測與分析���。
在要處理的大量數(shù)據(jù)中,常常存在一些異常數(shù)據(jù)����,它們與其它的數(shù)據(jù)的一般行為或模型不一致。這里數(shù)據(jù)記錄就是偏差(deviation)�,也就是孤立點。
偏差包括很多潛在的知識��,如不滿足常規(guī)類的異常例子�����、分類中出現(xiàn)的反常實例��、在不同時刻發(fā)生了顯著變化的某個對象或集合����、觀察值與模型推測出的期望值之間有顯著差異的事例等。
偏差的產(chǎn)生可能是某種數(shù)據(jù)錯誤造成的���,也可能是數(shù)據(jù)變異所固有的結(jié)果���。從數(shù)據(jù)集中檢測出這些偏差很有意義����,例如在欺詐探測中��,偏差可能預(yù)示著欺詐行為��。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學(xué)習(xí)CDA考試教材,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330