SPSS數(shù)據(jù)分析:如何刪除重復(fù)個案
很早的時候�,大家在SPSS中處理單個變量的重復(fù)值通常都是這樣的做法,首先將要處理的數(shù)據(jù)進行排序���,然后將其復(fù)制后在從新變量的第二行開始粘貼����,得到了兩個觀察量錯開一個位置的變量 �,然后對這兩個變量進行相減�����,最后挑選或刪除為零的選項以獲得完全無重復(fù)的數(shù)據(jù)���。這樣的做起來不算困難,但處理2個或2個以上變量的重復(fù)值就顯得有點乏力了���。下面就芒果的例子利用SPSS syntax對重復(fù)觀測值的處理進行相關(guān)探討����,簡要數(shù)據(jù)如下:
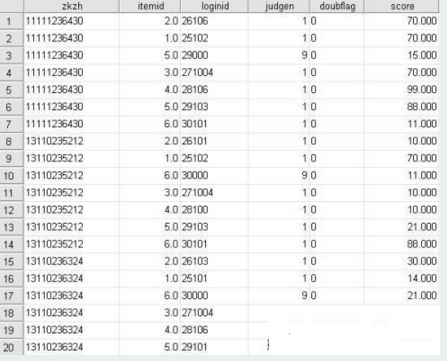
問題1.找出上表中zkzh相同且itemid也相同的所有記錄�。
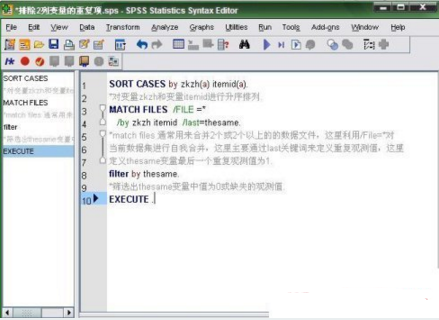
上圖是syntax命令及說明,關(guān)于sort cases/match files/filter等命令見下面小貼士的說明,首先看看數(shù)據(jù)處理結(jié)果:
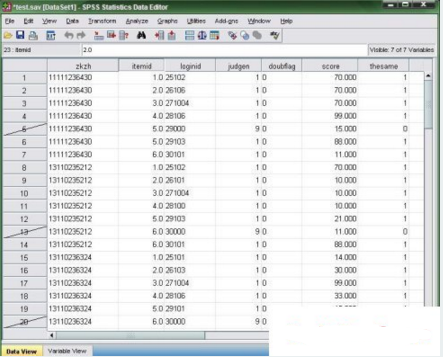
問題2. 如何快速的分離出被篩選的變量�?
還是利用上面的例子,我們利用dataset copy命令將被篩選出的觀測值快速的篩選出來�����,形成一個新的數(shù)據(jù)集���。
#1Filter off.
#2Dataset copy shaixuanji.
#3DATASET ACTIVATEshaixuanji.
#4SELECT IF thesame=0.
#5EXECUTE .
代碼解析:
第1行命令利用filter off命令清除上面的篩選效果���。
第2行命令式將當(dāng)前數(shù)據(jù)集復(fù)制到新的數(shù)據(jù)集shaixuanji中�。
第3-4行命令是激活數(shù)據(jù)集shaixuanji�,并且選擇thesame變量中值為0的觀測值(其他的默認刪除)。
第5行命令是即時運算命令����。
效果如下:
如果不想要這么多的變量,可以使用save outfile.../keep(drop)命令選擇自己需要的變量��。
問題3.有時候我們并不知道如何篩選重復(fù)值���,而是事先觀察比較重復(fù)值的相關(guān)特性��,然后做下一步的處理,那么如何選擇輸出重復(fù)值的相關(guān)信息呢�?
這里還是利用最初的數(shù)據(jù)進行說明,由于目的不同����,這里篩選查找重復(fù)觀測值的方式也不同。問題1中采用的是match files命令來處理重復(fù)值����,這里換一種方法,利用aggregate分類匯總命令來計量重復(fù)值,進而作進一步的匯總說明��,具體代碼如下:
#1AGGREGATE OUTFILE = * MODE = ADDVARIABLES
#2/BREAK = zkzh itemid
#3/sameCount = N.
#4SORT CASES BY sameCount (D).
#5COMPUTE filtervar=(sameCount > 1).
#6FILTER BY filtervar.
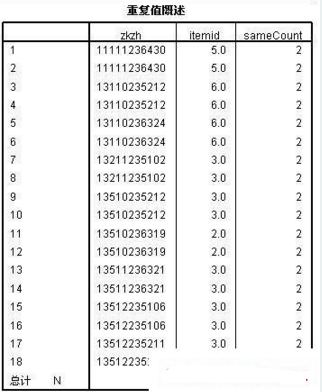
#7SUMMARIZE
#8/TABLES=zkzh itemid samecount
#9/FORMAT=LIST NOCASENUM TOTAL
#10/TITLE='重復(fù)值概述'
#11/CELLS=COUNT.
代碼解析:
第1-3行命令利用aggregate命令在當(dāng)前數(shù)據(jù)集中新增一個變量samecount記錄分組變量zkzh和itemid相同觀測值的數(shù)目�,類似于GUI操作中的data--aggregate.
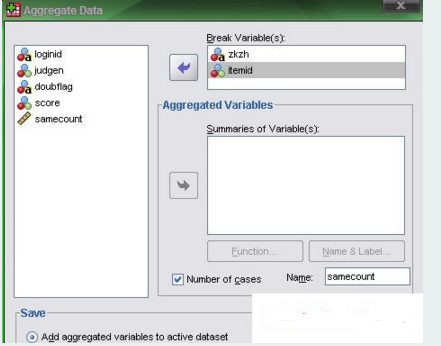
第4行命令對變量samecount進行降序排列.
第5行命令計算新變量filtervar,對其滿足條件samecount>1賦值1�����,否則賦值0.
第6行命令對數(shù)據(jù)集按變量filtercar進行篩選���,filtervar變量中值為0或缺失的都將被過濾.
第7-11行是制表命令��,等同于GUI菜單操作中的analyze--reports--case summarises��,第8行選擇表中的計量變量�����,這里選擇了zkzh等3個變量��,第9-10行則是對表格的格式及標(biāo)題進行設(shè)置�����,第11行是相關(guān)統(tǒng)計量的選擇�,這里選擇的是count,除此之外還可以選擇max\range\sum等其他統(tǒng)計量��。
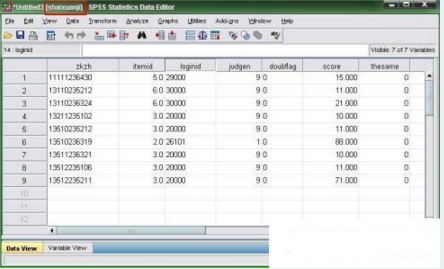
輸出結(jié)果:
小貼士:
Filter
Filter命令是用來從當(dāng)前數(shù)據(jù)集中排除觀測值而不刪除觀測值的命令�。當(dāng)變量的觀測值為0或缺失時這些觀測值將被過濾掉(SPSS中的表現(xiàn)效果為)。Filter相關(guān)命令規(guī)則:
1)只允許指定一個數(shù)值變量(該變量可以是原始變量或數(shù)據(jù)轉(zhuǎn)換變量)
2)使用filter off后�,恢復(fù)過濾掉的觀測值
3)當(dāng)filter命令不包含子命令時,將按filter off命令進行等效處理�,等SPSS output窗口會提示警告信息
4)Filter可以用在syntax語句的任何位置,和select if命令不同的是�,filter命令在input program語句中也有同樣的效果。需要注意的是這里的篩選變量需要時數(shù)據(jù)轉(zhuǎn)換變量�����。
其他說明:
1)filter命令并沒有改變當(dāng)前數(shù)據(jù)集���;
2)filter命令并沒有提供觀測值的選擇過濾標(biāo)準(zhǔn)��,系統(tǒng)缺失和用戶自定義缺失值,都將被過濾掉
3)如果filter的變量名改變了����,篩選效果仍然有效;但是篩選變量如果轉(zhuǎn)換為字符變量時����,filter命令效果將會消失
4)如果當(dāng)前數(shù)據(jù)集被match files���,add files或update等命令更改后,過濾變量未發(fā)生變化����,filter命令仍然有效
5)如果當(dāng)前數(shù)據(jù)集被一個新的數(shù)據(jù)集代替,filter命令將關(guān)閉
MATCH FILES
Match files命令可合并2個或2個以上含有相同觀測值但不同變量的數(shù)據(jù)文件����。例如,合并銷售人員的信息和銷售業(yè)績��,有點類似于數(shù)據(jù)庫中的select操作�����。最多可以合并50個數(shù)據(jù)文件���。例如���,合并數(shù)據(jù)part1,part2及當(dāng)前數(shù)據(jù)及可以用下面的代碼,如果怕數(shù)據(jù)合并錯誤��,可以先對這些數(shù)據(jù)集進行排序,然后利用by子命令根據(jù)排序變量進行合并��,還可以利用last或first子命令賦值1說明重復(fù)值位置�����。
MATCH FILES FILE='/data/part1.sav'
/FILE='/data/part2.sav'
/FILE=*.
SORT Cases
Sort cases基于一個或多個變量進行排序�,可以是升序(a)或降序(d),也可以是升序降序的組合。(默認為升序)�����,Sort cases相關(guān)說明:
1)關(guān)鍵詞by是可選的
2)By排序的變量可以是數(shù)字變量或字符變量����,但不能是系統(tǒng)變量或臨時變量(#various)
3)Sort cases是按變量順序進行排序的,優(yōu)先排序第一變量
4)Sort cases指定排序變量不能超過64個
例如:SORT CASES BY var1(A) var2(D).
*首先對變量1進行升序排列����,然后再此基礎(chǔ)上按變量2進行降序排列.
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認證考試,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學(xué)習(xí)CDA考試教材,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330