本文將介紹深入解讀利用Python語(yǔ)言解析XML文件的幾種方式�,并以筆者推薦使用的ElementTree模塊為例����,演示具體使用方法和場(chǎng)景��。文中所使用的Python版本為2.7。

在XML解析方面�,Python貫徹了自己“開(kāi)箱即用”(batteries included)的原則。在自帶的標(biāo)準(zhǔn)庫(kù)中����,Python提供了大量可以用于處理XML語(yǔ)言的包和工具,數(shù)量之多���,甚至讓Python編程新手無(wú)從選擇�。
本文將介紹深入解讀利用Python語(yǔ)言解析XML文件的幾種方式����,并以筆者推薦使用的ElementTree模塊為例,演示具體使用方法和場(chǎng)景�。文中所使用的Python版本為2.7。
什么是XML?
XML是可擴(kuò)展標(biāo)記語(yǔ)言(Extensible Markup Language)的縮寫��,其中的 標(biāo)記(markup)是關(guān)鍵部分。您可以創(chuàng)建內(nèi)容����,然后使用限定標(biāo)記標(biāo)記它,從而使每個(gè)單詞���、短語(yǔ)或塊成為可識(shí)別����、可分類的信息��。

標(biāo)記語(yǔ)言從早期的私有公司和政府制定形式逐漸演變成標(biāo)準(zhǔn)通用標(biāo)記語(yǔ)言(Standard Generalized Markup Language�,SGML)、超文本標(biāo)記語(yǔ)言(Hypertext Markup Language����,HTML),并且最終演變成 XML�����。XML有以下幾個(gè)特點(diǎn)��。
XML的設(shè)計(jì)宗旨是傳輸數(shù)據(jù)��,而非顯示數(shù)據(jù)����。
XML標(biāo)簽沒(méi)有被預(yù)定義。您需要自行定義標(biāo)簽�����。
XML被設(shè)計(jì)為具有自我描述性�。
XML是W3C的推薦標(biāo)準(zhǔn)。
目前��,XML在Web中起到的作用不會(huì)亞于一直作為Web基石的HTML��。 XML無(wú)所不在��。XML是各種應(yīng)用程序之間進(jìn)行數(shù)據(jù)傳輸?shù)淖畛S玫墓ぞ?����,并且在信息存?chǔ)和描述領(lǐng)域變得越來(lái)越流行�。因此,學(xué)會(huì)如何解析XML文件����,對(duì)于Web開(kāi)發(fā)來(lái)說(shuō)是十分重要的��。
有哪些可以解析XML的Python包?
Python的標(biāo)準(zhǔn)庫(kù)中��,提供了6種可以用于處理XML的包�。
xml.dom
xml.dom實(shí)現(xiàn)的是W3C制定的DOM API。如果你習(xí)慣于使用DOM API或者有人要求這這樣做�����,可以使用這個(gè)包����。不過(guò)要注意,在這個(gè)包中��,還提供了幾個(gè)不同的模塊��,各自的性能有所區(qū)別���。
DOM解析器在任何處理開(kāi)始之前���,必須把基于XML文件生成的樹狀數(shù)據(jù)放在內(nèi)存,所以DOM解析器的內(nèi)存使用量完全根據(jù)輸入資料的大小�。
xml.dom.minidom
xml.dom.minidom是DOM API的極簡(jiǎn)化實(shí)現(xiàn)����,比完整版的DOM要簡(jiǎn)單的多�,而且這個(gè)包也小的多�。那些不熟悉DOM的朋友,應(yīng)該考慮使用xml.etree.ElementTree模塊�。據(jù)lxml的作者評(píng)價(jià),這個(gè)模塊使用起來(lái)并不方便�����,效率也不高�����,而且還容易出現(xiàn)問(wèn)題���。
xml.dom.pulldom
與其他模塊不同,xml.dom.pulldom模塊提供的是一個(gè)“pull解析器”���,其背后的基本概念指的是從XML 流中pull事件�����,然后進(jìn)行處理��。雖然與SAX一樣采用事件驅(qū)動(dòng)模型(event-driven processing model)�,但是不同的是,使用pull解析器時(shí)��,使用者需要明確地從XML流中pull事件���,并對(duì)這些事件遍歷處理��,直到處理完成或者出現(xiàn)錯(cuò)誤����。
pull解析(pull parsing)是近來(lái)興起的一種XML處理趨勢(shì)��。此前諸如SAX和DOM這些流行的XML解析框架��,都是push-based��,也就是說(shuō)對(duì)解析工作的控制權(quán)��,掌握在解析器的手中����。
xml.sax

xml.sax模塊實(shí)現(xiàn)的是SAX API��,這個(gè)模塊犧牲了便捷性來(lái)?yè)Q取速度和內(nèi)存占用���。SAX是Simple API for XML的縮寫,它并不是由W3C官方所提出的標(biāo)準(zhǔn)�����。它是事件驅(qū)動(dòng)的�,并不需要一次性讀入整個(gè)文檔����,而文檔的讀入過(guò)程也就是SAX的解析過(guò)程。所謂事件驅(qū) 動(dòng)��,是指一種基于回調(diào)(callback)機(jī)制的程序運(yùn)行方法���。
xml.parser.expat
xml.parser.expat提供了對(duì)C語(yǔ)言編寫的expat解析器的一個(gè)直接的���、底層API接口�����。expat接口與SAX類似,也是基于事件回調(diào)機(jī)制��,但是這個(gè)接口并不是標(biāo)準(zhǔn)化的�����,只適用于expat庫(kù)。
expat是一個(gè)面向流的解析器�����。您注冊(cè)的解析器回調(diào)(或handler)功能���,然后開(kāi)始搜索它的文檔��。當(dāng)解析器識(shí)別該文件的指定的位置�����,它會(huì)調(diào)用 該部分相應(yīng)的處理程序(如果您已經(jīng)注冊(cè)的一個(gè))��。該文件被輸送到解析器����,會(huì)被分割成多個(gè)片斷,并分段裝到內(nèi)存中����。因此expat可以解析那些巨大的文件。
xml.etree.ElementTree(以下簡(jiǎn)稱ET)
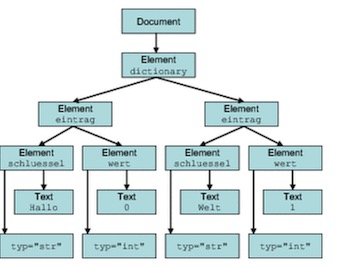
xml.etree.ElementTree模塊提供了一個(gè)輕量級(jí)��、Pythonic的API���,同時(shí)還有一個(gè)高效的C語(yǔ)言實(shí)現(xiàn)�����,即xml.etree.cElementTree。與DOM相比�,ET的速度更快,API使用更直接��、方便��。與SAX相比�����,ET.iterparse函數(shù)同樣提供了按需解析的功能�,不會(huì)一次性在內(nèi)存中讀入整個(gè)文檔。ET的性能與SAX模塊大致相仿�����,但是它的API更加高層次����,用戶使用起來(lái)更加便捷。
筆者建議����,在使用Python進(jìn)行XML解析時(shí),首選使用ET模塊���,除非你有其他特別的需求����,可能需要另外的模塊來(lái)滿足���。
解析XML的這幾種API并不是Python獨(dú)創(chuàng)的��,Python也是通過(guò)借鑒其他語(yǔ)言或者直接從其他語(yǔ)言引入進(jìn)來(lái)的��。例如expat就是一個(gè)用C 語(yǔ)言開(kāi)發(fā)的���、用來(lái)解析XML文檔的開(kāi)發(fā)庫(kù)����。而SAX最初是由DavidMegginson采用java語(yǔ)言開(kāi)發(fā)的��,DOM可以以一種獨(dú)立于平臺(tái)和語(yǔ)言的方 式訪問(wèn)和修改一個(gè)文檔的內(nèi)容和結(jié)構(gòu)�����,可以應(yīng)用于任何編程語(yǔ)言����。
下面,我們以ElementTree模塊為例�,介紹在Python中如何解析lxml�����。
利用ElementTree解析XML
Python標(biāo)準(zhǔn)庫(kù)中��,提供了ET的兩種實(shí)現(xiàn)。一個(gè)是純Python實(shí)現(xiàn)的xml.etree.ElementTree��,另一個(gè)是速度更快的C語(yǔ)言實(shí)現(xiàn)xml.etree.cElementTree����。請(qǐng)記住始終使用C語(yǔ)言實(shí)現(xiàn),因?yàn)樗乃俣纫旌芏?,而且?nèi)存消耗也要少很多。如果你所使用的Python版本中沒(méi)有cElementTree所需的加速模塊�,你可以這樣導(dǎo)入模塊:

如果某個(gè)API存在不同的實(shí)現(xiàn),上面是常見(jiàn)的導(dǎo)入方式��。當(dāng)然���,很可能你直接導(dǎo)入第一個(gè)模塊時(shí)�����,并不會(huì)出現(xiàn)問(wèn)題�����。請(qǐng)注意���,自Python 3.3之后����,就不用采用上面的導(dǎo)入方法���,因?yàn)镋lemenTree模塊會(huì)自動(dòng)優(yōu)先使用C加速器��,如果不存在C實(shí)現(xiàn)����,則會(huì)使用Python實(shí)現(xiàn)���。因此���,使用Python 3.3+的朋友,只需要import xml.etree.ElementTree即可�����。
將XML文檔解析為樹(tree)
我們先從基礎(chǔ)講起�。XML是一種結(jié)構(gòu)化、層級(jí)化的數(shù)據(jù)格式�,最適合體現(xiàn)XML的數(shù)據(jù)結(jié)構(gòu)就是樹�。ET提供了兩個(gè)對(duì)象:ElementTree將整個(gè)XML文檔轉(zhuǎn)化為樹����,Element則代表著樹上的單個(gè)節(jié)點(diǎn)�。對(duì)整個(gè)XML文檔的交互(讀取,寫入��,查找需要的元素)��,一般是在ElementTree層面進(jìn)行的��。對(duì)單個(gè)XML元素及其子元素�����,則是在Element層面進(jìn)行的��。下面我們舉例介紹主要使用方法��。
我們使用下面的XML文檔����,作為演示數(shù)據(jù):
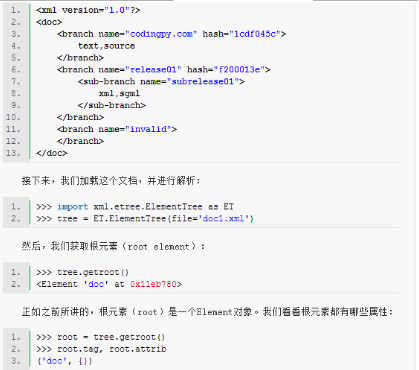
沒(méi)錯(cuò),根元素并沒(méi)有屬性��。與其他Element對(duì)象一樣��,根元素也具備遍歷其直接子元素的接口:
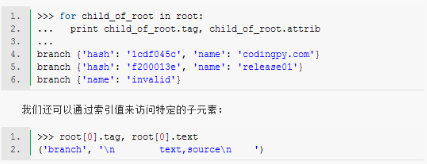
查找需要的元素
從上面的示例中,可以明顯發(fā)現(xiàn)我們能夠通過(guò)簡(jiǎn)單的遞歸方法(對(duì)每一個(gè)元素����,遞歸式訪問(wèn)其所有子元素)獲取樹中的所有元素。但是�����,由于這是十分常見(jiàn)的工作����,ET提供了一些簡(jiǎn)便的實(shí)現(xiàn)方法。
Element對(duì)象有一個(gè)iter方法�����,可以對(duì)某個(gè)元素對(duì)象之下所有的子元素進(jìn)行深度優(yōu)先遍歷(DFS)�����。ElementTree對(duì)象同樣也有這個(gè)方法���。下面是查找XML文檔中所有元素的最簡(jiǎn)單方法:

支持通過(guò)XPath查找元素
使用XPath查找感興趣的元素�����,更加方便����。Element對(duì)象中有一些find方法可以接受Xpath路徑作為參數(shù)����,find方法會(huì)返回第一個(gè)匹配的子元素,findall以列表的形式返回所有匹配的子元素, iterfind則返回一個(gè)所有匹配元素的迭代器(iterator)�����。ElementTree對(duì)象也具備這些方法��,相應(yīng)地它的查找是從根節(jié)點(diǎn)開(kāi)始的�。
下面是一個(gè)使用XPath查找元素的示例:

上面的代碼返回了branch元素之下所有tag為sub-branch的元素。接下來(lái)查找所有具備某個(gè)name屬性的branch元素:
>>> for elem in tree.iterfind('branch[@name="release01"]'): ... printelem.tag, elem.attrib ... branch {'hash': 'f200013e', 'name': 'release01'}
構(gòu)建XML文檔
利用ET�,很容易就可以完成XML文檔構(gòu)建,并寫入保存為文件�。ElementTree對(duì)象的write方法就可以實(shí)現(xiàn)這個(gè)需求。
一般來(lái)說(shuō)��,有兩種主要使用場(chǎng)景���。一是你先讀取一個(gè)XML文檔����,進(jìn)行修改,然后再將修改寫入文檔����,二是從頭創(chuàng)建一個(gè)新XML文檔。
修改文檔的話�����,可以通過(guò)調(diào)整Element對(duì)象來(lái)實(shí)現(xiàn)����。請(qǐng)看下面的例子:

利用iterparse解析XML流
XML文檔通常都會(huì)比較大,如何直接將文檔讀入內(nèi)存的話�,那么進(jìn)行解析時(shí)就會(huì)出現(xiàn)問(wèn)題。這也就是為什么不建議使用DOM��,而是SAX API的理由之一���。
我們上面談到�����,ET可以將XML文檔加載為保存在內(nèi)存里的樹(in-memory tree)����,然后再進(jìn)行處理。但是在解析大文件時(shí)�,這應(yīng)該也會(huì)出現(xiàn)和DOM一樣的內(nèi)存消耗大的問(wèn)題吧?沒(méi)錯(cuò)��,的確有這個(gè)問(wèn)題����。為了解決這個(gè)問(wèn)題���,ET提供了一個(gè)類似SAX的特殊工具——iterparse��,可以循序地解析XML�。
接下來(lái)����,筆者為大家展示如何使用iterparse,并與標(biāo)準(zhǔn)的樹解析方式進(jìn)行對(duì)比�。我們使用一個(gè)自動(dòng)生成的XML文檔,下面是該文檔的開(kāi)頭部分:
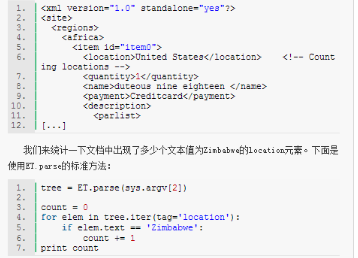
上面的代碼會(huì)將全部元素載入內(nèi)存����,逐一解析�����。當(dāng)解析一個(gè)約100MB的XML文檔時(shí)��,運(yùn)行上面腳本的Python進(jìn)程的內(nèi)存使用峰值為約560MB��,總運(yùn)行時(shí)間問(wèn)2.9秒����。
請(qǐng)注意����,我們其實(shí)不需要講整個(gè)樹加載到內(nèi)存里。只要檢測(cè)出文本為相應(yīng)值得location元素即可�。其他數(shù)據(jù)都可以廢棄。這時(shí)���,我們就可以用上iterparse方法了:
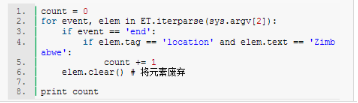
上面的for循環(huán)會(huì)遍歷iterparse事件��,首先檢查事件是否為end���,然后判斷元素的tag是否為location���,以及其文本值是否符合目標(biāo)值。另外�,調(diào)用elem.clear()非常關(guān)鍵:因?yàn)閕terparse仍然會(huì)生成一個(gè)樹,只是循序生成的而已����。廢棄掉不需要的元素,就相當(dāng)于廢棄了整個(gè)樹�,釋放出系統(tǒng)分配的內(nèi)存。
當(dāng)利用上面這個(gè)腳本解析同一個(gè)文件時(shí)�����,內(nèi)存使用峰值只有7MB���,運(yùn)行時(shí)間為2.5秒。速度提升的原因���,是我們這里只在樹被構(gòu)建時(shí)�,遍歷一次��。而使用parse的標(biāo)準(zhǔn)方法是先完成整個(gè)樹的構(gòu)建后���,才再次遍歷查找所需要的元素�����。
iterparse的性能與SAX相當(dāng)����,但是其API卻更加有用:iterparse會(huì)循序地構(gòu)建樹;而利用SAX時(shí)�����,你還得自己完成樹的構(gòu)建工作��。
來(lái)源 | 編程派
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�����;
? 想學(xué)習(xí)CDA考試教材����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫(kù)�,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情�����;
? 想了解CDA考試含金量���,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330