原文 | Spark 2015 Year In Review
翻譯 | 牛亞真
來自 | CSDN
Apache Spark在2015年得到迅猛發(fā)展���,開發(fā)節(jié)奏比以前任何時(shí)候都快�,在過去一年的時(shí)間里,發(fā)布了4個(gè)版本(Spark 1.3到Spark 1.6)�,各版本都添加了數(shù)以百計(jì)的改進(jìn)。
給Spark貢獻(xiàn)過源碼的開發(fā)者數(shù)量已經(jīng)超過1000����,是2014年年末人數(shù)的兩倍。據(jù)我們了解����,不管是大數(shù)據(jù)或小數(shù)據(jù)工具方面,Spark目前是開源項(xiàng)目中最活躍的����。對(duì)Spark的快速成長(zhǎng)及社區(qū)對(duì)Spark項(xiàng)目的重視讓我們深感責(zé)任重大。
在Databricks�,我們?nèi)匀辉谂ν苿?dòng)Spark向前發(fā)展,事實(shí)上����,2015年我們貢獻(xiàn)給Spark的代碼量是其它任何公司的10倍之多���。在本博文中,將重點(diǎn)突出2015年加入到項(xiàng)目中的主要開發(fā)內(nèi)容���。
1.數(shù)據(jù)科學(xué)API���,包括DataFrames,機(jī)器學(xué)習(xí)流水線(Machine Learning Pipelines)及R語(yǔ)言支持��;
2.平臺(tái)API���;
3.Tungsten項(xiàng)目和性能優(yōu)化��;
4.Spark流計(jì)算�。
在見證快速開發(fā)節(jié)奏的同時(shí)�����,也很高興目睹了用戶采用新版本的速度���。例如��,下圖給出的是超過200個(gè)客戶在Databricks運(yùn)行Spark版本的情況(注意單個(gè)客戶同時(shí)可以運(yùn)行多個(gè)版本的Spark)����。
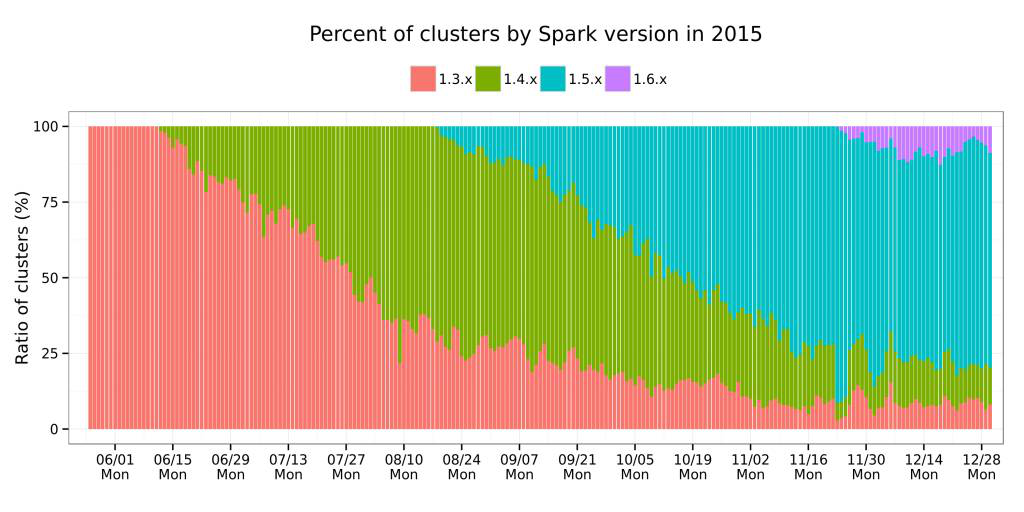
從上圖中可以看到,Spark用戶在緊隨最新版本方面積極性很高�����,在Spark 1.5發(fā)布后的僅三個(gè)月內(nèi)���,大多數(shù)的客戶便在使用它,同時(shí)有一小部分客戶已經(jīng)在試用2015年11月底發(fā)布的預(yù)覽版本的Spark 1.6?���,F(xiàn)在,讓我們來詳細(xì)說明2015年Spark的主要變化:
數(shù)據(jù)科學(xué)API: DataFrame�,ML Pipelins和R
在Spark之前,大數(shù)據(jù)相關(guān)讀物總是會(huì)涉及一系列令人望而生畏的概念��,從分布式計(jì)算到MapReduce函數(shù)式編程�����。從而��,大數(shù)據(jù)工具主要由那些掌握高級(jí)復(fù)雜技術(shù)水平的數(shù)據(jù)基礎(chǔ)團(tuán)隊(duì)使用。
Spark在2015年首要發(fā)展主題是為大數(shù)據(jù)構(gòu)建簡(jiǎn)化的APIs��,類似于為數(shù)據(jù)科學(xué)構(gòu)建的那樣����。我們并非逼迫數(shù)據(jù)科學(xué)家去學(xué)習(xí)整個(gè)新的發(fā)展范式,實(shí)際上是想要降低學(xué)習(xí)曲線����,提供類似于他們已經(jīng)熟悉的工具。
為了達(dá)此目的��,下面介紹下Spark的三個(gè)主要API附件����。
DataFrames:針對(duì)結(jié)構(gòu)化的數(shù)據(jù),是一個(gè)易用并且高效的API�����,類似于小數(shù)據(jù)工具�,像Python中的R和Pandas。
Machine Learning Pipelines:針對(duì)完整的機(jī)器學(xué)習(xí)工作流����,是一個(gè)易用的API�����。
SparkR:與Python一起��,R是深受數(shù)據(jù)科學(xué)家歡迎的編程語(yǔ)言�����。只需簡(jiǎn)單的學(xué)習(xí)一下���,數(shù)據(jù)科學(xué)家馬上就可以使用R和Spark處理數(shù)據(jù)�����,比他們的單一機(jī)器處理數(shù)據(jù)強(qiáng)大的多��。
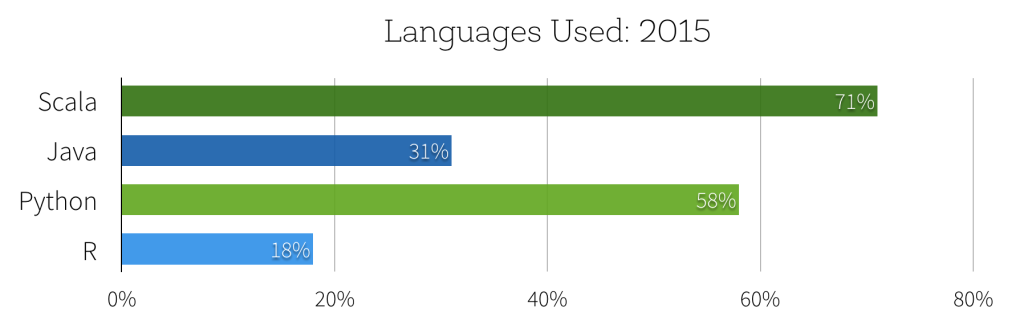
雖然這些API僅僅發(fā)布了數(shù)月����,根據(jù)2015年Spark調(diào)查報(bào)道,使用DataFrame API的Spark用戶已占62%���。正如調(diào)查結(jié)果所示����,調(diào)查對(duì)象大部分人都把自己定位為數(shù)據(jù)工程師(41%)或數(shù)據(jù)科學(xué)家(22%),數(shù)據(jù)科學(xué)家對(duì)Spark興趣的上升通過其使用的開發(fā)語(yǔ)言能更明顯地說明問題���,58%的調(diào)查對(duì)象使用Python(相比2014年增幅超過49%)����,18%的受訪者使用R API��。
由于我們發(fā)布了DataFrames���,因此也收集了社區(qū)的反饋�����,其中最為重要的反饋是:對(duì)于構(gòu)建更大型�、更復(fù)雜的數(shù)據(jù)工程項(xiàng)目��,經(jīng)典RDD API所提供的類型安全特性十分有用�����。基于此反饋��,針對(duì)這些不同種類的數(shù)據(jù)���,我們正在Spark 1.6中開發(fā)一個(gè)新類型Dataset API�。
平臺(tái)APIs
對(duì)應(yīng)用開發(fā)者來說��,Spark正成為通用的運(yùn)行時(shí)環(huán)境����。應(yīng)用程序僅需要針對(duì)單個(gè)集合的API進(jìn)行編程便可以運(yùn)行在不同種類的環(huán)境上(on-prem、cloud���、Hadoop等)及連接不同種類的數(shù)據(jù)源�����。在本年年初,我們便為第三方開發(fā)人員引入了標(biāo)準(zhǔn)的可插拔數(shù)據(jù)源API����,它可以智能地解析數(shù)據(jù)源格式。目前支持的數(shù)據(jù)源包括:
CSV�����, JSON, XML
Avro�, Parquet
MySQL, PostgreSQL���, Oracle�����, Redshift
Cassandra����, MongoDB�����, ElasticSearch
Salesforce�����, Google Spreadsheets
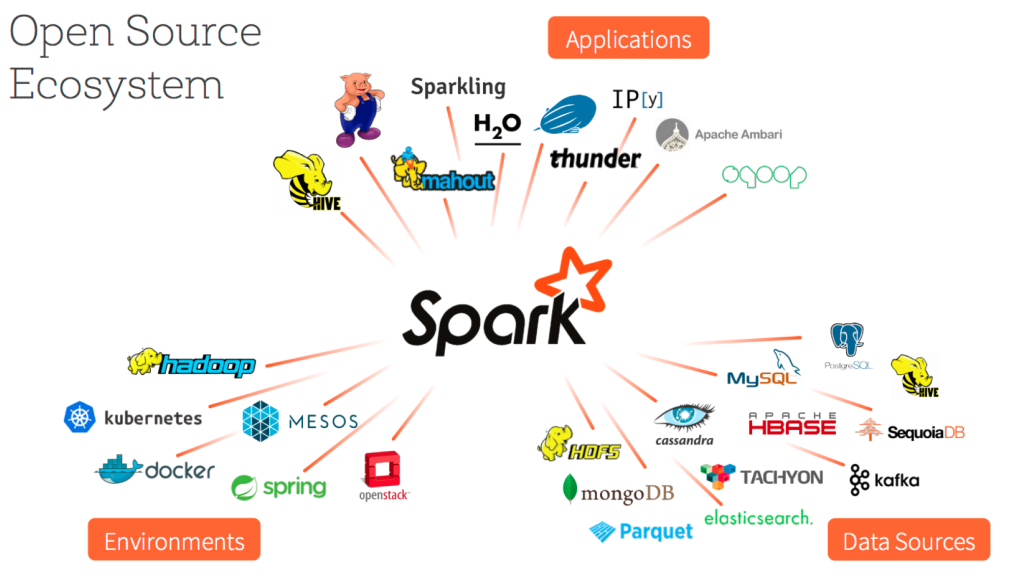
為便于查找數(shù)據(jù)源和算法對(duì)應(yīng)的庫(kù)��,我們也引入了Spark核心存儲(chǔ)庫(kù)spark-packages.org。
另外一個(gè)有趣的趨勢(shì)是Spark早期使用者大多數(shù)與Hadoop結(jié)合起來使用����,隨著Spark的發(fā)展我,Hadoop不再代表著大多數(shù)Spark使用時(shí)����。根據(jù)2015年Spark調(diào)查報(bào)告,48%的Spark部署方式為Spark standalone集群管理器�����,而Hadoop Yarn的使用僅為40%左右����。
Tungsten項(xiàng)目和性能優(yōu)化
根據(jù)2015年Spark調(diào)查報(bào)告,91%用戶認(rèn)為性能是Spark最重要的特征�,因此,性能優(yōu)化始終是Spark開發(fā)中的一個(gè)重要內(nèi)容�。
在今年年初,我們啟動(dòng)了Tungsten項(xiàng)目——被設(shè)計(jì)用于提高Spark內(nèi)核架構(gòu)的性能和健壯性的重要改進(jìn)�。Spark 1.5中已經(jīng)提供了Tungsten的初步功能,這其中包括二進(jìn)制處理(binary processing)��,它避免使用Java對(duì)象模型那種傳統(tǒng)二進(jìn)制內(nèi)存布局格式�。二進(jìn)制處理極大地降低了數(shù)據(jù)密集型任務(wù)處理時(shí)的垃圾回收壓力,除此之外����,Tungsten還包括新的代碼生成框架,在運(yùn)行時(shí)對(duì)用戶代碼中的表達(dá)式計(jì)算生成相應(yīng)經(jīng)過優(yōu)化的字節(jié)碼�����。2015年發(fā)布的四個(gè)Spark版本�����,我們也添加了大量能夠經(jīng)過代碼生成的內(nèi)置函數(shù)�,例如日期和字符串處理等常見任務(wù)。
另外����,數(shù)據(jù)處理性能在查詢執(zhí)行時(shí)也非常重要,Parquet已經(jīng)成為Spark中最常用的數(shù)據(jù)格式�����,其掃描性能對(duì)許多大型應(yīng)用程序的影響巨大����,在Spark 1.6當(dāng)中��,我們引入了一種新的Parquet讀取器�,該讀取器針對(duì)平滑模式(flat schemas)使用一種經(jīng)過優(yōu)化的代碼路徑�,在我們的基準(zhǔn)測(cè)試當(dāng)中,該新的讀取器掃描吞吐率增加了近50%��。
Spark流處理
隨著物聯(lián)網(wǎng)的崛起���,越來越多的機(jī)構(gòu)正在部署各自的流處理應(yīng)用程序�����,將這些流處理程序同傳統(tǒng)的流水線結(jié)合起來至關(guān)重要�����,Spark通過利用統(tǒng)一引擎進(jìn)行批處理和流數(shù)據(jù)處理簡(jiǎn)化了部署難度�。2015年Spark 流處理中增加的主要內(nèi)容包括:
直接Kafka連接器:Spark 1.3 改進(jìn)了與Kafka間的集成�,從而使得流處理程序能夠提供只執(zhí)行一次數(shù)據(jù)處理的語(yǔ)義并簡(jiǎn)化操作。額外的工作提供了容錯(cuò)性和保證零數(shù)據(jù)丟失�。
Web UI進(jìn)行監(jiān)控并幫助更好地調(diào)試應(yīng)用程序:為幫助監(jiān)控和調(diào)試能夠7*24小時(shí)不間斷運(yùn)行的流處理程序,Spark 1.4 引入了能夠顯示處理時(shí)間線和直方圖的新Web UI��,同時(shí)也能夠詳細(xì)描述各離散Streams
狀態(tài)管理10倍提升���。在Spark 1.6當(dāng)中�����,我們重新設(shè)計(jì)了Spark流處理中的狀態(tài)管理API���,新引入mapWithState API,它能夠線性地?cái)U(kuò)展更新的記錄數(shù)而非記錄總數(shù)�。在大多數(shù)應(yīng)用場(chǎng)景中能夠達(dá)到一個(gè)數(shù)量級(jí)的性能提升。
結(jié)束語(yǔ)
Databricks目前在Spark用戶培訓(xùn)和教育方面投入巨大��,在2015年��,我們與加州大學(xué)伯克利分校��、加州大學(xué)洛杉磯分校合作并提供兩個(gè)大規(guī)模在線開放課程���。第一個(gè)課程是Apache Spark大數(shù)據(jù)處理入門�,教授學(xué)生使用Spark和數(shù)據(jù)分析���;第二個(gè)課程是可擴(kuò)展的機(jī)器學(xué)習(xí)��,教授學(xué)生使用Spark進(jìn)行機(jī)器學(xué)習(xí)�。這兩門課程在edX平臺(tái)上都是免費(fèi)的,在我們發(fā)布此消息后��,目前已經(jīng)有超過125000個(gè)學(xué)生注冊(cè)�����,我們計(jì)算在今年完成對(duì)他們的培訓(xùn)��。
我們對(duì)今年與社區(qū)的共同努力所帶來的進(jìn)步感到自豪��,也為能夠繼承努力給Spark帶來更豐富的特性感到激動(dòng)�����,想了解2016年的開發(fā)內(nèi)容����,請(qǐng)繼續(xù)保持對(duì)我們博客的關(guān)注。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材���,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫(kù),點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情����;
? 想了解CDA考試含金量,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330