如何用SPSS做數據正態(tài)化轉換�����?
數據分析師在用spss做數據不完全符合正態(tài)分布�,接下來的問題是�����,很多學科都在講大樣本不用太考慮正態(tài)分布問題����,但事實上由此造成的誤差確實存在,有時還會比較大�����。那么數據分析師如何用SPSS做數據正態(tài)化轉換呢��?
嚴格說來,解決這個問題需要講四個方面:
什么是正態(tài)轉換�?
為什么做正態(tài)轉換?
何時做正態(tài)轉化�?
如何做正態(tài)轉化?
我擔心如果只講How(如何做)��,也許有些初學者不分場合�����,誤用濫用��。但是��,我同樣擔心如果從ABC講起����,難免過分啰嗦,甚至有藐視大家的智商之嫌��。所幸現在是互聯網時代���,有關上述What, Why, When問題的答案網上唾手可得��。如果對這些問題不甚了了的讀者�����,強烈建議先到google上用“How to transform data to normal distribution"搜一下(或點擊下面的“前10條”)���,前10條幾乎每篇都是必讀的經典。
有了上述交代���,我們"數據分析師"可以比較放心地來討論如何做正態(tài)轉換的問題了����。具體來說���,涉及以下幾步:
第一步
查看原始變量的分布形狀及其描述參數(Skewness和Kurtosis)�����。這可以用頻率或者描述性統(tǒng)計或者BoxPlot�;
第二步
根據變量的分布形狀��,決定是否做轉換����。這里,主要是看一下兩個問題:
1、左右是否對稱
也就是看Skewness(偏差度)的取值�。如果Skewness為0,則是完全對稱(但罕見)��;如果Skewness為正值�����,則說明該變量的分布為positively skewed(正偏態(tài)�,見下圖1b);如果Skewness為負值�����,則說明該變量的分布為negatively skewed(負偏態(tài)�����,見圖 1a)���。然而�����,肉眼直觀檢查����,往往無法判斷偏態(tài)的分布是否與對稱的正態(tài)分布有“顯著”差別,所以需要做顯著性檢驗���。如同其它統(tǒng)計顯著性檢驗一樣,Skewness的絕對值如大于其標準誤差的1.96倍���,就被認為是與正態(tài)分布有顯著差別�。如果檢驗結果顯著�����,我們也許(注意這里我用的是“也許”一詞)可以通過轉換來達到或接近對稱�。見注解1的說明。
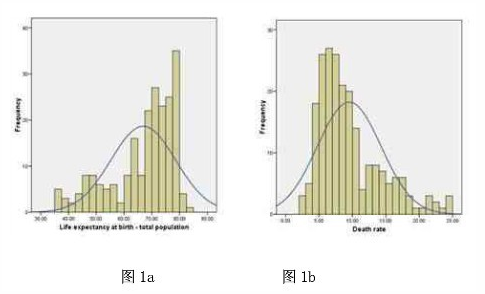
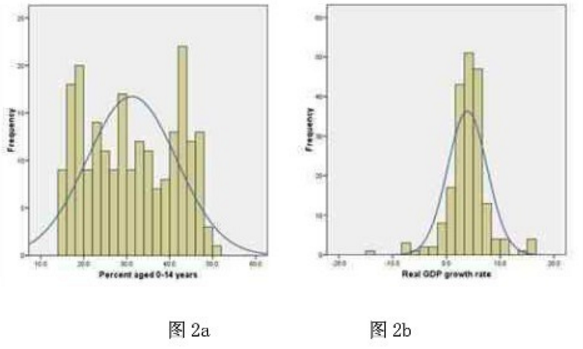
2�����、峰態(tài)是否陡緩適度
也就是看Kurtosis(峰態(tài))是否過分peaked(陡峭)或過分flat(平坦)�。如果Kurtosis為0,則說明該變量分布的峰態(tài)正合適����,不胖也不瘦(但罕見)��;如果Kurtosis為正值���,則說明該變量的分布峰態(tài)太陡峭(瘦高個,見圖2b)�;反之,如果Kurtosis為負值����,該變量的分布峰態(tài)太平緩(矮胖子,見圖2a)�。峰態(tài)是否適度,更難直觀看出�����,也需要通過顯著檢驗�。如同Skewness一樣,Kurtosis的絕對值如果大于其標準誤差的1.96倍���,就被認為與正態(tài)分布有顯著差別�。這時���,我們也許可以通過轉換來達到或接近正態(tài)分布(峰態(tài))���。
第三步
如果"數據分析師"需要做正態(tài)化轉換�����,還是根據變量的分布形狀�,確定相應的轉換公式�����。最常見的情況是正偏態(tài)加上陡峰態(tài)�����。
1���、如果是中度偏態(tài)
如Skewness為其標準誤差的2-3倍,可以考慮取根號值來轉換���,以下是SPSS的指令(其中"nx"是原始變量x的轉換值���,參見注2):
COMPUTE nx=SQRT(x)
2、如果高度偏態(tài)
如Skewness為其標準誤差的3倍以上�����,則可以取對數,其中又可分為自然對數和以10為基數的對數����。以下是轉換自然對數的指令(注2):
COMPUTE nx=LN(x)
以下是轉換成以10為基數的對數(其糾偏力度最強,有時會矯枉過正�����,將正偏態(tài)轉換成負偏態(tài)��,注2):
COMPUTE nx=LG10(x)
上述公式只能減輕或消除變量的正偏態(tài)(positive skewed)����,但如果不分青紅皂白(即不仔細操作第一和第二步)地用于負偏態(tài)(negative skewed)的變量,則會使負偏態(tài)變得更加嚴重��。如果第一步顯示了負偏態(tài)的分布�,則需要先對原始變量做reflection(反向轉換),即將所有的值反過來�,如將最大值變成最小值、最小值變成最大值���、等等���。如果一個變量的取值不多�,可用如下指令來反轉:
RECODE x(1=7)(2=6)(3=5)(5=3)(6=2)(7=1)
如果變量的取值很多或有小數��、分數���,上述方法幾乎不可能�,則需要寫如下的指令(不知大家現在是否信服了為什么要學syntax嗎�?):
COMPUTE nx=max-x+1, 其中max是x的最大值��。
第四步
回到第一步�����,再次檢驗轉換后變量的分布形狀����。如果"數據分析師"沒有解決問題���,或者甚至惡化(如上述的從正偏態(tài)轉成負偏態(tài))����,需要再從第二或第三步重新做起,然后再回到第一步的檢驗�,等等,直至達到比較令人滿意的結果(見注3)�。
數據正態(tài)化的特別注解
1、如同其它統(tǒng)計檢驗量一樣�����,Skewness和Kurtosis的的標準誤差也與樣本量直接有關���。具體說來�,Skewness的標準誤差約等于6除以n后的開方(根號喜下6/n)�����,而Kurtosis的標準誤差約等于24除以n后的開方(根號下24/n)�����,其中n均為樣本量��。由此可見�,樣本量越大,標準誤差越小,因此同樣大小的Skewness和Kurtosis在大樣本中越可能與正態(tài)分布有顯著差別����。這也許就是SW在問題中提到的“很多學科都在講大樣本不用太考慮正態(tài)分布問題”的由來。我的看法是�,如果小樣本的Skewness和Kurtosis是顯著的話,一定要轉換���;在大樣本的條件下���,如果Skewness和Kurtosis是輕度偏差,也許不需要轉換�,但如果嚴重偏差,也是要轉換����。
2、大家知道����,根號里的x不能為負數����,對數或倒數里的x不能為非正數(即等于或小于0)。如果你的x中有是負數或非正數,需要將其做線性轉換成非負數(即等于或大于0)或正數(大于0)���,如 COMPUTE nx = SQRT (x - min) 或 COMPUTE nx = LN (x - min + 1)�,其中的min是x的最小值(為一個非正數)�。
http://www.3lll3.cn/3、不是任何分布形態(tài)的變量都可以轉換的�。例外之一是“雙峰”或“多峰”分布(distribution with dual or multiple modality),沒有任何公式可以將之轉換成單峰的正態(tài)分布���。數據分析師培訓
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330