大數(shù)據(jù)技術架構解析
大數(shù)據(jù)數(shù)量龐大�,格式多樣化���。大量數(shù)據(jù)由家庭��、制造工廠和辦公場所的各種設備���、互聯(lián)網(wǎng)事務交易�、社交網(wǎng)絡的活動���、自動化傳感器���、移動設備以及科研儀器等生成。它的爆炸式增長已超出了傳統(tǒng)IT基礎架構的處理能力����,給企業(yè)和社會帶來嚴峻的數(shù)據(jù)管理問題。因此必須開發(fā)新的數(shù)據(jù)架構����,圍繞“數(shù)據(jù)收集、數(shù)據(jù)管理��、數(shù)據(jù)分析����、知識形成、智慧行動”的全過程�,開發(fā)使用這些數(shù)據(jù),釋放出更多數(shù)據(jù)的隱藏價值���。
一�、大數(shù)據(jù)建設思路
1)數(shù)據(jù)的獲得
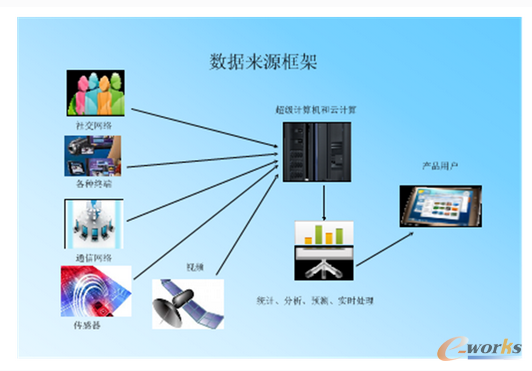

大數(shù)據(jù)產生的根本原因在于感知式系統(tǒng)的廣泛使用。隨著技術的發(fā)展�����,人們已經有能力制造極其微小的帶有處理功能的傳感器����,并開始將這些設備廣泛的布置于社會的各個角落,通過這些設備來對整個社會的運轉進行監(jiān)控��。這些設備會源源不斷的產生新數(shù)據(jù)��,這種數(shù)據(jù)的產生方式是自動的��。因此在數(shù)據(jù)收集方面�,要對來自網(wǎng)絡包括物聯(lián)網(wǎng)、社交網(wǎng)絡和機構信息系統(tǒng)的數(shù)據(jù)附上時空標志�����,去偽存真���,盡可能收集異源甚至是異構的數(shù)據(jù),必要時還可與歷史數(shù)據(jù)對照����,多角度驗證數(shù)據(jù)的全面性和可信性����。
2)數(shù)據(jù)的匯集和存儲
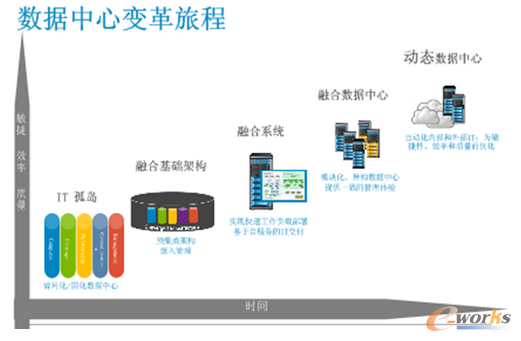
數(shù)據(jù)只有不斷流動和充分共享��,才有生命力�。應在各專用數(shù)據(jù)庫建設的基礎上,通過數(shù)據(jù)集成�,實現(xiàn)各級各類信息系統(tǒng)的數(shù)據(jù)交換和數(shù)據(jù)共享。 數(shù)據(jù)存儲要達到低成本����、低能耗、高可靠性目標����,通常要用到冗余配置、分布化和云計算技術�,在存儲時要按照一定規(guī)則對數(shù)據(jù)進行分類,通過過濾和去重��,減少存儲量���,同時加入便于日后檢索的標簽�。
3)數(shù)據(jù)的管理
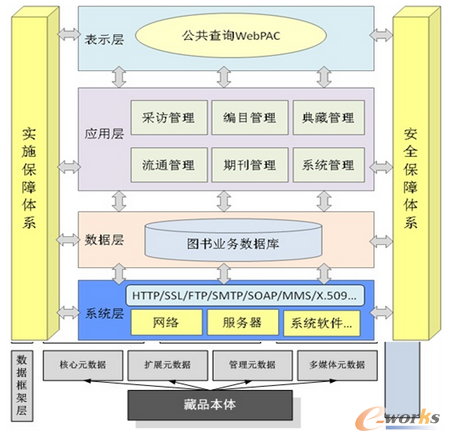
大數(shù)據(jù)管理的技術也層出不窮。在眾多技術中�����,有6種數(shù)據(jù)管理技術普遍被關注����,即分布式存儲與計算、內存數(shù)據(jù)庫技術�����、列式數(shù)據(jù)庫技術�����、云數(shù)據(jù)庫����、非關系型的數(shù)據(jù)庫、移動數(shù)據(jù)庫技術�。其中分布式存儲與計算受關注度最高。上圖是一個圖書數(shù)據(jù)管理系統(tǒng)����。
4)數(shù)據(jù)的分析
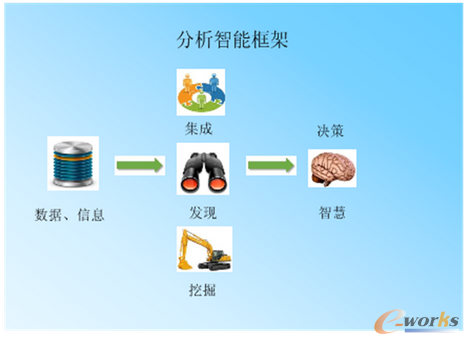
數(shù)據(jù)分析處理:有些行業(yè)的數(shù)據(jù)涉及上百個參數(shù),其復雜性不僅體現(xiàn)在數(shù)據(jù)樣本本身��,更體現(xiàn)在多源異構����、多實體和多空間之間的交互動態(tài)性,難以用傳統(tǒng)的方法描述與度量�����,處理的復雜度很大�,需要將高維圖像等多媒體數(shù)據(jù)降維后度量與處理,利用上下文關聯(lián)進行語義分析�����,從大量動態(tài)而且可能是模棱兩可的數(shù)據(jù)中綜合信息�����,并導出可理解的內容��。大數(shù)據(jù)的處理類型很多��,主要的處理模式可以分為流處理和批處理兩種。批處理是先存儲后處理��,而流處理則是直接處理數(shù)據(jù)�。挖掘的任務主要是關聯(lián)分析、聚類分析�、分類、預測���、時序模式和偏差分析等�。
5)大數(shù)據(jù)的價值:決策支持系統(tǒng)
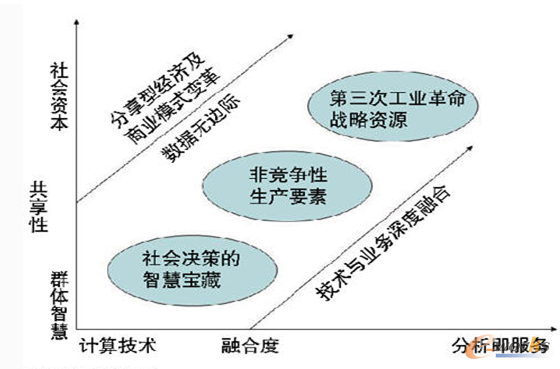
大數(shù)據(jù)的神奇之處就是數(shù)據(jù)分析師通過對過去和現(xiàn)在的數(shù)據(jù)進行分析�����,它能夠精確預測未來;通過對組織內部的和外部的數(shù)據(jù)整合����,它能夠洞察事物之間的相關關系;通過對海量數(shù)據(jù)的挖掘,它能夠代替人腦����,承擔起企業(yè)和社會管理的職責。
6)數(shù)據(jù)的使用
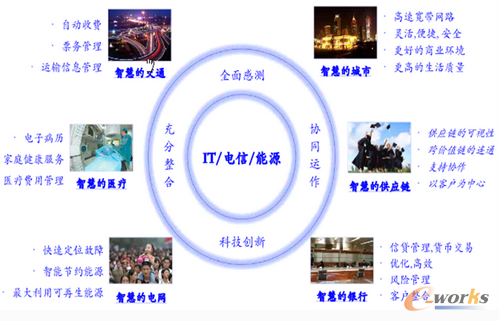
大數(shù)據(jù)有三層內涵:一是數(shù)據(jù)量巨大��、來源多樣和類型多樣的數(shù)據(jù)集;二是新型的數(shù)據(jù)處理和分析技術;三是運用數(shù)據(jù)分析形成價值���。大數(shù)據(jù)對科學研究��、經濟建設����、社會發(fā)展和文化生活等各個領域正在產生革命性的影響���。大數(shù)據(jù)應用的關鍵��,也是其必要條件����,就在于"IT"與"經營"的融合�,當然,這里的經營的內涵可以非常廣泛�����,小至一個零售門店的經營����,大至一個城市的經營。
二����、大數(shù)據(jù)基本架構
基于上述大數(shù)據(jù)的特征�����,通過傳統(tǒng)IT技術存儲和處理大數(shù)據(jù)成本高昂����。一個企業(yè)要大力發(fā)展大數(shù)據(jù)應用首先需要解決兩個問題:一是低成本�、快速地對海量、多類別的數(shù)據(jù)進行抽取和存儲;二是使用新的技術對數(shù)據(jù)進行分析和挖掘�����,為企業(yè)創(chuàng)造價值�����。因此��,大數(shù)據(jù)的存儲和處理與云計算技術密不可分�����,在當前的技術條件下�,基于廉價硬件的分布式系統(tǒng)(如Hadoop等)被認為是最適合處理大數(shù)據(jù)的技術平臺��。
Hadoop是一個分布式的基礎架構���,能夠讓用戶方便高效地利用運算資源和處理海量數(shù)據(jù),目前已在很多大型互聯(lián)網(wǎng)企業(yè)得到了廣泛應用���,如亞馬遜����、Facebook和Yahoo等�����。其是一個開放式的架構���,架構成員也在不斷擴充完善中,通常架構如圖2所示:
Hadoop體系架構
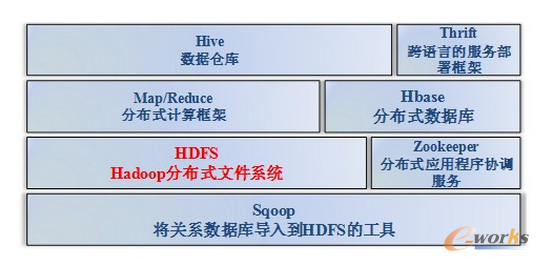
(1)Hadoop最底層是一個HDFS(Hadoop Distributed File System�,分布式文件系統(tǒng)),存儲在HDFS中的文件先被分成塊���,然后再將這些塊復制到多個主機中(DataNode�,數(shù)據(jù)節(jié)點)��。
(2)Hadoop的核心是MapReduce(映射和化簡編程模型)引擎,Map意為將單個任務分解為多個���,而Reduce則意為將分解后的多任務結果匯總���,該引擎由JobTrackers(工作追蹤,對應命名節(jié)點)和TaskTrackers(任務追蹤���,對應數(shù)據(jù)節(jié)點)組成��。當處理大數(shù)據(jù)查詢時���,MapReduce會將任務分解在多個節(jié)點處理,從而提高了數(shù)據(jù)處理的效率�����,避免了單機性能瓶頸限制����。
(3)Hive是Hadoop架構中的數(shù)據(jù)倉庫,主要用于靜態(tài)的結構以及需要經常分析的工作��。Hbase主要作為面向列的數(shù)據(jù)庫運行在HDFS上�,可存儲PB級的數(shù)據(jù)����。Hbase利用MapReduce來處理內部的海量數(shù)據(jù)�,并能在海量數(shù)據(jù)中定位所需的數(shù)據(jù)且訪問它。
(4)Sqoop是為數(shù)據(jù)的互操作性而設計�,可以從關系數(shù)據(jù)庫導入數(shù)據(jù)到Hadoop,并能直接導入到HDFS或Hive�����。
(5)Zookeeper在Hadoop架構中負責應用程序的協(xié)調工作���,以保持Hadoop集群內的同步工作。
(6)Thrift是一個軟件框架�����,用來進行可擴展且跨語言的服務的開發(fā)�����,最初由Facebook開發(fā)�����,是構建在各種編程語言間無縫結合的、高效的服務��。
Hadoop核心設計
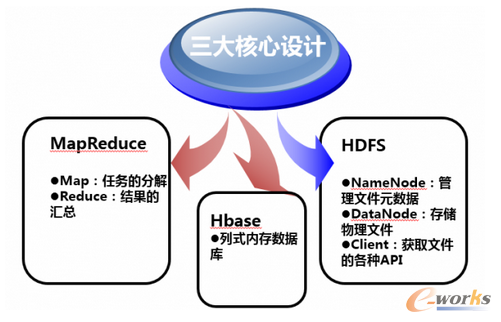
Hbase——分布式數(shù)據(jù)存儲系統(tǒng)
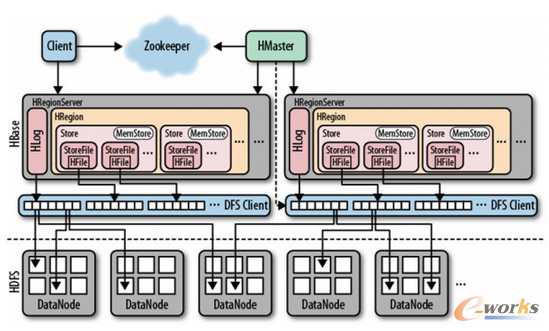
Client:使用HBase RPC機制與HMaster和HRegionServer進行通信
Zookeeper:協(xié)同服務管理���,HMaster通過Zookeepe可以隨時感知各個HRegionServer的健康狀況
HMaster: 管理用戶對表的增刪改查操作
HRegionServer:HBase中最核心的模塊����,主要負責響應用戶I/O請求����,向HDFS文件系統(tǒng)中讀寫數(shù)據(jù)
HRegion:Hbase中分布式存儲的最小單元,可以理解成一個Table
HStore:HBase存儲的核心��。由MemStore和StoreFile組成�����。
HLog:每次用戶操作寫入Memstore的同時��,也會寫一份數(shù)據(jù)到HLog文件
結合上述Hadoop架構功能�,大數(shù)據(jù)平臺系統(tǒng)功能建議如圖所示:
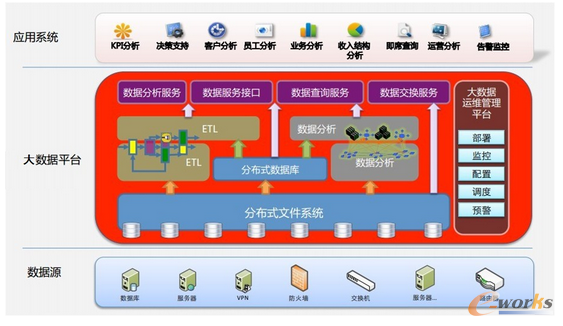
應用系統(tǒng):對于大多數(shù)企業(yè)而言,運營領域的應用是大數(shù)據(jù)最核心的應用���,之前企業(yè)主要使用來自生產經營中的各種報表數(shù)據(jù)��,但隨著大數(shù)據(jù)時代的到來���,來自于互聯(lián)網(wǎng)����、物聯(lián)網(wǎng)�、數(shù)據(jù)分析各種傳感器的海量數(shù)據(jù)撲面而至。于是����,一些企業(yè)開始挖掘和利用這些數(shù)據(jù),來推動運營效率的提升����。
數(shù)據(jù)平臺:借助大數(shù)據(jù)平臺,未來的互聯(lián)網(wǎng)絡將可以讓商家更了解消費者的使用習慣���,從而改進使用體驗?���;诖髷?shù)據(jù)基礎上的相應分析,能夠更有針對性的改進用戶體驗�����,同時挖掘新的商業(yè)機會。
數(shù)據(jù)源:數(shù)據(jù)源是指數(shù)據(jù)庫應用程序所使用的數(shù)據(jù)庫或者數(shù)據(jù)庫服務器����。豐富的數(shù)據(jù)源是大數(shù)據(jù)產業(yè)發(fā)展的前提。數(shù)據(jù)源在不斷拓展����,越來越多樣化。如:智能汽車可以把動態(tài)行駛過程變成數(shù)據(jù)����,嵌入到生產設備里的物聯(lián)網(wǎng)可以把生產過程和設備動態(tài)狀況變成數(shù)據(jù)。對數(shù)據(jù)源的不斷拓展不僅能帶來采集設備的發(fā)展�����,而且可以通過控制新的數(shù)據(jù)源更好地控制數(shù)據(jù)的價值�����。然而我國數(shù)字化的數(shù)據(jù)資源總量遠遠低于美歐����,就已有有限的數(shù)據(jù)資源來說�,還存在標準化�����、準確性�、完整性低,利用價值不高的情況��,這大大降低了數(shù)據(jù)的價值���。
三�、大數(shù)據(jù)的目標效果
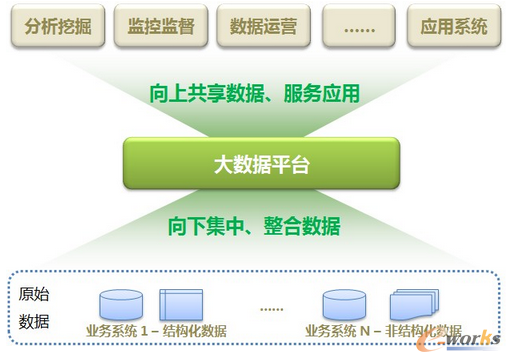
通過大數(shù)據(jù)的引入和部署���,可以達到如下效果:
1)數(shù)據(jù)整合
統(tǒng)一數(shù)據(jù)模型:承載企業(yè)數(shù)據(jù)模型����,促進企業(yè)各域數(shù)據(jù)邏輯模型的統(tǒng)一;
統(tǒng)一數(shù)據(jù)標準:統(tǒng)一建立標準的數(shù)據(jù)編碼目錄����,實現(xiàn)企業(yè)數(shù)據(jù)的標準化與統(tǒng)一存儲;
統(tǒng)一數(shù)據(jù)視圖:實現(xiàn)統(tǒng)一數(shù)據(jù)視圖�,使企業(yè)在客戶、產品和資源等視角獲取到一致的信息。
2)數(shù)據(jù)質量管控
數(shù)據(jù)質量校驗:根據(jù)規(guī)則對所存儲的數(shù)據(jù)進行一致性����、完整性和準確性的校驗,保證數(shù)據(jù)的一致性����、完整性和準確性;
數(shù)據(jù)質量管控:通過建立企業(yè)數(shù)據(jù)的質量標準、數(shù)據(jù)管控的組織��、數(shù)據(jù)管控的流程��,對數(shù)據(jù)質量進行統(tǒng)一管控��,以達到數(shù)據(jù)質量逐步完善��。
3)數(shù)據(jù)共享
消除網(wǎng)狀接口����,建立大數(shù)據(jù)共享中心,為各業(yè)務系統(tǒng)提供共享數(shù)據(jù)�,降低接口復雜度,提高系統(tǒng)間接口效率與質量;
以實時或準實時的方式將整合或計算好的數(shù)據(jù)向外系統(tǒng)提供��。
4)數(shù)據(jù)應用
查詢應用:平臺實現(xiàn)條件不固定�、不可預見��、格式靈活的按需查詢功能;
固定報表應用:視統(tǒng)計維度和指標固定的分析結果的展示��,可根據(jù)業(yè)務系統(tǒng)的需求��,分析產生各種業(yè)務報表數(shù)據(jù)等;
動態(tài)分析應用:按關心的維度和指標對數(shù)據(jù)進行主題性的分析�,動態(tài)分析應用中維度和指標不固定�。
四、總結
基于分布式技術構建的大數(shù)據(jù)平臺能夠有效降低數(shù)據(jù)存儲成本���,提升數(shù)據(jù)分析處理效率��,并具備海量數(shù)據(jù)��、高并發(fā)場景的支撐能力�����,可大幅縮短數(shù)據(jù)查詢響應時間���,滿足企業(yè)各上層應用的數(shù)據(jù)需求。
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號
經營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經營許可證編號:京B2-20210330