文 | Dong
來源 | 董的博客
概述
Apache Spark的高性能一定程度上取決于它采用的異步并發(fā)模型(這里指server/driver端采用的模型),這與Hadoop 2.0(包括YARN和MapReduce)是一致的�。Hadoop 2.0自己實現(xiàn)了類似Actor的異步并發(fā)模型,實現(xiàn)方式是epoll+狀態(tài)機��,而Apache Spark則直接采用了開源軟件Akka���,該軟件實現(xiàn)了Actor模型��,性能非常高�����。盡管二者在server端采用了一致的并發(fā)模型���,但在任務(wù)級別(特指Spark任務(wù)和MapReduce任務(wù))上卻采用了不同的并行機制: Hadoop MapReduce采用了多進程模型,而Spark采用了多線程模型�。
注意��,本文的多進程和多線程����,指的是同一個節(jié)點上多個任務(wù)的運行模式����。無論是MapReduce和Spark,整體上看��,都是多進程:MapReduce應(yīng)用程序是由多個獨立的Task進程組成的�;Spark應(yīng)用程序的運行環(huán)境是由多個獨立的Executor進程構(gòu)建的臨時資源池構(gòu)成的。
多進程模型便于細粒度控制每個任務(wù)占用的資源����,但會消耗較多的啟動時間,不適合運行低延遲類型的作業(yè)�,這是MapReduce廣為詬病的原因之一。而多線程模型則相反���,該模型使得Spark很適合運行低延遲類型的作業(yè)�。
總之�����,Spark同節(jié)點上的任務(wù)以多線程的方式運行在一個JVM進程中�����,可帶來以下好處:
任務(wù)啟動速度快���,與之相反的是MapReduce Task進程的慢啟動速度�����,通常需要1s左右��;
同節(jié)點上所有任務(wù)運行在一個進程中�,有利于共享內(nèi)存����。這非常適合內(nèi)存密集型任務(wù),尤其對于那些需要加載大量詞典的應(yīng)用程序����,可大大節(jié)省內(nèi)存。
同節(jié)點上所有任務(wù)可運行在一個JVM進程(Executor)中���,且Executor所占資源可連續(xù)被多批任務(wù)使用��,不會在運行部分任務(wù)后釋放掉�,這避免了每個任務(wù)重復(fù)申請資源帶來的時間開銷,對于任務(wù)數(shù)目非常多的應(yīng)用����,可大大降低運行時間。與之對比的是MapReduce中的Task:每個Task單獨申請資源�����,用完后馬上釋放�,不能被其他任務(wù)重用,盡管1.0支持JVM重用在一定程度上彌補了該問題�,但2.0尚未支持該功能。
盡管Spark的過線程模型帶來了很多好處�����,但同樣存在不足���,主要有:
由于同節(jié)點上所有任務(wù)運行在一個進程中�����,因此��,會出現(xiàn)嚴重的資源爭用���,難以細粒度控制每個任務(wù)占用資源。與之相反的是MapReduce���,它允許用戶單獨為Map Task和Reduce Task設(shè)置不同的資源�����,進而細粒度控制任務(wù)占用資源量�����,有利于大作業(yè)的正常平穩(wěn)運行�����。
下面簡要介紹MapReduce的多進程模型和Spark的多線程模型�。
MapReduce多進程模型
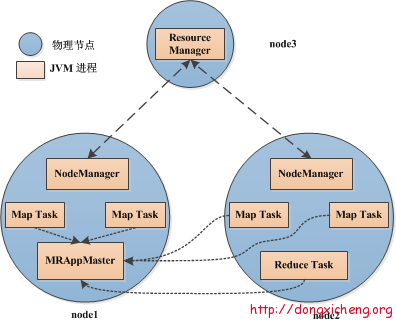
每個Task運行在一個獨立的JVM進程中��;
可單獨為不同類型的Task設(shè)置不同的資源量���,目前支持內(nèi)存和CPU兩種資源����;
每個Task運行完后,將釋放所占用的資源�����,這些資源不能被其他Task復(fù)用��,即使是同一個作業(yè)相同類型的Task���。也就是說����,每個Task都要經(jīng)歷“申請資源—> 運行Task –> 釋放資源”的過程�。
Spark多線程模型
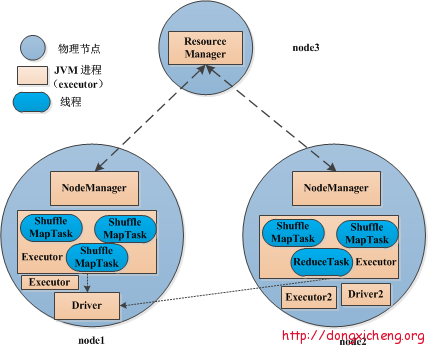
每個節(jié)點上可以運行一個或多個Executor服務(wù);
每個Executor配有一定數(shù)量的slot����,表示該Executor中可以同時運行多少個ShuffleMapTask或者ResultTask;
每個Executor單獨運行在一個JVM進程中�����,每個Task則是運行在Executor中的一個線程;
同一個Executor內(nèi)部的Task可共享內(nèi)存���,比如通過函數(shù)SparkContext#broadcast廣播的文件或者數(shù)據(jù)結(jié)構(gòu)只會在每個Executor中加載一次����,而不會像MapReduce那樣�,每個Task加載一次�;
Executor一旦啟動后,將一直運行�����,且它的資源可以一直被Task復(fù)用����,直到Spark程序運行完成后才釋放退出。
總結(jié)
總體上看���,Spark采用的是經(jīng)典的scheduler/workers模式�����,每個Spark應(yīng)用程序運行的第一步是構(gòu)建一個可重用的資源池�,然后在這個資源池里運行所有的ShuffleMapTask和ResultTask(注意,盡管Spark編程方式十分靈活��,不再局限于編寫Mapper和Reducer�,但是在Spark引擎內(nèi)部只用兩類Task便可表示出一個復(fù)雜的應(yīng)用程序,即ShuffleMapTask和ResultTask)��,而MapReduce應(yīng)用程序則不同�,它不會構(gòu)建一個可重用的資源池,而是讓每個Task動態(tài)申請資源�����,且運行完后馬上釋放資源�。
end
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認證考試,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330