文 | 寒小陽
來源 | CSDN博客
引言
提起筆來寫這篇博客,突然有點愧疚和尷尬�。愧疚的是,工作雜事多����,加之懶癌嚴(yán)重����,導(dǎo)致這個系列一直沒有更新�,向關(guān)注該系列的同學(xué)們道個歉。尷尬的是��,按理說���,機(jī)器學(xué)習(xí)介紹與算法一覽應(yīng)該放在最前面寫���,詳細(xì)的應(yīng)用建議應(yīng)該在講完機(jī)器學(xué)習(xí)常用算法之后寫,突然莫名奇妙在中間插播這么一篇�����,好像有點打亂主線�����。
老話說『亡羊補(bǔ)牢����,為時未晚』,前面開頭忘講的東西,咱在這塊兒補(bǔ)上�。我們先帶著大家過一遍傳統(tǒng)機(jī)器學(xué)習(xí)算法,基本思想和用途���。把問題解決思路和方法應(yīng)用建議提前到這里的想法也很簡單,希望能提前給大家一些小建議�����,對于某些容易出錯的地方也先給大家打個預(yù)防針�,這樣在理解后續(xù)相應(yīng)機(jī)器學(xué)習(xí)算法之后,使用起來也有一定的章法�����。
2.機(jī)器學(xué)習(xí)算法簡述
按照不同的分類標(biāo)準(zhǔn)����,可以把機(jī)器學(xué)習(xí)的算法做不同的分類。
2.1 從機(jī)器學(xué)習(xí)問題角度分類
我們先從機(jī)器學(xué)習(xí)問題本身分類的角度來看���,我們可以分成下列類型的算法:
監(jiān)督學(xué)習(xí)算法
機(jī)器學(xué)習(xí)中有一大部分的問題屬于『監(jiān)督學(xué)習(xí)』的范疇����,簡單口語化地說明,這類問題中���,給定的訓(xùn)練樣本中��,每個樣本的輸入x都對應(yīng)一個確定的結(jié)果y�����,我們需要訓(xùn)練出一個模型(數(shù)學(xué)上看是一個x→y的映射關(guān)系f)����,在未知的樣本x′給定后����,我們能對結(jié)果y′做出預(yù)測。
這里的預(yù)測結(jié)果如果是離散值(很多時候是類別類型���,比如郵件分類問題中的垃圾郵件/普通郵件��,比如用戶會/不會購買某商品)��,那么我們把它叫做分類問題(classification problem);如果預(yù)測結(jié)果是連續(xù)值(比如房價���,股票價格等等)�����,那么我們把它叫做回歸問題(regression problem)��。
有一系列的機(jī)器學(xué)習(xí)算法是用以解決監(jiān)督學(xué)習(xí)問題的��,比如最經(jīng)典的用于分類問題的樸素貝葉斯、邏輯回歸�����、支持向量機(jī)等等;比如說用于回歸問題的線性回歸等等����。
無監(jiān)督學(xué)習(xí)
有另外一類問題,給我們的樣本并沒有給出『標(biāo)簽/標(biāo)準(zhǔn)答案』�,就是一系列的樣本。而我們需要做的事情是���,在一些樣本中抽取出通用的規(guī)則��。這叫做『無監(jiān)督學(xué)習(xí)』����。包括關(guān)聯(lián)規(guī)則和聚類算法在內(nèi)的一系列機(jī)器學(xué)習(xí)算法都屬于這個范疇。
半監(jiān)督學(xué)習(xí)
這類問題給出的訓(xùn)練數(shù)據(jù)��,有一部分有標(biāo)簽�����,有一部分沒有標(biāo)簽����。我們想學(xué)習(xí)出數(shù)據(jù)組織結(jié)構(gòu)的同時,也能做相應(yīng)的預(yù)測��。此類問題相對應(yīng)的機(jī)器學(xué)習(xí)算法有自訓(xùn)練(Self-Training)�、直推學(xué)習(xí)(Transductive Learning)、生成式模型(Generative Model)等���。
總體說來����,最常見是前兩類問題�����,而對應(yīng)前兩類問題的一些機(jī)器學(xué)習(xí)算法如下:

2.2 從算法的功能角度分類
我們也可以從算法的共性(比如功能����,運作方式)角度對機(jī)器學(xué)習(xí)算法分類��。下面我們根據(jù)算法的共性去對它們歸個類����。不過需要注意的是���,我們下面的歸類方法可能對分類和回歸有比較強(qiáng)的傾向性����,而這兩類問題也是最常遇到的��。
2.2.1 回歸算法(Regression Algorithms)
回歸算法是一種通過最小化預(yù)測值與實際結(jié)果值之間的差距�����,而得到輸入特征之間的最佳組合方式的一類算法�。對于連續(xù)值預(yù)測有線性回歸等���,而對于離散值/類別預(yù)測�����,我們也可以把邏輯回歸等也視作回歸算法的一種���,常見的回歸算法如下:
Ordinary Least Squares Regression (OLSR)
Linear Regression
Logistic Regression
Stepwise Regression
Locally Estimated Scatterplot Smoothing (LOESS)
Multivariate Adaptive Regression Splines (MARS)
2.2.2 基于實例的算法(Instance-based Algorithms)
這里所謂的基于實例的算法��,我指的是我們最后建成的模型����,對原始數(shù)據(jù)樣本實例依舊有很強(qiáng)的依賴性���。這類算法在做預(yù)測決策時����,一般都是使用某類相似度準(zhǔn)則�,去比對待預(yù)測的樣本和原始樣本的相近度,再給出相應(yīng)的預(yù)測結(jié)果��。常見的基于實例的算法有:
k-Nearest Neighbour (kNN)
Learning Vector Quantization (LVQ)
Self-Organizing Map (SOM)
Locally Weighted Learning (LWL)
2.2.3 決策樹類算法(Decision Tree Algorithms)
決策樹類算法��,會基于原始數(shù)據(jù)特征���,構(gòu)建一顆包含很多決策路徑的樹���。預(yù)測階段選擇路徑進(jìn)行決策��。常見的決策樹算法包括:
Classification and Regression Tree (CART)
Iterative Dichotomiser 3 (ID3)
C4.5 and C5.0 (different versions of a powerful approach)
Chi-squared Automatic Interaction Detection (CHAID)
M5
Conditional Decision Trees
2.2.4 貝葉斯類算法(Bayesian Algorithms)
這里說的貝葉斯類算法���,指的是在分類和回歸問題中,隱含使用了貝葉斯原理的算法���。包括:
Naive Bayes
Gaussian Naive Bayes
Multinomial Naive Bayes
Averaged One-Dependence Estimators (AODE)
Bayesian Belief Network (BBN)
Bayesian Network (BN)
2.2.5 聚類算法(Clustering Algorithms)
聚類算法做的事情是����,把輸入樣本聚成圍繞一些中心的『數(shù)據(jù)團(tuán)』�,以發(fā)現(xiàn)數(shù)據(jù)分布結(jié)構(gòu)的一些規(guī)律。常用的聚類算法包括:
k-Means
Hierarchical Clustering
Expectation Maximisation (EM)
2.2.6 關(guān)聯(lián)規(guī)則算法(Association Rule Learning Algorithms)
關(guān)聯(lián)規(guī)則算法是這樣一類算法:它試圖抽取出����,最能解釋觀察到的訓(xùn)練樣本之間關(guān)聯(lián)關(guān)系的規(guī)則����,也就是獲取一個事件和其他事件之間依賴或關(guān)聯(lián)的知識,常見的關(guān)聯(lián)規(guī)則算法有:
Apriori algorithm
Eclat algorithm
2.2.7 人工神經(jīng)網(wǎng)絡(luò)類算法(Artificial Neural Network Algorithms)
這是受人腦神經(jīng)元工作方式啟發(fā)而構(gòu)造的一類算法����。需要提到的一點是,我把『深度學(xué)習(xí)』單拎出來了�����,這里說的人工神經(jīng)網(wǎng)絡(luò)偏向于更傳統(tǒng)的感知算法,主要包括:
Perceptron
Back-Propagation
Radial Basis Function Network (RBFN)
2.2.8 深度學(xué)習(xí)(Deep Learning Algorithms)
深度學(xué)習(xí)是近年來非?�;鸬?a href='/map/jiqixuexi/' style='color:#000;font-size:inherit;'>機(jī)器學(xué)習(xí)領(lǐng)域����,相對于上面列的人工神經(jīng)網(wǎng)絡(luò)算法,它通常情況下�����,有著更深的層次和更復(fù)雜的結(jié)構(gòu)����。有興趣的同學(xué)可以看看我們另一個系列機(jī)器學(xué)習(xí)與計算機(jī)視覺,最常見的深度學(xué)習(xí)算法包括:
Deep Boltzmann Machine (DBM)
Deep Belief Networks (DBN)
Convolutional Neural Network (CNN)
Stacked Auto-Encoders
2.2.9 降維算法(Dimensionality Reduction Algorithms)
從某種程度上說���,降維算法和聚類其實有點類似��,因為它也在試圖發(fā)現(xiàn)原始訓(xùn)練數(shù)據(jù)的固有結(jié)構(gòu)�,但是降維算法在試圖���,用更少的信息(更低維的信息)總結(jié)和描述出原始信息的大部分內(nèi)容�。有意思的是,降維算法一般在數(shù)據(jù)的可視化�����,或者是降低數(shù)據(jù)計算空間有很大的作用����。它作為一種機(jī)器學(xué)習(xí)的算法,很多時候用它先處理數(shù)據(jù)�����,再灌入別的機(jī)器學(xué)習(xí)算法學(xué)習(xí)���。主要的降維算法包括:
Principal Component Analysis (PCA)
Principal Component Regression (PCR)
Partial Least Squares Regression (PLSR)
Sammon Mapping
Multidimensional Scaling (MDS)
Linear Discriminant Analysis (LDA)
Mixture Discriminant Analysis (MDA)
Quadratic Discriminant Analysis (QDA)
Flexible Discriminant Analysis (FDA)
2.2.10 模型融合算法(Ensemble Algorithms)
嚴(yán)格意義上來說��,這不算是一種機(jī)器學(xué)習(xí)算法���,而更像是一種優(yōu)化手段/策略����,它通常是結(jié)合多個簡單的弱機(jī)器學(xué)習(xí)算法,去做更可靠的決策����。拿分類問題舉個例�����,直觀的理解�,就是單個分類器的分類是可能出錯����,不可靠的,但是如果多個分類器投票�����,那可靠度就會高很多�����。常用的模型融合增強(qiáng)方法包括:
Random Forest
Boosting
Bootstrapped Aggregation (Bagging)
AdaBoost
Stacked Generalization (blending)
Gradient Boosting Machines (GBM)
Gradient Boosted Regression Trees (GBRT)
2.3 機(jī)器學(xué)習(xí)算法使用圖譜
scikit-learn作為一個豐富的python機(jī)器學(xué)習(xí)庫�,實現(xiàn)了絕大多數(shù)機(jī)器學(xué)習(xí)的算法,有相當(dāng)多的人在使用�,于是我這里很無恥地把machine learning cheat sheet for sklearn搬過來了,原文可以看這里��。哈哈,既然講機(jī)器學(xué)習(xí)���,我們就用機(jī)器學(xué)習(xí)的語言來解釋一下���,這是針對實際應(yīng)用場景的各種條件限制,對scikit-learn里完成的算法構(gòu)建的一顆決策樹�,每一組條件都是對應(yīng)一條路徑,能找到相對較為合適的一些解決方法����,具體如下:
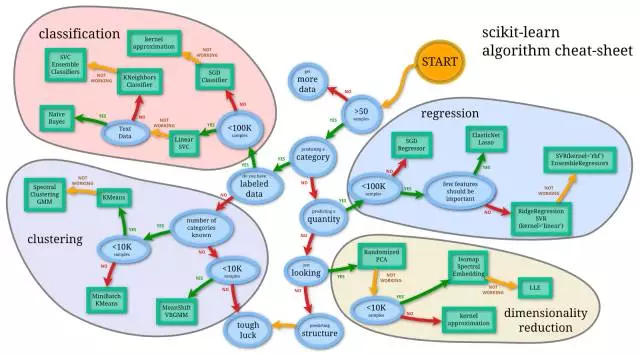
首先樣本量如果非常少的話,其實所有的機(jī)器學(xué)習(xí)算法都沒有辦法從里面『學(xué)到』通用的規(guī)則和模式���,so多弄點數(shù)據(jù)是王道���。然后根據(jù)問題是有/無監(jiān)督學(xué)習(xí)和連續(xù)值/離散值預(yù)測,分成了分類����、聚類、回歸和維度約減四個方法類����,每個類里根據(jù)具體情況的不同,又有不同的處理方法���。
3. 機(jī)器學(xué)習(xí)問題解決思路
上面帶著代價走馬觀花過了一遍機(jī)器學(xué)習(xí)的若干算法����,下面我們試著總結(jié)總結(jié)在拿到一個實際問題的時候���,如果著手使用機(jī)器學(xué)習(xí)算法去解決問題���,其中的一些注意點以及核心思路。主要包括以下內(nèi)容:
拿到數(shù)據(jù)后怎么了解數(shù)據(jù)(可視化)
選擇最貼切的機(jī)器學(xué)習(xí)算法
定位模型狀態(tài)(過/欠擬合)以及解決方法
大量極的數(shù)據(jù)的特征分析與可視化
各種損失函數(shù)(loss function)的優(yōu)缺點及如何選擇
多說一句����,這里寫的這個小教程,主要是作為一個通用的建議和指導(dǎo)方案����,你不一定要嚴(yán)格按照這個流程解決機(jī)器學(xué)習(xí)問題。
3.1 數(shù)據(jù)與可視化
我們先使用scikit-learn的make_classification函數(shù)來生產(chǎn)一份分類數(shù)據(jù)��,然后模擬一下拿到實際數(shù)據(jù)后我們需要做的事情�����。
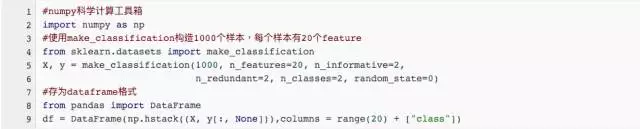
我們生成了一份包含1000個分類數(shù)據(jù)樣本的數(shù)據(jù)集,每個樣本有20個數(shù)值特征�����。同時我們把數(shù)據(jù)存儲至pandas中的DataFrame數(shù)據(jù)結(jié)構(gòu)中�。我們?nèi)∏皫仔械臄?shù)據(jù)看一眼:
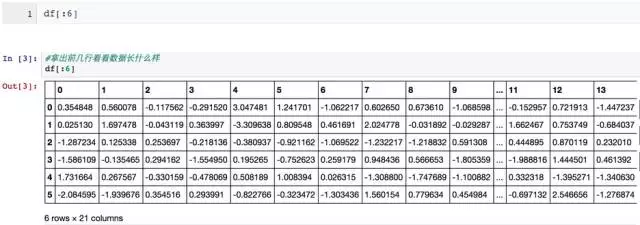
不幸的是,肉眼看數(shù)據(jù)����,尤其是維度稍微高點的時候,很有可能看花了也看不出看不出任何線索��。幸運的是����,我們對于圖像的理解力,比數(shù)字好太多���,而又有相當(dāng)多的工具可以幫助我們『可視化』數(shù)據(jù)分布�。
我們在處理任何數(shù)據(jù)相關(guān)的問題時�,了解數(shù)據(jù)都是很有必要的,而可視化可以幫助我們更好地直觀理解數(shù)據(jù)的分布和特性
數(shù)據(jù)的可視化有很多工具包可以用����,比如下面我們用來做數(shù)據(jù)可視化的工具包Seaborn��。最簡單的可視化就是數(shù)據(jù)散列分布圖和柱狀圖�,這個可以用Seanborn的pairplot來完成�。以下圖中2種顏色表示2種不同的類����,因為20維的可視化沒有辦法在平面表示,我們?nèi)〕隽艘徊糠志S度�,兩兩組成pair看數(shù)據(jù)在這2個維度平面上的分布狀況,代碼和結(jié)果如下:

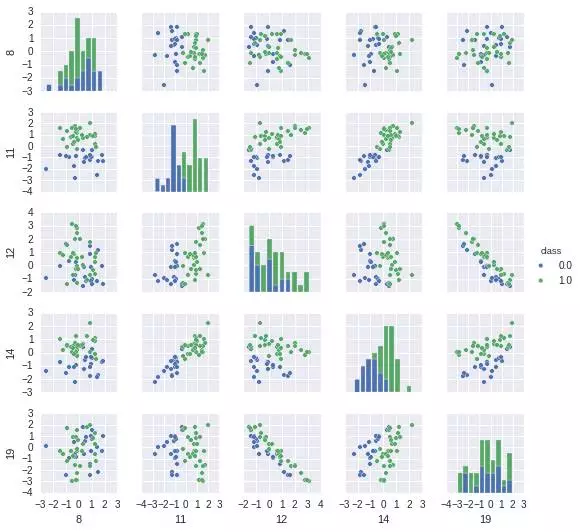
我們從散列圖和柱狀圖上可以看出��,確實有些維度的特征相對其他維度�����,有更好的區(qū)分度���,比如第11維和14維看起來很有區(qū)分度��。這兩個維度上看����,數(shù)據(jù)點是近似線性可分的��。而12維和19維似乎呈現(xiàn)出了很高的負(fù)相關(guān)性。接下來我們用Seanborn中的corrplot來計算計算各維度特征之間(以及最后的類別)的相關(guān)性���。代碼和結(jié)果圖如下:

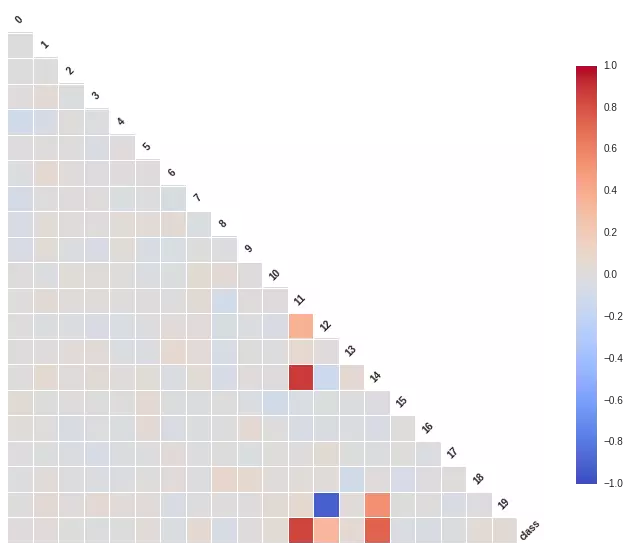
相關(guān)性圖很好地印證了我們之前的想法�,可以看到第11維特征和第14維特征和類別有極強(qiáng)的相關(guān)性�,同時它們倆之間也有極高的相關(guān)性。而第12維特征和第19維特征卻呈現(xiàn)出極強(qiáng)的負(fù)相關(guān)性��。強(qiáng)相關(guān)的特征其實包含了一些冗余的特征�,而除掉上圖中顏色較深的特征,其余特征包含的信息量就沒有這么大了����,它們和最后的類別相關(guān)度不高,甚至各自之間也沒什么先慣性���。
插一句����,這里的維度只有20���,所以這個相關(guān)度計算并不費太大力氣��,然而實際情形中���,你完全有可能有遠(yuǎn)高于這個數(shù)字的特征維度����,同時樣本量也可能多很多�����,那種情形下我們可能要先做一些處理����,再來實現(xiàn)可視化了�。別著急,一會兒我們會講到����。
3.2 機(jī)器學(xué)習(xí)算法選擇
數(shù)據(jù)的情況我們大致看了一眼,確定一些特征維度之后�����,我們可以考慮先選用機(jī)器學(xué)習(xí)算法做一個baseline的系統(tǒng)出來了���。這里我們繼續(xù)參照上面提到過的機(jī)器學(xué)習(xí)算法使用圖譜��。
我們只有1000個數(shù)據(jù)樣本�,是分類問題,同時是一個有監(jiān)督學(xué)習(xí)�����,因此我們根據(jù)圖譜里教的方法�����,使用LinearSVC(support vector classification with linear kernel)試試���。注意�����,LinearSVC需要選擇正則化方法以緩解過擬合問題;我們這里選擇使用最多的L2正則化����,并把懲罰系數(shù)C設(shè)為10����。我們改寫一下sklearn中的學(xué)習(xí)曲線繪制函數(shù),畫出訓(xùn)練集和交叉驗證集上的得分:
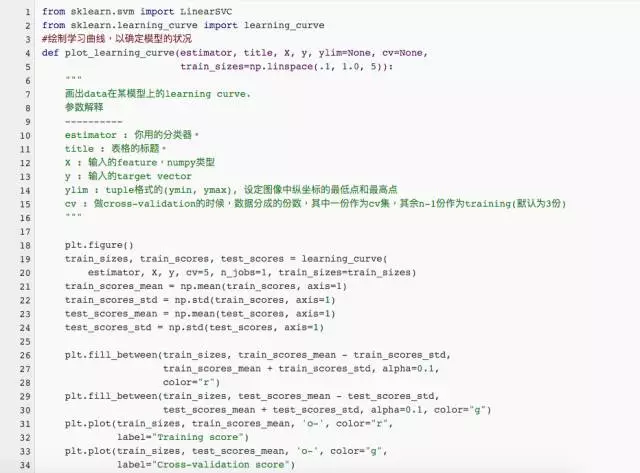
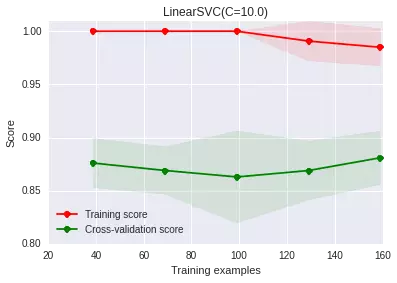
這幅圖上,我們發(fā)現(xiàn)隨著樣本量的增加�,訓(xùn)練集上的得分有一定程度的下降,交叉驗證集上的得分有一定程度的上升��,但總體說來�����,兩者之間有很大的差距�����,訓(xùn)練集上的準(zhǔn)確度遠(yuǎn)高于交叉驗證集��。這其實意味著我們的模型處于過擬合的狀態(tài)��,也即模型太努力地刻畫訓(xùn)練集��,一不小心把很多噪聲的分布也擬合上了����,導(dǎo)致在新數(shù)據(jù)上的泛化能力變差了��。
3.2.1 過擬合的定位與解決
問題來了���,過擬合咋辦?
針對過擬合���,有幾種辦法可以處理:
增大樣本量
這個比較好理解吧��,過擬合的主要原因是模型太努力地去記住訓(xùn)練樣本的分布狀況���,而加大樣本量,可以使得訓(xùn)練集的分布更加具備普適性�����,噪聲對整體的影響下降��。恩�����,我們提高點樣本量試試:

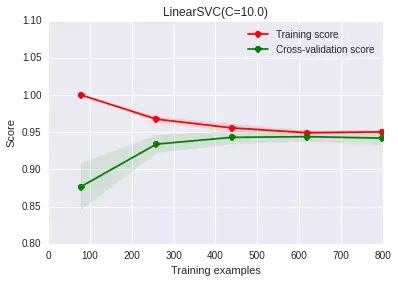
是不是發(fā)現(xiàn)問題好了很多?隨著我們增大訓(xùn)練樣本量�,我們發(fā)現(xiàn)訓(xùn)練集和交叉驗證集上的得分差距在減少,最后它們已經(jīng)非常接近了��。增大樣本量���,最直接的方法當(dāng)然是想辦法去采集相同場景下的新數(shù)據(jù)��,如果實在做不到����,也可以試試在已有數(shù)據(jù)的基礎(chǔ)上做一些人工的處理生成新數(shù)據(jù)(比如圖像識別中,我們可能可以對圖片做鏡像變換�����、旋轉(zhuǎn)等等)����,當(dāng)然,這樣做一定要謹(jǐn)慎��,強(qiáng)烈建議想辦法采集真實數(shù)據(jù)����。
減少特征的量(只用我們覺得有效的特征)
比如在這個例子中�����,我們之前的數(shù)據(jù)可視化和分析的結(jié)果表明����,第11和14維特征包含的信息對識別類別非常有用,我們可以只用它們。

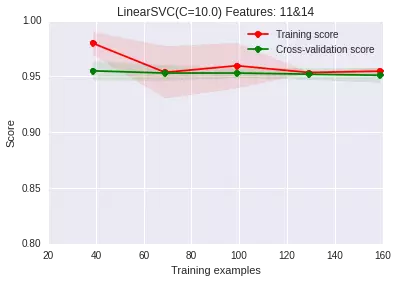
從上圖上可以看出�����,過擬合問題也得到一定程度的緩解��。不過我們這是自己觀察后�����,手動選出11和14維特征�����。那能不能自動進(jìn)行特征組合和選擇呢����,其實我們當(dāng)然可以遍歷特征的組合樣式,然后再進(jìn)行特征選擇(前提依舊是這里特征的維度不高���,如果高的話�,遍歷所有的組合是一個非常非常非常耗時的過程!!):

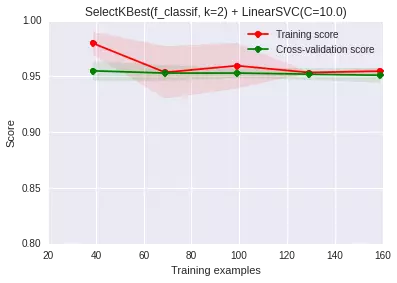
如果你自己跑一下程序���,會發(fā)現(xiàn)在我們自己手造的這份數(shù)據(jù)集上����,這個特征篩選的過程超級順利,但依舊像我們之前提過的一樣���,這是因為特征的維度不太高��。
從另外一個角度看�����,我們之所以做特征選擇���,是想降低模型的復(fù)雜度,而更不容易刻畫到噪聲數(shù)據(jù)的分布��。從這個角度出發(fā)��,我們還可以有(1)多項式你和模型中降低多項式次數(shù)
(2)神經(jīng)網(wǎng)絡(luò)中減少神經(jīng)網(wǎng)絡(luò)的層數(shù)和每層的結(jié)點數(shù) (c)SVM中增加RBF-kernel的bandwidth等方式來降低模型的復(fù)雜度���。
話說回來���,即使以上提到的辦法降低模型復(fù)雜度后�����,好像能在一定程度上緩解過擬合,但是我們一般還是不建議一遇到過擬合��,就用這些方法處理����,優(yōu)先用下面的方法:
增強(qiáng)正則化作用(比如說這里是減小LinearSVC中的C參數(shù))
正則化是我認(rèn)為在不損失信息的情況下,最有效的緩解過擬合現(xiàn)象的方法�����。

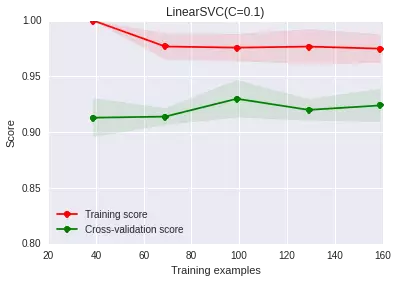
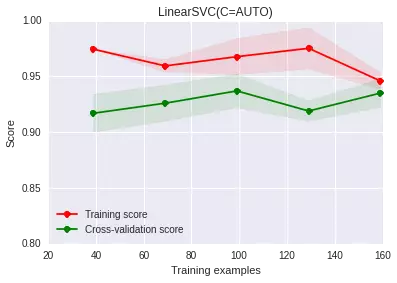
調(diào)整正則化系數(shù)后�,發(fā)現(xiàn)確實過擬合現(xiàn)象有一定程度的緩解,但依舊是那個問題�,我們現(xiàn)在的系數(shù)是自己敲定的,有沒有辦法可以自動選擇最佳的這個參數(shù)呢?可以�。我們可以在交叉驗證集上做grid-search查找最好的正則化系數(shù)(對于大數(shù)據(jù)樣本,我們依舊需要考慮時間問題���,這個過程可能會比較慢):

在500個點得到的結(jié)果是:{‘C’: 0.01}使用新的C參數(shù)�����,我們再看看學(xué)習(xí)曲線:
對于特征選擇的部分�����,我打算多說幾句�,我們剛才看過了用sklearn.feature_selection中的SelectKBest來選擇特征的過程,也提到了在高維特征的情況下���,這個過程可能會非常非常慢��。那我們有別的辦法可以進(jìn)行特征選擇嗎?比如說�����,我們的分類器自己能否甄別那些特征是對最后的結(jié)果有益的?這里有個實際工作中用到的小技巧����。
我們知道:
l2正則化����,它對于最后的特征權(quán)重的影響是,盡量打散權(quán)重到每個特征維度上�,不讓權(quán)重集中在某些維度上,出現(xiàn)權(quán)重特別高的特征�。
而l1正則化,它對于最后的特征權(quán)重的影響是�����,讓特征獲得的權(quán)重稀疏化����,也就是對結(jié)果影響不那么大的特征,干脆就拿不著權(quán)重�。
那基于這個理論,我們可以把SVC中的正則化替換成l1正則化����,讓其自動甄別哪些特征應(yīng)該留下權(quán)重。

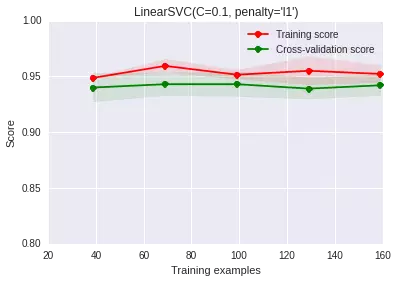
好了�����,我們一起來看看最后特征獲得的權(quán)重:

得到結(jié)果:

你看��,5 9 11 12 17 18這些維度的特征獲得了權(quán)重�����,而第11維權(quán)重最大��,也說明了它影響程度最大����。
3.2.2 欠擬合定位與解決
我們再隨機(jī)生成一份數(shù)據(jù)[1000*20]的數(shù)據(jù)(但是分布和之前有變化)�����,重新使用LinearSVC來做分類��。分類分類

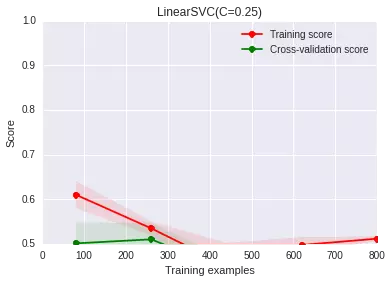
簡直爛出翔了有木有��,二分類問題����,我們做隨機(jī)猜測�����,準(zhǔn)確率都有0.5�,這比隨機(jī)猜測都高不了多少!!!怎么辦?
不要盲目動手收集更多資料,或者調(diào)整正則化參數(shù)����。我們從學(xué)習(xí)曲線上其實可以看出來,訓(xùn)練集上的準(zhǔn)確度和交叉驗證集上的準(zhǔn)確度都很低�����,這其實就對應(yīng)了我們說的『欠擬合』狀態(tài)。別急��,我們回到我們的數(shù)據(jù)����,還是可視化看看:

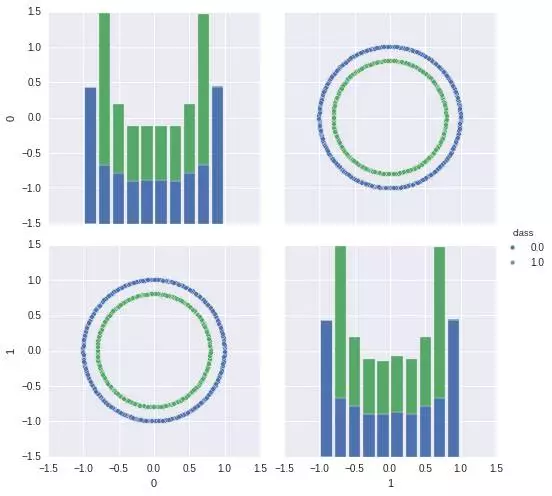
你發(fā)現(xiàn)什么了�����,數(shù)據(jù)根本就沒辦法線性分割!!!��,所以你再找更多的數(shù)據(jù)���,或者調(diào)整正則化參數(shù)�����,都是無濟(jì)于事的!!!
那我們又怎么解決欠擬合問題呢?通常有下面一些方法:
調(diào)整你的特征(找更有效的特征!!)
比如說我們觀察完現(xiàn)在的數(shù)據(jù)分布���,然后我們先對數(shù)據(jù)做個映射:

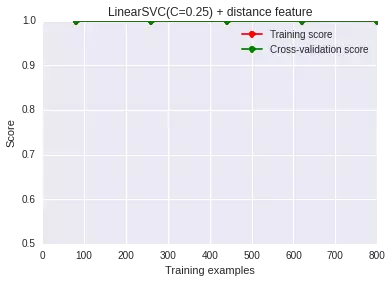
臥槽,少年�,這準(zhǔn)確率,被嚇尿了有木有啊!!!所以你看,選用的特征影響太大了�����,當(dāng)然����,我們這里是人工模擬出來的數(shù)據(jù),分布太明顯了����,實際數(shù)據(jù)上,會比這個麻煩一些��,但是在特征上面下的功夫還是很有回報的��。
使用更復(fù)雜一點的模型(比如說用非線性的核函數(shù))
我們對模型稍微調(diào)整了一下����,用了一個復(fù)雜一些的非線性rbf kernel:非線性rbf kernel非線性rbf kernel

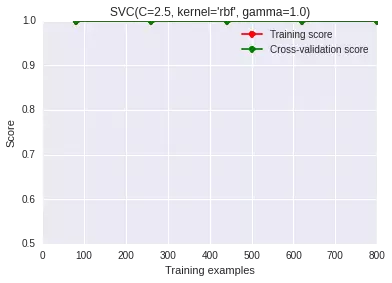
你看,效果依舊很贊��。
3.3 關(guān)于大數(shù)據(jù)樣本集和高維特征空間
我們在小樣本的toy dataset上���,怎么搗鼓都有好的方法����。但是當(dāng)數(shù)據(jù)量和特征樣本空間膨脹非常厲害時,很多東西就沒有那么好使了�,至少是一個很耗時的過程。舉個例子說�����,我們現(xiàn)在重新生成一份數(shù)據(jù)集�,但是這次,我們生成更多的數(shù)據(jù)���,更高的特征維度,而分類的類別也提高到5�����。
3.3.1 大數(shù)據(jù)情形下的模型選擇與學(xué)習(xí)曲線
在上面提到的那樣一份數(shù)據(jù)上�,我們用LinearSVC可能就會有點慢了,我們注意到機(jī)器學(xué)習(xí)算法使用圖譜推薦我們使用SGDClassifier�����。其實本質(zhì)上說�����,這個模型也是一個線性核函數(shù)的模型,不同的地方是�����,它使用了隨機(jī)梯度下降做訓(xùn)練�,所以每次并沒有使用全部的樣本,收斂速度會快很多��。再多提一點����,SGDClassifier對于特征的幅度非常敏感,也就是說��,我們在把數(shù)據(jù)灌給它之前��,應(yīng)該先對特征做幅度調(diào)整��,當(dāng)然��,用sklearn的StandardScaler可以很方便地完成這一點�����。
StandardScaler每次只使用一部分(mini-batch)做訓(xùn)練,在這種情況下���,我們使用交叉驗證(cross-validation)并不是很合適��,我們會使用相對應(yīng)的progressive validation:簡單解釋一下����,estimator每次只會拿下一個待訓(xùn)練batch在本次做評估���,然后訓(xùn)練完之后�����,再在這個batch上做一次評估,看看是否有優(yōu)化���。
得到如下的結(jié)果:
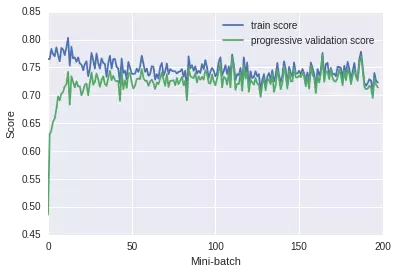
從這個圖上的得分�,我們可以看出在50個mini-batch迭代之后����,數(shù)據(jù)上的得分就已經(jīng)變化不大了。但是好像得分都不太高����,所以我們猜測一下�,這個時候我們的數(shù)據(jù)��,處于欠擬合狀態(tài)���。我們剛才在小樣本集合上提到了����,如果欠擬合��,我們可以使用更復(fù)雜的模型���,比如把核函數(shù)設(shè)置為非線性的�����,但遺憾的是像rbf核函數(shù)是沒有辦法和SGDClassifier兼容的�����。因此我們只能想別的辦法了���,比如這里�����,我們可以把SGDClassifier整個替換掉了��,用多層感知神經(jīng)網(wǎng)來完成這個任務(wù)�����,我們之所以會想到多層感知神經(jīng)網(wǎng)�����,是因為它也是一個用隨機(jī)梯度下降訓(xùn)練的算法����,同時也是一個非線性的模型��。當(dāng)然根據(jù)機(jī)器學(xué)習(xí)算法使用圖譜���,也可以使用核估計(kernel-approximation)來完成這個事情。
3.3.2 大數(shù)據(jù)量下的可視化
大樣本數(shù)據(jù)的可視化是一個相對比較麻煩的事情�,一般情況下我們都要用到降維的方法先處理特征。我們找一個例子來看看���,可以怎么做��,比如我們數(shù)據(jù)集取經(jīng)典的『手寫數(shù)字集』�����,首先找個方法看一眼這個圖片數(shù)據(jù)集�����。
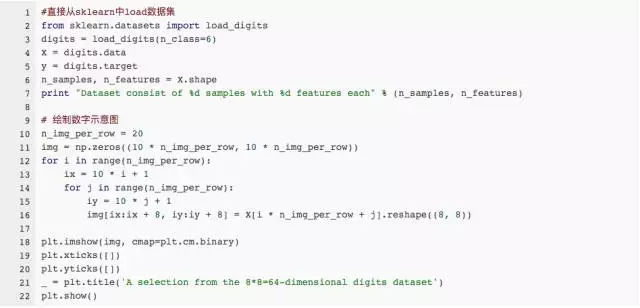

我們總共有1083個訓(xùn)練樣本�����,包含手寫數(shù)字(0,1,2,3,4,5)�����,每個樣本圖片中的像素點平鋪開都是64位����,這個維度顯然是沒辦法直接可視化的。下面我們基于scikit-learn的示例教程對特征用各種方法做降維處理��,再可視化��。
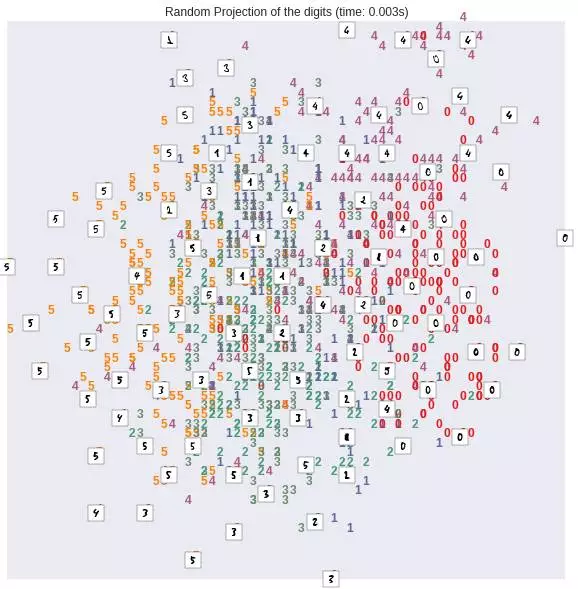
隨機(jī)投射
我們先看看,把數(shù)據(jù)隨機(jī)投射到兩個維度上的結(jié)果:

結(jié)果如下:
PCA降維
在維度約減/降維領(lǐng)域有一個非常強(qiáng)大的算法叫做PCA(Principal Component Analysis��,主成分分析)�����,它能將原始的絕大多數(shù)信息用維度遠(yuǎn)低于原始維度的幾個主成分表示出來��。PCA在我們現(xiàn)在的數(shù)據(jù)集上效果還不錯��,我們來看看用PCA對原始特征降維至2維后���,原始樣本在空間的分布狀況:

得到的結(jié)果如下:
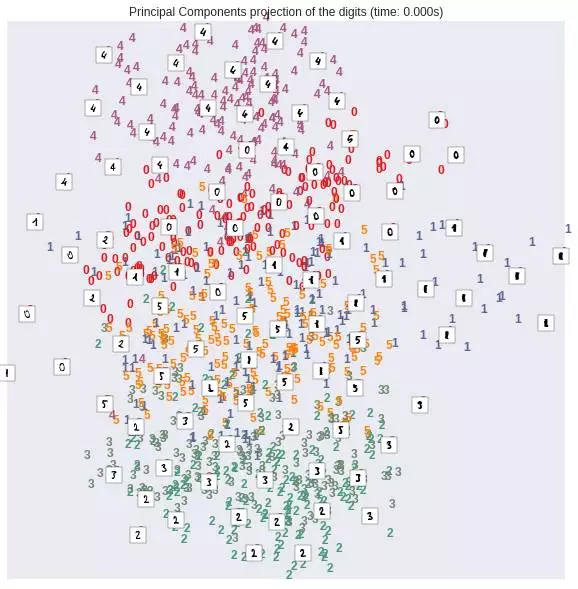
我們可以看出�����,效果還不錯�,不同的手寫數(shù)字在2維平面上�,顯示出了區(qū)域集中性。即使它們之間有一定的重疊區(qū)域�。如果我們用一些非線性的變換來做降維操作,從原始的64維降到2維空間����,效果更好,比如這里我們用到一個技術(shù)叫做t-SNE��,sklearn的manifold對其進(jìn)行了實現(xiàn):

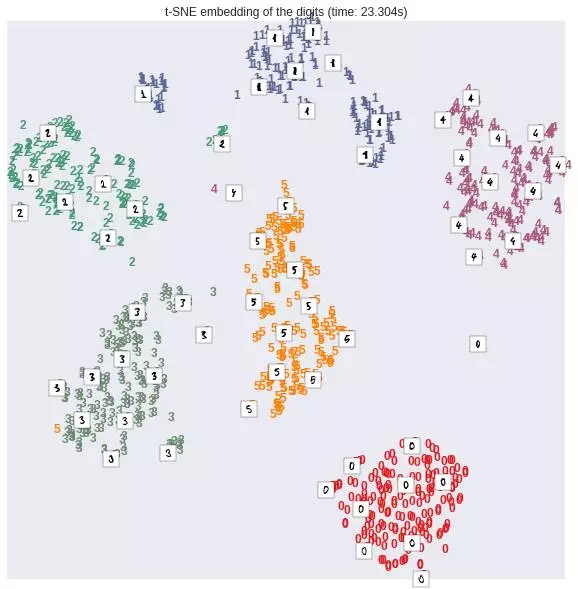
我們發(fā)現(xiàn)結(jié)果非常的驚人�����,似乎這個非線性變換降維過后�����,僅僅2維的特征����,就可以將原始數(shù)據(jù)的不同類別,在平面上很好地劃分開��。不過t-SNE也有它的缺點����,一般說來,相對于線性變換的降維�����,它需要更多的計算時間。也不太適合在大數(shù)據(jù)集上全集使用���。
3.4 損失函數(shù)的選擇
損失函數(shù)的選擇對于問題的解決和優(yōu)化�����,非常重要����。我們先來看一眼各種不同的損失函數(shù):

得到結(jié)果圖像如下:

不同的損失函數(shù)有不同的優(yōu)缺點:0-1損失函數(shù)(zero-one loss)非常好理解�����,直接對應(yīng)分類問題中判斷錯的個數(shù)��。但是比較尷尬的是它是一個非凸函數(shù)�����,這意味著其實不是那么實用��。
hinge loss(SVM中使用到的)的健壯性相對較高(對于異常點/噪聲不敏感)�。但是它沒有那么好的概率解釋。
log損失函數(shù)(log-loss)的結(jié)果能非常好地表征概率分布����。因此在很多場景����,尤其是多分類場景下����,如果我們需要知道結(jié)果屬于每個類別的置信度�,那這個損失函數(shù)很適合。缺點是它的健壯性沒有那么強(qiáng)�,相對hinge loss會對噪聲敏感一些。
多項式損失函數(shù)(exponential loss)(AdaBoost中用到的)對離群點/噪聲非常非常敏感�����。但是它的形式對于boosting算法簡單而有效�����。
感知損失(perceptron loss)可以看做是hinge loss的一個變種��。hinge loss對于判定邊界附近的點(正確端)懲罰力度很高��。而perceptron loss����,只要樣本的判定類別結(jié)果是正確的�,它就是滿意的�����,而不管其離判定邊界的距離���。優(yōu)點是比hinge loss簡單�����,缺點是因為不是max-margin boundary����,所以得到模型的泛化能力沒有hinge loss強(qiáng)�。
4. 總結(jié)
全文到此就結(jié)束了。先走馬觀花看了一遍機(jī)器學(xué)習(xí)的算法���,然后給出了對應(yīng)scikit-learn的『秘密武器』機(jī)器學(xué)習(xí)算法使用圖譜���,緊接著從了解數(shù)據(jù)(可視化)、選擇機(jī)器學(xué)習(xí)算法�����、定位過/欠擬合及解決方法、大量極的數(shù)據(jù)可視化和損失函數(shù)優(yōu)缺點與選擇等方面介紹了實際機(jī)器學(xué)習(xí)問題中的一些思路和方法����。本文和文章機(jī)器學(xué)習(xí)系列(3)_邏輯回歸應(yīng)用之Kaggle泰坦尼克之災(zāi)都提及了一些處理實際機(jī)器學(xué)習(xí)問題的思路和方法,有相似和互補(bǔ)之處����,歡迎大家參照著看����。
本文鏈接:http://www.36dsj.com/archives/39530
end
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學(xué)習(xí)CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330