文 | 譚政
來(lái)源 | 煉數(shù)成金
作者簡(jiǎn)介
譚政���,Hulu 網(wǎng)大數(shù)據(jù)基礎(chǔ)平臺(tái)研發(fā)��。曾在新浪微博平臺(tái)工作過(guò)���。專注于大數(shù)據(jù)存儲(chǔ)和處理�,對(duì) Hadoop、HBase 以及 Spark 等等均有深入的了解��。
Spark 最新的特性以及功能
2015 年中 Spark 版本從 1.2.1 升級(jí)到當(dāng)前最新的 1.5.2����,1.6.0 版本也馬上要進(jìn)行發(fā)布,每個(gè)版本都包含了許多的新特性以及重要的性能改進(jìn)�,我會(huì)按照時(shí)間順序列舉部分改進(jìn)出來(lái),希望大家對(duì) Spark 版本的演化有一個(gè)稍微直觀的認(rèn)識(shí)�����。
由于篇幅關(guān)系�,這次不能給大家一一講解其中每一項(xiàng)改進(jìn),因此挑選了一些我認(rèn)為比較重要的特性來(lái)給大家講解�����。如有遺漏和錯(cuò)誤���,還請(qǐng)幫忙指正��。
Spark 版本演化
首先還是先來(lái)看一下 Spark 對(duì)應(yīng)版本的變化:
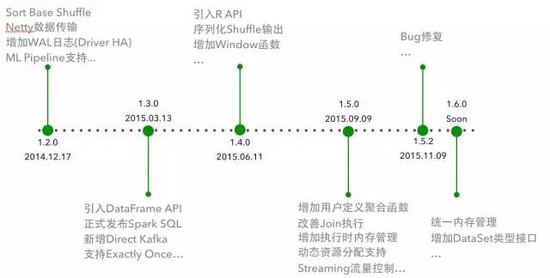
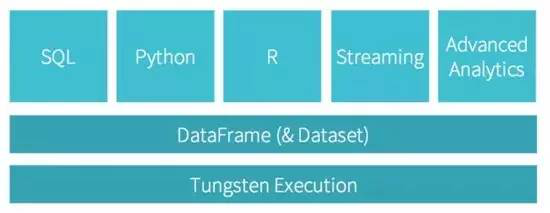
先來(lái)一個(gè)整體的介紹:1.2 版本主要集中于 Shuffle 優(yōu)化�����, 1.3 版本主要的貢獻(xiàn)是 DataFrame API��, 1.4 版本引入 R API 并啟動(dòng) Tungsten 項(xiàng)目階段�,1.5 版本完成了 Tungsten 項(xiàng)目的第一階段,1.6 版本將會(huì)繼續(xù)進(jìn)行 Tungsten 項(xiàng)目的第二個(gè)階段��。而我下面則重點(diǎn)介紹 DataFrame API 以及 Tungsten 項(xiàng)目���。
DataFrame 介紹
DataFrame API 是在 1.3.0 中引入的�,其目的是為了統(tǒng)一 Spark 中對(duì)結(jié)構(gòu)化數(shù)據(jù)的處理�����。在引入 DataFrame 之前�,Spark 之有上針對(duì)結(jié)構(gòu)化數(shù)據(jù)的 SQL 查詢以及 Hive 查詢。
這些查詢的處理流程基本類(lèi)似:查詢串先需要經(jīng)過(guò)解析器生成邏輯查詢計(jì)劃�����,然后經(jīng)過(guò)優(yōu)化器生成物理查詢計(jì)劃,最終被執(zhí)行器調(diào)度執(zhí)行���。
而不同的查詢引擎有不同的優(yōu)化器和執(zhí)行器實(shí)現(xiàn)���,并且使用了不同的中間數(shù)據(jù)結(jié)構(gòu),這就導(dǎo)致很難將不同的引擎的優(yōu)化合并到一起����,新增一個(gè)查詢語(yǔ)言也是非常艱難�����。
為了解決這個(gè)問(wèn)題�,Spark 對(duì)結(jié)構(gòu)化數(shù)據(jù)表示進(jìn)行了高層抽象,產(chǎn)生了 DataFrame API���。簡(jiǎn)單來(lái)說(shuō) DataFrame 可以看做是帶有 Schema 的 RDD(在1.3之前DataFrame 就叫做 SchemaRDD����,受到 R 以及 Python 的啟發(fā)改為 DataFrame這個(gè)名字)�����。
在 DataFrame 上可以應(yīng)用一系列的表達(dá)式,最終生成一個(gè)樹(shù)形的邏輯計(jì)劃�����。這個(gè)邏輯計(jì)劃將會(huì)經(jīng)歷 Analysis�����, Logical Optimization�����, Physical Planning 以及 Code Generation 階段最終變成可執(zhí)行的 RDD�����,如下圖所示:
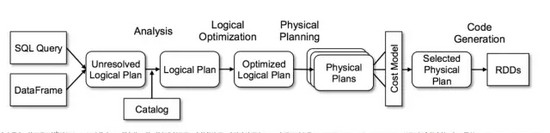
在上圖中����,除了最開(kāi)始解析 SQL/HQL 查詢串不一樣之外,剩下的部分都是同一套執(zhí)行流程���,在這套流程上 Spark 實(shí)現(xiàn)了對(duì)上層 Spark SQL�����, Hive SQL��, DataFrame 以及 R 語(yǔ)言的支持��。
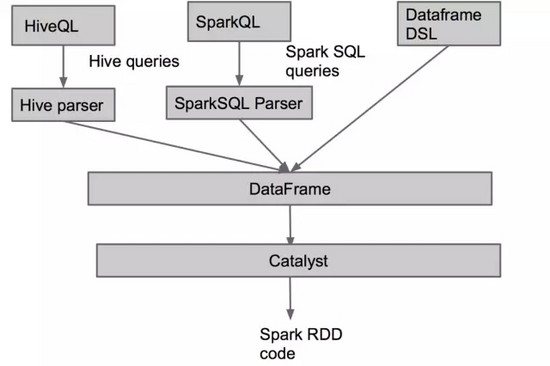
下面我們來(lái)看看這些語(yǔ)言的簡(jiǎn)單示例:
Spark SQL : val count = sqlContext.sql("SELECT COUNT(*) FROM records").collect().head.getLong(0)



各個(gè)語(yǔ)言的使用方式都很類(lèi)似����。除了類(lèi) SQL 的表達(dá)式操作之外,DataFrame 也提供普通的類(lèi)似于 RDD 的轉(zhuǎn)換����,例如可以寫(xiě)如下代碼:

另外還值得一提的是�,和 DataFrame API 緊密相關(guān)的 API -- DataSource API。如果說(shuō) DataFrame API 提供的是對(duì)結(jié)構(gòu)化數(shù)據(jù)的高層抽象���,那么 DataSource API 提供的則是對(duì)于結(jié)構(gòu)化數(shù)據(jù)統(tǒng)一的讀寫(xiě)接口�。
DataSource API 支持從 JSON�����, JDBC��, ORC����, parquet 中加載結(jié)構(gòu)化數(shù)據(jù) (SQLContext 類(lèi)中的諸多讀取方法�,均會(huì)返回一個(gè) DataFrame 對(duì)象)��,也同時(shí)支持將 DataFrame 的數(shù)據(jù)寫(xiě)入到上述數(shù)據(jù)源中 (DataFrame 中的 save 系列方法 )�����。
這兩個(gè) API 再加上層多種語(yǔ)言的支持�����,使得 Spark 對(duì)結(jié)構(gòu)化數(shù)據(jù)擁有強(qiáng)大的處理能力�,極大簡(jiǎn)化了用戶編程工作。
Tungsten 項(xiàng)目介紹
在官方介紹中 Tungsten 將會(huì)是對(duì) Spark 執(zhí)行引擎所做的最大的修改��,其主要目標(biāo)是改進(jìn) Spark 內(nèi)存和 CPU 的使用效率����,盡可能發(fā)揮出機(jī)器硬件的最大性能。
之所以將優(yōu)化的重點(diǎn)集中在內(nèi)存和 CPU 而不是 IO 之上是社區(qū)實(shí)踐發(fā)現(xiàn)現(xiàn)在很多的大數(shù)據(jù)應(yīng)用的瓶頸在 CPU ��。例如目前很多網(wǎng)絡(luò) IO 鏈路的速度達(dá)到 10Gbps�,SSD 硬盤(pán)和 Striped HDD 陣列的使用也使得磁盤(pán) IO 也有較大提升。而 CPU 的主頻卻沒(méi)有多少提升,CPU 核數(shù)的增長(zhǎng)也不如前兩者迅速��。
此外在 Spark 已經(jīng)對(duì) IO 做過(guò)很多的優(yōu)化(如列存儲(chǔ)以及 IO 剪枝可以減少 IO的數(shù)據(jù)量�����,優(yōu)化的 Shuffle 改善了 IO 和網(wǎng)絡(luò)的傳輸效率)����,再繼續(xù)進(jìn)行優(yōu)化提升空間并不大。
而隨著序列化以及 Hash 的廣泛使用����,現(xiàn)在 CPU 反而成為了一個(gè)瓶頸。
內(nèi)存方面�,使用 Java 原生的堆內(nèi)存管理方式很容易產(chǎn)生 OOM 問(wèn)題,并伴隨著較大的 GC 負(fù)擔(dān)�,進(jìn)一步降低了 CPU 的利用率��。
基于上述觀察 Spark 在 1.4 中啟動(dòng)了 Tungsten 項(xiàng)目�����,并在 1.5 中完成第一階段的優(yōu)化
這些優(yōu)化包括下面三個(gè)方面:
內(nèi)存管理和二進(jìn)制格式處理
緩存友好的計(jì)算
代碼生成
內(nèi)存管理和二進(jìn)制格式處理
避免以原生格式存儲(chǔ) Java 對(duì)象(使用二進(jìn)制的存儲(chǔ)格式)����,減少 GC 負(fù)擔(dān)
壓縮內(nèi)存數(shù)據(jù)格式��,減少內(nèi)存占用以及可能的溢寫(xiě)���。使用更準(zhǔn)確的內(nèi)存的統(tǒng)計(jì)而不是依賴啟發(fā)規(guī)則管理內(nèi)存。
對(duì)于那些已知數(shù)據(jù)格式運(yùn)算( DataFrame 和 SQL )����,直接使用二進(jìn)制的運(yùn)算,避免序列化和反序列化開(kāi)銷(xiāo)��。
緩存友好的計(jì)算
更加快的排序以及 Hash��,優(yōu)化 Aggregation�����, Join 以及 Shuffle 操作��。
代碼生成
更快的表達(dá)式計(jì)算以及 DataFrame/SQL 運(yùn)算(這是代碼生成的主要應(yīng)用場(chǎng)景��,主要是為了降低進(jìn)行表達(dá)式評(píng)估中 JVM 的各種開(kāi)銷(xiāo)�����,如虛函數(shù)調(diào)用,分支預(yù)測(cè)�,原始類(lèi)型的對(duì)象裝箱開(kāi)銷(xiāo)以及內(nèi)存消耗)更快的序列化。
相關(guān)的每個(gè)版本所做的優(yōu)化如下:
Tungsten 項(xiàng)目并不是完全是一個(gè)通用的優(yōu)化技術(shù)�,其中很多優(yōu)化利用了 DataFrame 模型所提供的豐富的語(yǔ)義信息(因此 DataFrame 和 Spark SQL 查詢能夠享受該項(xiàng)目所來(lái)的大量的好處),同樣未來(lái)也會(huì)改進(jìn) RDD API 來(lái)為底層優(yōu)化提供更多的信息支持�����。
Spark 在 Hulu 的實(shí)踐
Hulu 是一家在線付費(fèi)視頻網(wǎng)站���,每天都有大量的用戶觀看行為數(shù)據(jù)產(chǎn)生����,這些數(shù)據(jù)會(huì)由 Hulu 的大數(shù)據(jù)平臺(tái)進(jìn)行存儲(chǔ)以及處理�����。推薦團(tuán)隊(duì)需要從這些數(shù)據(jù)中挖掘出單個(gè)用戶感興趣的內(nèi)容并推薦給對(duì)應(yīng)的觀眾���,廣告團(tuán)隊(duì)需要根據(jù)用戶的觀看記錄以及行為給其推薦的最合適廣告��,而數(shù)據(jù)團(tuán)隊(duì)則需要分析所有數(shù)據(jù)的各個(gè)維度并為公司的策略制定提供有效支持。
他們的所有工作都是在 Hulu 的大數(shù)據(jù)平臺(tái)上完成的�,該平臺(tái)由 HDFS/Yarn, HBase, Hive�, Cassandera 以及的 Presto,Spark 等組成����。Spark 是運(yùn)行在 Yarn上,由 Yarn 來(lái)管理資源并進(jìn)行任務(wù)調(diào)度�����。
Spark 則主要有兩類(lèi)應(yīng)用:Streaming 應(yīng)用以及短時(shí) Job��。
Streaming 應(yīng)用中各個(gè)設(shè)備前端將用戶的行為日志輸入到 Kafka 中����,然后由 Spark Streaming 來(lái)進(jìn)行處理,輸出結(jié)果到 Cassandera���, HBase 以及 HDFS 中����。短時(shí) Job 并不像 Streaming 應(yīng)用一樣一直運(yùn)行,而是由用戶或者定時(shí)腳本觸發(fā),一般運(yùn)行時(shí)間從幾分鐘到十幾個(gè)小時(shí)不等���。
此外為了方便 PM 類(lèi)型的用戶更便捷的使用 Spark�,我們也搭建了 Apache Zeppelin 這種交互式可視化執(zhí)行環(huán)境�����。對(duì)于非 Python/Scala/Java/R 用戶(例如某些用戶想在 NodeJS 中提交 Spark 任務(wù))�,我們也提供 REST 的 Spark-JobServer 來(lái)方便用戶提交作業(yè)。
Hulu 從 0.9 版本就開(kāi)始將 Spark 應(yīng)用于線上作業(yè)����,內(nèi)部經(jīng)歷了 1.1.1, 1.2.0��, 1.4.0 等諸多版本��,目前內(nèi)部使用的最新版本是基于社區(qū) 1.5.1 進(jìn)行改造的�。
在之前的版本中我們遇到的很多的問(wèn)題也添加了不少新功能,大部分修改都已經(jīng)包含在最新版本里面����,我就不再這里贅述了。這節(jié)里我主要想講的是社區(qū)里所沒(méi)有的��,但是我們認(rèn)為還比較重要的一些修改����。
較多的迭代觸發(fā) StackOverflow 的問(wèn)題
在某些機(jī)器學(xué)習(xí)算法里面需要進(jìn)行比較多輪的迭代��,當(dāng)?shù)拇螖?shù)超過(guò)一定次數(shù)時(shí)候應(yīng)用程序就會(huì)發(fā)生 StackOverflow 而崩潰。這個(gè)次數(shù)限制并不會(huì)很大��,幾百次迭代就可能發(fā)生棧溢出���。大家可以利用一小段代碼來(lái)進(jìn)行一個(gè)簡(jiǎn)單的測(cè)試:

產(chǎn)生上述錯(cuò)誤的原因在于 Driver 將 RDD 任務(wù)發(fā)送給 Executor 執(zhí)行的時(shí)候需要將 RDD 的信息序列化后廣播到對(duì)應(yīng)的 Executor 上���。而 RDD 在序列的時(shí)候需要遞歸將其依賴的 RDD 序列化,這樣在出現(xiàn)長(zhǎng) lineage 的 RDD 的時(shí)候就可能因?yàn)榫€程的棧幀內(nèi)存不夠�����,拋出 StackOverflow 異常�。
解決方法也比較直接,就是將遞歸改為迭代�,把原來(lái)需要遞歸保存在線程棧幀的序列化 RDD 挪到堆區(qū)進(jìn)行保存。具體的做法是將 RDD 的依賴關(guān)系分離出來(lái)���,變成兩個(gè)映射表: rddId->List of depId 以及depId -> Dependency��。Driver 端然后將 RDD 以及這些映射序列化為字節(jié)數(shù)組廣播出去����,Executor 端接收到廣播消息后重新將映射組裝成為原始的依賴。
這個(gè)過(guò)程中要改動(dòng) RDD 核心 Task 接口���,需要經(jīng)過(guò)嚴(yán)格的測(cè)試���。但是在做這種優(yōu)化之后,迭代個(gè)一兩千次都沒(méi)有什么問(wèn)題�。
Streaming 延遲數(shù)據(jù)接收機(jī)制( Receive-Base )
在 Receive-Base 的 Spark Streaming 的架構(gòu)中, 主要有兩個(gè)角色 Driver 和 Executor��。
在 Executor 中運(yùn)行著 Receiver��, Receiver 的主要作用是從外部接收數(shù)據(jù)并緩存到本地內(nèi)存中����,同時(shí) Receiver 回向 Driver 匯報(bào)自己所接收的數(shù)據(jù)塊,Driver 定期產(chǎn)生新的任務(wù)并分發(fā)到各個(gè) Executor 去處理這些數(shù)據(jù)�����。
在應(yīng)用啟動(dòng)的時(shí)候��,Driver 會(huì)首先將 Receiver 處理程序調(diào)度到各個(gè) Executor 上讓其初始化��。一旦 Receiver 初始化完畢,它就開(kāi)始源源不斷的接收數(shù)據(jù)����,并且需要 Driver 定期調(diào)度任務(wù)來(lái)消耗這些數(shù)據(jù)。
但是在某些場(chǎng)景下��, Executor 處理端還并沒(méi)有準(zhǔn)備好�����,無(wú)法開(kāi)始處理數(shù)據(jù)���。
這時(shí)候在 Receiver 端就會(huì)發(fā)生內(nèi)存積壓,隨著積壓的數(shù)據(jù)越來(lái)越多��,大部分?jǐn)?shù)據(jù)都會(huì)撐過(guò)新生代回收年齡進(jìn)入老年代�,進(jìn)一步給 GC 帶來(lái)嚴(yán)重的壓力,這個(gè)時(shí)候也就離應(yīng)用程序崩潰不遠(yuǎn)了����。
在 Hulu 的 Spark Streaming 處理中,需要加載并初始化很多機(jī)器學(xué)習(xí)的模型���,這些模型的初始化非常費(fèi)時(shí)間��,長(zhǎng)的可能需要半個(gè)小時(shí)才能初始化完畢��。在此期間 Receiver 不能接收數(shù)據(jù)����,否者內(nèi)存將會(huì)被消耗殆盡。
Hulu 中的解決方法是在每個(gè) Executor 接收任何任務(wù)之前先進(jìn)行執(zhí)行一個(gè)用戶定義的初始化任務(wù)�����,初始化任務(wù)中可以執(zhí)行一些獨(dú)立的用戶代碼����。我們?cè)谛略隽艘粋€(gè)接口,讓用戶可以設(shè)置自定義的初始化任務(wù)���。
如下代碼所示:
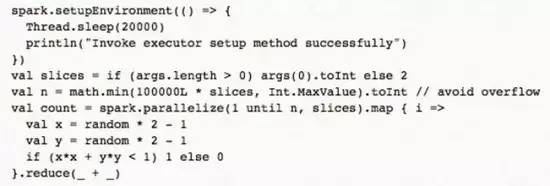
實(shí)現(xiàn)上需要更改 Spark 的任務(wù)調(diào)度器�����,先將每個(gè) Executor 設(shè)置為未初始化狀態(tài)�����,除了初始化任務(wù)之外調(diào)度器不會(huì)給未初始化狀態(tài)的 Executor 分配其他任務(wù)����。等 Executor 運(yùn)行完初始化任務(wù),調(diào)度器更新 Executor 的狀態(tài)為已初始化����,這樣的 Executor 就可以分配給其他正常任務(wù)了,包括初始化 Receiver 的任務(wù)�����。
其他注意事項(xiàng)
Spark 允許用戶設(shè)置 spark.executor.userClassPathFirst�����,這可以部分緩解用戶代碼庫(kù)和 Spark 系統(tǒng)代碼庫(kù)沖突的問(wèn)題�。
但是在實(shí)踐過(guò)程中我們發(fā)現(xiàn)��,大并發(fā)情況加載相同的類(lèi)有可能發(fā)生死鎖的情況(我們的一個(gè)場(chǎng)景下有 1/10 幾率復(fù)現(xiàn)該問(wèn)題)��。
其問(wèn)題在于 Spark 所新增加的 ChildFirstURLClassLoader 的實(shí)現(xiàn)引入了并發(fā)死鎖的問(wèn)題���。
Java 7 中的 ClassLoader 本身提供細(xì)粒度的類(lèi)加載并發(fā)鎖����,可以做到為每個(gè) classname 設(shè)置一個(gè)鎖,但是使用該細(xì)粒度的類(lèi)加載鎖有一個(gè)條件�,用戶自己實(shí)現(xiàn)的 ClassLoader 必須在自身靜態(tài)初始化方法中將自己注冊(cè)到 ClassLoader 中。
然而在 Scala 語(yǔ)言中并沒(méi)有類(lèi)的靜態(tài)初始化方法����,只有一個(gè)伴生對(duì)象的初始化方法。但是伴生對(duì)象和類(lèi)對(duì)象的類(lèi)型并不完全一致���。
因此 Scala 在 ChildFirstURLClassLoader 中模仿 Java 的 ClassLoader 實(shí)現(xiàn)了自己的細(xì)粒度的類(lèi)加載鎖�,然而這段代碼卻無(wú)法達(dá)到預(yù)期目的��,最終還是會(huì)降級(jí)到 ClassLoader 級(jí)別的鎖�,并且在某些場(chǎng)景下還會(huì)觸發(fā)死鎖,解決方法是去除對(duì)應(yīng)的細(xì)粒度鎖代碼��。
Spark 未來(lái)的發(fā)展趨勢(shì)
Spark 1.6 即將發(fā)布���,其中最重要的特性有兩個(gè) [SPARK-10000] 統(tǒng)一內(nèi)存管理以及 [SPARK-9999] DataSet API�。當(dāng)然還有很多其他的改進(jìn)�����,由于篇幅關(guān)系�,下面主要介紹上兩個(gè)���。
統(tǒng)一內(nèi)存管理
在 1.5 以及之前存在兩個(gè)獨(dú)立的內(nèi)存管理:執(zhí)行時(shí)內(nèi)存管理以及存儲(chǔ)內(nèi)存管理,前者是在對(duì) Shuffle�, Join, Sort����, Aggregation 等計(jì)算的時(shí)候所用到的內(nèi)存,后者是緩存以及廣播變量時(shí)用的內(nèi)存�。
可以通過(guò) spark.storage.memoryFraction 來(lái)指定兩部分的大小,默認(rèn)存儲(chǔ)占據(jù) 60% 的堆內(nèi)存���。這種方式分配的內(nèi)存都是靜態(tài)的�,需要手動(dòng)調(diào)優(yōu)以避免 spill���,且沒(méi)有一個(gè)合理的默認(rèn)值可以覆蓋到所有的應(yīng)用場(chǎng)景。
在 1.6 中這兩個(gè)部分內(nèi)存管理被統(tǒng)一起來(lái)了�,當(dāng)執(zhí)行時(shí)內(nèi)存超過(guò)給自己分配的大小時(shí)可以臨時(shí)向存儲(chǔ)時(shí)內(nèi)存借用空間,臨時(shí)借用的內(nèi)存可以在任何時(shí)候被回收���,反之亦然����。更進(jìn)一步可以設(shè)置存儲(chǔ)內(nèi)存的最低量,系統(tǒng)保證這部分量不會(huì)被剔除���。
DataSet API
RDD API 存儲(chǔ)的是原始的 JVM 對(duì)象���,提供豐富的函數(shù)式運(yùn)算符,使用起來(lái)很靈活���,但是由于缺乏類(lèi)型信息很難對(duì)它的執(zhí)行過(guò)程優(yōu)化���。DataFrame API 存儲(chǔ)的是 Row 對(duì)象,提供了基于表達(dá)式的運(yùn)算以及邏輯查詢計(jì)劃�����,很方便做優(yōu)化����,并且執(zhí)行起來(lái)速度很快,但是卻不如 RDD API 靈活���。
DataSet API 則充分結(jié)合了二者的優(yōu)勢(shì)���,既允許用戶很方便的操作領(lǐng)域?qū)ο笥謸碛?nbsp;SQL 執(zhí)行引擎的高性能表現(xiàn)�����。
本質(zhì)上來(lái)說(shuō) DataSet API 相當(dāng)于 RDD + Encoder�, Encoder 可以將原始的 JVM對(duì)象高效的轉(zhuǎn)化為二進(jìn)制格式�,使得可以后續(xù)對(duì)其進(jìn)行更多的處理。目前是實(shí)現(xiàn)為 Catalyst 的邏輯計(jì)劃�����,這樣就能夠充分利用現(xiàn)有的 Tungsten 的優(yōu)化成果��。
DataSet API 需要達(dá)到如下幾點(diǎn)目標(biāo):
快速:Encoder 需要至少和現(xiàn)有的 Kryo 或者 Java 序列一樣快�����。
類(lèi)型安全:在操作這些對(duì)象的時(shí)候需要盡可能提供編譯時(shí)的類(lèi)型安全�����,如果編譯期無(wú)法知曉類(lèi)型����,在發(fā)生 Schema 不匹配的時(shí)候需要快速失敗�����。
對(duì)象模型支持:默認(rèn)需要提供原子類(lèi)型,case 類(lèi)����,tuple, POJOs�����, JavaBeans 的 Encoder�����。
Java 兼容性:需要提供一個(gè)簡(jiǎn)單的 API 來(lái)兼容 Scala 和 Java�����,盡可能使用這些 API����,如果實(shí)在不能使用這些API也需要提供重載的版本。
DataFrame 的互操作:用戶需要能夠無(wú)縫的在 DataSet API 和 DataFrame API之間做轉(zhuǎn)換����。
目前 DataSet API 和 DataFrame API 還是獨(dú)立的兩個(gè) API����,未來(lái) DataFrame 有可能繼承自 DataSet[Row]����。
最后再來(lái)看一下整體的架構(gòu):
Q & A
1、在 hulu��, streaming 跑在多少個(gè)節(jié)點(diǎn)上����?Zeppelin 和 sparknotebook.io 各有什么優(yōu)劣、是如何選型的����?
hulu 的 Spark Streaming 運(yùn)行在 YARN 上,規(guī)模是幾百個(gè)節(jié)點(diǎn)��。我們當(dāng)前主要用的是 Zeppelin�,sparknotebook.ion 目前還沒(méi)有試用
2、我們用的是 hive on spark 模式����,因?yàn)?nbsp;hive 是統(tǒng)一入口�,上面已經(jīng)有 mr 和 tez��,請(qǐng)問(wèn)對(duì)比 spark sql 各自優(yōu)缺點(diǎn)�����?還有就到對(duì)比一下 spark shuffle 和 yarn自帶 shuffle(on yarn 模式)的優(yōu)缺點(diǎn)����?
底層的存儲(chǔ)引擎不一樣�����,相比于性能方面 spark 和 tez 不相上下����,但是穩(wěn)定性方面 spark 更勝一籌。spark shuffle 提供了三種實(shí)現(xiàn)���,分別是 hash-based��,sort-based 和 tungsten-sort�, 而 mapreduce shuffle 知識(shí) sort-based���,在靈活度上��,spark 更高�����,且個(gè)別之處����,spark 有深度優(yōu)化。
3�、能否簡(jiǎn)單說(shuō)說(shuō) spark 在圖片計(jì)算方面的應(yīng)用?
是指圖像處理方面嗎����,這方面 Spark 并沒(méi)有專門(mén)的組件來(lái)處理。圖片方面的應(yīng)用比較少�����,至少在 hulu 沒(méi)有����。
4、Tungsten 項(xiàng)目目前成熟嗎�����?或者說(shuō)貴司有線上應(yīng)用沒(méi)?
Tungsten 項(xiàng)目還處于開(kāi)發(fā)階段(階段二)����,不建議在線上使用��。
5����、請(qǐng)問(wèn)使用 Spark streaming 在 YARN 上和其他任務(wù)共同運(yùn)行,穩(wěn)定性如何�����?YARN 有沒(méi)有做 CPU 級(jí)別的隔離���?我們?cè)?nbsp;YARN 上運(yùn)行的任務(wù)����,運(yùn)行幾天就會(huì)掛掉�����,通常都是 OOM,但是從程序看��,并沒(méi)有使用過(guò)多內(nèi)存��。
如果 YARN 上還會(huì)混合運(yùn)行 mapreduce 和 tez 等應(yīng)用��,則會(huì)對(duì) Spark streaming 存在資源競(jìng)爭(zhēng)�,造成性能不穩(wěn)定,可以使用 label-based scheduling 對(duì)一些節(jié)點(diǎn)打標(biāo)簽�,專門(mén)運(yùn)行 Spark streaming??傮w上說(shuō),spark streaming 在 YARN 上運(yùn)行比較穩(wěn)定����。YARN 對(duì) CPU 有隔離,使用的 cgroups�。 如果是 OOM 掛掉,可能程序存在內(nèi)存泄露��,不知道你們用的什么版本���,建議使用 jprofile 定位一下內(nèi)存效率之處����。
6、能否簡(jiǎn)單對(duì)比下 Storm 和 Spark 的優(yōu)劣���?如何技術(shù)選型��?
Storm 是實(shí)時(shí)流式數(shù)據(jù)處理���,面向行處理�,單條延時(shí)比較低。Spark 是近實(shí)時(shí)流式處理��,面向 vp 處理���,吞吐量比較高�。如果應(yīng)用對(duì)實(shí)時(shí)性要求比較高建議試用 Storm�, 否則大家可以考慮利用 Spark 的豐富的數(shù)據(jù)操作能力。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫(kù),點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情����;
? 想了解CDA考試含金量,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330