原文來源 | cloudera
譯文來源 | 開源中國社區(qū)
最近�����,我加入了Cloudera����,在這之前,我在計算生物學/基因組學上已經(jīng)工作了差不多10年��。我的分析工作主要是利用Python語言和它很棒的科學計算棧來進行的�����。但Apache Hadoop的生態(tài)系統(tǒng)大部分都是用Java來實現(xiàn)的�,也是為Java準備的,這讓我很惱火����。所以���,我的頭等大事變成了尋找一些Python可以用的Hadoop框架。
在這篇文章里��,我會把我個人對這些框架的一些無關(guān)科學的看法寫下來����,這些框架包括:
Hadoop流
mrjob
dumbo
hadoopy
pydoop
其它
最終,在我的看來����,Hadoop的數(shù)據(jù)流(streaming)是最快也是最透明的選項,而且最適合于文本處理����。mrjob最適合于在Amazon EMR上快速工作,但是會有顯著的性能損失��。dumbo 對于大多數(shù)復雜的工作都很方便(對象作為鍵名(key))�����,但是仍然比數(shù)據(jù)流(streaming)要慢����。
請繼續(xù)往下閱讀����,以了解實現(xiàn)細節(jié)�����,性能以及功能的比較�。
一個有趣的問題
為了測試不同的框架,我們不會做“統(tǒng)計詞數(shù)”的實驗�,轉(zhuǎn)而去轉(zhuǎn)化谷歌圖書N-元數(shù)據(jù)��。 N-元代表一個n個詞構(gòu)成的元組����。這個n-元數(shù)據(jù)集提供了谷歌圖書文集中以年份分組的所有1-,2-��,3-�����,4-����,5-元記錄的統(tǒng)計數(shù)目����。 在這個n-元數(shù)據(jù)集中的每行記錄都由三個域構(gòu)成:n-元�����,年份��,觀測次數(shù)�����。(您能夠在http://books.google.com/ngrams取得數(shù)據(jù))��。
我們希望去匯總數(shù)據(jù)以觀測統(tǒng)計任何一對相互臨近的詞組合所出現(xiàn)的次數(shù)�����,并以年份分組���。實驗結(jié)果將使我們能夠判斷出是否有詞組合在某一年中比正常情況出現(xiàn)的更為頻繁��。如果統(tǒng)計時��,有兩個詞在四個詞的距離內(nèi)出現(xiàn)過�,那么我們定義兩個詞是“臨近”的。 或等價地��,如果兩個詞在2-�,3-或者5-元記錄中出現(xiàn)過,那么我們也定義它們是”臨近“的���。 一次����,實驗的最終產(chǎn)物會包含一個2-元記錄��,年份和統(tǒng)計次數(shù)�。
有一個微妙的地方必須強調(diào)���。n-元數(shù)據(jù)集中每個數(shù)據(jù)的值都是通過整個谷歌圖書語料庫來計算的����。從原理上來說�����,給定一個5-元數(shù)據(jù)集�����,我可以通過簡單地聚合正確的n-元來計算出4-元、3-元和2-元數(shù)據(jù)集��。例如�,當5-元數(shù)據(jù)集包含

時,我們可以將它聚合為2-元數(shù)據(jù)集以得出如下記錄

然而��,實際應(yīng)用中����,只有在整個語料庫中出現(xiàn)了40次以上的n元組才會被統(tǒng)計進來。所以����,如果某個5元組達不到40次的閾值,那么Google也提供組成這個5元組的2元組數(shù)據(jù)���,這其中有一些或許能夠達到閾值�。出于這個原因��,我們用相鄰詞的二元數(shù)據(jù)����,隔一個詞的三元組�,隔兩個詞的四元組�,以此類推。換句話說�����,與給定二元組相比����,三元組多的只是最外層的詞。除了對可能的稀疏n元數(shù)據(jù)更敏感���,只用n元組最外層的詞還有助于避免重復計算�����??偟膩碚f����,我們將在2元���、3元���、4元和5元數(shù)據(jù)集上進行計算�。
MapReduce的偽代碼來實現(xiàn)這個解決方案類似這樣:
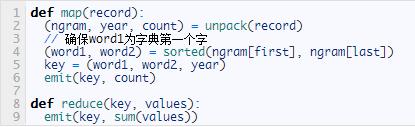
硬件
這些MapReduce組件在一個大約20GB的隨機數(shù)據(jù)子集上執(zhí)行�����。完整的數(shù)據(jù)集涵蓋1500個文件���;我們用這個腳本選取一個隨機子集�。文件名保持完整�����,這一點相當重要���,因為文件名確定了數(shù)據(jù)塊的n-元中n的值����。
Hadoop集群包含5個使用CentOS 6.2 x64的虛擬節(jié)點���,每個都有4個CPU��,10GB RAM��,100GB硬盤容量�����,并且運行CDH4���。集群每次能夠執(zhí)行20個并行運算����,每個組件能夠執(zhí)行10個減速器��。
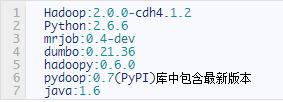
集群上運行的軟件版本如下:
實現(xiàn)
大多數(shù)Python框架都封裝了Hadoop Streaming��,還有一些封裝了Hadoop Pipes��,也有些是基于自己的實現(xiàn)�。下面我會分享一些我使用各種Python工具來寫Hadoop jobs的經(jīng)驗,并會附上一份性能和特點的比較�。我比較感興趣的特點是易于上手和運行,我不會去優(yōu)化某個單獨的軟件的性能����。
在處理每一個數(shù)據(jù)集的時候,都會有一些損壞的記錄�����。對于每一條記錄���,我們要檢查是否有錯并識別錯誤的種類����,包括缺少字段以及錯誤的N元大小�。對于后一種情況,我們必須知道記錄所在的文件名以便確定該有的N元大小�。
所有代碼可以從 GitHub 獲得。
Hadoop Streaming
Hadoop Streaming 提供了使用其他可執(zhí)行程序來作為Hadoop的mapper或者reduce的方式����,包括標準Unix工具和Python腳本。這個程序必須使用規(guī)定的語義從標準輸入讀取數(shù)據(jù)���,然后將結(jié)果輸出到標準輸出����。直接使用Streaming 的一個缺點是當reduce的輸入是按key分組的時候�����,仍然是一行行迭代的,必須由用戶來辨識key與key之間的界限��。
下面是mapper的代碼:
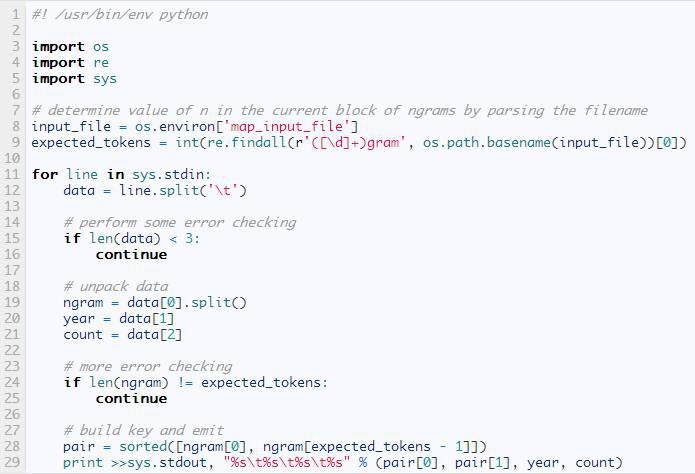
下面是reducer:
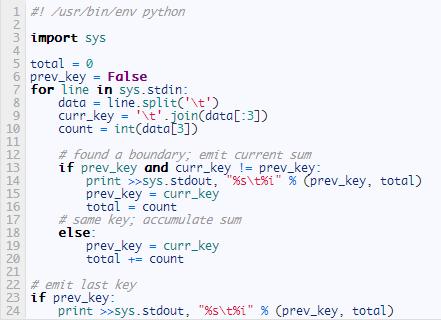
Hadoop流(Streaming)默認用一個tab字符分割健(key)和值(value)�����。因為我們也用tab字符分割了各個域(field)����,所以我們必須通過傳遞給Hadoop下面三個選項來告訴它我們數(shù)據(jù)的健(key)由前三個域構(gòu)成。

要執(zhí)行Hadoop任務(wù)命令
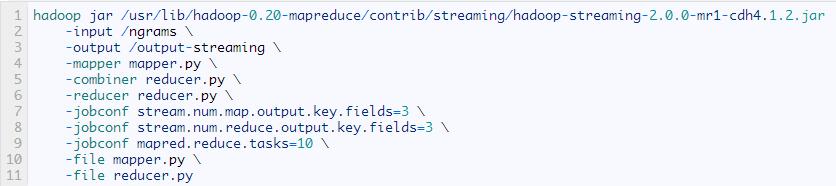
注意�����,mapper.py和reducer.py在命令中出現(xiàn)了兩次���,第一次是告訴Hadoop要執(zhí)行著兩個文件���,第二次是告訴Hadoop把這兩個文件分發(fā)給集群的所有節(jié)點。
Hadoop Streaming 的底層機制很簡單清晰�����。與此相反,Python以一種不透明的方式執(zhí)行他們自己的序列化/反序列化�����,而這要消耗更多的資源�。 而且����,如果Hadoop軟件已經(jīng)存在,Streaming就能運行�,而不需要再在上面配置其他的軟件。更不用說還能傳遞Unix 命令或者Java類名稱作 mappers/reducers了�����。
Streaming缺點是必須要手工操作��。用戶必須自己決定如何將對象轉(zhuǎn)化為為成鍵值對(比如JSON 對象)���。對于二進制數(shù)據(jù)的支持也不好��。而且如上面說過的�,必須在reducer手工監(jiān)控key的邊界����,這很容易出錯��。
mrjob
mrjob是一個開放源碼的Python框架����,封裝Hadoop的數(shù)據(jù)流���,并積極開發(fā)Yelp的����。由于Yelp的運作完全在亞馬遜網(wǎng)絡(luò)服務(wù)�,mrjob的整合與EMR是令人難以置信的光滑和容易(使用 boto包)。
mrjob提供了一個Python的API與Hadoop的數(shù)據(jù)流���,并允許用戶使用任何對象作為鍵和映射器����。默認情況下����,這些對象被序列化為JSON對象的內(nèi)部,但也有支持pickle的對象�。有沒有其他的二進制I / O格式的開箱即用�����,但有一個機制來實現(xiàn)自定義序列化����。
值得注意的是��,mrjob似乎發(fā)展的非?��?欤⒂泻芎玫奈臋n����。
所有的Python框架,看起來像偽代碼實現(xiàn):
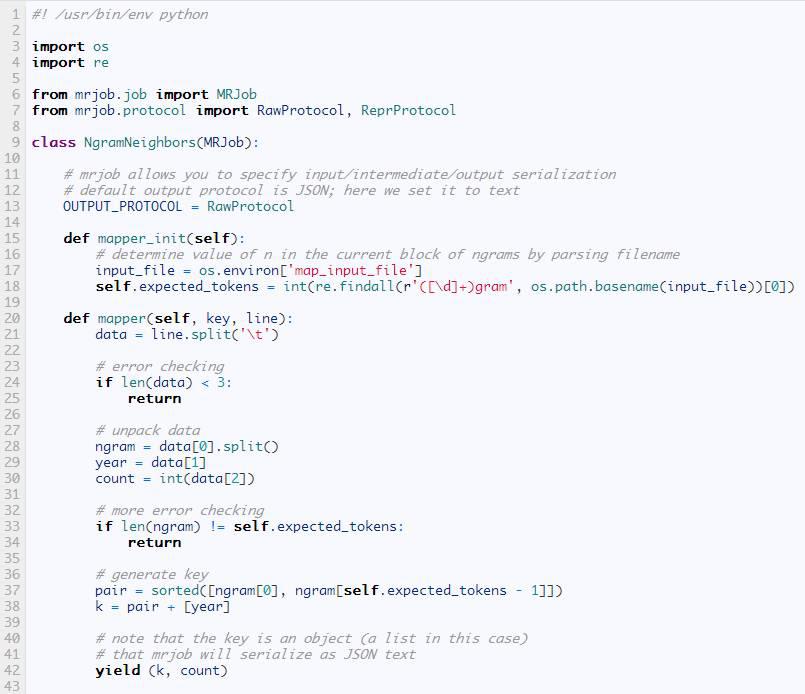
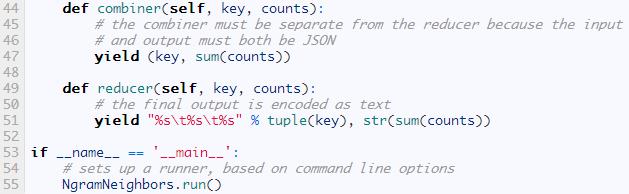
mrjob只需要安裝在客戶機上�����,其中在作業(yè)的時候提交�。下面是要運行的命令:

編寫MapReduce的工作是非常直觀和簡單的。然而�����,有一個重大的內(nèi)部序列化計劃所產(chǎn)生的成本。最有可能的二進制計劃將需要實現(xiàn)的用戶(例如�,為了支持typedbytes)。也有一些內(nèi)置的實用程序日志文件的解析����。最后,mrjob允許用戶寫多步驟的MapReduce的工作流程����,在那里從一個MapReduce作業(yè)的中間輸出被自動用作輸入到另一個MapReduce工作。
(注:其余的實現(xiàn)都非常相似����,除了包具體的實現(xiàn),他們都能被找到here.���。)
dumbo
dumbo 是另外一個使用Hadoop流包裝的框架�����。dumbo出現(xiàn)的較早�,本應(yīng)該被許多人使用�����,但由于缺少文檔,造成開發(fā)困難��。這也是不如mcjob的一點�����。
dumbo通過typedbytes執(zhí)行序列化���,能允許更簡潔的數(shù)據(jù)傳輸���,也可以更自然的通過指定JavaInputFormat讀取SequenceFiles或者其他格式的文件����,比如,dumbo也可以執(zhí)行Python的egg和Java的JAR文件���。
在我的印象中����, 我必須要手動安裝dumbo中的每一個節(jié)點����, 它只有在typedbytes和dumbo以eggs形式創(chuàng)建的時候才能運行�����。 就像他會因為onMemoryErrors終止一樣��,他也會因為使用組合器停止�。
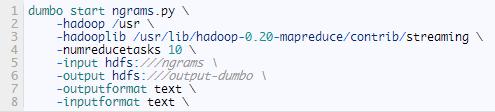
運行dumbo任務(wù)的代碼是:
hadoopy
hadoopy 是另外一個兼容dumbo的Streaming封裝����。同樣,它也使用typedbytes序列化數(shù)據(jù)����,并直接把 typedbytes 數(shù)據(jù)寫到HDFS。
它有一個很棒的調(diào)試機制�, 在這種機制下它可以直接把消息寫到標準輸出而不會干擾Streaming過程。它和dumbo很相似���,但文檔要好得多�����。文檔中還提供了與 Apache HBase整合的內(nèi)容�����。
用hadoopy的時候有兩種發(fā)發(fā)來啟動jobs:
launch 需要每個節(jié)點都已經(jīng)安裝了Python/hadoopy ��,但是在這之后的負載就小了���。
launch_frozen 不要求節(jié)點上已經(jīng)安裝了Python���,它會在運行的時候安裝,但這會帶來15秒左右的額外時間消耗(據(jù)說通過某些優(yōu)化和緩存技巧能夠縮短這個時間)���。
必須在Python程序中啟動hadoopy job�,它沒有內(nèi)置的命令行工具����。
我寫了一個腳本通過launch_frozen的方式啟動hadoopy
用launch_frozen運行之后����,我在每個節(jié)點上都安裝了hadoopy然后用launch方法又運行了一遍,性能明顯好得多��。
pydoop
與其他框架相比����,pydoop 封裝了Hadoop的管道(Pipes)���,這是Hadoop的C++ API。 正因為此����,該項目聲稱他們能夠提供更加豐富的Hadoop和HDFS接口,以及一樣好的性能��。我沒有驗證這個����。但是,有一個好處是可以用Python實現(xiàn)一個Partitioner�����,RecordReader以及RecordWriter���。所有的輸入輸出都必須是字符串�。
最重要的是��,我不能成功的從PIP或者源代碼構(gòu)建pydoop�。
其他
happy 是一個用Jython來寫Hadoop job的框架���,但是似乎已經(jīng)掛了
Disco 成熟的,非Hadoop 的 MapReduce.實現(xiàn)�,它的核心使用Erlang寫的,提供了Python的API�����,它由諾基亞開發(fā)�,不如Hadoop應(yīng)用廣泛。
octopy 是一個純Python的MapReduce實現(xiàn)��,它只有一個源文件�,并不適于“真正的”計算。
Mortar是另一個Python選擇���,它不久前才發(fā)布�����,用戶可以通過一個網(wǎng)頁應(yīng)用提交Apache Pig 或者 Python jobs 處理放置在 Amazon S3上的數(shù)據(jù)。
有一些更高層次的Hadoop生態(tài)體系中的接口����,像 Apache Hive和Pig���。Pig 可以讓用戶用Python來寫自定義的功能,是通過Jython來運行�����。 Hive 也有一個Python封裝叫做hipy
(Added Jan. 7 2013) Luigi 是一個用于管理多步作業(yè)流程的Python框架�����。它與Apache Oozie 有一點相似��,但是它內(nèi)置封裝了Hadoop Streaming(輕量級的封裝)�����。Luigi有一個非常好的功能是能夠在job出錯的時候拋出Python代碼的錯誤堆棧����,而且它的命令行界面也非常棒。它的README文件內(nèi)容很多����,但是卻缺少詳盡的參考文檔。Luigi 由Spotify 開發(fā)并在其內(nèi)部廣泛使用���。
本地java
最后��,我使用新的Hadoop Java API接口實施了MR任務(wù)�����,編譯完成后��,這樣來運行它:
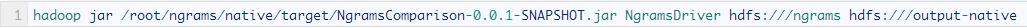
關(guān)于計數(shù)器的特別說明
在我的MR jobs的最初實現(xiàn)里����,我用計數(shù)器來跟蹤監(jiān)控不良記錄。在Streaming里��,需要把信息寫到stderr����。事實證明這會帶來不容忽視的額外開銷:Streaming job花的時間是原生java job的3.4倍。這個框架同樣有此問題�����。
將用Java實現(xiàn)的MapReduce job作為性能基準�����。 Python框架的值是其相對于Java的性能指標的比率�。
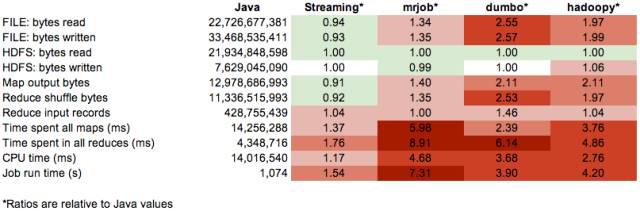
Java明顯最快,�,Streaming要多花一半時間,Python框架花的時間更多�。從mrjob mapper的profile數(shù)據(jù)來看,它在序列化/反序列化上花費了大量時間����。dumbo和hadoopy在這方面要好一點。如果用了combiner 的話dumbo 還可以更快��。
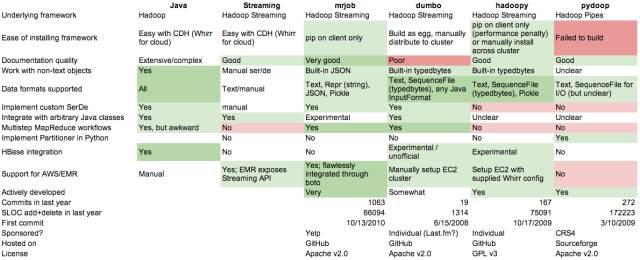
特點比較
大多來自各自軟件包中的文檔以及代碼庫����。
結(jié)論
Streaming是最快的Python方案,這面面沒有任何魔力�。但是在用它來實現(xiàn)reduce邏輯的時候,以及有很多復雜對象的時候要特別小心���。
所有的Python框架看起來都像是偽碼��,這非常棒��。
mrjob更新快�,成熟的易用,用它來組織多步MapReduce的工作流很容易����,還可以方便地使用復雜對象。它還可以無縫使用EMR���。但是它也是執(zhí)行速度最慢的�����。
還有一些不是很流行的 Python 框架����,他們的主要優(yōu)勢是內(nèi)置了對于二進制格式的支持��,但如果有必要話�����,這個完全可以由用戶代碼來自己實現(xiàn)����。
就目前來看:
Hadoop Streaming是一般情況下的最佳選擇,只要在使用reducer的時候多加小心,它還是很簡單易用的����。
從計算開銷方面考慮的話,選擇mrjob����,因為它與Amazon EMR結(jié)合最好����。
如果應(yīng)用比較復雜,包含了復合鍵����,要組合多步流程,dumbo 最合適��。它比Streaming慢��,但是比mrjob快���。
如果你在實踐中有自己的認識�,或是發(fā)現(xiàn)本文有錯誤�����,請在回復里提出。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330