數(shù)據(jù)分析師 之量化用戶研究
什么是用戶研究?
對于一個如此簡單的術(shù)語,“用戶研究”對于不同的人意義也是不同的�。對于用戶研究中的“用戶”�,Edward Tufte(Bisbort�����,1999)有一句名言:“只有兩個行業(yè)把他們的顧客稱作用戶:計算機設(shè)計(譯者注:computer design)以及販毒�。”
本書關(guān)注的是前者的用戶����。這里的用戶可以是一個付費顧客、內(nèi)部員工�、物理學家、呼叫中心處理員�、汽車司機、手機擁有者或是任何試圖去完成某個目標的人——尤其是那些涉及到軟件���、網(wǎng)站以及機器設(shè)備的目標���。
這里的“研究”寬泛而又模糊——它是以其為核心的方法和專業(yè)人員融匯的結(jié)果。Schumacher(2010,p.6)提出了以下的定義:
用戶研究是對于用戶目標��、需求和能力的系統(tǒng)研究���,它的目的是為了給設(shè)計��、架構(gòu)或改進工具來幫助用戶更好的工作和生活�。
相比起這個詞語的定義以及它包含的內(nèi)容�,我們更關(guān)心如何量化用戶的行為,因為這涉及到可用性相關(guān)專業(yè)人士��、設(shè)計師�����、產(chǎn)品經(jīng)理���、營銷人員以及開發(fā)者����。
用戶研究中的數(shù)據(jù)
盡管“用戶研究”這個說法最終可能會失寵����,但是它其中產(chǎn)出的數(shù)據(jù)卻不會。貫穿本書�����,我們將把重點放在可用性測試�����,使用一些來自可用性測試、用戶調(diào)查����、A/B測試以及實景調(diào)研的案例。之所以把重點放在可用性測試上�����,是有以下三點原因:
可用性測試依然是判別用戶是否在完成任務(wù)的核心方法���。
作者均執(zhí)行過大量的可用性測試并對其有著很多論述���。
可用性測試用到了許多其他用研方法所涉及到的指標。(比如到處都能看到的“完成率”)��。
可用性測試
可用性有一個國際標準:ISO 9241 pt.11(ISO,1998)���,其中把可用性定義為:在具體的使用場景下�����,一個產(chǎn)品能幫助具體用戶有效果��、有效率并滿意地達到一個具體目標的程度�����。盡管沒有方法來衡量效果����、效率以及滿意度���,一項09年針對將近100個總結(jié)性可用性測試的大型調(diào)查(Sauro和Lewis,2009)發(fā)現(xiàn)了執(zhí)行測試的人一般能收集到的內(nèi)容����。大部分的測試包含了一些組合����,這些組合包括:完成率、錯誤����、任務(wù)時間、任務(wù)級別滿意度(譯者注:task-level satisfaction)���、測試級別滿意度(譯者注:test-level satisfaction)�����、幫助途徑以及可用性問題列表(一般包含頻率和程度)���。
總體上來說�,有兩種可用性測試:找到并解決可用性問題(形成性測試)(譯者注:formative tests)和用指標描述一個應(yīng)用的可用性(總結(jié)性測試)(譯者注:summative tests)�����。這里的“形成性測試”和“總結(jié)性測試”兩個術(shù)語來自教育界(Scriven,1967)用于描述學生學習水平測試時用到的類似方式(“形成性”——提供即時的反饋來改進學習方式以及“總結(jié)性”——評估學到的內(nèi)容)��。
大多數(shù)的可用性測試屬于總結(jié)性的���。它們通常是一個小樣本量的定性活動���,在其中問題描述以及設(shè)計建議是以數(shù)據(jù)的形式輸出的。你的目標是發(fā)現(xiàn)盡可能多的問題并找到解決方案��,但是這并不意味著沒有定量什么事����。你可以從頻率、程度的角度量化問題,追蹤哪些用戶碰到了哪些問題�����,衡量一下他們完成任務(wù)花費的時間��,判斷一下他們是否成功的完成了任務(wù)����。
通常來講有兩種典型的總結(jié)性測試:基準測試以及比較測試?����;鶞士捎眯詼y試的目標是描述一個應(yīng)用相對于一系列基準來說的可用程度���。在基準測試里你可以提出一個界面中需要修復(fù)的問題并且它也提供了用于比較設(shè)計后改變的一條基線。
比較可用性測試�,就像他的名字一樣,這可以是比較同一個產(chǎn)品的不同版本�,也可以是比較幾個競品。在比較測試中�����,同一個用戶可以在所有的產(chǎn)品上嘗試完成任務(wù)(主題下的設(shè)計),或者不同組的用戶可以試驗各個產(chǎn)品(主題間的設(shè)計)��。
樣本量
對于樣本量有一種錯誤的觀點認為必須越大越好����,這樣才可以讓數(shù)據(jù)精確可使用并量化成可用數(shù)據(jù)。我們將在第6.7章中深入探討這個問題�,并且在本書中,我們都將展現(xiàn)給你如何在樣本量小于10的情況下獲得有效的數(shù)據(jù)結(jié)果��。不要讓你的樣本量(哪怕你只有2到5個用戶)阻礙你使用統(tǒng)計信息來量化數(shù)據(jù)并指導(dǎo)最終的設(shè)計方案�����。
代表性和隨機性
和樣本量能夠扯上些關(guān)系應(yīng)該算是樣本的構(gòu)成���。對于一個小樣本經(jīng)常會有人擔心它不夠有代表性����。樣本量以及代表性其實是不同的概念�。你可以建立一個數(shù)量只有5但是能夠代表人群的樣本,你也可以建立一個樣本量高達1000但是并沒有什么代表性的樣本�����。有關(guān)這兩個不同概念最著名的例子之一便是1936年《文學文摘》(譯者注:Literary Digesst)做的關(guān)于總統(tǒng)候選人民意調(diào)查。這本雜志調(diào)查自己的讀者傾向于投票給哪位候選人并收到了240萬份結(jié)果�����,但是最后卻預(yù)測錯了大選結(jié)果����。這里面問題不在于樣本的大小而在于樣本的代表性。而《文學文摘》收到回復(fù)的人群大多是高收入高學歷人群——顯然并不能夠代表所有人��。(詳見wiki)
在用戶研究中�,無論數(shù)據(jù)是定量的還是定性的,最重要的一件事在于你測試的用戶樣本能夠代表你所要針對的所有人��。否則你的調(diào)研結(jié)果從邏輯上就不適用于你的目標人群���。如果你用一個群體的樣本來推斷另一個不同的群體,那么再好的統(tǒng)計學都幫不上忙�。如果你想要深入了解如何改進雪地鞋的設(shè)計,去調(diào)研5個極地探險者都要比調(diào)研1000個沖浪者來的好���。在實踐中�,這就意味著如果你試圖從不同的用戶群里得出結(jié)論(比如���,新用戶和經(jīng)驗用戶�,或年長用戶和年輕用戶),你就該讓樣本很好的代表不同的用戶群��。
關(guān)于樣本量和代表性存在困擾的一個原因在于����,你的人群,比如說是由10個不同的組構(gòu)成��,而你的樣本量是5��,那么顯然樣本量不夠來代表所有的組別��。你就需要針對這制定合適的取樣方法來保證從每個需要調(diào)研的組別中都取得樣本——這個方法又叫“分層取樣”(譯者注:Stratified Sampling)�。比如說,如果你有理由相信以下幾點��,則考慮從不同組取樣:
在關(guān)鍵指標上不同組別之間有潛在的重要差別�。(Dickens,1987)
組與組之間存在潛在交流�����。(Aykin and Aykin��,1991)
在關(guān)鍵指標的變動性上,組與組之間不同����。
不同組之間取樣成本不一樣。
Gordon和Langmaid推薦用一下方法來定義一個組(1988):
寫下所有重要的變量���。
如果需要的話�,按優(yōu)先級對變量排序�。
設(shè)計一個理想的樣本。
利用常識來合并組����。
舉例來說,假設(shè)你一開始有24個組�,這些組都是基于6個人口統(tǒng)計地點、2種經(jīng)歷����、2種性別的組合。你可能規(guī)劃著(1)每組中都包含同樣數(shù)量的40歲以上和以下的男性女性��,(2)初學用戶和經(jīng)驗用戶分開�����,然后(3)棄用中間的那些用戶��。最后的規(guī)劃需要從2個組里取樣��。而沒有合并性別和年齡的規(guī)劃則需要從8個組里取樣��。
我們理想的假設(shè)你的樣本是從母人群中隨機挑選的?�,F(xiàn)實中這一點十分困難��。除非你強迫用戶去參與調(diào)查��,否則多多少少不會完全隨機��。在可用性研究和調(diào)查中�,如果人們決定參與,那么這一組里可以有不同的特點��,而如果人們不選擇參與則反之���。這個問題不僅僅存在在用戶研究中�。即便在要對藥物以及醫(yī)療程序作出生與死的決定的臨床測試里�,人們又不得不參與或者有某種疾病(癌癥或糖尿病)的時候,也有這樣的情況����。許多心理學課本里關(guān)于人們行為的準則居然是被一些大學本科生得出的——這是一個潛在的代表性以及隨機性問題�����。
你必須要意識到你的數(shù)據(jù)依舊是存在偏差的���,這也將制約到你的結(jié)論。在應(yīng)用研究中���,我們被預(yù)算以及用戶參與度所拘束���,可是產(chǎn)品依然必須要產(chǎn)出。所以���,在我們能收集到的數(shù)據(jù)的基礎(chǔ)之上����,我們盡量做出最正確的判斷���。在盡力讓樣本中的系統(tǒng)偏差最小化的同時要記住���,代表性比隨機性更加重要。換句話說��,哪怕你有一個非常完美的隨機樣本�����,但是它選取自錯誤的人群����,那么這個樣本也比不上選取自正確人群但不完美的樣本。
數(shù)據(jù)收集
可用性數(shù)據(jù)可以在一個傳統(tǒng)基于實驗室的有主持過程里被收集��,這個過程中,用戶去完成任務(wù),而一個主持人將觀察并與他們互動�����。這樣的測試過程無疑耗時耗力��,并且還需要具備用戶和觀察人兩個角色(這也阻礙其進行一些跨國的測試)���。這樣的研究一般運用小樣本的統(tǒng)計學過程,因為每一個樣本的成本實在太高了����。
近些年來�,遠程主持以及無主持的過程越來越受歡迎��。在遠程主持的過程中�����,用戶在自己的電腦上嘗試完成任務(wù)����,而主持人通過屏幕共享軟件來觀察并記錄用戶的行為。而在無主持的遠程測試過程中�����,用戶嘗試任務(wù)(通常是在網(wǎng)站上)����,而軟件記錄下點擊,頁面瀏覽以及時間���。對于遠程測試的辦法����,讀者可參閱《Beyond the Usability Lab》(Albert et al.,2010),里面有深入的討論����。
根據(jù)我們的經(jīng)驗,盡管量化人類行為動機是十分困難的��,這些行為的結(jié)果卻是易于觀察�����、衡量并利用的����。以下就是在用戶研究里���,可用性測試內(nèi)外能收集到的一些常見指標描述��。我們會在本書里不斷用到這些術(shù)語���。
完成率
完成率,也被稱為成功率����,是可用性指標里最為基本的。(Nielsen,2001)�����。他們一般都記錄成二進制的數(shù)據(jù):1代表任務(wù)成功����,0代表任務(wù)失敗。你所報告的成功率就是將那些成功完成任務(wù)的用戶數(shù)量除以所以嘗試任務(wù)的用戶數(shù)量����。舉例來說,如果10個用戶里有8個成功完成了任務(wù)�����,那么成功率就是0.8�,通常報告里寫成80%。你也可以用用100%減去成功率而記錄失敗率為20%�����。
當然��,也有辦法來定義一種表示部分成功的指標���,但是我們更加推崇這種簡單的二進制衡量方式��,因為它更加利于之后的統(tǒng)計分析��。本書里提到的成功率都是指這種二進制的成功率�����。
二進制統(tǒng)計的另一個好處在于它在科學以及統(tǒng)計學文獻里無處不在��。本質(zhì)上來說�,任何事物的出現(xiàn)和未出現(xiàn)都可以記錄成1或者0����,然后可以匯總成一定的比率。這個可以是在一個軟件上完成任務(wù)的用戶數(shù)量���,或是從疾病中恢復(fù)的病人數(shù)目�����,又或是湖里補上來的魚的數(shù)量�����,以及購買一個產(chǎn)品的顧客數(shù)量等等等等��,它們都適用于二進制比率�。
可用性問題
如果用戶在完成任務(wù)的時候遇到了問題,而這個問題又和界面有關(guān)系�����。那這就是一個用戶界面問題(UI問題)���。UI問題的匯總通常以列表的形式出現(xiàn)��。這個列表包含了問題名稱����、描述以及一個用來反映問題出現(xiàn)頻率和對用戶影響的級別評分�。
計算問題出現(xiàn)頻率的常用方法是把所有參與者遇到的問題數(shù)量除以參與者的數(shù)量。而評估問題影響程度常用的辦法(Rubin,1994;Dumas and Redish,1999)則是為這個影響的程度打分��,其參考以下標準:
這個問題是否導(dǎo)致任務(wù)無法完成;
這個問題是否導(dǎo)致完成的延遲或讓用戶遇到阻礙;
這個問題對于整個任務(wù)表現(xiàn)影響相對比較小;
這個問題有待繼續(xù)觀察���。
當你在處理數(shù)據(jù)時�����,如果這些數(shù)據(jù)是多類別的����,且有著一定的層次順序,那么就很有必要用某種方式合并一下這些數(shù)據(jù)���。一種方法便是用某種算法作為依據(jù)���。Rubin(1994)描述了一種將影響的四個級別(利用上面介紹到的4個級別,4表示最嚴重)和問題出現(xiàn)頻率的四個級別(4:大于等于90%;3::51-89%;2:11-50%;1:小于等于10%)通過分數(shù)疊加合并的辦法�����。舉例來說����,如果一個問題被監(jiān)測到有80%的出現(xiàn)頻率�,但相對來說影響較小,那么它的級別評分就是5(頻率3分加上影響2分)��。通過這種方法���,級別評分可以從最小2分到最大8分之間浮動�����。
還有一個類似的合并策略是將監(jiān)測到的出現(xiàn)頻率百分比乘上影響分(Lewis,2012)�����。得到的級別評分范圍取決于每個影響級別被賦予的值���。如果你把最嚴重的影響級別定義為10分�,那么最高級得分就是1000(也可以在這個基礎(chǔ)上除以10����,這樣得出的結(jié)果就在1到100的范圍內(nèi),便于分析)�。剩余三個影響級別的值取決于測試方的判斷,但一個合理的組合一般是5,3和1分��。利用這些值����,一個出現(xiàn)頻率為80%、有著較小影響的問題的級別得分是24(80乘以3除以10).
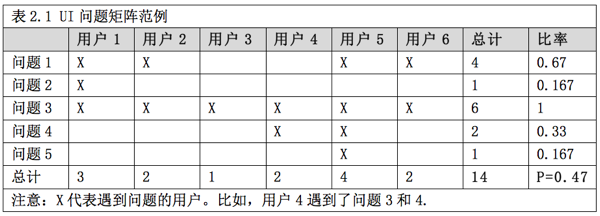
從分析的角度考慮���,把UI問題和遇到問題的用戶聯(lián)系起來是組織這些問題的好辦法����,就像表2.1那樣。
你要去了解在不同的測試階段用戶遇到一個問題的幾率是多大��。這能成為衡量可用性活動的影響以及ROI的關(guān)鍵指標�。而了解哪個用戶遇到哪個問題則能讓你更好的估量你的樣本量、問題發(fā)現(xiàn)率以及未發(fā)現(xiàn)問題的數(shù)量��。
 任務(wù)時間
任務(wù)時間
任務(wù)時間的意思是一個用戶在一個活動中花了多久的時間���。更詳細的說���,它就是用戶成功完成一個事先定義好的任務(wù)場景所花的時間,但它也可以是在網(wǎng)頁上呆的時間或電話時長���。它可以用毫秒、秒����、分鐘、小時�����、天或年來衡量,并且通常都是以平均數(shù)的方式來寫進報告(第三章有詳細描述)��。衡量并分析任務(wù)耗時有以下一些方法:
任務(wù)完成時間:成功完成任務(wù)的用戶花費的時間�����。
任務(wù)失敗時間:用戶參與任務(wù)直到放棄或者錯誤的完成所花費的時間���。
任務(wù)總時間:用戶在任務(wù)上花費的所有時間����。
錯誤
錯誤就是用戶在試著完成任務(wù)的過程中任何意外的行為����,小錯、誤解或遺漏����。錯誤數(shù)目的統(tǒng)計可以從0(沒有錯誤)到理論上無窮(雖然一般來說在可用性測試的一個任務(wù)里很少會出現(xiàn)超過20個的錯誤)。錯誤能夠提供非常有用的診斷信息�����,這些信息有關(guān)用戶為什么失敗以及映射到UI問題里可能出現(xiàn)錯誤的地方。當然����,錯誤也可以用二進制方式來衡量統(tǒng)計:用戶或是遇到了錯誤(1=yes),或是沒有(0=no)��。
滿意程度
在任務(wù)之后����、可用性測試最后階段或獨立于可用性測試之外的時間里,可以提供有關(guān)系統(tǒng)易用性看法的問卷���,完成這些問卷不會花費什么時間���。雖然說你可以用自己編寫的問題來評估對于易用性的感知,但如果你使用現(xiàn)有的標準化問卷���,你的結(jié)論將會更加可靠(Sauro 和 Lewis��,2009)����。我們將在第八章里詳細探討標準化可用性測試問卷��。
合并的分數(shù)
雖然可用性指標都互相緊密相關(guān)(Sauro 和 Lewis�����,2009)����,但是這個緊密的關(guān)系還不至于到它們相互能夠替換對方?��?偟膩碚f�����,那些完成了更多任務(wù)的用戶更趨向于把任務(wù)評價的更簡單并且完成的也更快�。然后有些用戶雖說沒有成功完成任務(wù)�,依然把任務(wù)評價的簡單;或是有些完成任務(wù)很快的用戶,卻覺得任務(wù)比較困難�����。在可用性測試里手機多種指標數(shù)據(jù)是有益的�,因為沒有任何單一的數(shù)據(jù)能夠像這一樣真實的反映整體的用戶體驗。然而�,分析報告這些數(shù)據(jù)將會是困難的,所以說如果將數(shù)據(jù)合并到一起,處理起來將會方便許多��。一個合并的可用性指標和其他任何單一的指標一樣��,并且可以更好地用作執(zhí)行面板(譯者注:executive dashboards)的組成部分�,或是用來判定產(chǎn)品之間的統(tǒng)計顯著性(詳見第五章)。如果你想了解更多關(guān)于合并多個指標為一個單一分數(shù)的內(nèi)容��,可以參閱Sauro and Kindlund(2005),Sauro and Lewis(2009),以及第九章中”Can You Combine Usability Metrics into Single Scores?”部分���。
A/B測試
A/B測試�,也叫做分半測試(譯者注:split-half testing),是一種受歡迎的對比網(wǎng)頁設(shè)計方案的方法��。在這類由Amazon普及的測試里���,用戶隨機的用兩種開發(fā)好的設(shè)計備選方案進行操作�����。而兩個方案設(shè)計上的區(qū)別可能像按鈕上不同的文字或產(chǎn)品的不同圖片一樣微妙�����,也可能是采用了完全不同的頁面布局和產(chǎn)品信息��。
點擊���、頁面瀏覽以及轉(zhuǎn)化率
對于網(wǎng)站和網(wǎng)頁應(yīng)用來說,標準的行為便是自動記錄其中的點擊數(shù)和頁面瀏覽量�。而且在大部分情況下,如果你自己沒有做研究的話��,這些是你能獲得的唯一數(shù)據(jù)�����。這倆個數(shù)據(jù)對于計算轉(zhuǎn)化率����、購買率或特色用法(譯者注:feature usage)都很有幫助,并且在A/B測試中被廣泛使用�����,尤其是像來分析完成率這樣的工作�。
為了檢驗到底哪個設(shè)計更好,你記錄下每個設(shè)計參與的用戶數(shù)量以及最后點擊的用戶數(shù)量��。比如����,如果有1000個用戶參與了設(shè)計方案A��,其中20個點擊了“注冊”;同時1050個用戶在設(shè)計方案B中進行操作�,48個用戶點擊了“注冊”�,那么轉(zhuǎn)化率就分別是2%和4.5%�。我們會在第五章里深入學習如何來判斷設(shè)計方案之間是否有統(tǒng)計差異�。
調(diào)研數(shù)據(jù)
調(diào)研是收集來自顧客相關(guān)態(tài)度看法的最簡單方法��。通常來說����,調(diào)研包含了一些開放性的評價和是/否的回答���,以及Likert式的評級量表數(shù)據(jù)���。。
評級量表
評級量表里項目的特點是封閉式的回答選項�。調(diào)查對象比較典型地會被要求對一個陳述發(fā)表同意還是不同意的看法(通常被稱為Likert式項目)����。為了方便數(shù)值分析,Likert經(jīng)典的5選項回答能夠被轉(zhuǎn)化成1到5的數(shù)字(見表2.2)����。
一旦你把這些回答的選擇轉(zhuǎn)化成了數(shù)字,你就可以計算出平均值和標準偏差����,并生成可靠區(qū)間(見第三章),或是用這些回答來和不同的產(chǎn)品進行比較(見第五章)���。第八章會細致的探討具體到可用性層面的問卷以及評級量表�����。用這類數(shù)據(jù)可以計算平均值以以及進行標準統(tǒng)計測試�,對此,人們有著一定的爭議�����,第九章中“把來自不同陳述及不同級別的回答數(shù)據(jù)平均在一起是否合適?”這部分內(nèi)容就會對此進行討論�����。

凈推薦值(譯者注:Net Promoter Scores)
有關(guān)用戶忠誠度以及未來購買行為的問題由來已久�,許多公司在可用性測試中紛紛采用了一種最近出現(xiàn)的創(chuàng)新方法——凈推薦問題以及得分(Reichheld,2003�����,2006)����。著名的凈推薦值(NPS)方法建立在一個有關(guān)顧客忠誠度的問題之上:有多大可能你會把這件產(chǎn)品推薦給你的朋友或者同事?回答的選項從0到10并分成以下三個維度:
推廣者:9到10
被動者:7到8
批評者:0到6
把推廣者回答的比重減去批評者回答的比重就得到了凈推薦值。這個數(shù)值從-100%到100%的范圍內(nèi)浮動�,數(shù)值越高意味著更高的忠誠度得分(推廣者比批評者多)。雖然也有其他的評分評級方式可以分析有關(guān)方面(比如說平均值和標準偏差)����,但是凈推薦值這樣分段式的算分方式在統(tǒng)計處理上有著細微的區(qū)別(見第五章)。
注:Net Promoter(凈推薦)����、NPS(凈推薦值)以及Net Promoter Score(凈推薦值)系Satmetrix Systems,Inc., Bain&Company 和 Fred Reichheld的注冊商標���。
評價以及開放式數(shù)據(jù)
分析并為評價分級對于一個用研來說是最基本的任務(wù)。開放式的評價可能是各種形式的����,例如:
顧客推廣或批評一個產(chǎn)品的理由。
現(xiàn)場調(diào)查時用戶的需求��。
客服電話里對于產(chǎn)品的抱怨����。
為何完成某個任務(wù)很困難�����。
就像可用性問題可以數(shù)量化一樣�����,用戶評價以及大部分開放式數(shù)據(jù)都可以被分類����、量化并提交到統(tǒng)計分析中(Sauro�,2011)���。你可以進一步進行分析�����,并生成可靠區(qū)間�,了解所有用戶中有多大比重的人可能有這樣的感覺(見第三章)�����。
需求的收集
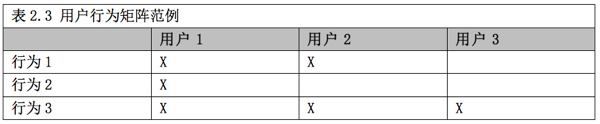
用戶研究另外一個關(guān)鍵功能便是發(fā)現(xiàn)一個產(chǎn)品的特點以及功能��?����?赡苓@和直接向用戶詢問他們要什么相比難多了���,但是我們有許多辦法來分析那些能夠透露出未滿足需求的用戶行為。就像表2.3那樣�����,這些行為可以在家里或辦公地點被監(jiān)測����,然后像量化UI問題那樣被量化。每一個行為將獲得一個稱呼和描述���,然后你在下面的表格里記錄下哪一個用戶做出了某個特定的行為�����,就像表格里展示的那樣。
你可以很方便的在報告里記錄做出某個行為的用戶比例,在這個比例附近生成可靠區(qū)間��,就像在統(tǒng)計完成率時做的那樣(見第三章)���。你也可以把需求發(fā)現(xiàn)的統(tǒng)計學模型應(yīng)用到預(yù)估樣本量����、需求發(fā)現(xiàn)率以及未發(fā)現(xiàn)需求數(shù)的工作中(見第七章)�����。
本章關(guān)鍵信息點
用戶研究是一個寬泛的術(shù)語����,它包含了能夠生成量化結(jié)果的多種方法論,包括可用性測試、調(diào)研����、問卷和現(xiàn)場調(diào)查等。
可用性測試是用戶研究中最為中心的一種工作���。通常生成例如完成率�、任務(wù)時間��、錯誤統(tǒng)計�����、滿意度數(shù)據(jù)和用戶界面問題這樣的指標��。
二進制完成率既是一種基本的可用性指標�����,也是科學研究的各個領(lǐng)域都能適用的指標��。
你可以量化小樣本里的數(shù)據(jù)并利用統(tǒng)計學來得出一定的結(jié)論�。
即便是開放式的評論和描述也可以被分類并量化�����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認證考試,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330