數(shù)據(jù)分析系列篇:數(shù)據(jù)分析方法論
掌握了excel��、spss、sas���、r這些分析工具之后����,我們來了解下數(shù)據(jù)分析的基本方法論���,其實數(shù)據(jù)分析方法不復(fù)雜,我們需要把一些核心的分析方法掌握了活學(xué)活用�����。
重點包括兩塊����,一塊是統(tǒng)計分析方法論:描述統(tǒng)計、假設(shè)檢驗��、相關(guān)分析����、方差分析��、回歸分析���、聚類分析、判別分析���、主成分與因子分析��、時間序列分析����、決策樹等��;
一塊是營銷管理常用分析方法論:SWOT�、4P、PEST��、SMART���、5W2H��、User behavior等���。
一�、統(tǒng)計分析方法論:
1.描述統(tǒng)計(Descriptive statistics):描述統(tǒng)計是通過圖表或數(shù)學(xué)方法���,對數(shù)據(jù)資料進行整理、分析��,并對數(shù)據(jù)的分布狀態(tài)�����、數(shù)字特征和隨機變量之間關(guān)系進行估計和描述的方法��。目的是描述數(shù)據(jù)特征�����,找出數(shù)據(jù)的基本規(guī)律���。描述統(tǒng)計分為集中趨勢分析和離中趨勢分析和相關(guān)分析三大部分��。
(1)數(shù)據(jù)的頻數(shù)分析:在數(shù)據(jù)的預(yù)處理部分�,我們曾經(jīng)提到利用頻數(shù)分析和交叉頻數(shù)分析來檢驗異常值�。此外,頻數(shù)分析也可以發(fā)現(xiàn)一些統(tǒng)計規(guī)律�����。比如說,收入低的被調(diào)查者用戶滿意度比收入高的被調(diào)查者高����,或者女性的用戶滿意度比男性低等。不過這些規(guī)律只是表面的特征���,在后面的分析中還要經(jīng)過檢驗�。
(2)數(shù)據(jù)的集中趨勢分析:數(shù)據(jù)的集中趨勢分析是用來反映數(shù)據(jù)的一般水平�,常用的指標有平均值、中位數(shù)和眾數(shù)等����。各指標的具體意義如下:
平均值:是衡量數(shù)據(jù)的中心位置的重要指標,反映了一些數(shù)據(jù)必然性的特點�����,包括算術(shù)平均值��、加權(quán)算術(shù)平均值�����、調(diào)和平均值和幾何平均值。
中位數(shù):是另外一種反映數(shù)據(jù)的中心位置的指標�,其確定方法是將所有數(shù)據(jù)以由小到大的順序排列,位于中央的數(shù)據(jù)值就是中位數(shù)�����。
眾數(shù):是指在數(shù)據(jù)中發(fā)生頻率最高的數(shù)據(jù)值����。
如果各個數(shù)據(jù)之間的差異程度較小��,用平均值就有較好的代表性���;而如果數(shù)據(jù)之間的差異程度較大���,特別是有個別的極端值的情況,用中位數(shù)或眾數(shù)有較好的代表性����。
(3)數(shù)據(jù)的離散程度分析:數(shù)據(jù)的離散程度分析主要是用來反映數(shù)據(jù)之間的差異程度,常用的指標有方差和標準差����。方差是標準差的平方�����,根據(jù)不同的數(shù)據(jù)類型有不同的計算方法�。
(4)數(shù)據(jù)的分布:在統(tǒng)計分析中�����,通常要假設(shè)樣本的分布屬于正態(tài)分布��,數(shù)據(jù)的正態(tài)性離群值檢驗���,已知標準差Nair檢驗����,未知標準差時�,有Grubbs檢驗,Dixon檢驗���,偏度-峰度法等�����。其中常用偏度-峰度法需要用偏度和峰度兩個指標來檢查樣本是否符合正態(tài)分布����。偏度衡量的是樣本分布的偏斜方向和程度;而峰度衡量的是樣本分布曲線的尖峰程度�。一般情況下,如果樣本的偏度接近于0�,而峰度接近于3,就可以判斷總體的分布接近于正態(tài)分布�。
(5)繪制統(tǒng)計圖:用圖形的形式來表達數(shù)據(jù),比用文字表達更清晰����、更簡明��。在SPSS軟件里����,可以很容易的繪制各個變量的統(tǒng)計圖形,包括條形圖���、餅圖和折線圖等���。
2.假設(shè)檢驗:是數(shù)理統(tǒng)計學(xué)中根據(jù)一定假設(shè)條件由樣本推斷總體的一種方法。具體作法是:根據(jù)問題的需要對所研究的總體作某種假設(shè),記作H0���;選取合適的統(tǒng)計量���,這個統(tǒng)計量的選取要使得在假設(shè)H0成立時,其分布為已知�;由實測的樣本,計算出統(tǒng)計量的值���,并根據(jù)預(yù)先給定的顯著性水平進行檢驗�����,作出拒絕或接受假設(shè)H0的判斷����。常用的假設(shè)檢驗方法有u—檢驗法�����、t檢驗法��、χ2檢驗法(卡方檢驗)����、F—檢驗法�,秩和檢驗等�。
3.相關(guān)分析:相關(guān)分析是研究現(xiàn)象之間是否存在某種依存關(guān)系,并對具體有依存關(guān)系的現(xiàn)象探討其相關(guān)方向以及相關(guān)程度�,是研究隨機變量之間的相關(guān)關(guān)系的一種統(tǒng)計方法。常見的有線性相關(guān)分析��、偏相關(guān)分析和距離分析�。相關(guān)分析與回歸分析在實際應(yīng)用中有密切關(guān)系。然而在回歸分析中�,所關(guān)心的是一個隨機變量Y對另一個(或一組)隨機變量X的依賴關(guān)系的函數(shù)形式。而在相關(guān)分析中 �,所討論的變量的地位一樣,分析側(cè)重于隨機變量之間的種種相關(guān)特征�����。例如�����,以X�、Y分別記小學(xué)生的數(shù)學(xué)與語文成績�,感興趣的是二者的關(guān)系如何���,而不在于由X去預(yù)測Y。
4.方差分析(Analysis of Variance��,簡稱ANOVA):又稱“變異數(shù)分析”或“F檢驗”�,是R.A.Fisher發(fā)明的,用于兩個及兩個以上樣本均數(shù)差別的顯著性檢驗���。 由于各種因素的影響�����,研究所得的數(shù)據(jù)呈現(xiàn)波動狀����。造成波動的原因可分成兩類��,一是不可控的隨機因素��,另一是研究中施加的對結(jié)果形成影響的可控因素����。
方差分析是從觀測變量的方差入手,研究諸多控制變量中哪些變量是對觀測變量有顯著影響的變量����。
5.回歸分析:回歸主要的種類有:線性回歸�����,曲線回歸�,二元logistic回歸�,多元logistic回歸?���;貧w分析的應(yīng)用是非常廣泛的,統(tǒng)計軟件包使各種回歸方法計算十分方便�����。
一般來說�����,回歸分析是通過規(guī)定因變量和自變量來確定變量之間的因果關(guān)系�����,建立回歸模型�,并根據(jù)實測數(shù)據(jù)來求解模型的各個參數(shù),然后評價回歸模型是否能夠很好的擬合實測數(shù)據(jù)��;如果能夠很好的擬合�����,則可以根據(jù)自變量作進一步預(yù)測����。
6.聚類分析:聚類主要解決的是在“物以類聚、人以群分”����,比如以收入分群,高富帥VS矮丑窮��;比如按職場分群���,職場精英VS職場小白等等����。
聚類的方法層出不窮�,基于用戶間彼此距離的長短來對用戶進行聚類劃分的方法依然是當前最流行的方法。大致的思路是這樣的:首先確定選擇哪些指標對用戶進行聚類��;然后在選擇的指標上計算用戶彼此間的距離,距離的計算公式很多��,最常用的就是直線距離(把選擇的指標當作維度��、用戶在每個指標下都有相應(yīng)的取值����,可以看作多維空間中的一個點,用戶彼此間的距離就可理解為兩者之間的直線距離���。)��;最后聚類方法把彼此距離比較短的用戶聚為一類�,類與類之間的距離相對比較長����。
常用的算法k-means、分層�、FCM等。
7.判別分析:從已知的各種分類情況中總結(jié)規(guī)律(訓(xùn)練出判別函數(shù))���,當新樣品進入時����,判斷其與判別函數(shù)之間的相似程度(概率最大���,距離最近��,離差最小等判別準則)��。
常用判別方法:最大似然法�,距離判別法����,F(xiàn)isher判別法,Bayes判別法�����,逐步判別法等���。
注意事項:
a. 判別分析的基本條件:分組類型在兩組以上�����,解釋變量必須是可測的��;
b. 每個解釋變量不能是其它解釋變量的線性組合(比如出現(xiàn)多重共線性情況時����,判別權(quán)重會出現(xiàn)問題);
c. 各解釋變量之間服從多元正態(tài)分布(不符合時����,可使用Logistic回歸替代),且各組解釋變量的協(xié)方差矩陣相等(各組協(xié)方方差矩陣有顯著差異時�����,判別函數(shù)不相同)�。
相對而言,即使判別函數(shù)違反上述適用條件�����,也很穩(wěn)健����,對結(jié)果影響不大。
應(yīng)用領(lǐng)域:對客戶進行信用預(yù)測�,尋找潛在客戶(是否為消費者,公司是否成功��,學(xué)生是否被錄用等等),臨床上用于鑒別診斷���。
8.主成分與因子分析:主成分分析基本原理:利用降維(線性變換)的思想���,在損失很少信息的前提下把多個指標轉(zhuǎn)化為幾個綜合指標(主成分),即每個主成分都是原始變量的線性組合,且各個主成分之間互不相關(guān),使得主成分比原始變量具有某些更優(yōu)越的性能(主成分必須保留原始變量90%以上的信息)�,從而達到簡化系統(tǒng)結(jié)構(gòu),抓住問題實質(zhì)的目的�。
因子分析基本原理:利用降維的思想,由研究原始變量相關(guān)矩陣內(nèi)部的依賴關(guān)系出發(fā)��,將變量表示成為各因子的線性組合����,從而把一些具有錯綜復(fù)雜關(guān)系的變量歸結(jié)為少數(shù)幾個綜合因子。(因子分析是主成分的推廣����,相對于主成分分析,更傾向于描述原始變量之間的相關(guān)關(guān)系)�����。
9.時間序列分析:經(jīng)典的統(tǒng)計分析都假定數(shù)據(jù)序列具有獨立性��,而時間序列分析則側(cè)重研究數(shù)據(jù)序列的互相依賴關(guān)系。后者實際上是對離散指標的隨機過程的統(tǒng)計分析���,所以又可看作是隨機過程統(tǒng)計的一個組成部分����。例如�����,記錄了某地區(qū)第一個月����,第二個月,……��,第N個月的降雨量���,利用時間序列分析方法�,可以對未來各月的雨量進行預(yù)報��。
10.決策樹(Decision Tree):是在已知各種情況發(fā)生概率的基礎(chǔ)上�����,通過構(gòu)成決策樹來求取凈現(xiàn)值的期望值大于等于零的概率,評價項目風(fēng)險����,判斷其可行性的決策分析方法,是直觀運用概率分析的一種圖解法���。由于這種決策分支畫成圖形很像一棵樹的枝干�,故稱決策樹����。在機器學(xué)習(xí)中��,決策樹是一個預(yù)測模型���,他代表的是對象屬性與對象值之間的一種映射關(guān)系����。Entropy = 系統(tǒng)的凌亂程度��,使用算法ID3, C4.5和C5.0生成樹算法使用熵����。這一度量是基于信息學(xué)理論中熵的概念����。
常見的數(shù)據(jù)分析方法論大體的就是這些��,結(jié)合案例多練習(xí)下基本上就明白是什么回事���。
二�、營銷管理方法論:
1.SWOT:
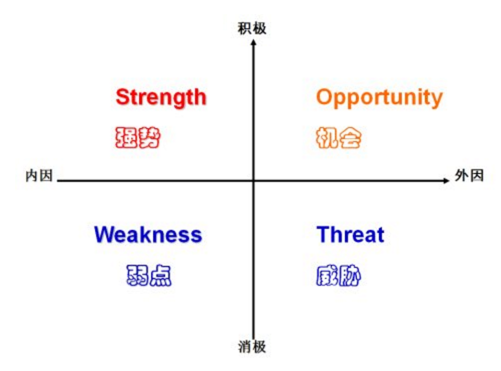
如表1的小額信貸公司的SWOT分析:

2.4P:4P即產(chǎn)品����、價格、促銷�、渠道;

3.PEST

如吉利收購沃爾沃例子

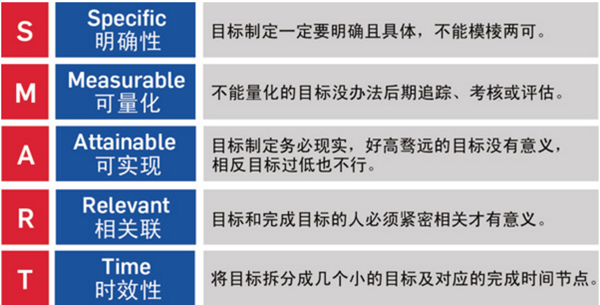
4.SMART
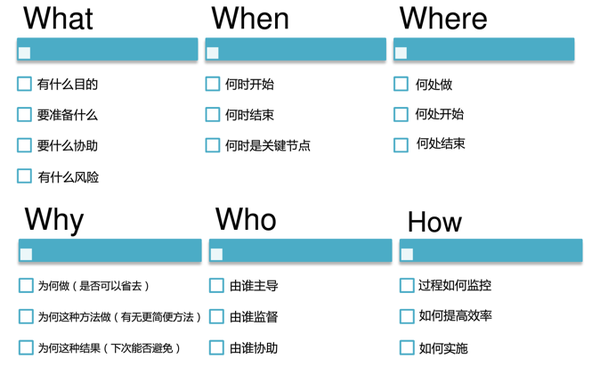
5.5W2H
6.User behavior

CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330