運(yùn)營商數(shù)據(jù)分析挖掘在廣告行業(yè)的應(yīng)用
在前兩天的分享中���,同事提到了���,目前廣告行業(yè)正在經(jīng)歷一場深刻的變革,由‘注重觸達(dá)’轉(zhuǎn)為‘注重精準(zhǔn)營銷’����,有‘單向營銷’轉(zhuǎn)為‘互動(dòng)營銷’。
實(shí)時(shí)上���,這場變革對廣告技術(shù)影響也非常深刻----直接導(dǎo)致了‘搜索�����、推薦����、廣告’三個(gè)技術(shù)趨于融合�。
為什么會(huì)導(dǎo)致這一趨勢呢?因?yàn)檫@場變革的核心是對用戶的理解,是通過數(shù)據(jù)分析師的數(shù)據(jù)來快速解讀用戶�。簡單說,品牌類廣告是‘轟炸用戶’�,效果類廣告是‘迎合用戶’。
下面我們"數(shù)據(jù)分析師"簡單看一下在擁有不同的數(shù)據(jù)源時(shí)����,如何做到‘迎合用戶’
第一種:我稱之為‘算命先生’��,這里的算命先生可是褒義詞�,算命算的好��,里面的學(xué)問大的很�。算命先生主要是收集當(dāng)事人的當(dāng)前信息,以及所有人的統(tǒng)計(jì)信息��。主要用到統(tǒng)計(jì)學(xué)相關(guān)知識(shí)��。
在DSP里��,單純根據(jù)流量數(shù)據(jù)和效果監(jiān)測數(shù)據(jù)來投放��,就屬于這種方式���。即:看一下效果好的人,當(dāng)初看廣告時(shí)是在哪兒看的�����,看的什么內(nèi)容����,什么時(shí)候看的��,用什么瀏覽器看的等���,來決定下次我們還在這個(gè)時(shí)間段,這個(gè)網(wǎng)頁上�,給使用這個(gè)瀏覽器的人投放。
第二種:我稱之為‘管中窺豹’�,即通過布碼,來捕獲用戶的部分離散的網(wǎng)絡(luò)行為��。比如�����,我在某個(gè)看照片分享網(wǎng)站上有布碼�����,我可以給到過這個(gè)網(wǎng)站上的人投放相機(jī)廣告等�。
布碼范圍大了以后,甚至可以將這些離散的行為點(diǎn)串連起來����,獲取到用戶的行為軌跡�����,從而分析用戶特征��,以此作為廣告投放依據(jù)�。
但是��,布碼對站長來說�����,相當(dāng)與在自己家里放了個(gè)別人的攝像頭��,所以稍大一點(diǎn)的網(wǎng)站對布碼都是有些抵觸的���。想在各大電商,搜索引擎等流量巨大的站點(diǎn)上布碼��,幾乎是不太可能的�����。因此�,通過布碼獲取到的用戶行為只能是一些離散的行為�����。這種方式對用戶的分析是有限的��。
問題1:布碼指的是打點(diǎn)么�?
嘉賓回答:就是將自己的代碼加載到客戶的網(wǎng)站上�����,常見的有圖片布碼:即客戶的網(wǎng)站上加入一個(gè)1像素的隱藏圖片�,用戶訪問網(wǎng)站時(shí),瀏覽器發(fā)送一個(gè)圖片請求到布碼者的服務(wù)器�����。
提問者:嗯�,和打點(diǎn)日志差不多
嘉賓回答:這種對客戶站點(diǎn)影響較小,也是一般的客戶樂于接受的方式��,缺點(diǎn)時(shí)對布碼者能獲取到的信息有限�。
還有一種時(shí)js加碼,即客戶網(wǎng)站上加入布碼者的js代碼����。這種方式布碼者可以獲取更多的信息���,比如模擬客戶做cookiemapping, 但站長一般不太歡迎這種方式。
第三種:我稱之為‘盲人摸象’�,即通過各種渠道購買數(shù)據(jù),比如從CDN廠商或其他渠道獲取數(shù)據(jù)��。這部分?jǐn)?shù)據(jù)價(jià)值就很大了����。通過這種方式甚至可以獲取到部分用戶的一段時(shí)間的連續(xù)行為。
這種方式的問題是:
(1)訪問記錄不全面(比如�����,CDN只有訪問緩存的數(shù)據(jù)����,域名服務(wù)商只有域名解析的數(shù)據(jù))
(2)數(shù)據(jù)量有限。不同的渠道獲取的都是局部的數(shù)據(jù)��,很難拿到省級以致全國級的數(shù)據(jù)�����。
(3)成本(數(shù)據(jù)關(guān)聯(lián)成本����,對接成本)等
由于以上問題,這種方式數(shù)據(jù)分析師只能分析出局部特征����。
第四種:我稱之為‘科學(xué)預(yù)測’,數(shù)據(jù)分析師即通過運(yùn)營商全量數(shù)據(jù)��,分析用戶的全網(wǎng)行為��。并以此作為投放依據(jù)��。也就是今天我們分享的方式�����。
通過以上分析����,我們可以看出,在這場變革中數(shù)據(jù)分析師的‘?dāng)?shù)據(jù)’起到的巨大作用�。
但是,單純的擁有數(shù)據(jù)����,并不一定是最后的贏家�。必須掌握從沙子里提取出金子的技術(shù)����,才能真正享受數(shù)據(jù)的價(jià)值。
目前我們在廣告行業(yè)里���,只涉及到DSP和DMP兩部分���。我對這兩部分的理解是:DSP是身體,DMP是大腦�。對于DSP,我們要求健康�,敏捷。對大腦的要求是聰明���,記性好��。
先說一下DSP�����,前面同事也分享過了���,在RTB流程里,ADExchange相當(dāng)于拍賣師�����,就是負(fù)責(zé)敲錘�。DSP相當(dāng)與舉牌人,就是負(fù)責(zé)舉牌���。DSP要快速評估價(jià)值����,決定是否值的買�����,值的出多少錢買�。DSP出價(jià)要‘快’,等到拍賣師敲錘后再想改就晚了��。
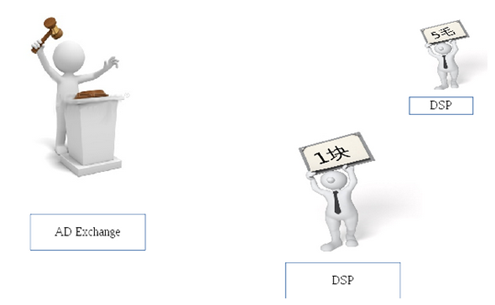
DSP的要求看似簡單��,但真正做到也是非常有技術(shù)挑戰(zhàn)的�����。單純說敏捷,在RTB的競拍流程中要求比現(xiàn)實(shí)中的要高多了?���,F(xiàn)實(shí)中,拍賣師還要喊三次�����,在RTB中����,只給了100毫秒的思考時(shí)間,這之中還包含網(wǎng)絡(luò)延遲等難以控制的因數(shù)��。
再說健康�����,RTB中�,一方面,ADExchange本身會(huì)考核DSP的健康情況�,DSP要是出了問題,ADExchange會(huì)減少分給你的流量�����。你要老出問題,ADExchange就不帶你玩兒了����。
另一邊����,廣告主也盯著你的報(bào)表。某些時(shí)候���,比如雙十一之前的投放時(shí)間,真是寸時(shí)寸金���。另外,計(jì)費(fèi)也是一個(gè)挑戰(zhàn)�,在RTB流程中,實(shí)時(shí)計(jì)費(fèi)是必須的�����,實(shí)時(shí)就意味著不可以有半點(diǎn)錯(cuò)誤���。

這個(gè)是DSP的基本架構(gòu)����,其中的最核心是BidServer和CountServer,BidServer負(fù)責(zé)和ADExchange交互�,要求拍賣時(shí)快速舉牌。CountServer是效果監(jiān)控服務(wù)器�,要求仔細(xì)記好帳。
我們先看一下對競價(jià)核心的要求:
(1)及時(shí)準(zhǔn)確的出價(jià)
(2)敏捷的響應(yīng)變更
這里涉及到很多技術(shù)點(diǎn)�,我在這里列舉一些:
一、層次分明的架構(gòu):ADExchange適配->流量控制->活動(dòng)匹配->效果評估->智能出價(jià)��。層次間相互解耦�。一個(gè)穩(wěn)定的系統(tǒng),必然是一個(gè)簡單��,層次分明的系統(tǒng)�。
各層次見流量逐級篩檢,簡單的規(guī)則在前�,復(fù)雜的規(guī)則在后,能排除大流量的規(guī)則在前�����,排除小流量的規(guī)則在后���。
二�����、熱加載:每層都可以有多個(gè)實(shí)現(xiàn)����,根據(jù)需要?jiǎng)討B(tài)加載實(shí)現(xiàn),不影響即有投放����。昨天的分享中也提到���,在DSP的各各環(huán)節(jié)中�����,有很多策略和算法需要調(diào)整�����。這些調(diào)整關(guān)系到‘錢是不是花在刀刃上’的問題���,因此必須盡快的看到效果。效果好的要保留并繼續(xù)進(jìn)化����,效果差的要及時(shí)查找原因或淘汰�����。要做到這些調(diào)整的快速響應(yīng)�,熱加載的支持是必不可少的�。
三、共享內(nèi)存:數(shù)據(jù)及策略更新推送到共享內(nèi)存��,實(shí)現(xiàn)更新的塊送響應(yīng)��。運(yùn)營人員制定的策略�,推送服務(wù)器推送過來的最新余額,都通過共享內(nèi)存的方式給多個(gè)進(jìn)程共享��。
四�����、數(shù)據(jù)結(jié)構(gòu)優(yōu)化:如通過紅黑樹實(shí)現(xiàn)快速索引�����。
五、通過tcpcopy,實(shí)現(xiàn)在線實(shí)時(shí)測試��。通過tcpcopy,可以實(shí)時(shí)拷貝線上流量到測試環(huán)境����,使用真實(shí)流量測試。
再說一下記費(fèi)及報(bào)表涉及的技術(shù)點(diǎn),這兩部分的要求都是:一要準(zhǔn)確����,二要實(shí)時(shí)。
(1)通過基于內(nèi)存的KV數(shù)據(jù)庫redis實(shí)現(xiàn)實(shí)時(shí)記費(fèi)��。
(2)通過spark-streaming實(shí)現(xiàn)多維實(shí)時(shí)報(bào)表���,快速反饋投放效果����。
另外���,為了提升效率,我們采用C語言實(shí)現(xiàn)的BidServer����。其他部分則為了快速開發(fā)而采用了java,但java在存在大量對象引用時(shí)的GC表現(xiàn)會(huì)很糟糕,因此我們采用了mapdb直接內(nèi)存讀寫技術(shù)解決大量引用帶來的GC問題���。
DSP里另外一個(gè)很重要的主題就是動(dòng)態(tài)創(chuàng)意�����,靜態(tài)創(chuàng)意的種類是有限的��,很難迎合所有客戶���。只有通過動(dòng)態(tài)創(chuàng)意,實(shí)現(xiàn)真正千人千面��,才能真正做迎合用戶����。
動(dòng)態(tài)創(chuàng)意對DSP的要求相對會(huì)高一些,要自己提供播放代碼����。由于這些代碼會(huì)在用戶瀏覽器上執(zhí)行,因此一定要保證代碼質(zhì)量���。
另外�,和靜態(tài)素材可以直接使用CDN加速不同,動(dòng)態(tài)素材里包含靜態(tài)的可以加速的部分�����,還包括動(dòng)態(tài)的不能加速的部分�。必須細(xì)心區(qū)別對待。
前面我們也提到�,廣告行業(yè)的這次變革對技術(shù)的影響中,其中之一是推薦技術(shù)在廣告行業(yè)的應(yīng)用�。推薦技術(shù)進(jìn)入到廣告行業(yè)后主要就是應(yīng)用在動(dòng)態(tài)創(chuàng)意上。通過推薦技術(shù)在廣告上展示用戶最關(guān)心的商品�,可以大幅提升用戶點(diǎn)擊廣告的可能性。
動(dòng)態(tài)創(chuàng)意要展示什么����,需要在DMP對用戶的深入分析的基礎(chǔ)上,運(yùn)用推薦相關(guān)算法如協(xié)同過濾做模型訓(xùn)練���,才能使用�。另外����,dsp的流量篩選�����,用戶效果評估等,也需要有算法的支持����。
這就涉及到DSP的中樞神經(jīng):算法平臺(tái)。
為什么我把它叫做中樞神經(jīng)��,而不是叫做大腦呢�����?����。因?yàn)椋嬲乃伎级际峭ㄟ^DMP做的����。在算法平臺(tái)里只做模型匹配計(jì)算。
算法平臺(tái)是一個(gè)非常重要的模塊���,各種算法在這里PK�,最終產(chǎn)出一個(gè)最優(yōu)結(jié)果����。這里涉及到的技術(shù)點(diǎn)也非常多���,比如各種算法、交叉校驗(yàn)����、數(shù)據(jù)可視化等。
下面說一下DMP��,簡單說����,DMP要做三件事兒:
(1)擦亮眼睛
(2)長點(diǎn)記性
(3)動(dòng)動(dòng)腦子
DMP搭建在基于YARN的Spark集群之上,主要用到的技術(shù)是Spark-SQL��,Spark-Streaming和MLLib���。
下面�����,我們分開來說�����。
一���、先說擦亮眼睛。
所謂擦亮眼睛�,就是要能看到用戶到底做了什么事情。比如:用戶在什么時(shí)間�����,什么地方上網(wǎng)�,是在PC上還是通過手機(jī)上網(wǎng),是通過瀏覽器還是通過APP�����,是看新聞還是在購物還是在玩游戲�,看新聞的話看的什么主題的新聞,購物的瀏覽了哪些商品����,收藏了哪些商品,購買了哪些商品�。玩游戲的話,玩兒的什么什么游戲����。是否有充值行為�,充值頻率等���。
我們把這個(gè)功能稱為內(nèi)容識(shí)別�����,“數(shù)據(jù)分析師”將死板的流量日志��,分析為活靈活現(xiàn)的用戶行為����。這里涉及到的技術(shù)點(diǎn)也挺多的��,比如新聞的語義分析���,主題詞提取���。商品的爬取和分類,APP的識(shí)別��,以及APP內(nèi)行為的識(shí)別等。內(nèi)容識(shí)別是后續(xù)分析的基礎(chǔ)�����,內(nèi)容識(shí)別是需要不斷投入精力去完善的核心功能��。在這里靈活運(yùn)用相關(guān)各種機(jī)器學(xué)習(xí)算法的應(yīng)用也可以很大程度上彌補(bǔ)人力的不足�。
還有一點(diǎn)需要注意的是��,由于運(yùn)營商的數(shù)據(jù)是全量的網(wǎng)絡(luò)數(shù)據(jù)�,其中既有用戶直接的點(diǎn)擊行為產(chǎn)生的日志,也有頁面ajax自己更新頁面數(shù)據(jù)的日志�,還有應(yīng)用程序甚至是爬蟲爬取網(wǎng)頁的日志。日志產(chǎn)生的根源到底是那種方式產(chǎn)生的�,必須要能識(shí)別清楚。不然���,不斷自己刷新的頁面��,你可能會(huì)誤認(rèn)為用戶很關(guān)心這個(gè)頁面而多次訪問��。
二�、我們再說一下第二點(diǎn)�����,即長點(diǎn)記性。
所謂長點(diǎn)記性���,就是說這個(gè)人第一次出現(xiàn)你不認(rèn)識(shí)�,第二次出現(xiàn)你就要認(rèn)識(shí)它了?�,F(xiàn)實(shí)生活中����,一些評價(jià)不錯(cuò)的便利店,店員都會(huì)記住老主顧���,老主顧來了會(huì)主動(dòng)提醒他說你要的那個(gè)啥啥啥今天缺貨����,或者啥啥啥到貨了���。在做數(shù)據(jù)分析時(shí)���,也要識(shí)別出哪些行為是一個(gè)人,以便給出這個(gè)人的特征��。
有些人可能疑惑了,運(yùn)營商數(shù)據(jù)不是天然就能區(qū)分開不同的人嗎����?在一定程度上是這樣的,比如通過寬帶上網(wǎng)帳號AD���,我們可以鎖定一個(gè)家庭�����,通過imei,基本可以鎖定一個(gè)手機(jī)�。
但是,問題是這些標(biāo)示都是設(shè)備級的�。一個(gè)家里可能好幾個(gè)人上網(wǎng),甚至很多公司是幾百上千人共用一個(gè)AD帳號上網(wǎng)���。對于移動(dòng)數(shù)據(jù)����,很多山寨機(jī)的imei是相同的�。從另外的角度說一個(gè)人也可能在多個(gè)AD帳號下上網(wǎng),比如在家里和公司��。一個(gè)人也可能擁有多部手機(jī)。
所以���,用戶識(shí)別是非常重要的�����,而且難度非常大��。而誤識(shí)別的影響也非常大���,如果將多個(gè)人的行為誤關(guān)聯(lián)到一個(gè)人��,就可能會(huì)影響后續(xù)人的特征判斷�,甚至影響到人群的模型訓(xùn)練����。

如上圖所示,我們?nèi)绾螌⒂脩舨煌膖oken圈起來�����,鎖定這些token背后的自然人����,是用戶識(shí)別要解決的核心問題�����。
我們解決這個(gè)問題的法寶有兩個(gè)�,一個(gè)是通過cookie����,將用一個(gè)AD帳號下的不同的人分開,另一個(gè)是通過用戶名�,將不同AD帳號下的人關(guān)聯(lián)起來。
如何使用好cookie�����,也是一個(gè)比較復(fù)雜的問題��。很多網(wǎng)站將cookie作為人或?yàn)g覽器的標(biāo)示���,但是又不全是。有些網(wǎng)站會(huì)把cookie單純當(dāng)作一個(gè)客戶端存儲(chǔ)來使用�,比如通過cookie標(biāo)示用戶上次閱讀的那篇文章的哪個(gè)章節(jié)。所以必須要識(shí)別出哪個(gè)cookie是作為身份標(biāo)示的使用的�。
如果全網(wǎng)的站點(diǎn)全部通過人工標(biāo)注,基本上是不可能的�。我們采用統(tǒng)計(jì)規(guī)則和機(jī)器學(xué)習(xí)算法相互配合的方式���,成功的識(shí)別出了大部分網(wǎng)站用作身份標(biāo)示的cookie。然后在這個(gè)基礎(chǔ)上人工篩查��,做到了非常準(zhǔn)確的身份標(biāo)示cookie的識(shí)別�����。
cookie的另外一個(gè)問題就是不能跨站點(diǎn)�,同一個(gè)人在不同站點(diǎn)上的cookie是不同的,如何同一個(gè)人在不同網(wǎng)站上的cookie關(guān)聯(lián)起來呢��?
我們發(fā)現(xiàn)�����,互聯(lián)網(wǎng)不是一個(gè)各各孤立的獨(dú)島���,用戶訪問網(wǎng)站時(shí)��,大部分也是通過點(diǎn)擊連接從一個(gè)站點(diǎn)到另外一個(gè)站點(diǎn)��。比如通過百度搜索連接跳轉(zhuǎn)到新浪�。而且很多站點(diǎn)都有嵌入其他站點(diǎn)的頁面或服務(wù)����,比如新浪頁面里有某個(gè)DSP的廣告等��。
基于這個(gè)事實(shí)�����,我們可以通過referer樹��,將多個(gè)站點(diǎn)的cookie關(guān)聯(lián)到一起�����。
當(dāng)然�,refere樹并不是萬能的����,很多熱門會(huì)有多人同時(shí)訪問����,說以還需要加入很多規(guī)則,這些規(guī)則的梳理�����,同樣需要訓(xùn)練加人工的方式。
三���、對DMP的第三點(diǎn)要求���,即動(dòng)動(dòng)腦子。
即結(jié)合各種算法����,找出每個(gè)人的特征,每個(gè)商品的特征���,每個(gè)APP的特征����,每個(gè)網(wǎng)站的特征等��,并分析人與人之間的關(guān)系�,人與商品之間的關(guān)系,人與APP之間的關(guān)系�,人與網(wǎng)站之間的關(guān)系等。通過這些關(guān)系分析�����,來預(yù)測用戶下一步的行為。
這一部分的核心就是算法����,也就是DMP被稱為大腦的主要原因。算法部分昨天同事已經(jīng)分享過了��,今天我就不詳細(xì)說了�����。數(shù)據(jù)分析師培訓(xùn)
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�����;
? 想學(xué)習(xí)CDA考試教材��,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫�����,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量����,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330