R語(yǔ)言實(shí)現(xiàn)常用的5種分析方法(主成分+因子+多維標(biāo)度+判別+聚類)
R語(yǔ)言多元分析系列之一:主成分分析
主成分分析(principal components analysis, PCA)是一種分析���、簡(jiǎn)化數(shù)據(jù)集的技術(shù)���。它把原始數(shù)據(jù)變換到一個(gè)新的坐標(biāo)系統(tǒng)中��,使得任何數(shù)據(jù)投影的第一大方差在第一個(gè)坐標(biāo)(稱為第一主成分)上�,第二大方差在第二個(gè)坐標(biāo)(第二主成分)上����,依次類推。主成分分析經(jīng)常用減少數(shù)據(jù)集的維數(shù)�,同時(shí)保持?jǐn)?shù)據(jù)集的對(duì)方差貢獻(xiàn)最大的特征。這是通過保留低階主成分���,忽略高階主成分做到的�。這樣低階成分往往能夠保留住數(shù)據(jù)的最重要方面����。但是在處理觀測(cè)數(shù)目小于變量數(shù)目時(shí)無(wú)法發(fā)揮作用�,例如基因數(shù)據(jù)。
R語(yǔ)言中進(jìn)行主成分分析可以采用基本的princomp函數(shù)����,將結(jié)果輸入到summary和plot函數(shù)中可分別得到分析結(jié)果和碎石圖。但psych擴(kuò)展包更具靈活性�����。
一 、選擇主成分個(gè)數(shù)
選擇主成分個(gè)數(shù)通常有如下幾種評(píng)判標(biāo)準(zhǔn):
根據(jù)經(jīng)驗(yàn)與理論進(jìn)行選擇
根據(jù)累積方差貢獻(xiàn)率 ����,例如選擇使累積方差貢獻(xiàn)率達(dá)到80%的主成分個(gè)數(shù)。
根據(jù)相關(guān)系數(shù)矩陣的特征值�����,選擇特征值大于1的主成分�。
另一種較為先進(jìn)的方法是平行分析(parallel analysis)。該方法首先生成若干組與原始數(shù)據(jù)結(jié)構(gòu)相同的隨機(jī)矩陣�,求出其特征值并進(jìn)行平均,然后和真實(shí)數(shù)據(jù)的特征值進(jìn)行比對(duì)��,根據(jù)交叉點(diǎn)的位置來(lái)選擇主成分個(gè)數(shù)����。我們選擇USJudgeRatings數(shù)據(jù)集舉例,首先加載psych包�����,然后使用fa.parallel函數(shù)繪制下圖���,從圖中可見第一主成分位于紅線上方��,第二主成分位于紅線下方����,因此主成分?jǐn)?shù)目選擇1。
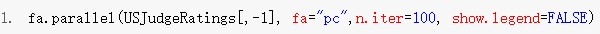
二 ���、提取主成分

從上面的結(jié)果觀察到��,PC1即觀測(cè)變量與主成分之間的相關(guān)系數(shù)���,h2是變量能被主成分解釋的比例,u2則是不能解釋的比例����。主成分解釋了92%的總方差。注意此結(jié)果與princomp函數(shù)結(jié)果不同���,princomp函數(shù)返回的是主成分的線性組合系數(shù),而principal函數(shù)返回原始變量與主成分之間的相關(guān)系數(shù)����,這樣就和因子分析的結(jié)果意義相一致。
三 ���、旋轉(zhuǎn)主成分
旋轉(zhuǎn)是在保持累積方差貢獻(xiàn)率不變條件下����,將主成分負(fù)荷進(jìn)行變換,以方便解釋�。成分旋轉(zhuǎn)這后各成分的方差貢獻(xiàn)率將重新分配,此時(shí)就不可再稱之為“主成分”而僅僅是“成分”��。旋轉(zhuǎn)又可分為正交旋轉(zhuǎn)和斜交旋轉(zhuǎn)����。正交旋轉(zhuǎn)的流行方法是方差最大化,需要在principal中增加rotate='varimax'參數(shù)加以實(shí)現(xiàn)��。也有觀點(diǎn)認(rèn)為主成分分析一般不需要進(jìn)行旋轉(zhuǎn)�。
四、計(jì)算主成分得分
主成分得分是各變量的線性組合����,在計(jì)算出主成分得分之后,還可以將其進(jìn)行回歸等做進(jìn)一步分析處理���。但注意如果輸入數(shù)據(jù)不是原始數(shù)據(jù)時(shí)��,則無(wú)法計(jì)算主成分得分��。我們需要在principal中增加score=T的參數(shù)設(shè)置�����,結(jié)果將存放在結(jié)果的score元素中�����。
R語(yǔ)言多元分析系列之二:探索性因子分析
探索性因子分析(Exploratory Factor Analysis�,EFA)是一項(xiàng)用來(lái)找出多元觀測(cè)變量的本質(zhì)結(jié)構(gòu)、并進(jìn)行處理降維的技術(shù)�����。
因而EFA能夠?qū)⒕哂绣e(cuò)綜復(fù)雜關(guān)系的變量綜合為少數(shù)幾個(gè)核心因子����。EFA和PCA的區(qū)別在于:PCA中的主成分是原始變量的線性組合,而EFA中的原始變量是公共因子的線性組合����,因子是影響變量的潛在變量,變量中不能被因子所解釋的部分稱為誤差�����,因子和誤差均不能直接觀察到�。進(jìn)行EFA需要大量的樣本,一般經(jīng)驗(yàn)認(rèn)為如何估計(jì)因子的數(shù)目為N���,則需要有5N到10N的樣本數(shù)目��。
雖然EFA和PCA有本質(zhì)上的區(qū)別��,但在分析流程上有相似之處�。下面我們用ability.cov這個(gè)心理測(cè)量數(shù)據(jù)舉例����,其變量是對(duì)人的六種能力,例如閱讀和拼寫能力進(jìn)行了測(cè)驗(yàn)��,其數(shù)據(jù)是一個(gè)協(xié)方差矩陣而非原始數(shù)據(jù)�。R語(yǔ)言中stats包中的factanal函數(shù)可以完成這項(xiàng)工作,但這里我們使用更為靈活的psych包����。
一、選擇因子個(gè)數(shù)
一般選擇因子個(gè)數(shù)可以根據(jù)相關(guān)系數(shù)矩陣的特征值�,特征值大于0則可選擇做為因子。我們?nèi)允褂闷叫蟹治龇ǎ?/span>parallel analysis)����。該方法首先生成若干組與原始數(shù)據(jù)結(jié)構(gòu)相同的隨機(jī)矩陣,求出其特征值并進(jìn)行平均���,然后和真實(shí)數(shù)據(jù)的特征值進(jìn)行比對(duì)��,根據(jù)交叉點(diǎn)的位置來(lái)選擇因子個(gè)數(shù)���。根據(jù)下圖我們可以觀察到特征值與紅線的關(guān)系,有兩個(gè)因子都位于紅線上方����,顯然應(yīng)該選擇兩個(gè)因子。

二�����、提取因子
psych包中是使用fa函數(shù)來(lái)提取因子�,將nfactors參數(shù)設(shè)定因子數(shù)為2,rotate參數(shù)設(shè)定了最大化方差的因子旋轉(zhuǎn)方法����,最后的fm表示分析方法�,由于極大似然方法有時(shí)不能收斂���,所以此處設(shè)為迭代主軸方法。從下面的結(jié)果中可以觀察到兩個(gè)因子解釋了60%的總方差���。Reading和vocabulary這兩個(gè)變量于第一項(xiàng)因子有關(guān)���,而picture、blocks和maze變量與第二項(xiàng)因子有關(guān)����,general變量于兩個(gè)因子都有關(guān)系。

如果采用基本函數(shù)factanal進(jìn)行因子分析���,那么函數(shù)形式應(yīng)該是factanal(covmat=correlations����,factors=2�,rottion='varimax'),這會(huì)得到相同的結(jié)果�����。此外,我們還可以用圖形來(lái)表示因子和變量之間的關(guān)系

三�����、因子得分
得到公共因子后�����,我們可以象主成分分析那樣反過來(lái)考察每個(gè)樣本的因子得分�����。如果輸入的是原始數(shù)據(jù)���,則可以在fa函數(shù)中設(shè)置score=T參數(shù)來(lái)獲得因子得分���。如果象上面例子那樣輸入的是相關(guān)矩陣,則需要根據(jù)因子得分系數(shù)來(lái)回歸估計(jì)���。

參考資料:R
in Action
R語(yǔ)言多元分析系列之三:多維標(biāo)度分析
多維標(biāo)度分析(MDS)是一種將多維空間的研究對(duì)象簡(jiǎn)化到低維空間進(jìn)行定位��、分析和歸類�����,同時(shí)又保留對(duì)象間原始關(guān)系的數(shù)據(jù)分析方法��。
設(shè)想一下如果我們?cè)跉W氏空間中已知一些點(diǎn)的座標(biāo)��,由此可以求出歐氏距離�。那么反過來(lái)��,已知距離應(yīng)該也能得到這些點(diǎn)之間的關(guān)系���。這種距離可以是古典的歐氏距離��,也可以是廣義上的“距離”�����。MDS就是在盡量保持這種高維度“距離”的同時(shí)�,將數(shù)據(jù)在低維度上展現(xiàn)出來(lái)���。從這種意義上來(lái)講���,主成分分析也是多維標(biāo)度分析的一個(gè)特例。
一����、距離的度量
多元分析中常用有以下幾種距離����,即絕對(duì)值距離��、歐氏距離(euclidean)�、馬氏距離(manhattan)、 兩項(xiàng)距離(binary)����、明氏距離(minkowski)。在R中通常使用disk函數(shù)得到樣本之間的距離��。MDS就是對(duì)距離矩陣進(jìn)行分析�����,以展現(xiàn)并解釋數(shù)據(jù)的內(nèi)在結(jié)構(gòu)�����。
在經(jīng)典MDS中�,距離是數(shù)值數(shù)據(jù)表示,將其看作是歐氏距離�。在R中stats包的cmdscale函數(shù)實(shí)現(xiàn)了經(jīng)典MDS��。它是根據(jù)各點(diǎn)的歐氏距離����,在低維空間中尋找各點(diǎn)座標(biāo)�,而盡量保持距離不變。
非度量MDS方法中����,“距離"不再看作數(shù)值數(shù)據(jù),而只是順序數(shù)據(jù)�。例如在心理學(xué)實(shí)驗(yàn)中���,受試者只能回答非常同意����、同意��、不同意����、非常不同意這幾種答案。在這種情況下�,經(jīng)典MDS不再有效�����。Kruskal在1964年提出了一種算法來(lái)解決這個(gè)問題����。在R中MASS包的isoMDS函數(shù)可以實(shí)現(xiàn)這種算法����,另一種流行的算法是由sammon函數(shù)實(shí)現(xiàn)的。
二�����、經(jīng)典MDS
下面我們以HSAUR2包中的watervoles數(shù)據(jù)來(lái)舉例����。該數(shù)據(jù)是一個(gè)相似矩陣,表示了不同地區(qū)水田鼠的相似程度����。首先加載數(shù)據(jù)然后用cmdscales進(jìn)行分析。

下面計(jì)算前兩個(gè)特征值在所有特征值中的比例�,這是為了檢測(cè)能否用兩個(gè)維度的距離來(lái)表示高維空間中距離,如果達(dá)到了0.8左右則表示是合適的。

然后從結(jié)果中提取前兩個(gè)維度的座標(biāo)��,用ggplot包進(jìn)行繪圖��。

三��、非度量MDS
第二例子中的數(shù)據(jù)是關(guān)于新澤西州議員投票行為的相似矩陣����,這里我們用MASS包中的isoMDS函數(shù)進(jìn)行分析

參考資料:
A Handbook of
Statistical Analyses Using R
多元統(tǒng)計(jì)分析及R語(yǔ)言建模
R語(yǔ)言多元分析系列之四:判別分析
判別分析(discriminant analysis)是一種分類技術(shù)。它通過一個(gè)已知類別的“訓(xùn)練樣本”來(lái)建立判別準(zhǔn)則�����,并通過預(yù)測(cè)變量來(lái)為未知類別的數(shù)據(jù)進(jìn)行分類��。
判別分析的方法大體上有三類����,即Fisher判別�����、Bayes判別和距離判別�。Fisher判別思想是投影降維,使多維問題簡(jiǎn)化為一維問題來(lái)處理。選擇一個(gè)適當(dāng)?shù)耐队拜S�,使所有的樣品點(diǎn)都投影到這個(gè)軸上得到一個(gè)投影值。對(duì)這個(gè)投影軸的方向的要求是:使每一組內(nèi)的投影值所形成的組內(nèi)離差盡可能小�����,而不同組間的投影值所形成的類間離差盡可能大���。Bayes判別思想是根據(jù)先驗(yàn)概率求出后驗(yàn)概率�����,并依據(jù)后驗(yàn)概率分布作出統(tǒng)計(jì)推斷��。距離判別思想是根據(jù)已知分類的數(shù)據(jù)計(jì)算各類別的重心�,對(duì)未知分類的數(shù)據(jù)�,計(jì)算它與各類重心的距離,與某個(gè)重心距離最近則歸于該類����。

一.線性判別
當(dāng)不同類樣本的協(xié)方差矩陣相同時(shí),我們可以在R中使用MASS包的lda函數(shù)實(shí)現(xiàn)線性判別����。lda函數(shù)以Bayes判別思想為基礎(chǔ)����。當(dāng)分類只有兩種且總體服從多元正態(tài)分布條件下��,Bayes判別與Fisher判別����、距離判別是等價(jià)的。本例使用iris數(shù)據(jù)集來(lái)對(duì)花的品種進(jìn)行分類�����。首先載入MASS包����,建立判別模型,其中的prior參數(shù)表示先驗(yàn)概率�。然后利用table函數(shù)建立混淆矩陣,比對(duì)真實(shí)類別和預(yù)測(cè)類別���。

二.二次判別
當(dāng)不同類樣本的協(xié)方差矩陣不同時(shí),則應(yīng)該使用二次判別�。
model2=qda(Species~.,data=iris��,cv=T)
這里將CV參數(shù)設(shè)置為T,是使用留一交叉檢驗(yàn)(leave-one-out cross-validation)��,并自動(dòng)生成預(yù)測(cè)值���。這種條件下生成的混淆矩陣較為可靠���。此外還可以使用predict(model)$posterior提取后驗(yàn)概率。
在使用lda和qda函數(shù)時(shí)注意:其假設(shè)是總體服從多元正態(tài)分布���,若不滿足的話則謹(jǐn)慎使用�。
參考資料:
Modern Applied
Statistics With S
Data_Analysis_and_Graphics_Using_R__An_Example_Based_Approach
R語(yǔ)言多元分析系列之五:聚類分析
聚類分析(Cluster Analysis)是根據(jù)“物以類聚”的道理��,對(duì)樣品或指標(biāo)進(jìn)行分類的一種多元統(tǒng)計(jì)分析方法����,它是在沒有先驗(yàn)知識(shí)的情況下���,對(duì)樣本按各自的特性來(lái)進(jìn)行合理的分類。
聚類分析被應(yīng)用于很多方面���,在商業(yè)上�����,聚類分析被用來(lái)發(fā)現(xiàn)不同的客戶群�,并且通過購(gòu)買模式刻畫不同的客戶群的特征;在生物上��,聚類分析被用來(lái)動(dòng)植物分類和對(duì)基因進(jìn)行分類�����,獲取對(duì)種群固有結(jié)構(gòu)的認(rèn)識(shí)��;在因特網(wǎng)應(yīng)用上��,聚類分析被用來(lái)在網(wǎng)上進(jìn)行文檔歸類來(lái)修復(fù)信息�。
聚類分析有兩種主要計(jì)算方法,分別是凝聚層次聚類(Agglomerative hierarchical method)和K均值聚類(K-Means)�����。
一���、層次聚類
層次聚類又稱為系統(tǒng)聚類���,首先要定義樣本之間的距離關(guān)系,距離較近的歸為一類���,較遠(yuǎn)的則屬于不同的類���。可用于定義“距離”的統(tǒng)計(jì)量包括了歐氏距離(euclidean)����、馬氏距離(manhattan)、 兩項(xiàng)距離(binary)��、明氏距離(minkowski)�����。還包括相關(guān)系數(shù)和夾角余弦�。
層次聚類首先將每個(gè)樣本單獨(dú)作為一類,然后將不同類之間距離最近的進(jìn)行合并��,合并后重新計(jì)算類間距離����。這個(gè)過程一直持續(xù)到將所有樣本歸為一類為止。在計(jì)算類間距離時(shí)則有六種不同的方法��,分別是最短距離法���、最長(zhǎng)距離法�����、類平均法����、重心法、中間距離法��、離差平方和法����。
下面我們用iris數(shù)據(jù)集來(lái)進(jìn)行聚類分析,在R語(yǔ)言中所用到的函數(shù)為hclust�����。首先提取iris數(shù)據(jù)中的4個(gè)數(shù)值變量����,然后計(jì)算其歐氏距離矩陣。然后將矩陣?yán)L制熱圖��,從圖中可以看到顏色越深表示樣本間距離越近,大致上可以區(qū)分出三到四個(gè)區(qū)塊����,其樣本之間比較接近。

然后使用hclust函數(shù)建立聚類模型��,結(jié)果存在model1變量中����,其中ward參數(shù)是將類間距離計(jì)算方法設(shè)置為離差平方和法�。使用plot(model1)可以繪制出聚類樹圖。如果我們希望將類別設(shè)為3類�,可以使用cutree函數(shù)提取每個(gè)樣本所屬的類別。

為了顯示聚類的效果����,我們可以結(jié)合多維標(biāo)度和聚類的結(jié)果。先將數(shù)據(jù)用MDS進(jìn)行降維����,然后以不同的的形狀表示原本的分類,用不同的顏色來(lái)表示聚類的結(jié)果���??梢钥吹?/span>setose品種聚類很成功��,但有一些virginica品種的花被錯(cuò)誤和virginica品種聚類到一起。

二���、K均值聚類
K均值聚類又稱為動(dòng)態(tài)聚類�����,它的計(jì)算方法較為簡(jiǎn)單�����,也不需要輸入距離矩陣��。首先要指定聚類的分類個(gè)數(shù)N����,隨機(jī)取N個(gè)樣本作為初始類的中心�,計(jì)算各樣本與類中心的距離并進(jìn)行歸類,所有樣本劃分完成后重新計(jì)算類中心���,重復(fù)這個(gè)過程直到類中心不再變化����。
在R中使用kmeans函數(shù)進(jìn)行K均值聚類,centers參數(shù)用來(lái)設(shè)置分類個(gè)數(shù)���,nstart參數(shù)用來(lái)設(shè)置取隨機(jī)初始中心的次數(shù)��,其默認(rèn)值為1����,但取較多的次數(shù)可以改善聚類效果����。model2$cluster可以用來(lái)提取每個(gè)樣本所屬的類別����。
model2=kmeans(data,centers=3����,nstart=10)
使用K均值聚類時(shí)需要注意,只有在類的平均值被定義的情況下才能使用����,還要求事先給出分類個(gè)數(shù)。一種方法是先用層次聚類以決定個(gè)數(shù)���,再用K均值聚類加以改進(jìn)�。或者以輪廓系數(shù)來(lái)判斷分類個(gè)數(shù)�。改善聚類的方法還包括對(duì)原始數(shù)據(jù)進(jìn)行變換,如對(duì)數(shù)據(jù)進(jìn)行降維后再實(shí)施聚類���。
cluster擴(kuò)展包中也有許多函數(shù)可用于聚類分析����,如agnes函數(shù)可用于凝聚層次聚類���,diana可用于劃分層次聚類����,pam可用于K均值聚類�����,fanny用于模糊聚類���。
原文鏈接:http://www.cnblogs.com/wentingtu/archive/2012/03/03/2377971.html
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫(kù)�����,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情�����;
? 想了解CDA考試含金量����,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330