詳解R語(yǔ)言中的遺傳算法
文 | 張丹(Conan)
前言
人類(lèi)總是在生活中摸索規(guī)律����,把規(guī)律總結(jié)為經(jīng)驗(yàn)�����,再把經(jīng)驗(yàn)傳給后人�,讓后人發(fā)現(xiàn)更多的規(guī)規(guī)律,每一次知識(shí)的傳遞都是一次進(jìn)化的過(guò)程�,最終會(huì)形成了人類(lèi)的智慧�����。自然界規(guī)律�,讓人類(lèi)適者生存地活了下來(lái)��,聰明的科學(xué)家又把生物進(jìn)化的規(guī)律�,總結(jié)成遺傳算法,擴(kuò)展到了更廣的領(lǐng)域中�����。
本文將帶你走進(jìn)遺傳算法的世界�。
目錄
遺傳算法介紹
遺傳算法原理
遺傳算法R語(yǔ)言實(shí)現(xiàn)
1. 遺傳算法介紹
遺傳算法是一種解決最優(yōu)化的搜索算法,是進(jìn)化算法的一種�����。進(jìn)化算法最初借鑒了達(dá)爾文的進(jìn)化論和孟德?tīng)柕倪z傳學(xué)說(shuō)���,從生物進(jìn)化的一些現(xiàn)象發(fā)展起來(lái)����,這些現(xiàn)象包括遺傳、基因突變�、自然選擇和雜交等。遺傳算法通過(guò)模仿自然界生物進(jìn)化機(jī)制���,發(fā)展出了隨機(jī)全局搜索和優(yōu)化的方法�。遺傳算法其本質(zhì)是一種高效����、并行�、全局搜索的方法,它能在搜索過(guò)程中自動(dòng)獲取和積累有關(guān)搜索空間的知識(shí)��,并自適應(yīng)的控制搜索過(guò)程��,計(jì)算出全局最優(yōu)解�。
遺傳算法的操作使用適者生存的原則,在潛在的種群中逐次產(chǎn)生一個(gè)近似最優(yōu)解的方案����,在每一代中,根據(jù)個(gè)體在問(wèn)題域中的適應(yīng)度值和從自然遺傳學(xué)中借鑒來(lái)的再造方法進(jìn)行個(gè)體選擇���,產(chǎn)生一個(gè)新的近似解����。這個(gè)過(guò)程會(huì)導(dǎo)致種群中個(gè)體的進(jìn)化,得到的新個(gè)體比原來(lái)個(gè)體更能適應(yīng)環(huán)境��,就像自然界中的改造一樣�。
如果從生物進(jìn)化的角度,我們可以這樣理解��。在一個(gè)種群中����,個(gè)體數(shù)量已經(jīng)有一定規(guī)模,為了進(jìn)化發(fā)展����,通過(guò)選擇和繁殖產(chǎn)生下一代的個(gè)體,其中繁殖過(guò)程包括交配和突變�����。根據(jù)適者生存的原則�����,選擇過(guò)程會(huì)根據(jù)新個(gè)體的適應(yīng)度進(jìn)行保留或淘汰���,但也不是完全以適應(yīng)度高低作為導(dǎo)向���,如果單純選擇適應(yīng)度高的個(gè)體可能會(huì)產(chǎn)生局部最優(yōu)的種群����,而非全局最優(yōu)��,這個(gè)種群將不會(huì)再進(jìn)化����,稱(chēng)為早熟。之后���,通過(guò)繁殖過(guò)程���,讓個(gè)體兩兩交配產(chǎn)生下一代新個(gè)體�����,上一代個(gè)體中優(yōu)秀的基因會(huì)保留給下一代���,而劣制的基因?qū)⒈粋€(gè)體另一半的基因所代替�����。最后,通過(guò)小概率事件發(fā)生基因突變,通過(guò)突變產(chǎn)生新的下一代個(gè)體,實(shí)現(xiàn)種群的變異進(jìn)化。
經(jīng)過(guò)這一系列的選擇��、交配和突變的過(guò)程�,產(chǎn)生的新一代個(gè)體將不同于初始的一代�,并一代一代向增加整體適應(yīng)度的方向發(fā)展����,因?yàn)樽詈玫膫€(gè)體總是更多的被選擇去產(chǎn)生下一代���,而適應(yīng)度低的個(gè)體逐漸被淘汰掉����。這樣的過(guò)程不斷的重復(fù):每個(gè)個(gè)體被評(píng)價(jià)���,計(jì)算出適應(yīng)度���,兩個(gè)個(gè)體交配,然后突變��,產(chǎn)生第三代����。周而復(fù)始,直到終止條件滿足為止����。
遺傳算法需要注意的問(wèn)題:
遺傳算法在適應(yīng)度函數(shù)選擇不當(dāng)?shù)那闆r下有可能收斂于局部最優(yōu),而不能達(dá)到全局最優(yōu)��。
初始種群的數(shù)量很重要�,如果初始種群數(shù)量過(guò)多,算法會(huì)占用大量系統(tǒng)資源�;如果初始種群數(shù)量過(guò)少,算法很可能忽略掉最優(yōu)解�。
對(duì)于每個(gè)解,一般根據(jù)實(shí)際情況進(jìn)行編碼���,這樣有利于編寫(xiě)變異函數(shù)和適應(yīng)度函數(shù)��。
在編碼過(guò)的遺傳算法中��,每次變異的編碼長(zhǎng)度也影響到遺傳算法的效率����。如果變異代碼長(zhǎng)度過(guò)長(zhǎng)�,變異的多樣性會(huì)受到限制����;如果變異代碼過(guò)短,變異的效率會(huì)非常低下�,選擇適當(dāng)?shù)淖儺愰L(zhǎng)度是提高效率的關(guān)鍵。
變異率是一個(gè)重要的參數(shù)��。
對(duì)于動(dòng)態(tài)數(shù)據(jù),用遺傳算法求最優(yōu)解比較困難���,因?yàn)槿旧w種群很可能過(guò)早地收斂���,而對(duì)以后變化了的數(shù)據(jù)不再產(chǎn)生變化。對(duì)于這個(gè)問(wèn)題�����,研究者提出了一些方法增加基因的多樣性�,從而防止過(guò)早的收斂。其中一種是所謂觸發(fā)式超級(jí)變異���,就是當(dāng)染色體群體的質(zhì)量下降(彼此的區(qū)別減少)時(shí)增加變異概率�;另一種叫隨機(jī)外來(lái)染色體��,是偶爾加入一些全新的隨機(jī)生成的染色體個(gè)體����,從而增加染色體多樣性。
選擇過(guò)程很重要��,但交叉和變異的重要性存在爭(zhēng)議��。一種觀點(diǎn)認(rèn)為交叉比變異更重要,因?yàn)樽儺悆H僅是保證不丟失某些可能的解����;而另一種觀點(diǎn)則認(rèn)為交叉過(guò)程的作用只不過(guò)是在種群中推廣變異過(guò)程所造成的更新��,對(duì)于初期的種群來(lái)說(shuō)��,交叉幾乎等效于一個(gè)非常大的變異率�,而這么大的變異很可能影響進(jìn)化過(guò)程。
遺傳算法很快就能找到良好的解����,即使是在很復(fù)雜的解空間中。
遺傳算法并不一定總是最好的優(yōu)化策略�,優(yōu)化問(wèn)題要具體情況具體分析。所以在使用遺傳算法的同時(shí)�����,也可以嘗試其他算法���,互相補(bǔ)充�����,甚至根本不用遺傳算法��。
遺傳算法不能解決那些“大海撈針”的問(wèn)題����,所謂“大海撈針”問(wèn)題就是沒(méi)有一個(gè)確切的適應(yīng)度函數(shù)表征個(gè)體好壞的問(wèn)題,使得算法的進(jìn)化失去導(dǎo)向�����。
對(duì)于任何一個(gè)具體的優(yōu)化問(wèn)題�����,調(diào)節(jié)遺傳算法的參數(shù)可能會(huì)有利于更好的更快的收斂����,這些參數(shù)包括個(gè)體數(shù)目、交叉率和變異率���。例如太大的變異率會(huì)導(dǎo)致丟失最優(yōu)解��,而過(guò)小的變異率會(huì)導(dǎo)致算法過(guò)早的收斂于局部最優(yōu)點(diǎn)����。對(duì)于這些參數(shù)的選擇,現(xiàn)在還沒(méi)有實(shí)用的上下限�����。
適應(yīng)度函數(shù)對(duì)于算法的速度和效果也很重要�。
遺傳算法的應(yīng)用領(lǐng)域包括計(jì)算機(jī)自動(dòng)設(shè)計(jì)、生產(chǎn)調(diào)度�、電路設(shè)計(jì)�、游戲設(shè)計(jì)、機(jī)器人學(xué)習(xí)�、模糊控制、時(shí)間表安排�����,神經(jīng)網(wǎng)絡(luò)訓(xùn)練等�。然而,我準(zhǔn)備把遺傳算法到金融領(lǐng)域����,比如回測(cè)系統(tǒng)的參數(shù)尋優(yōu)方案,我會(huì)在以后的文章中�����,介紹有關(guān)金融解決方案。
2. 遺傳算法原理
在遺傳算法里�����,優(yōu)化問(wèn)題的解是被稱(chēng)為個(gè)體�����,它表示為一個(gè)變量序列����,叫做染色體或者基因串。染色體一般被表達(dá)為簡(jiǎn)單的字符串或數(shù)字串��,也有其他表示法�,這一過(guò)程稱(chēng)為編碼。首先要?jiǎng)?chuàng)建種群����,算法隨機(jī)生成一定數(shù)量的個(gè)體,有時(shí)候也可以人工干預(yù)這個(gè)過(guò)程進(jìn)行��,以提高初始種群的質(zhì)量��。在每一代中�,每一個(gè)個(gè)體都被評(píng)價(jià)�,并通過(guò)計(jì)算適應(yīng)度函數(shù)得到一個(gè)適應(yīng)度數(shù)值����。種群中的個(gè)體被按照適應(yīng)度排序,適應(yīng)度高的在前面�����。
接下來(lái)��,是產(chǎn)生下一代個(gè)體的種群��,通過(guò)選擇過(guò)程和繁殖過(guò)程完成����。
選擇過(guò)程����,是根據(jù)新個(gè)體的適應(yīng)度進(jìn)行的,但同時(shí)并不意味著完全的以適應(yīng)度高低作為導(dǎo)向��,因?yàn)閱渭冞x擇適應(yīng)度高的個(gè)體將可能導(dǎo)致算法快速收斂到局部最優(yōu)解而非全局最優(yōu)解�����,我們稱(chēng)之為早熟。作為折中����,遺傳算法依據(jù)原則:適應(yīng)度越高,被選擇的機(jī)會(huì)越高�,而適應(yīng)度低的,被選擇的機(jī)會(huì)就低��。初始的數(shù)據(jù)可以通過(guò)這樣的選擇過(guò)程組成一個(gè)相對(duì)優(yōu)化的群體。
繁殖過(guò)程,表示被選擇的個(gè)體進(jìn)入交配過(guò)程����,包括交配(crossover)和突變(mutation),交配對(duì)應(yīng)算法中的交叉操作����。一般的遺傳算法都有一個(gè)交配概率�����,范圍一般是0.6~1����,這個(gè)交配概率反映兩個(gè)被選中的個(gè)體進(jìn)行交配的概率。
例如��,交配概率為0.8,則80%的“夫妻”個(gè)體會(huì)生育后代��。每?jī)蓚€(gè)個(gè)體通過(guò)交配產(chǎn)生兩個(gè)新個(gè)體��,代替原來(lái)的“老”個(gè)體�,而不交配的個(gè)體則保持不變。交配過(guò)程���,父母的染色體相互交換�����,從而產(chǎn)生兩個(gè)新的染色體�����,第一個(gè)個(gè)體前半段是父親的染色體,后半段是母親的�,第二個(gè)個(gè)體則正好相反。不過(guò)這里指的半段並不是真正的一半��,這個(gè)位置叫做交配點(diǎn)���,也是隨機(jī)產(chǎn)生的����,可以是染色體的任意位置。
突變過(guò)程��,表示通過(guò)突變產(chǎn)生新的下一代個(gè)體���。一般遺傳算法都有一個(gè)固定的突變常數(shù)����,又稱(chēng)為變異概率��,通常是0.1或者更小�����,這代表變異發(fā)生的概率��。根據(jù)這個(gè)概率���,新個(gè)體的染色體隨機(jī)的突變�����,通常就是改變?nèi)旧w的一個(gè)字節(jié)(0變到1����,或者1變到0)。
遺傳算法實(shí)現(xiàn)將不斷的重復(fù)這個(gè)過(guò)程:每個(gè)個(gè)體被評(píng)價(jià)��,計(jì)算出適應(yīng)度�,兩個(gè)個(gè)體交配,然后突變����,產(chǎn)生下一代,直到終止條件滿足為止��。一般終止條件有以下幾種:
進(jìn)化次數(shù)限制
計(jì)算耗費(fèi)的資源限制��,如計(jì)算時(shí)間��、計(jì)算占用的CPU����,內(nèi)存等
個(gè)體已經(jīng)滿足最優(yōu)值的條件��,即最優(yōu)值已經(jīng)找到
當(dāng)適應(yīng)度已經(jīng)達(dá)到飽和��,繼續(xù)進(jìn)化不會(huì)產(chǎn)生適應(yīng)度更好的個(gè)體
人為干預(yù)
算法實(shí)現(xiàn)原理:
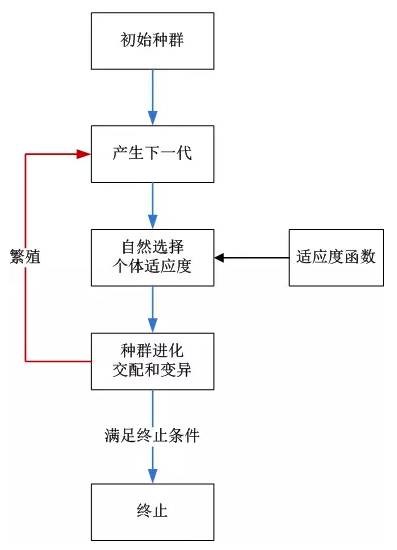
1. 創(chuàng)建初始種群
2. 循環(huán):產(chǎn)生下一代
3. 評(píng)價(jià)種群中的個(gè)體適應(yīng)度
4. 定義選擇的適應(yīng)度函數(shù)
5. 改變?cè)摲N群(交配和變異)
6. 返回第二步
7. 滿足終止條件結(jié)束
3. 遺傳算法R語(yǔ)言實(shí)現(xiàn)
本節(jié)的系統(tǒng)環(huán)境
Win7
64bit
R: 3.1.1 x86_64-w64-mingw32/x64 (64-bit)
一個(gè)典型的遺傳算法要求:一個(gè)基因表示的求解域,
一個(gè)適應(yīng)度函數(shù)來(lái)評(píng)價(jià)解決方案���。
遺傳算法的參數(shù)通常包括以下幾個(gè):
種群規(guī)模(Population)�,即種群中染色體個(gè)體的數(shù)目���。
染色體的基因個(gè)數(shù)(Size)���,即變量的數(shù)目。
交配概率(Crossover)���,用于控制交叉計(jì)算的使用頻率�����。交叉操作可以加快收斂���,使解達(dá)到最有希望的最優(yōu)解區(qū)域,因此一般取較大的交叉概率����,但交叉概率太高也可能導(dǎo)致過(guò)早收斂。
變異概率(Mutation)�����,用于控制變異計(jì)算的使用頻率,決定了遺傳算法的局部搜索能力���。
中止條件(Termination)��,結(jié)束的標(biāo)志�����。
在R語(yǔ)言中�,有一些現(xiàn)成的第三方包已經(jīng)實(shí)現(xiàn)的遺傳算法��,我們可以直接進(jìn)行使用��。
mcga包�,多變量的遺傳算法,用于求解多維函數(shù)的最小值�����。
genalg包�,多變量的遺傳算法,用于求解多維函數(shù)的最小值�。
rgenoud包,復(fù)雜的遺傳算法����,將遺傳算法和衍生的擬牛頓算法結(jié)合起來(lái),可以求解復(fù)雜函數(shù)的最優(yōu)化化問(wèn)題��。
gafit包��,利用遺傳算法求解一維函數(shù)的最小值����。不支持R 3.1.1的版本。
GALGO包��,利用遺傳算法求解多維函數(shù)的最優(yōu)化解����。不支持R 3.1.1的版本。
本文將介紹mcga包和genalg包的遺傳算法的使用���。
3.1
mcga包
我們使用mcga包的mcga()函數(shù)���,可以實(shí)現(xiàn)多變量的遺傳算法。
mcga包是一個(gè)遺傳算法快速的工具包����,主要解決實(shí)值優(yōu)化的問(wèn)題���。它使用的變量值表示基因序列,而不是字節(jié)碼��,因此不需要編解碼的處理�����。mcga實(shí)現(xiàn)了遺傳算法的交配和突變的操作�,并且可以進(jìn)行大范圍和高精度的搜索空間的計(jì)算,算法的主要缺點(diǎn)是使用了256位的一元字母表��。
首先��,安裝mcga包����。

查看一下mcga()函數(shù)的定義。

參數(shù)說(shuō)明:
popsize�����,個(gè)體數(shù)量�����,即染色體數(shù)目
chsize,基因數(shù)量��,限參數(shù)的數(shù)量
crossprob���,交配概率,默認(rèn)為1.0
mutateprob����,突變概率,默認(rèn)為0.01
elitism�,精英數(shù)量,直接復(fù)制到下一代的染色體數(shù)目��,默認(rèn)為1
minval���,隨機(jī)生成初始種群的下邊界值
maxval����,隨機(jī)生成初始種群的上邊界值
maxiter�,繁殖次數(shù),即循環(huán)次數(shù)�����,默認(rèn)為10
evalFunc,適應(yīng)度函數(shù)�,用于給個(gè)體進(jìn)行評(píng)價(jià)
接下來(lái),我們給定一個(gè)優(yōu)化的問(wèn)題��,通過(guò)mcga()函數(shù)���,計(jì)算最優(yōu)化的解�����。
題目1:設(shè)fx=(x1-5)^2 + (x2-55)^2 +(x3-555)^2 +(x4-5555)^2 +(x5-55555)^2����,計(jì)算fx的最小值�����,其中x1�,x2,x3���,x4�����,x5為5個(gè)不同的變量����。
從直觀上看,如果想得到fx的最小值��,其實(shí)當(dāng)x1=5�����,x2=55�����,x3=555��,x4=5555����,x5=55555時(shí)��,fx=0為最小值�。如果使用窮舉法�����,通過(guò)循環(huán)的方法找到這5個(gè)變量�,估計(jì)會(huì)很費(fèi)時(shí)的���,我就不做測(cè)試了�。下面我們看一下遺傳算法的運(yùn)行情況���。

我們得到的最優(yōu)化的結(jié)果為x1=5.000317�, x2=54.997099�, x3=554.999873, x4=5555.003120���, x5=55554.218695�����,和我們預(yù)期的結(jié)果非常接近��,而且耗時(shí)只有3.6秒�����。這個(gè)結(jié)果是非常令人滿意地�,不是么!如果使用窮舉法����,時(shí)間復(fù)雜度為O(n^5),估計(jì)沒(méi)有5分鐘肯定算不出來(lái)����。
當(dāng)然,算法執(zhí)行時(shí)間和精度����,都是通過(guò)參數(shù)進(jìn)行配置的�。如果增大個(gè)體數(shù)目或循環(huán)次數(shù),一方面會(huì)增加算法的計(jì)算時(shí)間�,另一方面結(jié)果也可能變得更精準(zhǔn)。所以���,在實(shí)際的使用過(guò)程中���,需要根據(jù)一定的經(jīng)驗(yàn)調(diào)整這幾個(gè)參數(shù)。
3.2
genalg包
我們使用genalg包的rbga()函數(shù),也可以實(shí)現(xiàn)多變量的遺傳算法����。
genalg包不僅實(shí)現(xiàn)了遺傳算法�����,還提供了遺傳算法的數(shù)據(jù)可視化�,給用戶(hù)更直觀的角度理解算法。默認(rèn)圖顯示的最小和平均評(píng)價(jià)值�,表示遺傳算法的計(jì)算進(jìn)度。直方圖顯出了基因選擇的頻率�,即基因在當(dāng)前個(gè)體中被選擇的次數(shù)。參數(shù)圖表示評(píng)價(jià)函數(shù)和變量值�,非常方便地看到評(píng)價(jià)函數(shù)和變量值的相關(guān)關(guān)系。
首先�,安裝genalg包。
查看一下rbga()函數(shù)的定義�����。

參數(shù)說(shuō)明:
stringMin��,設(shè)置每個(gè)基因的最小值
stringMax�,設(shè)置每個(gè)基因的最大值
suggestions��,建議染色體的可選列表
popSize��,個(gè)體數(shù)量�����,即染色體數(shù)目�,默認(rèn)為200
iters�����,迭代次數(shù)����,默認(rèn)為100
mutationChance,突變機(jī)會(huì)���,默認(rèn)為1/(size+1),它影響收斂速度和搜索空間的探測(cè)���,低機(jī)率導(dǎo)致更快收斂����,高機(jī)率增加了搜索空間的跨度。
elitism���,精英數(shù)量�����,默認(rèn)為20%����,直接復(fù)制到下一代的染色體數(shù)目
monitorFunc���,監(jiān)控函數(shù)�����,每產(chǎn)生一代后運(yùn)行
evalFunc��,適應(yīng)度函數(shù)����,用于給個(gè)體進(jìn)行評(píng)價(jià)
showSettings��,打印設(shè)置���,默認(rèn)為false
verbose���,打印算法運(yùn)行日志���,默認(rèn)為false
接下來(lái),我們給定一個(gè)優(yōu)化的問(wèn)題���,通過(guò)rbga()函數(shù)��,計(jì)算最優(yōu)化的解��。
題目2:設(shè)fx=abs(x1-sqrt(exp(1)))+abs(x2-log(pi))���,計(jì)算fx的最小值,其中x1�,x2為2個(gè)不同的變量。
從直觀上看����,如果想得到fx的最小值���,其實(shí)當(dāng)x1=sqrt(exp(1))=1.648721����, x2=log(pi)=1.14473時(shí),fx=0為最小值��。同樣地�����,如果使用窮舉法��,通過(guò)循環(huán)的方法找到這2個(gè)變量��,估計(jì)會(huì)很費(fèi)時(shí)的�,我也不做測(cè)試了。下面我們看一下rbga()函數(shù)的遺傳算法的運(yùn)行情況�����。

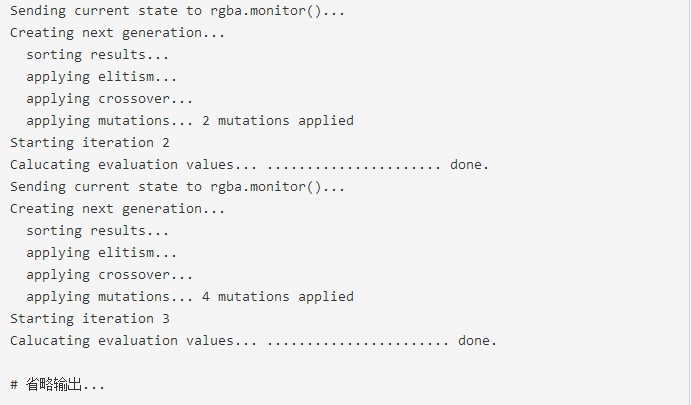
程序運(yùn)行截圖
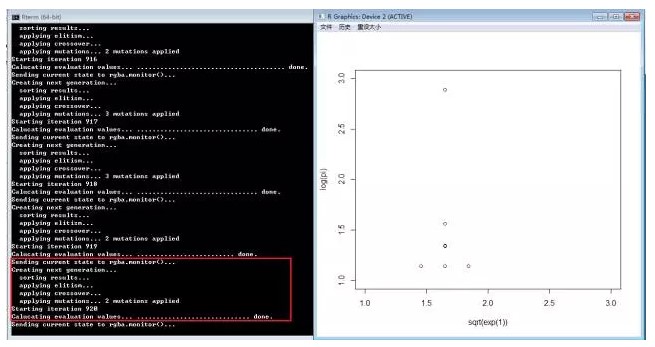
需要注意的是�,程序在要命令行界面運(yùn)行,如果在RStudio中運(yùn)行����,會(huì)出現(xiàn)下面的錯(cuò)誤提示。
我們迭代1000次后����,查看計(jì)算結(jié)果�����。
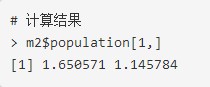
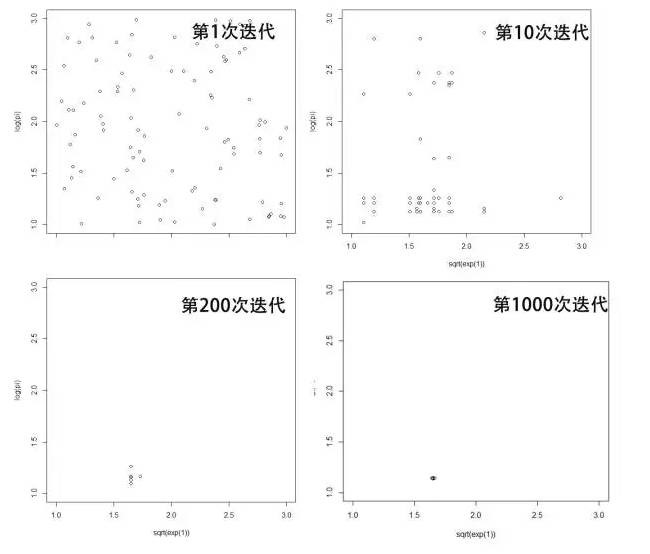
我們得到的最優(yōu)化的結(jié)果為x1=1.650571��, x2=1.145784��,非常接近最終的結(jié)果��。另外�,我們可以通過(guò)genalg包的可視化功能���,看到迭代過(guò)程的每次的計(jì)算結(jié)果����。下面截圖分為對(duì)應(yīng)1次迭代����,10次迭代,200次迭代和1000次迭代的計(jì)算結(jié)果��。從圖中可以看出,隨著迭代次數(shù)的增加�����,優(yōu)選出的結(jié)果集變得越來(lái)越少�����,而且越來(lái)越精準(zhǔn)���。
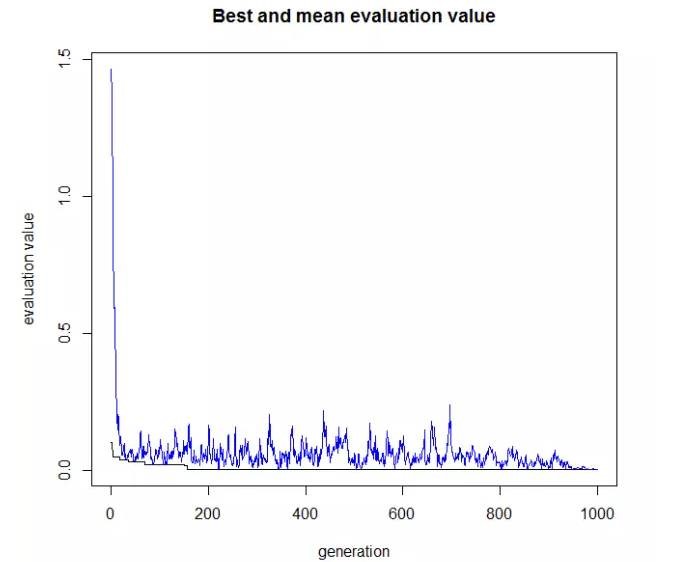
默認(rèn)圖輸出,用于描述遺傳過(guò)程的進(jìn)展�,X軸為迭代次數(shù),Y軸評(píng)價(jià)值�,評(píng)價(jià)值越接近于0越好。在1000迭代1000次后���,基本找到了精確的結(jié)果�。
>
plot(m2)
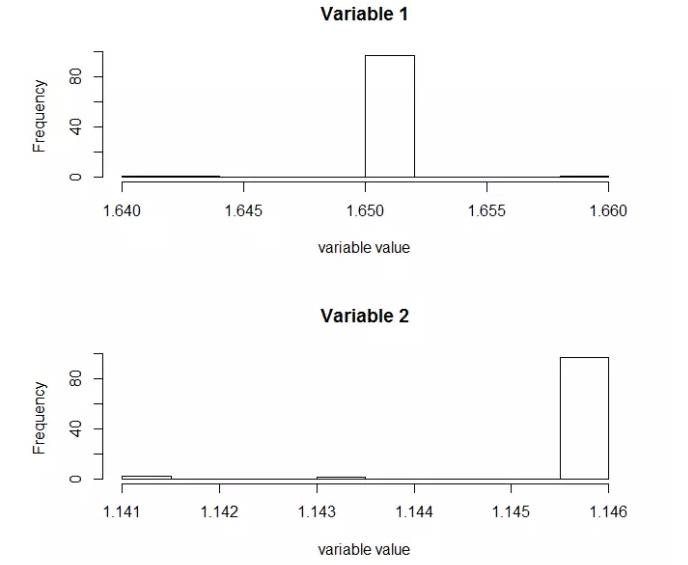
直方圖輸出��,用于描述對(duì)染色體的基因選擇頻率�,即一個(gè)基因在染色體中的當(dāng)前人口被選擇的次數(shù)。當(dāng)x1在1.65區(qū)域時(shí)�,被選擇超過(guò)80次;當(dāng)x2在1.146區(qū)域時(shí),被選擇超過(guò)了80次����。通過(guò)直方圖,我們可以理解為更優(yōu)秀的基因被留給了后代��。
>
plot(m2�,type='hist')
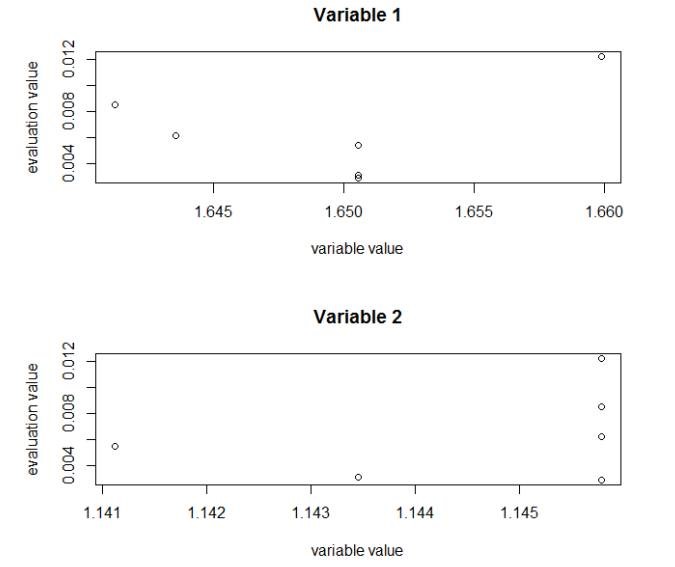
參數(shù)圖輸出,用于描述評(píng)價(jià)函數(shù)和變量的值的相關(guān)關(guān)系����。對(duì)于x1,評(píng)價(jià)值越小����,變量值越準(zhǔn)確,但相關(guān)關(guān)系不明顯����。對(duì)于x2,看不出相關(guān)關(guān)系�����。
>
plot(m2����,type='vars')
對(duì)比mcga包和genalg包��,mcga包適合計(jì)算大范圍取值空間的最優(yōu)解�����,而用genalg包對(duì)于大范圍取值空間的計(jì)算就表現(xiàn)就不太好了。從另一個(gè)方面講�����,genalg包提供了可視化工具��,可以讓我們直觀的看遺傳算法的收斂過(guò)程�,對(duì)于算法的理解和調(diào)優(yōu)是非常有幫助的。
在掌握了遺傳算法后�����,我們就可以快度地處理一些優(yōu)化的問(wèn)題了��,比如接下來(lái)我會(huì)介紹的金融回測(cè)系統(tǒng)的參數(shù)尋優(yōu)方案�����。讓我們遠(yuǎn)離窮舉法,珍惜CPU的每一秒時(shí)間����。
來(lái)自粉絲日志
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�;
? 想學(xué)習(xí)CDA考試教材,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫(kù)����,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情�����;
? 想了解CDA考試含金量��,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330