8個提高數(shù)據(jù)分析工作效率的技巧
我剛和一位老友恢復了聯(lián)系。她一直對數(shù)據(jù)科學很感興趣�����,但10個月前才涉足這一領域——作為一個數(shù)據(jù)科學家加入了一個組織���。我明顯感覺到她已經(jīng)在新的崗位上學到了很多東西����。然而�,我們聊天時,她提到了一個至今在我腦海里都揮之不去的事實或者說是問題。她說���,不論她表現(xiàn)如何�,每一個項目或分析任務在令經(jīng)理滿意之前都要做好多次���。她還提到,往往事后發(fā)現(xiàn)原本不需要花這么多時間����!
聽起來是不是很像你的遭遇?你會不會在得出像樣的答案之前反復分析很多次�����?或者一遍又一遍地為類似的活動寫著代碼��?如果是這樣的話����,這篇文章正好適合你。我會分享一些提高效率和減少不必要的重復工作的方法���。
備注:請別誤會��。我不是說迭代都不好�����。這篇文章的重點在于如何識別哪些迭代是必要的����,哪些是不必要且需要避免的。
什么原因?qū)е铝藬?shù)據(jù)分析中的重復工作�?
我認為沒有加入新信息,就沒必要重復分析(后面提到一個例外)����。下面這些重復工作都是可以避免的:
-
對客戶問題的診斷有偏差,不能滿足需求�,所以要重做。
-
重復分析的目的在于收集更多的變量�,而你之前認為不需要這些變量。
-
之前沒有考慮到影響你分析活動的偏差或假設����,后來考慮到了所以要重做。
哪些迭代是必要的呢����?下面舉兩個例子���,一、你先建立了一個6個月后的模型�,隨后有了新的信息,由此導致的迭代是健康的����。二、你有意地從簡單的模型開始逐漸深入理解并構建復雜模型�����。
上面沒有涵蓋所有可能的情況�����,但我相信這些例子足夠幫助你判斷你的分析迭代是不是健康的���。
這些生產(chǎn)力殺手的影響?
我們很清楚一點——沒有人想在分析中出現(xiàn)不健康的迭代和生產(chǎn)力殺手�。不是每個數(shù)據(jù)科學家都樂于一邊做一邊增加變量并反復運行整個分析過程。
分析師和數(shù)據(jù)科學家會因為不健康迭代和喪失效率而深感挫敗���,缺乏成就感�����。那么讓我們盡一切努力來避免它們吧���。
小貼士:如何避免不健康迭代并增加效率
技巧1: 只關注重大問題
每個組織都有很多可以用數(shù)據(jù)解決的小問題!但雇一個數(shù)據(jù)科學家的主要目的不在于解決這些小問題���。好鋼要用在刀刃上,應該選取3到4個對整個組織影響最大的數(shù)據(jù)問題交給數(shù)據(jù)科學家來解決���。這些問題一般具有挑戰(zhàn)性���,會給你的分析活動帶來最大杠桿(或者收獲滿滿或者顆粒無收,想象一下借貸炒股)�����。當更大的問題沒被解決時�,你不應當去解決小問題。
聽起來沒什么����,但實際上很多組織都沒做好這一點!我看到很多銀行沒用數(shù)據(jù)分析去改善風險評分,而是去做市場營銷���。有些保險公司沒用數(shù)據(jù)分析提升客戶留存率���,而是試圖建立針對代理機構的獎勵計劃�。
技巧2: 一開始就創(chuàng)建數(shù)據(jù)分析的演示文稿 (可能的布局和結構)
我一直這樣做并且受益匪淺��。把分析演示稿的框架搭起來應該是項目啟動后的第一件事��。這聽起來或許有悖常理����,然而一旦你養(yǎng)成這個習慣,就可以節(jié)省時間�����。
如何搭框架呢����?
你可以用ppt����、word、或者一段話來搭框架��,形式是無關緊要的。重要的是一開始就要把所有可能情況列出來�����。例如���,如果你試圖降低壞賬沖銷率��,那么可以像下面一樣布局你的演示文稿:
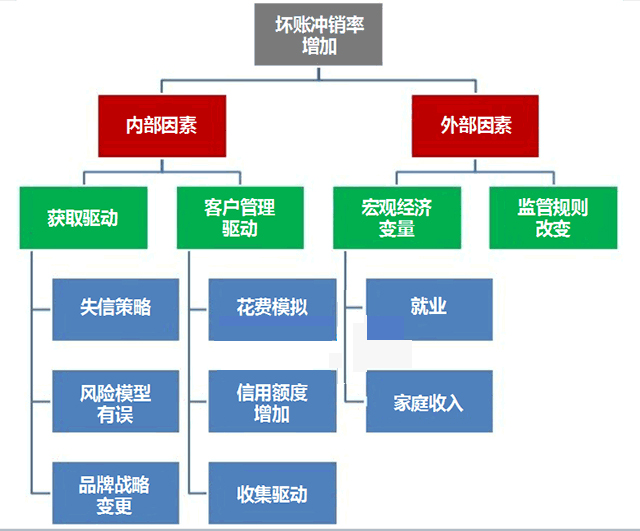
接下來�����,你可以考慮每個因素如何影響壞賬沖銷率����?例如��,由于給客戶增加了信用額度導致銀行的壞賬沖銷率增加����,你可以:
首先,確定那些信用額度沒被增加的客戶并沒有導致此次壞賬沖銷率增加�。
下一步,用一個數(shù)學公式來測量這個影響�����。
一旦你把分析中的每一個分支都考慮到了,那么你已經(jīng)為自己創(chuàng)造了一個良好的起點�����。
技巧3: 事先定義數(shù)據(jù)需求
數(shù)據(jù)需求直接源于最后的分析結果�����。如果你已經(jīng)全面地規(guī)劃了要做哪些分析��、產(chǎn)生什么結果��,那么你將知道數(shù)據(jù)需求是什么�。這里有幾個提示來幫助你:
? 試著賦予數(shù)據(jù)需求一個結構: 不單是記下變量列表,你應該分門別類地想清楚分析活動需要哪些表格�。以上面增加壞賬沖銷率為例�,你將需要客戶人口統(tǒng)計表,過往市場營銷活動統(tǒng)計表�����,客戶過去 12 個月的交易記錄�,銀行信貸政策變更文件等資料���。
? 收集你可能需要的所有數(shù)據(jù): 即使你不是 100%肯定是否需要所有的變量,在這一階段你應該把所有數(shù)據(jù)都收集起來��。這樣做工作量大一些�,但是與在以后的環(huán)節(jié)增加變量收集數(shù)據(jù)相比,還是更有效率一些���。
? 定義您感興趣的數(shù)據(jù)的時間區(qū)間���。
技巧 4: 確保你的分析可重現(xiàn)
這個提示聽起來可能很簡單——但初學者和高級分析人員都難以把握好這一點。初學者會用Excel執(zhí)行每一步活動��,其中包括復制粘貼數(shù)據(jù)��。對于高級用戶����,任何通過命令行界面完成的工作都可能不可重現(xiàn)。
同樣����,使用記事本(notebook)時需要格外小心。你應該克制自己修改以前的步驟��,尤其是在前面的數(shù)據(jù)已經(jīng)被后面的步驟使用的情況下。記事本在維護這種涉及前后數(shù)據(jù)勾稽關系的數(shù)據(jù)流方面表現(xiàn)地非常強大���。但是如果記事本中沒維護這種數(shù)據(jù)流����,它也會非常沒用���。
技巧5: 建標準代碼庫
沒必要為簡單的操作一次又一次重寫代碼��。它不僅浪費時間���,還可能會造成語法錯誤。另一個竅門是創(chuàng)建常見操作的標準代碼庫并在整個團隊中共享��。
這將不僅確保整個團隊使用相同的代碼����,而且也使他們更有效率。
技巧6: 建中間數(shù)據(jù)集市
很多的時候��,你會反復需要同一批信息�����。例如���,你將在多個分析和報告中用到所有客戶信用卡消費記錄�����。雖然你可以每次都從交易記錄表中提取��,但是創(chuàng)建包含這些表的中間數(shù)據(jù)集市�,可以有效節(jié)省時間和精力�。同樣,市場營銷活動的匯總表也沒必要每次都查詢提取一次��。
技巧7: 使用保留樣本和交叉驗證防止過度擬合
很多初學者低估了保留樣本和交叉驗證的強大�����。很多人傾向于認為只要訓練集足夠大����,幾乎不會過擬合,因此沒必要交叉驗證或保留樣本����。
有這種想法����,往往會在最后出岔子��。不單我這樣說——可以看一下Kaggle上任意競賽公開或非公開的排行榜���。你會發(fā)現(xiàn)前十名中有些人不再過擬合時他們的排名就不再下降了���。你可以想象這些都是高級數(shù)據(jù)科學家。
技巧8: 集中一段時間工作并且有規(guī)律地休息
對于我來說�,最佳的工作狀態(tài)是集中利用2-3小時解決一個問題或項目。作為一名數(shù)據(jù)科學家��,你很難同時完成多項任務���。你需要以自己的最佳狀態(tài)對待一個單獨的問題����。對于我來說����,2-3 小時的時間窗口最有效率�,你可以依據(jù)個人情況自行設定��。
后記
上面這些就是我提高工作效率的一些方法���。我不強調(diào)非要第一次就把事情做好,但是你必須養(yǎng)成每一次都能做好的習慣——這樣你才能成為一個專業(yè)的數(shù)據(jù)科學家�。
你有什么提高工作效率的好方法嗎?有的話請在下面的評論中留言�����。
原文標題:8 Productivity hacks for Data Scientists & Business Analysts
翻譯筆記
1�、catch up with sb.還特指同某人恢復聯(lián)系,相當于become current with what’s going on in someone’s life when you haven’t been in touch for a while
所以這句話的意思是說 “再次聯(lián)絡到(碰到/遇到)你真好”,特指有段時間和你沒有見面或者聯(lián)絡時候的說法。
2���、productivity killers�����,生產(chǎn)效率殺手����,降低生產(chǎn)效率的因素�����,阻礙提高生產(chǎn)效率的因素。
3�、壞賬沖銷率,信用卡行業(yè)的重要指標��,每月發(fā)生壞賬除以當月初信用卡應收款總額的年化比例�����,主要用于衡量資產(chǎn)的信用水平�����。
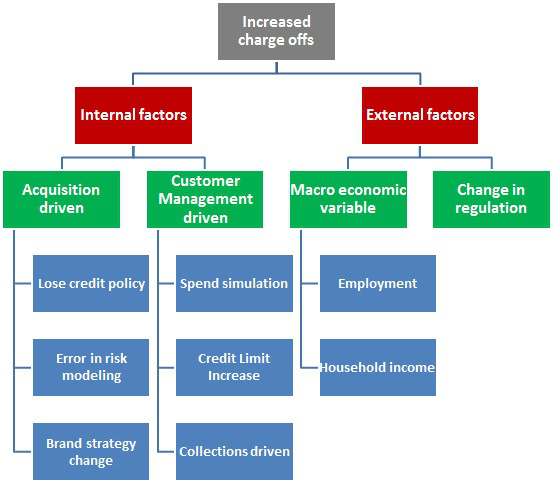
4����、插圖中Brand strategy change,品牌戰(zhàn)略變更可能會導致壞賬沖銷率增加�����。例如����,當采用競爭品牌或者邊際品牌戰(zhàn)略時可能會導致壞賬沖銷率的增加��。
5�、品牌戰(zhàn)略:
-
形象品牌����。在品牌競爭中形象品牌能有效地贏得公眾的信賴�����,形成良好的“口碑”效應�,對累積、提升品牌資本有著極為重要的作用�����,能促進企業(yè)其它品牌的推廣���。例如����,雀巢公司的“雀巢”作為母品牌就是形象品牌�����,它有力地推動了其眾多的子品牌。因此�����,企業(yè)的品牌經(jīng)營戰(zhàn)略不能沒有形象品牌�����。
-
競爭品牌,通常是針對市場上同類產(chǎn)品而推出的,它將通過其特殊的市場定位如技術上的�����、價格上的或服務上的特色撕開競爭對手的防線,或開辟嶄新的目標市場�����。顯然���,競爭品牌的主要目的就是為企業(yè)爭奪更多的市場份額��,創(chuàng)立企業(yè)的競爭優(yōu)勢��。這種類型的品牌也許現(xiàn)在并不能為企業(yè)帶來多少利潤�,但發(fā)展?jié)摿O大,是企業(yè)參與未來市場品牌競爭的關鍵和希望��。
-
利潤品牌�,是企業(yè)多品牌經(jīng)營的中心。利潤品牌為企業(yè)創(chuàng)造利潤是現(xiàn)代品牌經(jīng)營的重要特征��。利潤品牌一般都是企業(yè)獨特技術(企業(yè)核心競爭力)的代表��,競爭者難于在較短時間內(nèi)進入這一領域為企業(yè)創(chuàng)造很大的利潤空間����,甚至是超額利潤�。當然這類品牌如果不加以提升和改善,就有進入衰退期的可能��。
-
邊際品牌�,是企業(yè)多品牌經(jīng)營戰(zhàn)略的必要補充。邊際品牌不是企業(yè)的形象品牌��、競爭品牌��,從其表象看難于創(chuàng)造利潤但因其具有一定的客戶基礎��,不像其它品牌那樣需要高額的投資�。因此����,即使該品牌的銷售額停滯不前或緩慢下降�����,仍有一批忠誠的消費者不會放棄這類品牌��。邊際品牌的作用就是創(chuàng)造盈余資源�,并為企業(yè)的競爭品牌、形象品牌和利潤品牌提供資源支持�,為沖銷企業(yè)的固定經(jīng)營費用做出貢獻。
6�、插圖中“Acquisition driven”,acquisition意為(1)(對公司的)收購��,并購����;(2)(圖書館通過采購、交換贈閱等)圖書資料的獲得�;獲得的書籍(或報刊、雜志)�����;(3)(知識、技能等的)獲得����,習得。例如��,data acquisition指數(shù)據(jù)采集����。
7、插圖中“Spend simulation”����,譯者在此只依文解義的翻成了“花費模擬”��。在ask.com搜索引擎中�,沒有相應內(nèi)容,網(wǎng)站提示是否搜索spent simulation����,spent是一個互動游戲,由一個幫助流浪者和貧窮者的公益組織發(fā)起��,玩家用1000美元生活一個月模擬貧窮的生活狀態(tài)����,玩家參與互動游戲時會面臨很多選擇��,比如Cover the minimum on your credit cards or pay the rent?支付信用卡還是支付房租���。這個游戲從2011年2月第一次舉辦到2014年7月已經(jīng)有200萬人在218個國家玩超過400萬次。如果客戶參與這類活動���,可能會導致信用卡超期未付���。參考鏈接:http://umdurham.org/ https://en.wikipedia.org/wiki/SPENT_(online_game)#cite_note-2
8、data requirement�����,數(shù)據(jù)需求����,與之相關的還有Market requirement,Production requirement�,其中產(chǎn)品需求與數(shù)據(jù)需求關系緊密。因為數(shù)據(jù)需求隨著產(chǎn)品業(yè)務邏輯展開��。要收集一個產(chǎn)品的數(shù)據(jù),首先需要了解產(chǎn)品業(yè)務邏輯��,例如功能之間的交互關系以及單一功能的業(yè)務邏輯�����。其次將業(yè)務邏輯節(jié)點化��,識別出重要節(jié)點并列出優(yōu)先級���。再次將節(jié)點化的業(yè)務代碼化���,主要將列出的重要節(jié)點(需要統(tǒng)計的節(jié)點)添加統(tǒng)計事件和統(tǒng)計參數(shù)。最后形成數(shù)據(jù)需求文檔�����。
9���、more often than not,往往����。
讀后感
譯完這篇文章,我感覺數(shù)據(jù)分析人員可以從兩個方面借鑒經(jīng)驗,一是從傳統(tǒng)管理咨詢行業(yè)借力���,DA需要具備的能力包括傳統(tǒng)咨詢行業(yè)解決問題的能力加上數(shù)據(jù)處理技能��。比如本文的第二點提示��,類似于咨詢行業(yè)的重要方法——結構化思維����?��?梢詤⒖及虐爬っ魍芯帉懙摹禠ogic in writing, thinking and problem solving》(中文譯名:金字塔原理——思考���、表達和解決問題的邏輯),這本書是麥肯錫的經(jīng)典培訓教材���,介紹了很多實用的方法����,幫助讀者在思考表達時重點突出����、邏輯清晰�����、主次分明�����。二是可以從傳統(tǒng)的數(shù)據(jù)資源規(guī)劃中得到啟發(fā)�。本文第三點提示��,如何確定數(shù)據(jù)需求���,恰恰可以參照傳統(tǒng)數(shù)據(jù)資源規(guī)劃中從業(yè)務需求得到數(shù)據(jù)需求�����,并對業(yè)務和數(shù)據(jù)進行建模的系統(tǒng)化方法�,具體可以參考高復先教授的《信息資源規(guī)劃:信息化建設基礎工程》���。
本文最后提到工作和休息�,這點因人而異�。我覺得需要關注以下幾點:
一是評估綜合效率�����。一周有一兩次效率特高,但綜合效率或許不如一周都保持一個平穩(wěn)的節(jié)奏���?�?梢試L試用番茄鐘這種時間管理工具來量化分析一下自己的情況���;
二是調(diào)整生活習慣。數(shù)據(jù)分析工作需要飽滿的精力�����,影響精力的因素很多�,比如暴飲暴食可能就會帶來負面影響。
三是關注呼吸,如果我們高效率的時候身心舒暢�,呼吸自然��,那么這種狀態(tài)是可持續(xù)的。如果精力集中時,經(jīng)常屏住呼吸��,這種方式更傾向于消耗����。冥想和正念訓練或許會有幫助����。
工作有如跑馬拉松�,有些人的目標不為跑得快只為跑得年頭久����,希望60歲依然能去跑����,這類人對控制心率的需求大過提高速度。有些人希望盡快提高成績���,去沖刺幾個重要賽事,因而自愿承擔自由基增加的代價��。做數(shù)據(jù)分析也一樣,設定怎樣的目標���,那就怎樣去奔跑吧。
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330