優(yōu)化網(wǎng)站信息架構(gòu)
如何讓用戶更方便快捷地在網(wǎng)站上尋找到他們需要的信息��,當(dāng)然不能脫離博客的主題——網(wǎng)站數(shù)據(jù)分析����,所以這里主要介紹的是如何通過網(wǎng)站分析來優(yōu)化網(wǎng)站�����,實(shí)現(xiàn)用戶對信息的快速獲取���,首先介紹的是網(wǎng)站的信息架構(gòu)�。
關(guān)于信息架構(gòu)����,網(wǎng)站設(shè)計(jì)的同學(xué)才是專家,我在這里只是班門弄斧��,根據(jù)大學(xué)里面閱讀的信息架構(gòu)類文獻(xiàn)資料的一些殘存的記憶,再加上這幾天臨時(shí)抱佛腳的簡單溫習(xí)����,在這里表述一下我的一點(diǎn)拙見。
信息架構(gòu)的定義
根據(jù)維基百科的定義�����,信息架構(gòu)(Information Architecture�����,簡稱IA)是在信息環(huán)境中�����,影響系統(tǒng)組織����、導(dǎo)覽、及分類標(biāo)簽的組合結(jié)構(gòu)�����。它是基于信息架構(gòu)方法論��,并運(yùn)用計(jì)算機(jī)技術(shù)管理和組織信息的一個(gè)專門學(xué)科。信息架構(gòu)并非一開始就應(yīng)用于網(wǎng)站設(shè)計(jì)����,其起源于情報(bào)科學(xué),最初應(yīng)該是用于圖書館等地方的信息組織和信息檢索的���。
《用戶體驗(yàn)的要素——以用戶為中心的WEB設(shè)計(jì)》這本書中對信息架構(gòu)的定義基于網(wǎng)站設(shè)計(jì):信息架構(gòu)著重于設(shè)計(jì)組織分類和導(dǎo)航的結(jié)構(gòu)�,從而讓用戶可以提高效率���、有效地瀏覽網(wǎng)站的內(nèi)容。
具體的就不再多說的�����,可能各有各的理解�,這里直接來看一個(gè)實(shí)例——Wordpress的信息架構(gòu)模式:
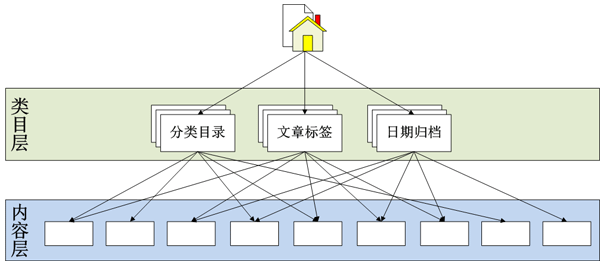
當(dāng)然,上面這個(gè)圖只能展示一個(gè)大體的網(wǎng)站信息架構(gòu)���,中間的類目層也許不止一層���,會有大類、子類�����、子子類……底層可以是文章也可能是頁面或者一些其他的具體內(nèi)容。而網(wǎng)站的內(nèi)部關(guān)系也往往因?yàn)槿只蚓植繉?dǎo)航����、網(wǎng)站內(nèi)鏈和內(nèi)容關(guān)聯(lián)等功能的存在而復(fù)雜的多,圖上的箭頭也會密集很多�,但我們無需羅列所有內(nèi)容間的關(guān)系,關(guān)鍵是在理清基本的結(jié)構(gòu)���。
信息架構(gòu)的類型
還是參考《用戶體驗(yàn)的要素——以用戶為中心的WEB設(shè)計(jì)》中對信息架構(gòu)的幾個(gè)分類:
層次結(jié)構(gòu)(Hierarchical Structure)
也叫樹形結(jié)構(gòu)����,是最常見的網(wǎng)站信息架構(gòu)模式���,上面舉例的Wordpress的信息架構(gòu)就是典型的層次結(jié)構(gòu)�����。樹形結(jié)構(gòu)中箭頭的方向不一定是自上而下的���,也可能是自下而上或者是雙向的,而內(nèi)容層之間也會因?yàn)橐恍╆P(guān)聯(lián)鏈接的存在而存在同層次間的指向箭頭。
矩陣結(jié)構(gòu)(Matrix Structure)
矩陣結(jié)構(gòu)比較注重“維”的概念�����,即從多維的角度來檢索信息��,如時(shí)間���、地域���、內(nèi)容分類等,典型的應(yīng)用就是內(nèi)容管理系統(tǒng)(CMS)網(wǎng)站或者電子商務(wù)類網(wǎng)站�,比如你瀏覽豆瓣的電影時(shí)可以篩選:2010年—美國—科幻���,也許這個(gè)時(shí)候《鋼鐵俠2》就呈現(xiàn)在你面前了�����。
線性結(jié)構(gòu)(Sequential Structure)
看到線性結(jié)構(gòu)也許你馬上會想到面包屑�,它將網(wǎng)站中最重要的一個(gè)信息架構(gòu)路線展現(xiàn)了出來�����,即使它無法為你提供你在網(wǎng)站上的平面坐標(biāo)��,但至少它顯示了你現(xiàn)在正處于關(guān)鍵線路的哪個(gè)點(diǎn)上;當(dāng)然����,網(wǎng)站的一些關(guān)鍵路徑一般也是按照線性結(jié)構(gòu)涉及的,比如用戶注冊流程或電子商務(wù)網(wǎng)站的購買流程等�。
網(wǎng)站分析與信息架構(gòu)
根據(jù)網(wǎng)站業(yè)務(wù)模式的不同,可以選擇適合自己網(wǎng)站的信息架構(gòu)的模式�����,無論是上面的哪種信息架構(gòu)模式�����,只要設(shè)計(jì)和運(yùn)用合理����,用戶便能夠在你的網(wǎng)站上以最方便的形式、最快的速度找到他們需要的信息�����。
但當(dāng)我瀏覽某些網(wǎng)站時(shí)�����,有時(shí)真的會讓我感覺到“找不到北”,結(jié)果就是直接關(guān)閉該頁面�,如果不希望讓已經(jīng)進(jìn)入了你的網(wǎng)站的用戶輕易地離開,網(wǎng)站信息架構(gòu)的好壞將直接影響網(wǎng)站的用戶體驗(yàn)�����。所以我們需要通過一些方法來檢驗(yàn)網(wǎng)站的信息架構(gòu)是否滿足用戶的信息檢索的需求�����。
1.嘗試整理出類似上面例子中的網(wǎng)站信息架構(gòu)圖
這個(gè)是最簡單最直觀的方法����,如果你的網(wǎng)站信息架構(gòu)足夠清晰,那么畫出這樣的圖對你來說也絕非難事��;而當(dāng)網(wǎng)站的應(yīng)用比較復(fù)雜����、內(nèi)容比較寬泛����,那么可能要整理出網(wǎng)站的整體信息架構(gòu)就會相對困難,但我相信一個(gè)設(shè)計(jì)優(yōu)秀的網(wǎng)站只要稍加整理,大體的信息架構(gòu)圖還是畫得出來的�����;而當(dāng)你絞盡腦汁就是理不清你的網(wǎng)站的信息架構(gòu)的頭緒的時(shí)候�,那么說明你的網(wǎng)站需要優(yōu)化了。
2.通過網(wǎng)站分析的方法驗(yàn)證信息架構(gòu)的合理性
本文的副標(biāo)題是“讓用戶更容易地找到需要的信息”����,所以我們需要分析用戶是否能夠在你的網(wǎng)站上方便快捷地找到他們需要的信息,這里推薦一種方法——尋找網(wǎng)站中的迷失用戶(Lost Visits)��。
在一個(gè)合理的信息架構(gòu)下�����,大多數(shù)的用戶是不會在你的網(wǎng)站上迷路的�����;反之�,混亂的信息架構(gòu)會導(dǎo)致大量的用戶迷失方向,就像是進(jìn)入了一個(gè)巨大的迷宮�����。那么如何尋找這些迷失用戶?我們可以先分析下這類用戶的行為��,最明顯特征的就是:連續(xù)點(diǎn)擊好幾個(gè)頁面���,每個(gè)頁面都只是初步瀏覽(因?yàn)闆]有找到他們需要的信息)就轉(zhuǎn)到另外的頁面或直接離開了�����。所以我們可以借助網(wǎng)站分析中的兩個(gè)度量:
瀏覽頁面數(shù)(Depth of Visit):一次訪問中用戶總的瀏覽頁面數(shù)�����;
頁面平均停留時(shí)間(Avg. Time on Page):一次瀏覽中用戶在每個(gè)頁面的平均停留時(shí)間��,即該次訪問總停留時(shí)間(Time on Site)/該次訪問頁面數(shù)(Depth of Visit)�����。
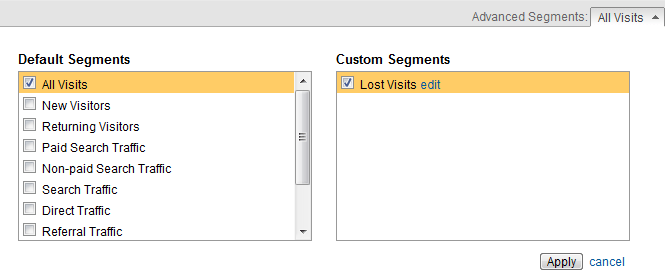
我們可以用戶細(xì)分的方法把那些瀏覽頁面數(shù)較多�,但頁面平均停留時(shí)間較短的用戶瀏覽看作是迷失用戶�����,具體的數(shù)值可以根據(jù)網(wǎng)站自身的特點(diǎn)進(jìn)行定義��,比如我定義我的博客中瀏覽頁面數(shù)大于等于4��,而頁面平均停留時(shí)間小于等于15秒的Visits為迷失用戶的瀏覽行為��,我們可以借助Google Analytics中的高級群組(Advanced Segment)來區(qū)分出這類用戶��,關(guān)于如何使用Google Analytics的高級群組功能��,可以參考藍(lán)鯨的文章——Google Analytics功能篇—高級群組���,如下圖:
當(dāng)然�����,你可能會說這種用戶區(qū)分的方法不準(zhǔn)確�����,這類用戶不一定就是迷失用戶�����,也有可能他們確實(shí)找到并瀏覽了具體內(nèi)容�����,但因?yàn)閮?nèi)容不夠吸引人或者其他原因而馬上離開了該頁面���。所以這里用高級群組劃分出來的這類Visits的數(shù)量不能看作是迷失用戶的一個(gè)絕對數(shù)值����,我們只能認(rèn)為里面的大部分Visits都是迷失用戶�����,而不排除存在某些另類�。所以更合理的方法是通過計(jì)算這類Visits占網(wǎng)站總Visits的比例情況來分析網(wǎng)站的信息架構(gòu)到底是否合理,我們可以在Google Analytics上面選取網(wǎng)站的All Visits和Lost Visits進(jìn)行比例和趨勢的比較��,如下圖:

網(wǎng)站中迷失用戶瀏覽的所占比例只需通過Lost Visits/All Visits就可以計(jì)算得到���,但這個(gè)時(shí)候你還是無法根據(jù)這個(gè)計(jì)算結(jié)果來評判網(wǎng)站的信息架構(gòu)到底是好是壞�,因?yàn)檫€缺少一個(gè)基準(zhǔn)線(Benchmark)或者說是評判標(biāo)準(zhǔn)����。在Google Analytics上面的Visitors標(biāo)簽下,提供了“Sites of similar size”的基準(zhǔn)比較(Benchmarking)�����,你可以選擇與你的網(wǎng)站相似類型的網(wǎng)站作為基準(zhǔn)線進(jìn)行數(shù)據(jù)比較����,這的確是個(gè)很好的參考,因?yàn)橥ㄟ^比較能夠更加明確你的網(wǎng)站在同類型網(wǎng)站中的優(yōu)勢和劣勢�����,為網(wǎng)站優(yōu)化指明方向��。GA借助其強(qiáng)大的數(shù)據(jù)平臺可以為我們提供基準(zhǔn)線�,但也許對于上面這個(gè)例子會顯得無能為力,這個(gè)時(shí)候需要我們理性地自己去選擇一個(gè)合適的基準(zhǔn)線����,比如我的博客目前類目和內(nèi)容都還比較少���,那么我可能會定義我的網(wǎng)站的迷失用戶比例應(yīng)該控制在1%以下���;但如果對于一個(gè)應(yīng)用和內(nèi)容比較復(fù)雜的網(wǎng)站,那么基準(zhǔn)線顯然會需要定得更高一點(diǎn)�����。一旦某段時(shí)間的數(shù)據(jù)越過了基準(zhǔn)線,就需要關(guān)注一下網(wǎng)站的信息架構(gòu)是不是在趨于混亂了�,是不是該進(jìn)行一下整理和優(yōu)化了。
總之�,一個(gè)好的信息架構(gòu)能夠幫助用戶更容易地找到他們需要的信息,從而有效地提升網(wǎng)站的用戶體驗(yàn)��,所以�,嘗試著去優(yōu)化下你的網(wǎng)站的信息架構(gòu)。如果你有更好的方法能夠有效地檢驗(yàn)網(wǎng)站的信息架構(gòu)的優(yōu)劣�����,或者能夠明確地分析得到網(wǎng)站信息架構(gòu)的哪些細(xì)節(jié)上存在缺陷��,希望能與我交流���,我期待網(wǎng)站分析方法在優(yōu)化網(wǎng)站信息架構(gòu)方面的更多的應(yīng)用��。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試���,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�;
? 想學(xué)習(xí)CDA考試教材�����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫���,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量��,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330