大數(shù)據從無人談及,到現(xiàn)在的大肆炒作����,到底什么才是大數(shù)據,對于數(shù)據分析師���,它有意味著什么�����?本文將為您解答���。
以下為譯文:
我用Google搜索了一下“Big Data”,得到了19,600,000個結果……而使用同樣的詞語,在兩年前你幾乎搜索不到什么內容����,而現(xiàn)在大數(shù)據的內容被大肆炒作,內容多得讓人眼花繚亂�����。而這些內容主要是來自IBM����、麥肯錫和O’Reilly ��,大多數(shù)文章都是基于營銷目的的夸夸其談���,對真實的情況并不了解���,有些觀點甚至是完全錯誤的。我問自己…… 大數(shù)據之于數(shù)據分析師���,它意味著什么呢���?
如下圖所示,谷歌趨勢顯示,與“網站分析”(web analytics)和”商業(yè)智能”(business intelligence)較為平穩(wěn)的搜索曲線相比���,“大數(shù)據”(big data)的搜索量迎來了火箭式的大幅度增長����。
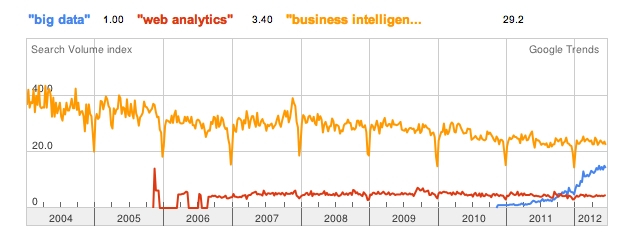
大數(shù)據 – 炒作
Gartner把“大數(shù)據”的發(fā)展階段定位在“社交電視”和“移動機器人”之間����,正向著中部期望的高峰點邁進,而現(xiàn)在是達到較為成熟的階段前的二至五年�����。這種定位有著其合理性�。各種奏唱著“大數(shù)據”頌歌的產品數(shù)量正在迅速增長,大眾媒體也進入了“大數(shù)據”主題的論辯中����,比如紐約時報的“大數(shù)據的時代“,以及一系列在福布斯上發(fā)布的題為” 大數(shù)據技術評估檢查表“的文章�。
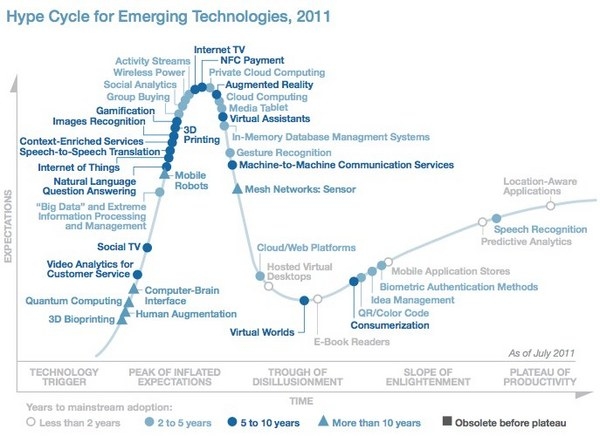
進步的一面體現(xiàn)在,大數(shù)據的概念正在促使內部組織的文化發(fā)生轉變���,對過時的“商務智能”形成挑戰(zhàn)����,并促進了“分析”意識的提升。
基于大數(shù)據的創(chuàng)新技術可以很容易地被應用到類似數(shù)據分析的各種環(huán)境中�。值得一提的是,企業(yè)組織通過應用先進的業(yè)務分析����,業(yè)務將變得更廣泛、更復雜�,價值也更高,而傳統(tǒng)的網站分析受到的關注將會有所減弱���。
大數(shù)據 – 定義
什么是“大數(shù)據”,目前并沒有統(tǒng)一的定義����。維基百科提供的定義有些拙劣,也不完整:“ 大數(shù)據���,指的是所涉及的數(shù)據量規(guī)模巨大到無法通過主流的工具��,在合理的時間內擷取���、管理����、處理���、并整理成為人們所能解讀的信息 “�。
IBM 提供了一個充分的簡單易懂的概述:
大數(shù)據有以下三個特點:大批量(Volume)��、高速度(Velocity)和多樣化(Variety) ��。
-
大批量 – 大數(shù)據體積龐大��。企業(yè)里到處充斥著數(shù)據���,信息動不動就達到了TB級���,甚至是PB級。
-
高速度 – 大數(shù)據通常對時間敏感�����。為了最大限度地發(fā)揮其業(yè)務價值�,大數(shù)據必須及時使用起來。
-
多樣化 – 大數(shù)據超越了結構化數(shù)據���,它包括所有種類的非結構化數(shù)據��,如文本���、音頻��、視頻��、點擊流��、日志文件等等都可以是大數(shù)據的組成部分���。
MSDN的布萊恩·史密斯在IBM的基礎上增加了第四點:
-
變異性 – 數(shù)據可以使用不同的定義方式來進行解釋。不同的問題需要不同的闡釋�����。
大數(shù)據 – 技術角度
大數(shù)據包括了以下幾個方面:數(shù)據采集���、存儲、搜索����、共享����、分析和可視化�,而這些步驟在商務智能中也可以找到。在皮特·沃登的“ 大數(shù)據詞匯表 “中����,囊括了60種創(chuàng)新技術,并提供了相關的大數(shù)據技術概念的簡要概述�����。
獲取 :數(shù)據的獲取包括了各種數(shù)據源���、內部或外部的���、結構化或非結構化的數(shù)據?�!按蠖鄶?shù)公共數(shù)據源的結構都不清晰����,充滿了噪音,而且還很難獲得��。” 技術: Google Refine����、Needlebase、ScraperWiki���、BloomReach ��。
序列化 :“你在努力把你的數(shù)據變成有用的東西�����,而這些數(shù)據會在不同的系統(tǒng)間傳遞�,并可能存儲在不同節(jié)點的文件中�。這些操作都需要某種序列化,因為數(shù)據處理的不同階段可能需要不同的語言和API���。當你在處理非常大量的記錄時�����,該如何表示和存儲數(shù)據,你所做的選擇對你的存儲要求和性能將產生巨大影響��。 技術: JSON、BSON��、Thrift�����、Avro��、Google Protocol Buffers �。
存儲 :“大規(guī)模的數(shù)據處理操作使用了全新的方式來訪問數(shù)據,而傳統(tǒng)的文件系統(tǒng)并不適用��。它要求數(shù)據能即時大批量的讀取和寫入����。效率優(yōu)先,而那些有助于組織信息的易于用戶使用的目錄功能可能就顯得沒那么重要��。因為數(shù)據的規(guī)模巨大��,這也意味著它需要被存儲在多臺分布式計算機上����。“ 技術: Amazon S3、Hadoop分布式文件系統(tǒng) ��。
服務器 :“云”是一個非常模糊的術語���,我們可能對它所表示的內容并不很了解�����,但目前在計算資源的可用性方面已有了真正突破性的發(fā)展���。以前我們都習慣于購買或長期租賃實體機器,而現(xiàn)在更常見的情況是直接租用正運行著虛擬實例的計算機來作為服務器���。這樣供應商可以以較為經濟的價格為用戶提供一些短期的靈活的機器租賃服務��,這對于很多數(shù)據處理應用程序來說這是再理想不過的事情�。因為有了能夠快速啟動的大型集群���,這樣使用非常小的預算處理非常大的數(shù)據問題就可能成為現(xiàn)實�����?��!?技術: Amazon EC2、Google App Engine�、Amazon Elastic Beanstalk、Heroku ����。
NoSQL :在IT行為中,NoSQL(實際上意味著“不只是SQL”)是一類廣泛的數(shù)據庫管理系統(tǒng)�,它與關系型數(shù)據庫管理系統(tǒng)(RDBMS)的傳統(tǒng)模型有著一些顯著不同,而最重要的是����,它們并不使用SQL作為其主要的查詢語言。這些數(shù)據存儲可能并不需要固定的表格模式����,通常不支持連接操作,也可能無法提供完整的ACID(原子性—Atomicity�����、一致性—Consistency�、隔離性—Isolation、持久性—Durability)的保證�����,而且通常從水平方向擴展(即通過添加新的服務器以分攤工作量,而不是升級現(xiàn)有的服務器)���。 技術: Apache Hadoop��、Apache Casandra���、MongoDB、Apache CouchDB�����、Redis�����、BigTable��、HBase����、Hypertable、Voldemort �����。
MapReduce :“在傳統(tǒng)的關系數(shù)據庫的世界里,在信息被加載到存儲器后���,所有的數(shù)據處理工作才能開始,使用的是一門專用的基于高度結構化和優(yōu)化過的數(shù)據結構的查詢語言��。這種方法由Google首創(chuàng)�����,并已被許多網絡公司所采用�����,創(chuàng)建一個讀取和寫入任意文件格式的管道�����,中間的結果橫跨多臺計算機進行計算�,以文件的形式在不同的階段之間傳送?���!?技術: Hadoop和Hive�、Pig�����、Cascading���、Cascalog�、mrjob��、Caffeine�����、S4�、MapR、Acunu��、Flume�����、Kafka��、Azkaban����、Oozie�、Greenplum ����。
處理 :“從數(shù)據的海洋中獲取你想要的簡潔而有價值的信息是一件挑戰(zhàn)性的事情,不過現(xiàn)在的數(shù)據系統(tǒng)已經有了長足的進步��,這可以幫助你把數(shù)據集到轉變成為清晰而有意義的內容�����。在數(shù)據處理的過程中你會遇上很多不同的障礙�,你需要使用到的工具包括了快速統(tǒng)計分析系統(tǒng)以及一些支持性的助手程序����。“ 技術: R���、Yahoo! Pipes���、Mechanical Turk、Solr/ Lucene�、ElasticSearch�、Datameer�����、Bigsheets����、Tinkerpop 。 初創(chuàng)公司: Continuuity��、Wibidata�、Platfora 。
自然語言處理 :“自然語言處理(NLP)……重點是利用好凌亂的�、由人類創(chuàng)造的文本并提取有意義的信息?��!?技術: 自然語言工具包Natural Language Toolkit�、Apache OpenNLP��、Boilerpipe�����、OpenCalais�。
機器學習 :“機器學習系統(tǒng)根據數(shù)據作出自動化決策����。系統(tǒng)利用訓練的信息來處理后續(xù)的數(shù)據點���,自動生成類似于推薦或分組的輸出結果����。當你想把一次性的數(shù)據分析轉化成生產服務的行為�����,而且這些行為在沒有監(jiān)督的情況下也能根據新的數(shù)據執(zhí)行類似的動作���,這些系統(tǒng)就顯得特別有用。亞馬遜的產品推薦功能就是這其中最著名的一項技術應用�����?���!?技術: WEKA、Mahout���、scikits.learn�����、SkyTree ���。
可視化 :“要把數(shù)據的含義表達出來��,一個最好的方法是從數(shù)據中提取出重要的組成部分����,然后以圖形的方式呈現(xiàn)出來����。這樣就可以讓大家快速探索其中的規(guī)律而不是僅僅籠統(tǒng)的展示原始數(shù)值,并以此簡潔地向最終用戶展示易于理解的結果���。隨著Web技術的發(fā)展���,靜態(tài)圖像甚至交互式對象都可以用于數(shù)據可視化的工作中,展示和探索之間的界限已經模糊���?���!?技術: GraphViz、Processing�、Protovis、Google Fusion Tables���、Tableau ���。
大數(shù)據 – 挑戰(zhàn)
最近舉行的世界經濟論壇也在討論大數(shù)據,會議確定了一些大數(shù)據應用的機會���,但在數(shù)據共用的道路上仍有兩個主要的問題和障礙��。
1.隱私和安全
正如Craig & Ludloff在“隱私和大數(shù)據“的專題中所提到的�,一個難以避免的危機正在形成�����,大數(shù)據將瓦解并沖擊著我們生活的很多方面���,這些方面包括私隱權、政府或國際法規(guī)、隱私權的安全性和商業(yè)化���、市場營銷和廣告……
試想一下歐盟的cookie法規(guī)�����,或是這樣的一個簡單情景�,一個公司可以輕易地在社交網絡上收集各種信息并建立完整的資料檔案�,這其中包括了人們詳細的電子郵箱地址、姓名�����、地理位置�����、興趣等等��。這真是一件嚇人的事情�!
2.人力資本
麥肯錫全球研究所的報告顯示 ,美國的數(shù)據人才的缺口非常大�,還將需要140,000到190,000個有著“深度分析”專業(yè)技能的工作人員和1.500個精通數(shù)據的經理。
尋找熟練的“網站分析”人力資源是一個挑戰(zhàn)��,另外,要培養(yǎng)自己的真正擁有分析技能的人員���,需要學習的內容很多�,這無疑是另一個大挑戰(zhàn)�����。
大數(shù)據 – 價值創(chuàng)造
很多大數(shù)據的內容都提及了價值創(chuàng)造����、競爭優(yōu)勢和生產率的提高。要利用大數(shù)據創(chuàng)造價值�,主要有以下六種方式。
-
透明度 :讓利益相關人員都可以及時快速訪問數(shù)據��。
-
實驗 :啟用實驗以發(fā)現(xiàn)需求�,展示不同的變體并提升效果。隨著越來越多的交易數(shù)據以數(shù)字形式存儲���,企業(yè)可以收集更準確�、更詳細的績效數(shù)據�。
-
細分 :更精細的種群細分���,可以帶來不同的自定義行為���。
-
決策支持 :使用自動化算法替換/支持人類決策��,這可以改善決策�����,減少風險����,并發(fā)掘被隱藏的但有價值的見解�����。
-
創(chuàng)新 :大數(shù)據有助于企業(yè)創(chuàng)造出新的產品和服務��,或提升現(xiàn)有的產品和服務���,發(fā)明新的商業(yè)模式或完善原來的商業(yè)模式���。
-
工業(yè)領域的增長 :有了足夠的和經過適當培訓的人力資源,那些重要的成果才會成為現(xiàn)實并產生價值�����。
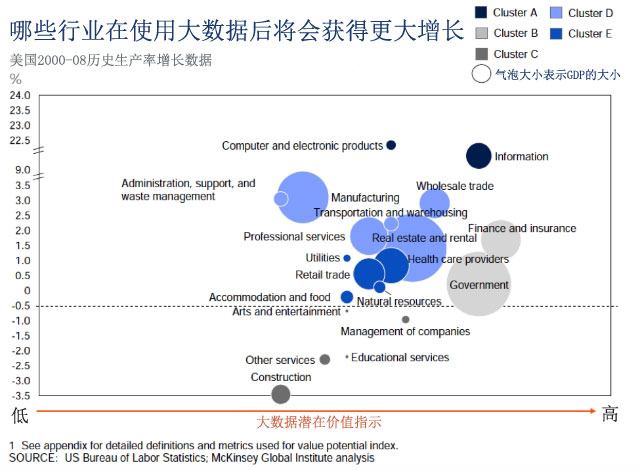
數(shù)據分析的機會領域
當“網站分析”發(fā)展到“數(shù)據智能“,毫無疑問�����,數(shù)據分析人員也工作也應該發(fā)生一些轉變�,過去的工作主要是以網站為中心并制定渠道的具體戰(zhàn)術,而在將來則需要負責更具戰(zhàn)略性的�����、面向業(yè)務和(大)數(shù)據專業(yè)知識的工作�。
數(shù)據分析師的主要關注點不應該是較低層的基礎設施和工具開發(fā)。以下幾點是數(shù)據分析的機會領域:
處理 :掌握正確的工具以便可以在不同條件下(不同的數(shù)據集��、不同的業(yè)務環(huán)境等)進行高效的分析�����。目前網站分析專家們最常用的工具無疑是各類網站分析工具��,大多數(shù)人并不熟悉商業(yè)智能和統(tǒng)計分析工具如Tableau����、SAS�、Cognos等的使用���。擁有這些工具的專業(yè)技能將對數(shù)據分析人員的發(fā)展大有好處。
NLP:學習非結構化數(shù)據分析的專業(yè)技能���,比如社交媒體��、呼叫中心日志和郵件的數(shù)據多為非結構化數(shù)據���。從數(shù)據處理的角度來看,在這個行業(yè)中我們的目標應該是確定和掌握一些最合適的分析方法和工具���,無論是社會化媒體情感分析還是一些更復雜的平臺��。
可視化 :掌握儀表板的展示技能����,或者寬泛點來說�,掌握數(shù)據可視化的技術是擺在數(shù)據分析師面前一個明顯的機會(注:不要把數(shù)據可視化與現(xiàn)在網絡營銷中常用的“信息圖”infographics相混淆)。
行動計劃
在大數(shù)時代���,其中一個最大的挑戰(zhàn)將是滿足需求和技術資源的供給���。當前的“網站分析”的基礎普遍并不足夠成熟以支持真正的大數(shù)據的使用����,填補技能差距���,越來越多的“網站分析師”將成長為“數(shù)據分析師”�����。
CDA數(shù)據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330