大數(shù)據(jù)研究常用軟件工具與應用場景
如今����,大數(shù)據(jù)日益成為研究行業(yè)的重要研究目標����。面對其高數(shù)據(jù)量�、多維度與異構化的特點,以及分析方法思路的擴展����,傳統(tǒng)統(tǒng)計工具已經(jīng)難以應對。
工欲善其事�,必先利其器�。眾多新的軟件分析工具作為深入大數(shù)據(jù)洞察研究的重要助力�, 也成為數(shù)據(jù)科學家所必須掌握的知識技能。
然而�����,現(xiàn)實情況的復雜性決定了并不存在解決一切問題的終極工具��。實際研究過程中����,需要根據(jù)實際情況靈活選擇最合適的工具(甚至多種工具組合使用),才能更好的完成研究探索��。
為此�,本文針對研究人員(非技術人員)的實際情況,介紹當前大數(shù)據(jù)研究涉及的一些主要工具軟件(因為相關軟件眾多���,只介紹常用的)���,并進一步闡述其應用特點和適合的場景,以便于研究人員能有的放矢的學習和使用����。
基礎篇
傳統(tǒng)分析/商業(yè)統(tǒng)計
Excel�、SPSS�、SAS 這三者對于研究人員而言并不陌生。
Excel 作為電子表格軟件���,適合簡單統(tǒng)計(分組/求和等)需求��,由于其方便好用�,功能也能滿足很多場景需要���,所以實際成為研究人員最常用的軟件工具�����。其缺點在于功能單一����,且可處理數(shù)據(jù)規(guī)模?。ㄟ@一點讓很多研究人員尤為頭疼)�����。這兩年Excel在大數(shù)據(jù)方面(如地理可視化和網(wǎng)絡關系分析)上也作出了一些增強���,但應用能力有限���。
SPSS(SPSS Statistics)和SAS作為商業(yè)統(tǒng)計軟件����,提供研究常用的經(jīng)典統(tǒng)計分析(如回歸���、方差��、因子����、多變量分析等)處理�����。
SPSS 輕量��、易于使用�����,但功能相對較少����,適合常規(guī)基本統(tǒng)計分析
SAS 功能豐富而強大(包括繪圖能力),且支持編程擴展其分析能力�,適合復雜與高要求的統(tǒng)計性分析。
上述三個軟件在面對大數(shù)據(jù)環(huán)境出現(xiàn)了各種不適�,具體不再贅述。但這并不代表其沒有使用價值����。如果使用傳統(tǒng)研究方法論分析大數(shù)據(jù)時,海量原始數(shù)據(jù)資源經(jīng)過前期處理(如降維和統(tǒng)計匯總等)得到的中間研究結果�����,就很適合使用它們進行進一步研究�����。
數(shù)據(jù)挖掘
數(shù)據(jù)挖掘作為大數(shù)據(jù)應用的重要領域�����,在傳統(tǒng)統(tǒng)計分析基礎上����,更強調(diào)提供機器學習的方法,關注高維空間下復雜數(shù)據(jù)關聯(lián)關系和推演能力����。代表是SPSS Modeler(注意不是SPSS Statistics,其前身為Clementine)
SPSS Modeler 的統(tǒng)計功能相對有限, 主要是提供面向商業(yè)挖掘的機器學習算法(決策樹�、神經(jīng)元網(wǎng)絡、分類��、聚類和預測等)的實現(xiàn)��。同時�����,其數(shù)據(jù)預處理和結果輔助分析方面也相當方便���,這一點尤其適合商業(yè)環(huán)境下的快速挖掘����。不過就處理能力而言��,實際感覺難以應對億級以上的數(shù)據(jù)規(guī)模�。
另一個商業(yè)軟件 Matlab 也能提供大量數(shù)據(jù)挖掘的算法�����,但其特性更關注科學與工程計算領域�����。而著名的開源數(shù)據(jù)挖掘軟件Weka���,功能較少,且數(shù)據(jù)預處理和結果分析也比較麻煩����,更適合學術界或有數(shù)據(jù)預處理能力的使用者。
中級篇
1��、通用大數(shù)據(jù)可視化分析
近兩年來出現(xiàn)了許多面向大數(shù)據(jù)�、具備可視化能力的分析工具,在商業(yè)研究領域�,TableAU無疑是卓越代表。
TableAU 的優(yōu)勢主要在于支持多種大數(shù)據(jù)源/格式�,眾多的可視化圖表類型,加上拖拽式的使用方式���,上手快�,非常適合研究員使用,能夠涵蓋大部分分析研究的場景��。不過要注意��,其并不能提供經(jīng)典統(tǒng)計和機器學習算法支持���, 因此其可以替代Excel, 但不能代替統(tǒng)計和數(shù)據(jù)挖掘軟件。另外�����,就實際處理速度而言���,感覺面對較大數(shù)據(jù)(實例超過3000萬記錄)時�����,并沒有官方介紹的那么迅速���。
2 、關系分析
關系分析是大數(shù)據(jù)環(huán)境下的一個新的分析熱點(比如信息傳播圖���、社交關系網(wǎng)等)�,其本質(zhì)計算的是點之間的關聯(lián)關系。相關工具中����,適合數(shù)據(jù)研究人員的是一些可視化的輕量桌面型工具,最常用的是Gephi�����。
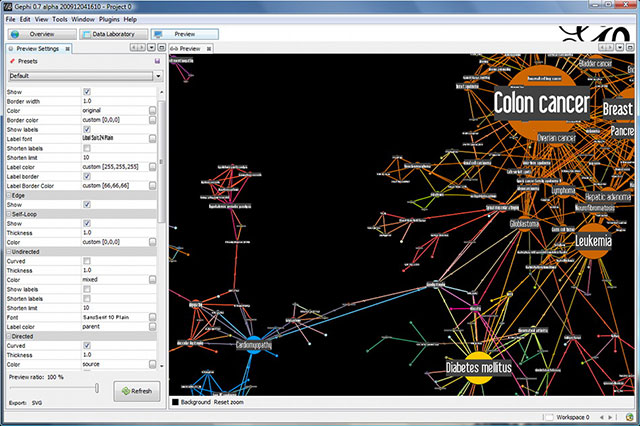
Gephi 是免費軟件�,擅長解決圖網(wǎng)絡分析的很多需求,其插件眾多�,功能強且易用。我們經(jīng)?���?吹降母鞣N社交關系/傳播譜圖, 很多都是基于其力導向圖(Force directed graph)功能生成。但由于其由java編寫���,限制了處理性能(感覺處理超過10萬節(jié)點/邊時常陷入假死)��,如分析百萬級節(jié)點(如微博熱點傳播路徑)關系時��,需先做平滑和剪枝處理����。 而要處理更大規(guī)模(如億級以上)的關系網(wǎng)絡(如社交網(wǎng)絡關系)數(shù)據(jù),則需要專門的圖關系數(shù)據(jù)庫(如GraphLab/GraphX)來支撐了��,其技術要求較高�,此處不再介紹。
3���、時空數(shù)據(jù)分析
當前很多軟件(包括TableAU)都提供了時空數(shù)據(jù)的可視化分析功能。但就使用感受來看��,其大都只適合較小規(guī)模(萬級)的可視化展示分析����,很少支持不同粒度的快速聚合探索。
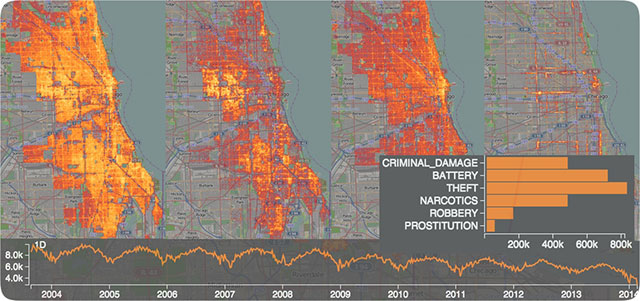
如果要分析千萬級以上的時空數(shù)據(jù)��,比如新浪微博上億用戶發(fā)文的時間與地理分布(從省到街道多級粒度的探索)時�,推薦使用 NanoCubes(http://www.nanocubes.net/)。該開源軟件可在日常的辦公電腦上提供對億級時空數(shù)據(jù)的快速展示和多級實時鉆取探索分析���。下圖是對芝加哥犯罪時間地點的分析����,網(wǎng)站有更多的實時分析的演示例子
4�、文本/非結構化分析
基于自然語言處理(NLP)的文本分析��,在非結構化內(nèi)容(如互聯(lián)網(wǎng)/社交媒體/電商評論)大數(shù)據(jù)的分析方面(甚至調(diào)研開放題結果分析)有重要用途���。其應用處理涉及分詞、特征抽取��、情感分析�����、多主題模型等眾多內(nèi)容��。
由于實現(xiàn)難度與領域差異��,當前市面上只有一些開源函數(shù)包或者云API(如BosonNLP)提供一些基礎處理功能����,尚未看到適合商業(yè)研究分析中文文本的集成化工具軟件(如果有誰知道煩請通知我)。在這種情況下��,各商業(yè)公司(如HCR)主要依靠內(nèi)部技術實力自主研發(fā)適合業(yè)務所需的分析功能�����。
高級篇
前面介紹的各種大數(shù)據(jù)分析工具,可應對的數(shù)據(jù)都在億級以下�����,也以結構化數(shù)據(jù)為主�。當實際面臨以下要求: 億級以上/半實時性處理/非標準化復雜需求 ��,通常就需要借助編程(甚至借助于Hadoop/Spark等分布式計算框架)來完成相關的分析�����。 如果能掌握相關的編程語言能力�����,那研究員的分析能力將如虎添翼����。
當前適合大數(shù)據(jù)處理的編程語言����,包括:
R語言——最適合統(tǒng)計研究背景的人員學習�����,具有豐富的統(tǒng)計分析功能庫以及可視化繪圖函數(shù)可以直接調(diào)用。通過Hadoop-R更可支持處理百億級別的數(shù)據(jù)��。 相比SAS,其計算能力更強�����,可解決更復雜更大數(shù)據(jù)規(guī)模的問題���。
Python語言——最大的優(yōu)勢是在文本處理以及大數(shù)據(jù)量處理場景����,且易于開發(fā)����。在相關分析領域����,Python代替R的勢頭越來越明顯。
Java語言——通用性編程語言�����,能力最全面���,擁有最多的開源大數(shù)據(jù)處理資源(統(tǒng)計��、機器學習����、NLP等等)直接使用����。也得到所有分布式計算框架(Hadoop/Spark)的支持。
前面的內(nèi)容介紹了面向大數(shù)據(jù)研究的不同工具軟件/語言的特點和適用場景�����。 這些工具能夠極大增強研究員在大數(shù)據(jù)環(huán)境下的分析能力,但更重要的是研究員要發(fā)揮自身對業(yè)務的深入理解,從數(shù)據(jù)結果中洞察發(fā)現(xiàn)有深度的結果�����,這才是最有價值的。
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330