基于神經(jīng)網(wǎng)絡(luò)的推薦系統(tǒng)模型
為用戶提供建議的平臺。協(xié)同過濾算法是推薦系統(tǒng)中使用的主要算法之一�����。這種算法簡單�、高效;然而,數(shù)據(jù)的稀疏性和方法的可擴(kuò)展性限制了這些算法的性能����,并且很難進(jìn)一步提高推薦結(jié)果的質(zhì)量。因此�,提出了一種將協(xié)同過濾推薦算法與深度學(xué)習(xí)技術(shù)相結(jié)合的模型,其中包括兩部分���。首先���,該模型采用基于二次多項(xiàng)式回歸模型的特征表示方法,通過改進(jìn)傳統(tǒng)的矩陣因子分解算法���,更準(zhǔn)確地獲得潛在特征���。這些潛在特征被認(rèn)為是深層神經(jīng)網(wǎng)絡(luò)模型的輸入數(shù)據(jù)��。該模型的第二部分����,用于預(yù)測評價分?jǐn)?shù)�����。最后���,通過與其他三個公共數(shù)據(jù)集的推薦算法進(jìn)行比較,驗(yàn)證了我們的模型可以有效地提高推薦性能��。
隨著人工智能技術(shù)的發(fā)展���,越來越多的智能產(chǎn)品正在被應(yīng)用���。日常生活,為各種各樣的人提供方便����。個性化推薦系統(tǒng)的智能推薦功能可以有效地為用戶提供服務(wù)。從海量的互聯(lián)網(wǎng)數(shù)據(jù)中獲取有價值的
推薦算法是推薦系統(tǒng)中最重要的部分��,直接決定推薦結(jié)果的質(zhì)量和性能。的系統(tǒng)�����。常用的算法可以分為兩大類:基于內(nèi)容的[1]方法和協(xié)同過濾[2]-[4]方法��?;趦?nèi)容的方法通過對額外信息(如文檔內(nèi)容、用戶配置文件和項(xiàng)目屬性)的分析來構(gòu)建用戶和項(xiàng)目的肖像(描述)��,從而提出建議�����。在大多數(shù)情況下�����,用來構(gòu)建肖像的信息很難獲得甚至是偽造的;因此,它的性能而且應(yīng)用范圍受到很大的限制�。協(xié)同過濾算法是推薦系統(tǒng)中應(yīng)用最廣泛的算法;它們是不同的從基于內(nèi)容的方法中,他們不需要關(guān)于用戶或項(xiàng)目的信息�,他們只基于用戶和諸如點(diǎn)擊、瀏覽和評級等項(xiàng)目的交互信息做出準(zhǔn)確的推薦����。雖然該方法簡單有效���,隨著互聯(lián)網(wǎng)的快速發(fā)展,數(shù)據(jù)的稀疏性限制了算法的性能;因此�,研究人員已經(jīng)開始尋找其他方法來提高推薦性能。
近年來����,深度神經(jīng)網(wǎng)絡(luò)(DNNs)在計(jì)算機(jī)視覺[5]���、語音識別[6]����、自然語言處理[7]等各個領(lǐng)域取得了巨大的成功��。然而��,對這些技術(shù)的推薦系統(tǒng)研究很少�����。一些研究人員
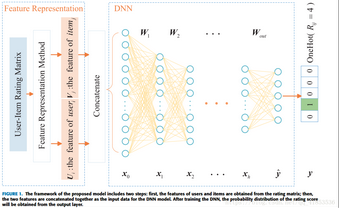
最近提出的基于深度學(xué)習(xí)的推薦模型���,但大多數(shù)模型都使用了附加的特性���,比如文本內(nèi)容和音頻信息��,以提高它們的性能�����。鑒于上述信息可能難以獲得大多數(shù)推薦系統(tǒng)���,本文提出了一種基于DNNs的推薦模型,該模型不需要除了用戶和項(xiàng)目之間的交互之外的任何額外信息��。我們模型的主要框架如圖1所示�����。首先��,我們使用用戶項(xiàng)目評級矩陣來獲取用戶和項(xiàng)目的特性����,我們將在第3節(jié)中討論。然后����,我們將這些特征作為神經(jīng)網(wǎng)絡(luò)的輸入�����。在輸出層中�,我們將獲得一些概率值��,這些值表示用戶可能給出的分?jǐn)?shù)的概率��。最后����,以概率最高的分?jǐn)?shù)作為預(yù)測結(jié)果�。通過對三種公共數(shù)據(jù)集的常用和最先進(jìn)的算法進(jìn)行比較,證明該模型能夠有效地提高推薦精度�。
本文的其余部分組織如下:在第2節(jié)中,我們介紹了基于DNNs的CF方法和一些推薦算法���。我們將在第3節(jié)詳細(xì)描述我們的模型���。第4節(jié)包含一些實(shí)驗(yàn)評估和討論。在第5節(jié)中我們提供了一個簡短的結(jié)論����。
Breese等[8]將CF算法分為兩類:基于內(nèi)存的方法和基于模型的方法��?�;趦?nèi)存的CF使用用戶[9]或項(xiàng)目[10]之間的相似性來提出建議�。由于該方法有效且易于實(shí)現(xiàn)��,因此得到了廣泛的應(yīng)用�����,但隨著推薦系統(tǒng)規(guī)模的增大����,相似度的計(jì)算也變得越來越困難;此外,高數(shù)據(jù)稀疏性也限制了該方法的性能�。
為了解決上述問題,提出了許多基于模型的推薦算法��,如潛在語義模型[11]�、貝葉斯模型[12]、基于回歸的模型[13]�、聚類模型[14]、矩陣因子分解模型[15]�����。在各種CF技術(shù)中,矩陣分解是最常用的方法�。該方法將用戶和項(xiàng)映射到具有相同維度的向量,該維度表示用戶或項(xiàng)的潛在特性��。該方法的代表性工作包括非參數(shù)概率主成分分析(NPCA)[16]�、奇異值分解(SVD)[17]、概率矩陣分解(PMF)[18]����。然而,通過矩陣分解方法學(xué)習(xí)的潛在特征往往不夠有效�����,特別是當(dāng)評價矩陣非常稀疏的時候�。
另一方面���,深度學(xué)習(xí)技術(shù)最近在計(jì)算機(jī)視覺和自然語言處理領(lǐng)域取得了巨大的成功����。這些技術(shù)在學(xué)習(xí)特征表現(xiàn)方面表現(xiàn)出極大的潛力;因此,研究人員已經(jīng)開始將深度學(xué)習(xí)方法應(yīng)用于推薦領(lǐng)域����。Salakhutdinov等[19]使用受限的玻爾茲曼機(jī)代替?zhèn)鹘y(tǒng)的矩陣分解來執(zhí)行CF��,而Georgiev和Nakov[20]通過合并兩者之間的關(guān)聯(lián)來擴(kuò)展工作�����。用戶和項(xiàng)目之間�。還有其他一些基于深度學(xué)習(xí)的研究方法���,但他們主要關(guān)注[21]和[22]等音樂推薦���。這些研究分別使用傳統(tǒng)的卷積神經(jīng)網(wǎng)絡(luò)和深度信任網(wǎng)絡(luò)來學(xué)習(xí)音樂的內(nèi)容特征。除了音樂推薦��,Wang等[23]提出了采用深度學(xué)習(xí)模型獲取內(nèi)容特征的層次貝葉斯模型�,并采用傳統(tǒng)的CF模型來處理評級信息。正如我們所看到的����,這些基于深度學(xué)習(xí)技術(shù)的方法或多或少地通過學(xué)習(xí)諸如文本內(nèi)容之類的內(nèi)容特征來提出建議。以及音樂的光譜�����。當(dāng)我們無法獲得物品的內(nèi)容時,這些方法是不適用的��。因此��,他等[24]提出了一種基于深度學(xué)習(xí)的新的推薦框架��。在他們的方法中����,用戶和項(xiàng)目通過其ID的一熱編碼表示;顯然,該方法只在模型的訓(xùn)練階段使用ID信息�,這使得大量的先驗(yàn)信息無法使用。因此���,特征學(xué)習(xí)的有效性難以保證��。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試��,點(diǎn)擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學(xué)習(xí)CDA考試教材�,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫��,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量��,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330