深度學習之損失函數(shù)與激活函數(shù)的選擇
在深度神經(jīng)網(wǎng)絡(DNN)反向傳播算法(BP)中���,我們對DNN的前向反向傳播算法的使用做了總結(jié)���。其中使用的損失函數(shù)是均方差�,而激活函數(shù)是Sigmoid�。實際上DNN可以使用的損失函數(shù)和激活函數(shù)不少。這些損失函數(shù)和激活函數(shù)如何選擇呢���?以下是本文的內(nèi)容��。
MSE損失+Sigmoid激活函數(shù)的問題
先來看看均方差+Sigmoid的組合有什么問題�?���;仡櫹耂igmoid激活函數(shù)的表達式為:
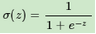
函數(shù)圖像如下:
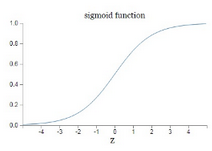
從圖上可以看出,對于Sigmoid���,當z的取值越來越大后�����,函數(shù)曲線變得越來越平緩���,意味著此時的導數(shù)σ′(z)也越來越小。同樣的�,當z的取值越來越小時,也有這個問題����。僅僅在z取值為0附近時��,導數(shù)σ′(z)的取值較大����。在均方差+Sigmoid的反向傳播算法中�,每一層向前遞推都要乘以σ′(z),得到梯度變化值�。Sigmoid的這個曲線意味著在大多數(shù)時候,我們的梯度變化值很小�,導致我們的W,b更新到極值的速度較慢,也就是我們的算法收斂速度較慢�。那么有什么什么辦法可以改進呢?
交叉熵損失+Sigmoid改進收斂速度
Sigmoid的函數(shù)特性導致反向傳播算法收斂速度慢的問題���,那么如何改進呢�?換掉Sigmoid�����?這當然是一種選擇�����。另一種常見的選擇是用交叉熵損失函數(shù)來代替均方差損失函數(shù)。每個樣本的交叉熵損失函數(shù)的形式:
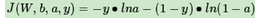
其中����,?為向量內(nèi)積。這個形式其實很熟悉����,在邏輯回歸原理小結(jié)中其實我們就用到了類似的形式,只是當時我們是用最大似然估計推導出來的����,而這個損失函數(shù)的學名叫交叉熵。
使用了交叉熵損失函數(shù)��,就能解決Sigmoid函數(shù)導數(shù)變化大多數(shù)時候反向傳播算法慢的問題嗎�?我們來看看當使用交叉熵時,我們輸出層δL的梯度情況��。
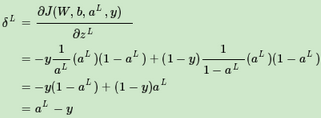
對比一下均方差損失函數(shù)時在δL梯度
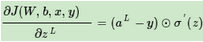
使用交叉熵����,得到的的δl梯度表達式?jīng)]有了σ′(z),梯度為預測值和真實值的差距��,這樣求得的Wl,bl的梯度也不包含σ′(z)��,因此避免了反向傳播收斂速度慢的問題。通常情況下�����,如果我們使用了sigmoid激活函數(shù)�,交叉熵損失函數(shù)肯定比均方差損失函數(shù)好用。
對數(shù)似然損失+softmax進行分類輸出
在前面我們都假設輸出是連續(xù)可導的值��,但是如果是分類問題��,那么輸出是一個個的類別���,那我們怎么用DNN來解決這個問題呢?
DNN分類模型要求是輸出層神經(jīng)元輸出的值在0到1之間�,同時所有輸出值之和為1。很明顯����,現(xiàn)有的普通DNN是無法滿足這個要求的。但是我們只需要對現(xiàn)有的全連接DNN稍作改良�,即可用于解決分類問題。在現(xiàn)有的DNN模型中���,我們可以將輸出層第i個神經(jīng)元的激活函數(shù)定義為如下形式:
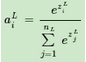
這個方法很簡潔漂亮�����,僅僅只需要將輸出層的激活函數(shù)從Sigmoid之類的函數(shù)轉(zhuǎn)變?yōu)樯鲜降募せ詈瘮?shù)即可��。上式這個激活函數(shù)就是我們的softmax激活函數(shù)���。它在分類問題中有廣泛的應用�����。將DNN用于分類問題���,在輸出層用softmax激活函數(shù)也是最常見的了。
對于用于分類的softmax激活函數(shù)�����,對應的損失函數(shù)一般都是用對數(shù)似然函數(shù)��,即:
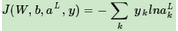
其中yk的取值為0或者1��,如果某一訓練樣本的輸出為第i類�。則yi=1,其余的j≠i都有yj=0。由于每個樣本只屬于一個類別,所以這個對數(shù)似然函數(shù)可以簡化為:
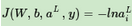
可見損失函數(shù)只和真實類別對應的輸出有關����,這樣假設真實類別是第i類,則其他不屬于第i類序號對應的神經(jīng)元的梯度導數(shù)直接為0����。對于真實類別第i類,它的WiL對應的梯度計算為:

可見�,梯度計算也很簡潔,也沒有第一節(jié)說的訓練速度慢的問題����。當softmax輸出層的反向傳播計算完以后,后面的普通DNN層的反向傳播計算和之前講的普通DNN沒有區(qū)別���。
梯度爆炸or消失與ReLU
學習DNN,大家一定聽說過梯度爆炸和梯度消失兩個詞�。尤其是梯度消失,是限制DNN與深度學習的一個關鍵障礙�����,目前也沒有完全攻克��。
什么是梯度爆炸和梯度消失呢?簡單理解�����,就是在反向傳播的算法過程中���,由于我們使用了是矩陣求導的鏈式法則�����,有一大串連乘��,如果連乘的數(shù)字在每層都是小于1的�����,則梯度越往前乘越小�,導致梯度消失�����,而如果連乘的數(shù)字在每層都是大于1的�����,則梯度越往前乘越大,導致梯度爆炸���。
比如如下的梯度計算:
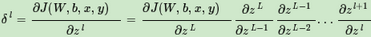
如果不巧我們的樣本導致每一層的梯度都小于1���,則隨著反向傳播算法的進行,我們的δl會隨著層數(shù)越來越小���,甚至接近越0�����,導致梯度幾乎消失����,進而導致前面的隱藏層的W,b參數(shù)隨著迭代的進行���,幾乎沒有大的改變�,更談不上收斂了��。這個問題目前沒有完美的解決辦法��。
而對于梯度爆炸���,則一般可以通過調(diào)整我們DNN模型中的初始化參數(shù)得以解決��。
對于無法完美解決的梯度消失問題��,一個可能部分解決梯度消失問題的辦法是使用ReLU(Rectified Linear Unit)激活函數(shù)����,ReLU在卷積神經(jīng)網(wǎng)絡CNN中得到了廣泛的應用��,在CNN中梯度消失似乎不再是問題����。那么它是什么樣子呢?其實很簡單����,比我們前面提到的所有激活函數(shù)都簡單,表達式為:
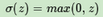
也就是說大于等于0則不變�����,小于0則激活后為0�����。
其他激活函數(shù)
DNN常用的激活函數(shù)還有:
tanh
這個是sigmoid的變種,表達式為:
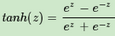
tanh激活函數(shù)和sigmoid激活函數(shù)的關系為:

tanh和sigmoid對比主要的特點是它的輸出落在了[-1,1],這樣輸出可以進行標準化����。同時tanh的曲線在較大時變得平坦的幅度沒有sigmoid那么大,這樣求梯度變化值有一些優(yōu)勢�����。當然��,要說tanh一定比sigmoid好倒不一定�,還是要具體問題具體分析。
softplus
這個其實就是sigmoid函數(shù)的原函數(shù)��,表達式為:
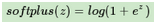
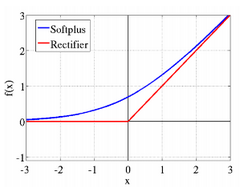
它的導數(shù)就是sigmoid函數(shù)����。softplus的函數(shù)圖像和ReLU有些類似。它出現(xiàn)的比ReLU早��,可以視為ReLU的鼻祖�����。
PReLU
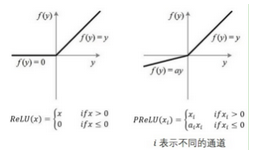
從名字就可以看出它是ReLU的變種����,特點是如果未激活值小于0,不是簡單粗暴的直接變?yōu)?���,而是進行一定幅度的縮小�����。如下圖���。
小結(jié)
上面我們對DNN損失函數(shù)和激活函數(shù)做了詳細的討論,重要的點有:
1)如果使用sigmoid激活函數(shù)�,則交叉熵損失函數(shù)一般肯定比均方差損失函數(shù)好;
2)如果是DNN用于分類�,則一般在輸出層使用softmax激活函數(shù)和對數(shù)似然損失函數(shù);
3)ReLU激活函數(shù)對梯度消失問題有一定程度的解決����,尤其是在CNN模型中。











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330