異常檢測原理與實(shí)驗(yàn)
最近需要對欺詐報價進(jìn)行識別處理�,簡單的模型就是給定很多不同數(shù)據(jù)集,需要找出每個spu下可能存在的欺詐數(shù)據(jù)�����,比如{20,22,30},其中的欺詐數(shù)據(jù)可能就是30����。其實(shí)加以抽象,屬于異常檢測范圍���。
異常檢測是發(fā)現(xiàn)與大部分對象不同的對象����,其中這些不同的對象稱為離群點(diǎn)�����。一般異常檢測的方法主要有數(shù)理統(tǒng)計法�、數(shù)據(jù)挖掘方法。一般在預(yù)處理階段發(fā)生的異常檢測����,更多的是依托數(shù)理統(tǒng)計的思想完成的����。
一�、基于模型
首先判斷出數(shù)據(jù)的分布模型,比如某種分布(高斯分布����、泊松分布等等)。然后根據(jù)原始數(shù)據(jù)(包括正常點(diǎn)與離群點(diǎn))���,算出分布的參數(shù)�����,從而可以代入分布方程求出概率�����。例如高斯分布�,根據(jù)原始數(shù)據(jù)求出期望u和方差����?,然后擬合出高斯分布函數(shù),從而求出原始數(shù)據(jù)出現(xiàn)的概率�����;根據(jù)數(shù)理統(tǒng)計的思想����,概率小的可以當(dāng)做離群點(diǎn)�����。
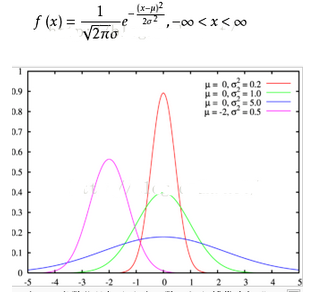
優(yōu)點(diǎn):
方法簡單���,無需訓(xùn)練�����,可以用在小數(shù)據(jù)集上��。
缺點(diǎn):
發(fā)現(xiàn)離群點(diǎn)效果差�,離群點(diǎn)對模型參數(shù)影響大�����,造成區(qū)分效果差。需要數(shù)值化
import java.util.List;
/**
* 實(shí)現(xiàn)描述:計算正態(tài)分布
*
* @author jin.xu
* @version v1.0.0
* @see
* @since 16-9-9 下午12:02
*/
public class Gauss {
public double getMean(List<Double> dataList) {
double sum = 0;
for (double data : dataList) {
sum += data;
}
double mean = sum;
if (dataList.size() > 0) {
mean = sum / dataList.size();
}
return mean;
}
public double getStd(List<Double> dataList, double mean) {
double sum = 0;
for (double data : dataList) {
sum += (data - mean) * (data - mean);
}
double std = sum;
if (dataList.size() > 0) {
std = sum / dataList.size();
}
return Math.sqrt(std);
}
public double getProbability(double data, double meam, double std) {
double tmp = (1.0 / (Math.sqrt(2 * 3.141592653) * std)) * Math.exp(-(Math.pow(data - meam, 2) / (2 * Math.pow(std, 2))));
return tmp;
}
}
二�、基于近鄰度
需要度量對象之間的距離,離群點(diǎn)一般是距離大部分?jǐn)?shù)據(jù)比較遠(yuǎn)的點(diǎn)�����。一般這種方法是計算每個點(diǎn)與其距離最近的k個點(diǎn)的距離和�����,然后累加起來��,這就是K近鄰方法�����。
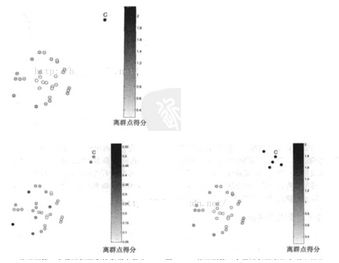
優(yōu)點(diǎn):
原理簡單�,無需訓(xùn)練,可用在任何數(shù)據(jù)集
缺點(diǎn):
需要計算距離��,計算量大�����,K的選定以及多于K個離群點(diǎn)聚集在一起導(dǎo)致誤判�。
public class KNN {
public static double process(int index,Position position, int k, List<Position> positionList) {
List<Double> distances = Lists.newArrayList();
for (int i = 0; i < positionList.size(); ++i) {
if (i != index) {
distances.add(Math.sqrt(Math.pow((positionList.get(i).getX() - position.getX()), 2)+Math.pow((positionList.get(i).getY()-position.getY()),2)));
}
}
Collections.sort(distances);
k = k < distances.size() ? k : distances.size();
double knnDistance = 0.0;
for (int i = 0; i < k; ++i) {
knnDistance += distances.get(i);
}
return knnDistance;
}
private static class Position{
int x;
int y;
public int getX() {
return x;
}
public void setX(int x) {
this.x = x;
}
public int getY() {
return y;
}
public void setY(int y) {
this.y = y;
}
}
}
三��、基于密度
低密度區(qū)域的數(shù)據(jù)點(diǎn)可以當(dāng)做某種程度上的離群點(diǎn)�?���;诿芏鹊暮突诮彽氖敲芮邢嚓P(guān)的,簡單來說����,密度和近鄰的距離成反比����。一般的度量公式如下:
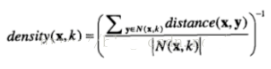
density(x,k)表示包含x的k近鄰的密度,distance(x,y)表示x到y(tǒng)的距離�,N(x,k)表示x的k近鄰集合。
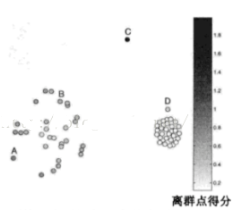
優(yōu)點(diǎn):
相對準(zhǔn)確
缺點(diǎn):
需要度量密度�,需要設(shè)定閾值
四、基于聚類
丟棄遠(yuǎn)離其他聚類簇的小聚類簇�。需要給出小聚類簇的大小閾值、聚類簇距離閾值�。常用的聚類方法比較多,比如K-means(變種K-models)����、EM����、層次聚類算法(分裂型和歸約型)�。具體方法說明可見:漫話數(shù)據(jù)挖掘。
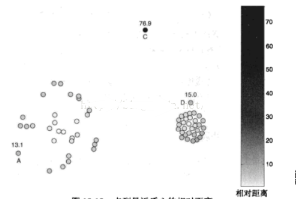
優(yōu)點(diǎn):
引入數(shù)據(jù)挖掘聚類的方法���,在樣本充足的情況下準(zhǔn)確度會相對較高
缺點(diǎn):
需要訓(xùn)練���,計算量大,原理相對復(fù)雜
需要建立適當(dāng)?shù)哪P?���,需要充足的?xùn)練樣本
總之異常檢測的通用方法大致有4種:基于模型、k近鄰�、基于密度和基于聚類的。實(shí)際使用數(shù)據(jù)是線上的報價�,由于每個SPU下報價有限,聚類不適合��,所以用基于模型的和k近鄰的做了試驗(yàn)�;基于密度的和K近鄰差不多,而且需要密度范圍的距離閾值���,就沒有選擇����。此外,涉及的實(shí)驗(yàn)數(shù)據(jù)是公司的�,代碼是興趣使然,所以就不公布具體實(shí)驗(yàn)數(shù)據(jù)�。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學(xué)習(xí)CDA考試教材�,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫�����,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量�����,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330