用機(jī)器學(xué)習(xí)檢測(cè)異常點(diǎn)擊流
本文內(nèi)容是我學(xué)習(xí)ML時(shí)做的一個(gè)練手項(xiàng)目��,描述應(yīng)用機(jī)器學(xué)習(xí)的一般步驟��。該項(xiàng)目的目標(biāo)是從點(diǎn)擊流數(shù)據(jù)中找出惡意用戶的請(qǐng)求��。點(diǎn)擊流數(shù)據(jù)長(zhǎng)下圖這樣子����,包括請(qǐng)求時(shí)間、IP�、平臺(tái)等特征:

該項(xiàng)目從開(kāi)始做到階段性完成,大致可分為兩個(gè)階段:算法選擇和工程優(yōu)化����。算法選擇階段挑選合適的ML模型,嘗試了神經(jīng)網(wǎng)絡(luò)、高斯分布���、Isolation
Forest等三個(gè)模型���。由于點(diǎn)擊流數(shù)據(jù)本身的特性�,導(dǎo)致神經(jīng)網(wǎng)絡(luò)和高斯分布并不適用于該場(chǎng)景,最終選擇了Isolation
Forest�����。工程優(yōu)化階段�,最初使用單機(jī)訓(xùn)練模型和預(yù)測(cè)結(jié)果,但隨著數(shù)據(jù)量的增加�,最初的單機(jī)系統(tǒng)出現(xiàn)了性能瓶頸;然后開(kāi)始優(yōu)化性能���,嘗試了分布化訓(xùn)練��,最終通過(guò)單機(jī)異步化達(dá)到了性能要求����。
1 算法選擇
1.1 神經(jīng)網(wǎng)絡(luò)
剛開(kāi)始沒(méi)經(jīng)驗(yàn)�����,受TensorFlow熱潮影響,先嘗試了神經(jīng)網(wǎng)絡(luò)�。選用的神經(jīng)網(wǎng)絡(luò)是MLP(Multilayer
Perceptron,多層感知器)��,一種全連接的多層網(wǎng)絡(luò)��。MLP是有監(jiān)督學(xué)習(xí)�����,需要帶標(biāo)簽的樣本�����,這里“帶標(biāo)簽”的意思是樣本數(shù)據(jù)標(biāo)注了哪些用戶請(qǐng)求是惡意的���、哪些是正常的�。但后臺(tái)并沒(méi)有現(xiàn)成帶標(biāo)簽的惡意用戶樣本數(shù)據(jù)���。后來(lái)通過(guò)安全側(cè)的一些數(shù)據(jù)“間接”給用戶請(qǐng)求打上了標(biāo)簽�����,然后選擇IP���、平臺(tái)��、版本號(hào)����、操作碼等數(shù)據(jù)作為MLP的輸入數(shù)據(jù)����。結(jié)果當(dāng)然是失敗���,想了下原因有兩個(gè):
1��, 樣本的標(biāo)簽質(zhì)量非常差�,用這些樣本訓(xùn)練出來(lái)的模型性能當(dāng)然也很差��;
2���, 輸入的特征不足以刻畫(huà)惡意用戶����。
數(shù)據(jù)的質(zhì)量問(wèn)題目前很難解決,所以只能棄用MLP����。
1.2 高斯分布
然后嘗試其他模型。通過(guò)搜索發(fā)現(xiàn)�,有一類ML模型專門(mén)用于異常檢測(cè),找到了Andrew Ng介紹的基于高斯分布的異常檢測(cè)算法:高斯分布如下圖所示:
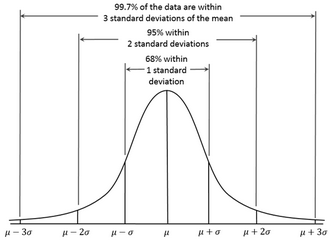
這個(gè)算法的思想比較簡(jiǎn)單:與大部分樣本不一致的樣本就是異常�;通過(guò)概率密度量化“不一致”。具體做法是:選擇符合高斯分布或能轉(zhuǎn)換為高斯分布的特征�����,利用收集到的數(shù)據(jù)對(duì)高斯分布做參數(shù)估計(jì)�,把概率密度函數(shù)值小于某個(gè)閾值的點(diǎn)判定為異常。
所謂的參數(shù)估計(jì)是指�,給定分布數(shù)據(jù),求分布的參數(shù)��。對(duì)高斯分布來(lái)說(shuō)����,就是求μ和σ。用極大似然估計(jì)可以得到高斯分布參數(shù)的解析解:
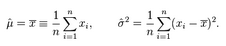
得到高斯分布參數(shù)后�,用下式計(jì)算概率密度:
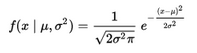
X表示一個(gè)特征輸入。若有多個(gè)特征x0��、x1、…�、xn,一種簡(jiǎn)單的處理方法是將其結(jié)果連乘起來(lái)即可:f(x) = f(x0)f(x1)…f(xn)��。
然后選定一個(gè)閾值ε��,把f(x) < ε的樣本判定為異常�����。ε值需根據(jù)實(shí)際情況動(dòng)態(tài)調(diào)整���,默認(rèn)可設(shè)定ε = f(μ- 3σ)�。
把這個(gè)模型初步應(yīng)用于點(diǎn)擊流異常檢測(cè)時(shí)�,效果還不錯(cuò)��,但在進(jìn)一步實(shí)施過(guò)程中碰到一個(gè)棘手問(wèn)題:樣本中最重要的一個(gè)特征是操作碼���,當(dāng)前操作碼在微信后臺(tái)的取值范圍是[101,
1000]�,每個(gè)操作碼的請(qǐng)求次數(shù)是模型的基礎(chǔ)輸入��,對(duì)900個(gè)特征計(jì)算概率密度再相乘�,非常容易導(dǎo)致結(jié)果下溢出�,以致無(wú)法計(jì)算出精度合適的概率密度值�����。這個(gè)現(xiàn)象被稱為維度災(zāi)難(Dimension
Disaster)�。
解決維度災(zāi)難的一個(gè)常見(jiàn)做法是降維,降維的手段有多種�,這里不展開(kāi)討論了。在點(diǎn)擊流分析的實(shí)踐中���,降維的效果并不好�����,主要原因有兩個(gè):
1��, 正常用戶和惡意用戶的訪問(wèn)模式并不固定�,導(dǎo)致很難分解出有效的特征矩陣或特征向量����;
2, 降維的本質(zhì)是有損壓縮���,有損壓縮必定導(dǎo)致信息丟失�。但在本例中每一維的信息都是關(guān)鍵信息,有損壓縮會(huì)極大破壞樣本的有效性�����。
高斯分布模型的維度災(zāi)難在本例中較難解決��,只能再嘗試其他模型了
1.3 Isolation Forest
Isolation
Forest���,可翻譯為孤異森林�����,該算法的基本思想是:隨機(jī)選擇樣本的一個(gè)特征���,再隨機(jī)選擇該特征取值范圍中的一個(gè)值,對(duì)樣本集做拆分��,迭代該過(guò)程���,生成一顆Isolation
Tree;樹(shù)上葉子節(jié)點(diǎn)離根節(jié)點(diǎn)越近���,其異常值越高���。迭代生成多顆Isolation Tree�,生成Isolation
Forest��,預(yù)測(cè)時(shí)�����,融合多顆樹(shù)的結(jié)果形成最終預(yù)測(cè)結(jié)果�。Isolation Forest的基礎(chǔ)結(jié)構(gòu)有點(diǎn)類似經(jīng)典的隨機(jī)森林(Random
Forest)。
這個(gè)異常檢測(cè)模型有效利用了異常樣本“量少”和“與正常樣本表現(xiàn)不一樣”的兩個(gè)特點(diǎn)���,不依賴概率密度因此不會(huì)導(dǎo)致高維輸入的下溢出問(wèn)題����。提取少量點(diǎn)擊流樣本測(cè)試����,它在900維輸入的情況下也表現(xiàn)良好,最終選擇它作為系統(tǒng)的模型���。
2 工程優(yōu)化
工程實(shí)現(xiàn)經(jīng)歷了單機(jī)訓(xùn)練�����、分布式訓(xùn)練��、單機(jī)異步化訓(xùn)練3個(gè)方案�,下面內(nèi)容介紹實(shí)現(xiàn)過(guò)程中碰到的問(wèn)題和解決方法。
2.1 單機(jī)訓(xùn)練
整個(gè)系統(tǒng)主要包括收集數(shù)據(jù)�����、訓(xùn)練模型����、預(yù)測(cè)異常、上報(bào)結(jié)果四個(gè)部分����。
2.1.1 收集數(shù)據(jù)
剛開(kāi)始嘗試該模型時(shí),是通過(guò)手工方式從mmstreamstorage獲取樣本的:
1�����,通過(guò)logid 11357���,得到手工登錄成功用戶的uin和登錄時(shí)間;
2��,利用mmstreamstorage提供的接口,得到用戶登錄后10分鐘的點(diǎn)擊流���;
但這樣做有兩個(gè)缺點(diǎn):
1�,上述步驟1是離線手工操作的�����,需要做成自動(dòng)化�����;
2��,mmstreamstorage的接口性能較差���,只能提供2萬(wàn)/min的查詢性能�,上海IDC登錄的峰值有9萬(wàn)/min����。
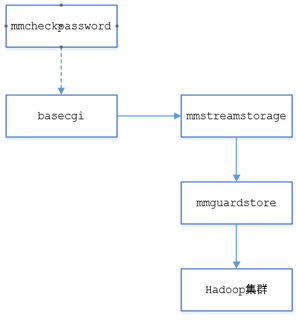
改進(jìn)辦法是復(fù)用點(diǎn)擊流上報(bào)模塊mmstreamstorage,增加一個(gè)旁路數(shù)據(jù)的邏輯:
1���,手工登錄時(shí)在presence中記錄手工登錄時(shí)間��,mmstreamstorage基于該時(shí)間旁路一份數(shù)據(jù)給mmguardstore�����。由于mmstreamstorage每次只能提供單挑點(diǎn)擊流數(shù)據(jù)�����,所以需要在mmguardstore中緩存����;
2,mmguardstore做完數(shù)據(jù)清洗和特征提取���,然后把樣本數(shù)據(jù)落地����,最后利用crontab定期將該數(shù)據(jù)同步到Hadoop集群中�����。
最終的數(shù)據(jù)收集模塊結(jié)構(gòu)圖如下所示:
點(diǎn)擊流數(shù)據(jù)提供了IP���、平臺(tái)����、版本號(hào)����、操作碼等特征,經(jīng)過(guò)多次試驗(yàn)����,選定用戶手工登錄后一段時(shí)間內(nèi)操作碼的訪問(wèn)次數(shù)作為模型的輸入。
上面我們提到過(guò)點(diǎn)擊流的操作碼有900個(gè)有效取值�����,所以一個(gè)顯然的處理方法是���,在mmguardstore中把用戶的點(diǎn)擊流數(shù)據(jù)轉(zhuǎn)化為一個(gè)900維的向量��,key是cgi id�,value是對(duì)應(yīng)cgi的訪問(wèn)次數(shù)����。該向量刻畫(huà)了用戶的行為�,可稱為行為特征向量���。
2.1.2 訓(xùn)練模型
初起為了控制不確定性�,只輸入1萬(wàn)/分鐘的樣本給模型訓(xùn)練和預(yù)測(cè)�����。系統(tǒng)的工作流程是先從Hadoop加載上一分鐘的樣本數(shù)據(jù)����,然后用數(shù)據(jù)訓(xùn)練Isolation Forest模型,最后用訓(xùn)練好的模型做異常檢測(cè)����,并將檢測(cè)結(jié)果同步到tdw。
在1萬(wàn)/分鐘輸入下取得較好的檢測(cè)結(jié)果后���,開(kāi)始導(dǎo)入全量數(shù)據(jù)���,全量數(shù)據(jù)數(shù)據(jù)的峰值為20萬(wàn)/分鐘左右。出現(xiàn)的第一個(gè)問(wèn)題是�����,一分鐘內(nèi)無(wú)法完成加載數(shù)據(jù)、訓(xùn)練模型�����、預(yù)測(cè)結(jié)果�����,單加載數(shù)據(jù)就耗時(shí)10分鐘左右����。這里先解釋下為什么有“一分鐘”的時(shí)間周期限制����,主要原因有兩個(gè):
1, 想盡快獲取檢測(cè)結(jié)果���;
2�, 由于點(diǎn)擊流異常檢測(cè)場(chǎng)景的特殊性����,模型性能有時(shí)效性,需要經(jīng)常用最新數(shù)據(jù)訓(xùn)練新的模型���。
解決性能問(wèn)題的第一步是要知道性能瓶頸在哪里�����,抽樣發(fā)現(xiàn)主要是加載數(shù)據(jù)和訓(xùn)練模型耗時(shí)較多�,預(yù)測(cè)異常和上報(bào)結(jié)果的耗時(shí)并沒(méi)有隨數(shù)據(jù)量的增加而快速上漲。
加載數(shù)據(jù)的耗時(shí)主要消耗在網(wǎng)絡(luò)通信上:樣本文件太大了��,導(dǎo)致系統(tǒng)從Hadoop同步樣本數(shù)據(jù)時(shí)碰到網(wǎng)絡(luò)帶寬瓶頸�。但由于樣本是文本類數(shù)據(jù),對(duì)數(shù)據(jù)先壓縮再傳輸可極大減少通信量����,這里的耗時(shí)比較容易優(yōu)化。
訓(xùn)練模型的耗時(shí)增加源于輸入數(shù)據(jù)量的增加���。下圖是1萬(wàn)樣本/min的輸入下����,系統(tǒng)個(gè)階段的耗時(shí):
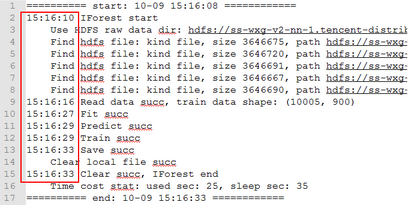
其中:
加載程序: 2s
加載數(shù)據(jù): 6s
訓(xùn)練模型:11s
分類異常: 2s
保存結(jié)果: 4s
單輪總耗時(shí):25s
需處理全量數(shù)據(jù)時(shí)�,按線性關(guān)系換算,“訓(xùn)練模型”耗時(shí)為:11s * 24 = 264s���,約為4.4分鐘���,單機(jī)下無(wú)法在1分鐘內(nèi)完成計(jì)算�。
最先想到的優(yōu)化訓(xùn)練模型耗時(shí)的辦法是分布式訓(xùn)練����。
2.2 分布式訓(xùn)練
由于scikit-learn只提供單機(jī)版的Isolation
Forest實(shí)現(xiàn),所以只能自己實(shí)現(xiàn)它的分布式版本���。了解了下目前最常用的分布式訓(xùn)練方法是參數(shù)服務(wù)器(Parameter
Server���,PS)模式�,其想法比較簡(jiǎn)單:訓(xùn)練模型并行跑在多機(jī)上,訓(xùn)練結(jié)果在PS合并�����。示意圖如下所示:
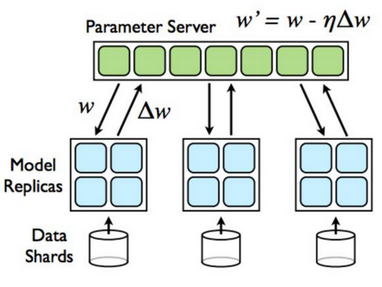
分布式訓(xùn)練對(duì)算法有一定要求����,而Isolation Forest正好適用于分布式訓(xùn)練。
然后嘗試在TensorFlow上實(shí)現(xiàn)Isolation Forest的分布式訓(xùn)練版本�。選擇TensorFlow的原因有主要兩個(gè):
1, TensorFlow已經(jīng)實(shí)現(xiàn)了一個(gè)分布式訓(xùn)練框架����;
2����, TensorFlow的tf.contrib.learn包已經(jīng)實(shí)現(xiàn)的Random Forest可作參考(Isolation
Forest在結(jié)構(gòu)上與Random Forest類似)�����,只需對(duì)Isolation Forest定制一個(gè)Operation即可��。
寫(xiě)完代碼測(cè)試時(shí)�����,發(fā)現(xiàn)了個(gè)巨坑的問(wèn)題:TenforFlow內(nèi)部的序列化操作非常頻繁�����、性能十分差����。構(gòu)造了110個(gè)測(cè)試樣本,scikit-learn耗時(shí)只有0.340秒�����,29萬(wàn)次函數(shù)調(diào)用;而TensorFlow耗時(shí)達(dá)207.831秒��,有2.48億次函數(shù)調(diào)用���。
TensorFlow性能抽樣:
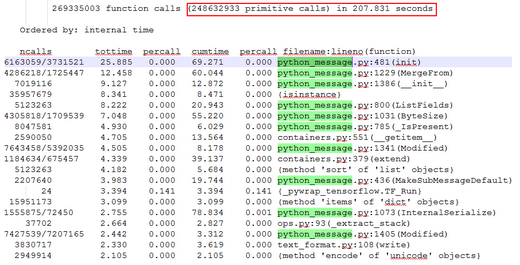
Scikit-learn性能抽樣:

從TensorFlow的性能抽樣數(shù)據(jù)可以看到�,耗時(shí)排前排的函數(shù)都不是實(shí)現(xiàn)Isolation Forest算法的函數(shù)�����,其原因應(yīng)該與TensorFlow基于Graph��、Session的實(shí)現(xiàn)方式有關(guān)��。感覺(jué)這里坑比較深��,遂放棄填坑����。
也了解了下基于Spark的spark-sklearn����,該項(xiàng)目暫時(shí)還未支持Isolation Forest,也因?yàn)榭犹睿粫r(shí)半會(huì)搞不定而放棄了�。
2.3 單機(jī)異步化訓(xùn)練
沒(méi)搞定分布式訓(xùn)練,只能回到單機(jī)場(chǎng)景再想辦法�。單機(jī)優(yōu)化有兩個(gè)著力點(diǎn):優(yōu)化算法實(shí)現(xiàn)和優(yōu)化系統(tǒng)結(jié)構(gòu)。
首先看了下scikit-learn中Isoaltion Forest的實(shí)現(xiàn)���,底層專門(mén)用Cython優(yōu)化了�,再加上Joblib庫(kù)的多CPU并行�����,算法實(shí)現(xiàn)上的優(yōu)化空間已經(jīng)很小了�,只能從系統(tǒng)結(jié)構(gòu)上想辦法。
系統(tǒng)結(jié)構(gòu)上的優(yōu)化有兩個(gè)利器:并行化和異步化����。之前的單機(jī)模型,加載數(shù)據(jù)�、訓(xùn)練模型、預(yù)測(cè)異常���、上報(bào)結(jié)果在單進(jìn)程中串行執(zhí)行�,由此想到的辦法是啟動(dòng)4個(gè)工作進(jìn)程分別處理相應(yīng)的四個(gè)任務(wù):異步訓(xùn)練模型�、預(yù)測(cè)異常和上報(bào)結(jié)果,并行加載數(shù)據(jù)。工作進(jìn)程之間用隊(duì)列通信��,隊(duì)列的一個(gè)優(yōu)勢(shì)是容易實(shí)現(xiàn)流量控制�����。
寫(xiě)完代碼測(cè)試����,卻發(fā)現(xiàn)YARD環(huán)境中的Python
HDFS庫(kù)在多進(jìn)程并發(fā)下直接拋異常。嘗試多個(gè)方法發(fā)現(xiàn)這個(gè)問(wèn)題較難解決�,暫時(shí)只能想辦法規(guī)避。經(jīng)測(cè)試發(fā)現(xiàn)����,直接從Hadoop同步所有壓縮過(guò)的樣本數(shù)據(jù)只需2秒左右,由此想到規(guī)避方法是:先單進(jìn)程同步所有樣本數(shù)據(jù)����,再多進(jìn)程并發(fā)解壓、加載和預(yù)測(cè)�����。
按上述想法修改代碼測(cè)試�����,效果較好�,處理所有樣本只需20秒左右,達(dá)到了1分鐘處理完所有樣本的要求�。然后提交YARD作業(yè)線上跑,處理所有樣本耗時(shí)卻達(dá)到200~400秒:
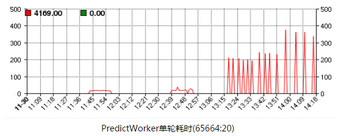
咨詢YARD側(cè)同學(xué)����,得知YARD對(duì)提交的離線作業(yè)有CPU配額的硬限制,分時(shí)段配額如下表:
00:00~09:00 80%
09:00~19:00 50%
19:00~23:00 15%
23:00~24:00 50%
晚高峰時(shí)段的配額只有15%����。
與YARD側(cè)同學(xué)溝通,他們答應(yīng)后續(xù)會(huì)支持scikit-learn庫(kù)的在線服務(wù)�����。目前通過(guò)手工方式在一臺(tái)有scikit-learn的mmguardstore機(jī)器上運(yùn)行在線服務(wù)���,晚高峰時(shí)段處理全量數(shù)據(jù)耗時(shí)為20秒左右�����。
最終的系統(tǒng)結(jié)構(gòu)圖如下圖所示:
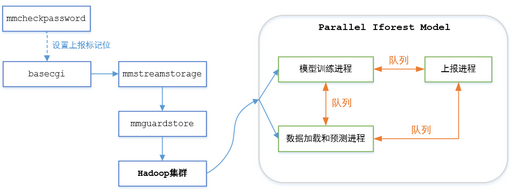
模型訓(xùn)練進(jìn)程定期訓(xùn)練最新的模型���,并把模型通過(guò)隊(duì)列傳給預(yù)測(cè)進(jìn)程����。預(yù)測(cè)進(jìn)程每分鐘運(yùn)行一次���,檢查模型隊(duì)列上是否有新模型可使用�����,然后加載數(shù)據(jù)��、檢測(cè)異常����,將檢測(cè)結(jié)果通過(guò)上報(bào)隊(duì)列傳給上報(bào)進(jìn)程���。上報(bào)進(jìn)程block在上報(bào)隊(duì)列上����,一旦發(fā)現(xiàn)有新數(shù)據(jù)����,就根據(jù)數(shù)據(jù)類型執(zhí)行上報(bào)監(jiān)控、上報(bào)tdw等操作�。
2.4 評(píng)估性能
安全側(cè)將異常用戶分為以下幾類:盜號(hào)、LBS/加好友�����、養(yǎng)號(hào)�����、欺詐��、外掛/多開(kāi)等���。由于這些分類的異常打擊是由不同同學(xué)負(fù)責(zé)�����,不便于對(duì)Isolation
Forest的分類結(jié)果做評(píng)估���,因此需要在Isolation
Forest的基礎(chǔ)上,再加一個(gè)分類器�����,標(biāo)記“異常樣本”的小類。利用操作碼實(shí)現(xiàn)了該分類器�。
接入全量數(shù)據(jù)后,每天準(zhǔn)實(shí)時(shí)分析1億量級(jí)的樣本����,檢測(cè)出500萬(wàn)左右的異常,精確分類出15萬(wàn)左右的惡意請(qǐng)求���。惡意請(qǐng)求的uin�����、類型����、發(fā)生時(shí)間通過(guò)tdw中轉(zhuǎn)給安全側(cè)�。安全側(cè)通過(guò)線下人工分析和線上打擊,從結(jié)果看檢測(cè)效果較好���。
2.5 持續(xù)優(yōu)化
再回過(guò)頭觀察點(diǎn)擊流數(shù)據(jù)��,我們使用的Isolation
Forest模型只利用了操作碼的統(tǒng)計(jì)數(shù)據(jù)����。可以明顯看到�����,點(diǎn)擊流是一個(gè)具備時(shí)間序列信息的時(shí)序數(shù)據(jù)����。而自然語(yǔ)言處理(Natural Language
Processing�,NLP)領(lǐng)域已經(jīng)積累了非常多的處理時(shí)序數(shù)據(jù)的理論和實(shí)戰(zhàn)經(jīng)驗(yàn),如LSTM�、word2vec等模型。后續(xù)期望能引入NLP的相關(guān)工具挖掘出更多惡意用戶����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�;
? 想學(xué)習(xí)CDA考試教材,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫(kù)�����,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情�;
? 想了解CDA考試含金量,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330